Prediction using Vertex AI pipelines

In this lesson, we described and create a Vertex AI pipeline.

A pipeline is composed of modular pieces of components chained together to form a pipeline.
Essentially a machine learning pipeline lets you automate the ML workflow including every step it takes to produce a machine learning model.
These multiple steps are code-based and sequential and do everything from data extraction, data preprocessing, model training, model evaluation, model deployment and retraining.
In order for your ML pipeline to work well in production, the components must be orchestrated, which means the dependencies and dataflow between them must be coordinated on some schedule or synchronized in some way and regularly updated, particularly if the data is very dynamic.
This practice is known as machine learning orchestration.

Vertex AI pipelines are portable and scalable ML workflows that are based on containers and Google Cloud services.
Vertex AI pipelines can run pipelines built using the Kubeflow pipeline’s SDK or TensorFlow Extended.

If you use TensorFlow in an ML workflow that processes terabytes of structured data or text data, we recommend that you build your pipeline using TFX.
For other use cases, we recommend that you build your pipeline using the Kubeflow pipeline’s SDK.
To orchestrate your ML workflow on Vertex AI pipelines, you must first describe your workflow as a pipeline.
The following sample demonstrates how to use the Google Cloud Pipeline components to build a pipeline.

Here, you import Kubeflow pipelines and set up your environment variables for project ID, region and the pipeline path.
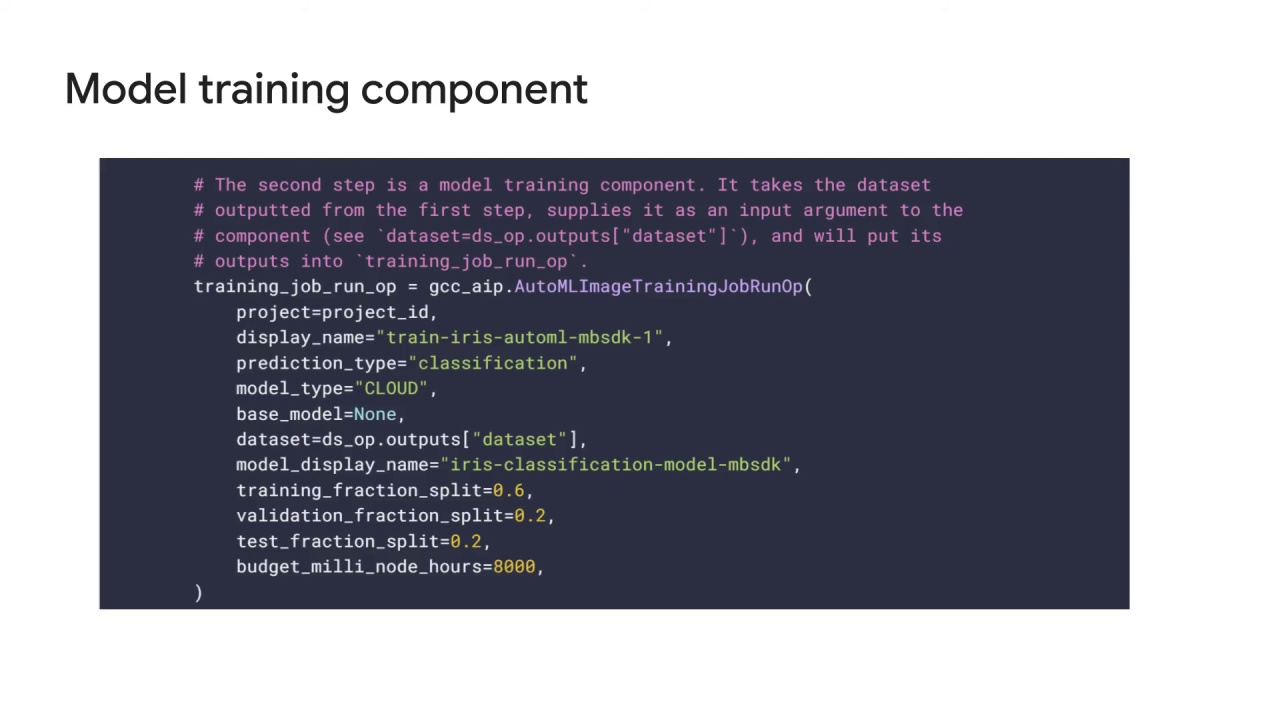
The next step is a model training component.
It takes the dataset outputted from the first step,
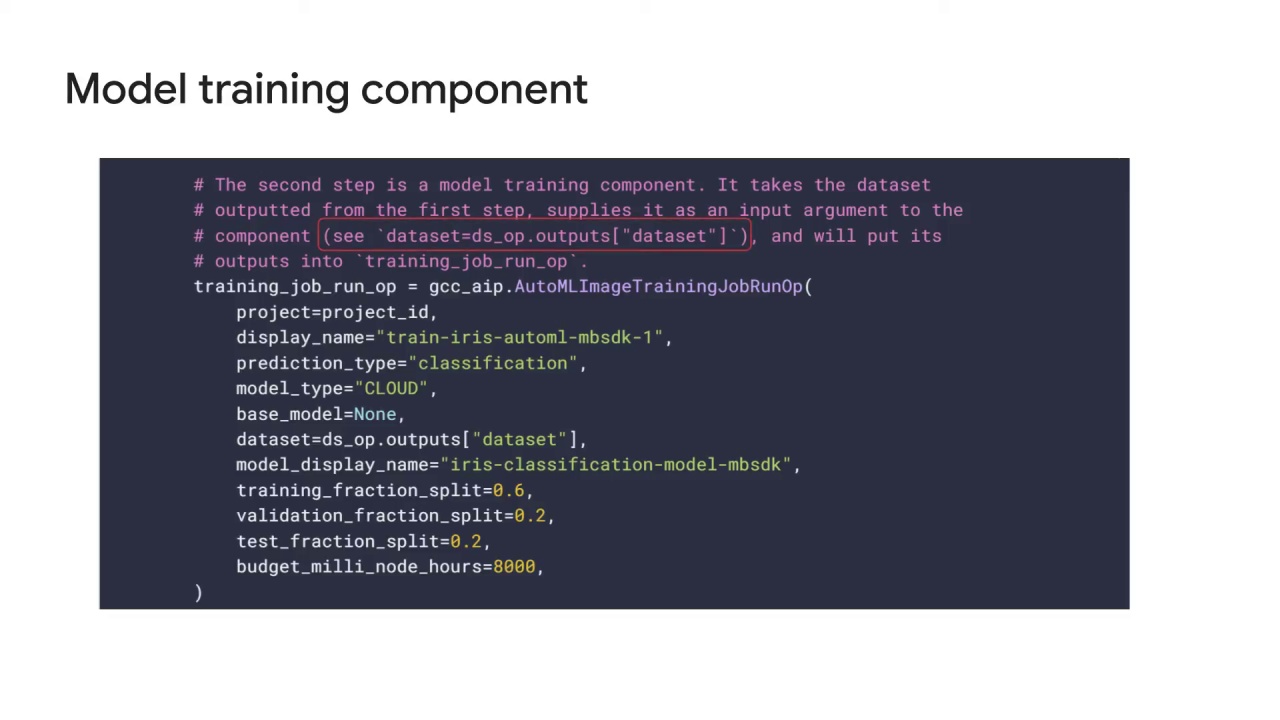
supplies it as an input argument to the component, the dataset variable shown here,
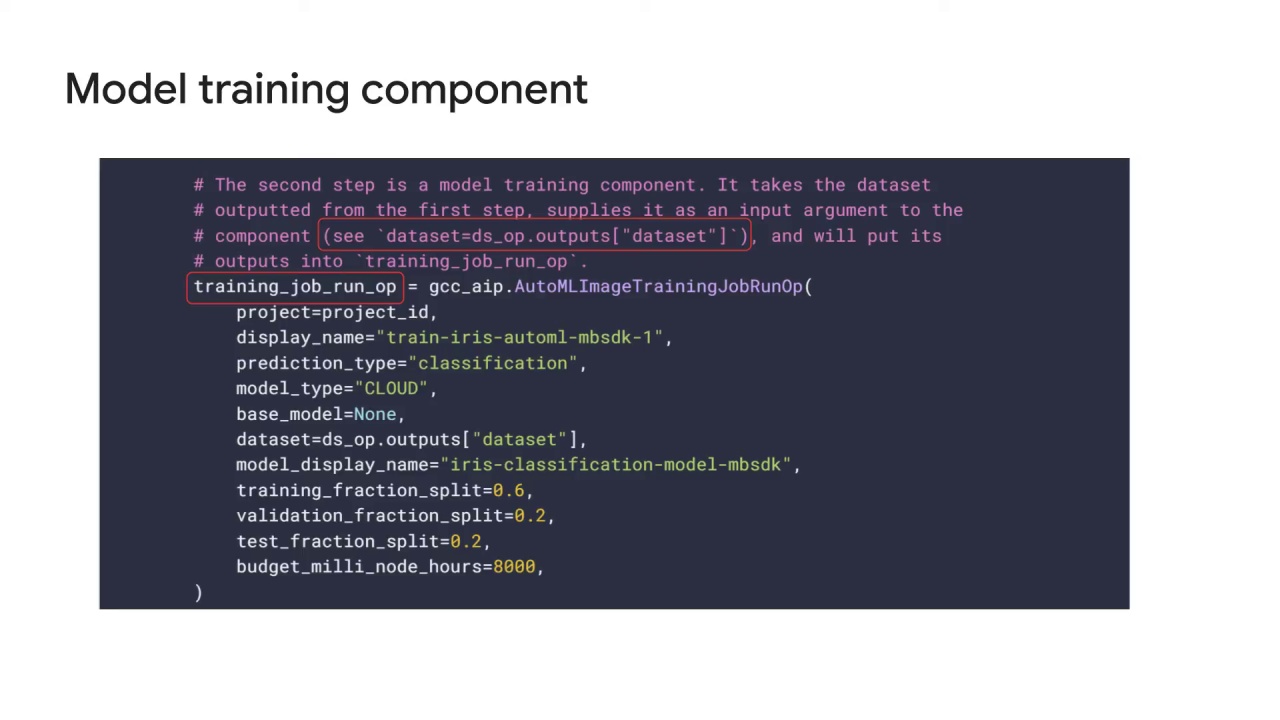
and will put its outputs into the variable training_op_run_op, also shown here.

