C2W2: Tackle Overfitting with Data Augmentation
C2W2: Tackle Overfitting with Data Augmentation#
https-deeplearning-ai/tensorflow-1-public/C2/W2/assignment/C2W2_Assignment.ipynb
Commit
d79901fon Feb 23, Compare
import os
import zipfile
import random
import shutil
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
!wget --no-check-certificate \
"https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip" \
-O "/tmp/cats-and-dogs.zip"
local_zip = '/tmp/cats-and-dogs.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
--2023-04-12 14:46:38-- https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
Resolving download.microsoft.com (download.microsoft.com)... 104.124.158.9, 2600:141c:5000:18e::317f, 2600:141c:5000:187::317f
Connecting to download.microsoft.com (download.microsoft.com)|104.124.158.9|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 824887076 (787M) [application/octet-stream]
Saving to: ‘/tmp/cats-and-dogs.zip’
/tmp/cats-and-dogs. 100%[===================>] 786.67M 5.80MB/s in 2m 16s
2023-04-12 14:48:54 (5.80 MB/s) - ‘/tmp/cats-and-dogs.zip’ saved [824887076/824887076]
source_path = '/tmp/PetImages'
source_path_dogs = os.path.join(source_path, 'Dog')
source_path_cats = os.path.join(source_path, 'Cat')
# Deletes all non-image files (there are two .db files bundled into the dataset)
!find /tmp/PetImages/ -type f ! -name "*.jpg" -exec rm {} +
# os.listdir returns a list containing all files under the given path
print(f"There are {len(os.listdir(source_path_dogs))} images of dogs.")
print(f"There are {len(os.listdir(source_path_cats))} images of cats.")
There are 12500 images of dogs.
There are 12500 images of cats.
root_dir = '/tmp/cats-v-dogs'
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
def create_train_val_dirs(root_path):
os.makedirs(os.path.join(root_path, 'training/cats'))
os.makedirs(os.path.join(root_path, 'training/dogs'))
os.makedirs(os.path.join(root_path, 'validation/cats'))
os.makedirs(os.path.join(root_path, 'validation/dogs'))
try:
create_train_val_dirs(root_path=root_dir)
except FileExistsError:
print("You should not be seeing this since the upper directory is removed beforehand")
for rootdir, dirs, files in os.walk(root_dir):
for subdir in dirs:
print(os.path.join(rootdir, subdir))
/tmp/cats-v-dogs/training
/tmp/cats-v-dogs/validation
/tmp/cats-v-dogs/training/dogs
/tmp/cats-v-dogs/training/cats
/tmp/cats-v-dogs/validation/dogs
/tmp/cats-v-dogs/validation/cats
def split_data(SOURCE_DIR, TRAINING_DIR, VALIDATION_DIR, SPLIT_SIZE):
source_files = []
for image_name in os.listdir(SOURCE_DIR):
image_path = os.path.join(SOURCE_DIR, image_name)
if not os.path.getsize(image_path):
print(f"{image_name} is zero length, so ignoring.")
continue
source_files.append(image_name)
num_images = len(source_files)
num_training = int(num_images * SPLIT_SIZE)
list_files = random.sample(source_files, num_images)
training_images = list_files[:num_training]
validation_images = list_files[num_training:]
for training_image in training_images:
shutil.copyfile(os.path.join(SOURCE_DIR, training_image),
os.path.join(TRAINING_DIR, training_image))
for validation_image in validation_images:
shutil.copyfile(os.path.join(SOURCE_DIR, validation_image),
os.path.join(VALIDATION_DIR, validation_image))
CAT_SOURCE_DIR = "/tmp/PetImages/Cat/"
DOG_SOURCE_DIR = "/tmp/PetImages/Dog/"
TRAINING_DIR = "/tmp/cats-v-dogs/training/"
VALIDATION_DIR = "/tmp/cats-v-dogs/validation/"
TRAINING_CATS_DIR = os.path.join(TRAINING_DIR, "cats/")
VALIDATION_CATS_DIR = os.path.join(VALIDATION_DIR, "cats/")
TRAINING_DOGS_DIR = os.path.join(TRAINING_DIR, "dogs/")
VALIDATION_DOGS_DIR = os.path.join(VALIDATION_DIR, "dogs/")
# Empty directories in case you run this cell multiple times
if len(os.listdir(TRAINING_CATS_DIR)) > 0:
for file in os.scandir(TRAINING_CATS_DIR):
os.remove(file.path)
if len(os.listdir(TRAINING_DOGS_DIR)) > 0:
for file in os.scandir(TRAINING_DOGS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_CATS_DIR)) > 0:
for file in os.scandir(VALIDATION_CATS_DIR):
os.remove(file.path)
if len(os.listdir(VALIDATION_DOGS_DIR)) > 0:
for file in os.scandir(VALIDATION_DOGS_DIR):
os.remove(file.path)
split_size = .9
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, VALIDATION_CATS_DIR, split_size)
split_data(DOG_SOURCE_DIR, TRAINING_DOGS_DIR, VALIDATION_DOGS_DIR, split_size)
print(f"\n\nOriginal cat's directory has {len(os.listdir(CAT_SOURCE_DIR))} images")
print(f"Original dog's directory has {len(os.listdir(DOG_SOURCE_DIR))} images\n")
print(f"There are {len(os.listdir(TRAINING_CATS_DIR))} images of cats for training")
print(f"There are {len(os.listdir(TRAINING_DOGS_DIR))} images of dogs for training")
print(f"There are {len(os.listdir(VALIDATION_CATS_DIR))} images of cats for validation")
print(f"There are {len(os.listdir(VALIDATION_DOGS_DIR))} images of dogs for validation")
666.jpg is zero length, so ignoring.
11702.jpg is zero length, so ignoring.
Original cat's directory has 12500 images
Original dog's directory has 12500 images
There are 11249 images of cats for training
There are 11249 images of dogs for training
There are 1250 images of cats for validation
There are 1250 images of dogs for validation
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
batch_size=32,
class_mode='binary',
target_size=(150, 150))
validation_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
batch_size=32,
class_mode='binary',
target_size=(150, 150))
return train_generator, validation_generator
train_generator, validation_generator = train_val_generators(TRAINING_DIR, VALIDATION_DIR)
Found 22498 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1, activation='sigmoid')])
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
model = create_model()