The third and fourth steps are for deploying the model.
Here, you create an endpoint by passing in the project ID and a display name.
You then deploy the model by passing in the model output, endpoint and automatic min_replica and max_replica count.
Recall that replica_count is the minimum number of nodes for this deployment.
The node count can be increased or decreased as required by the prediction node up to the maximum number of nodes but will never fall below this number.
This value must be greater than or equal to one.
If the min_replica_count flag is omitted, the value defaults to one.
The max_replica_count is the maximum number of nodes.
If you omit the max_replica_count flag, then the maximum number of nodes is set to the value of min_replica_count.

After the workflow of your pipeline is defined, you can proceed to compile the pipeline into a JSON format.
The JSON file will include all of the information for executing your pipeline on Vertex Pipeline Services.
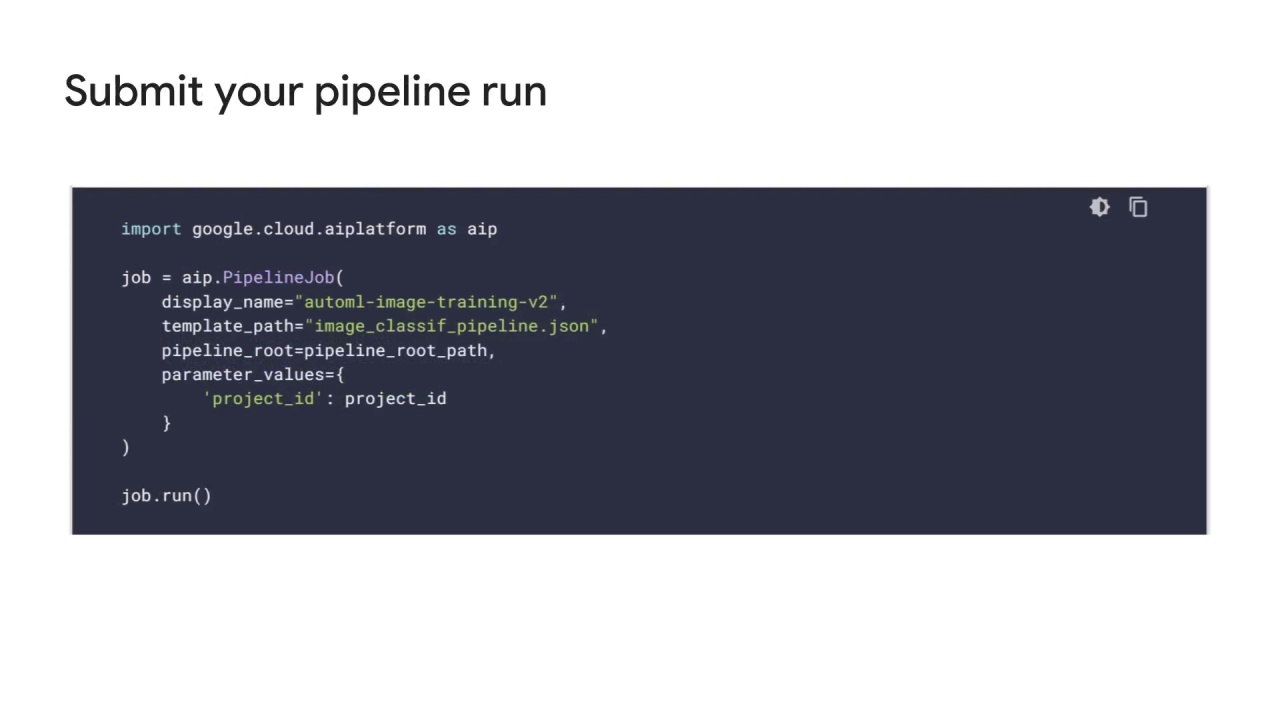
Once the workflow of your pipeline is compiled into the JSON format, you can use the Vertex AI Python client to submit and run your pipeline.