history = model.fit(train_generator,
epochs=15,
verbose=1,
validation_data=validation_generator)
Epoch 1/15
225/704 [========>.....................] - ETA: 1:39 - loss: 0.6650 - accuracy: 0.5888
/home/eavelar/miniconda3/envs/py38_tf210/lib/python3.8/site-packages/PIL/TiffImagePlugin.py:864: UserWarning: Truncated File Read
warnings.warn(str(msg))
704/704 [==============================] - 150s 209ms/step - loss: 0.6336 - accuracy: 0.6364 - val_loss: 0.5526 - val_accuracy: 0.7096
Epoch 2/15
704/704 [==============================] - 143s 203ms/step - loss: 0.5767 - accuracy: 0.6973 - val_loss: 0.5100 - val_accuracy: 0.7512
Epoch 3/15
704/704 [==============================] - 143s 203ms/step - loss: 0.5477 - accuracy: 0.7235 - val_loss: 0.4912 - val_accuracy: 0.7716
Epoch 4/15
704/704 [==============================] - 143s 203ms/step - loss: 0.5360 - accuracy: 0.7315 - val_loss: 0.4807 - val_accuracy: 0.7840
Epoch 5/15
704/704 [==============================] - 142s 202ms/step - loss: 0.5215 - accuracy: 0.7437 - val_loss: 0.4802 - val_accuracy: 0.7752
Epoch 6/15
704/704 [==============================] - 141s 201ms/step - loss: 0.5105 - accuracy: 0.7507 - val_loss: 0.4404 - val_accuracy: 0.8048
Epoch 7/15
704/704 [==============================] - 141s 201ms/step - loss: 0.4984 - accuracy: 0.7592 - val_loss: 0.4170 - val_accuracy: 0.8244
Epoch 8/15
704/704 [==============================] - 141s 201ms/step - loss: 0.4839 - accuracy: 0.7683 - val_loss: 0.4079 - val_accuracy: 0.8200
Epoch 9/15
704/704 [==============================] - 142s 201ms/step - loss: 0.4707 - accuracy: 0.7780 - val_loss: 0.3711 - val_accuracy: 0.8364
Epoch 10/15
704/704 [==============================] - 141s 201ms/step - loss: 0.4644 - accuracy: 0.7838 - val_loss: 0.3790 - val_accuracy: 0.8400
Epoch 11/15
704/704 [==============================] - 142s 202ms/step - loss: 0.4507 - accuracy: 0.7902 - val_loss: 0.3465 - val_accuracy: 0.8508
Epoch 12/15
704/704 [==============================] - 142s 202ms/step - loss: 0.4431 - accuracy: 0.7982 - val_loss: 0.3653 - val_accuracy: 0.8444
Epoch 13/15
704/704 [==============================] - 143s 203ms/step - loss: 0.4388 - accuracy: 0.7977 - val_loss: 0.3633 - val_accuracy: 0.8416
Epoch 14/15
704/704 [==============================] - 139s 197ms/step - loss: 0.4306 - accuracy: 0.8047 - val_loss: 0.3755 - val_accuracy: 0.8424
Epoch 15/15
704/704 [==============================] - 140s 199ms/step - loss: 0.4267 - accuracy: 0.8068 - val_loss: 0.4265 - val_accuracy: 0.8216
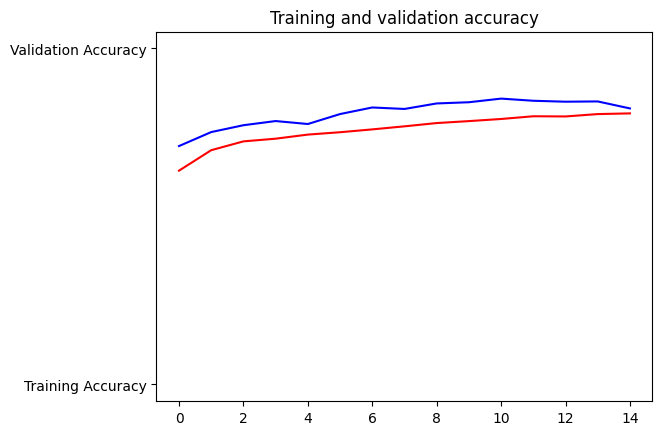
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
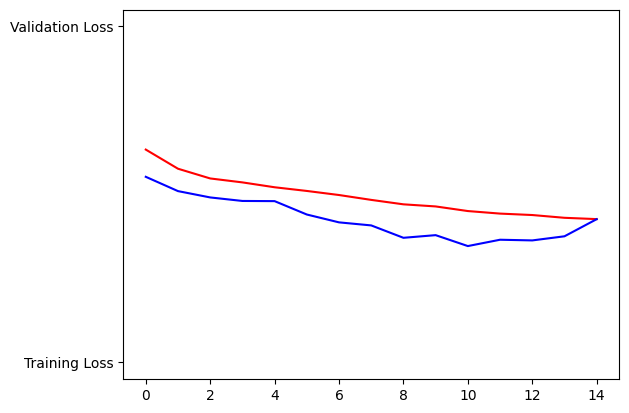
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot(epochs, acc, 'r', "Training Accuracy")
plt.plot(epochs, val_acc, 'b', "Validation Accuracy")
plt.title('Training and validation accuracy')
plt.show()
print("")
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot(epochs, loss, 'r', "Training Loss")
plt.plot(epochs, val_loss, 'b', "Validation Loss")
plt.show()