Parameter server strategy
Earlier we explored the asynchronous parameter server architecture.
A parameter server training cluster consists of workers and parameter servers.
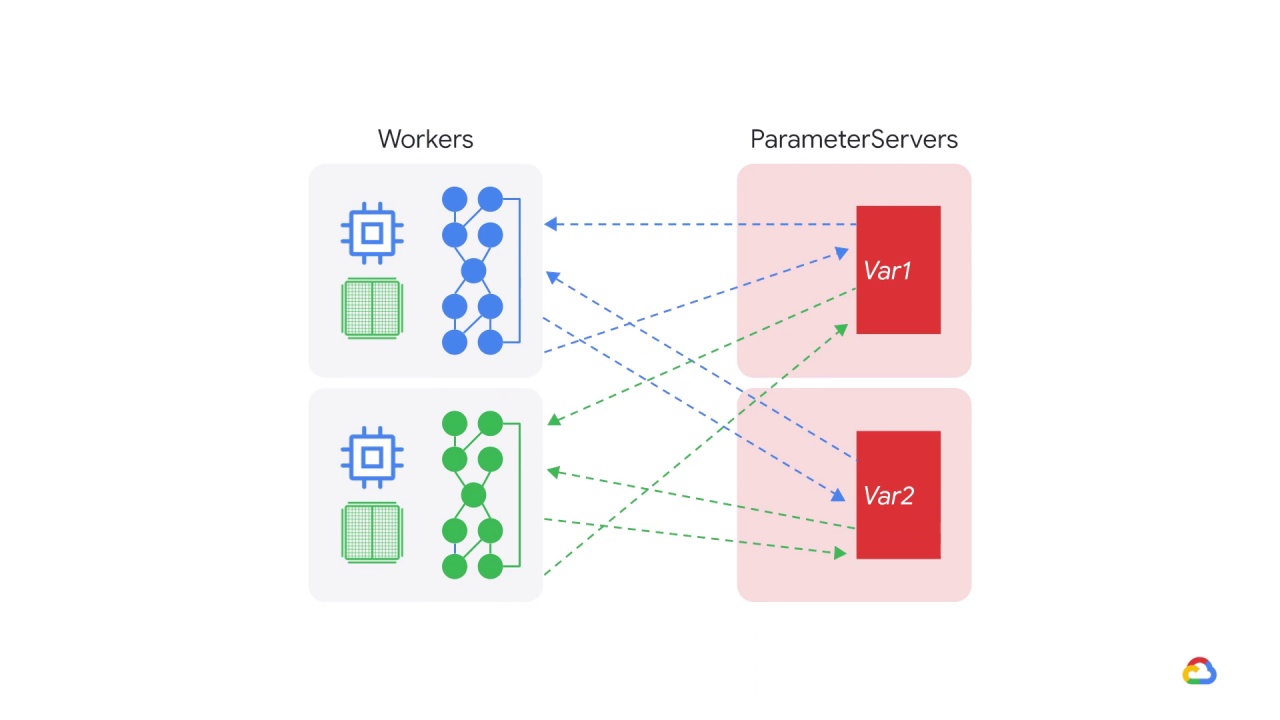
Variables are created on parameter servers and they are read and updated by workers in each step.
By default, workers read and update these variables independently without synchronizing with each other.
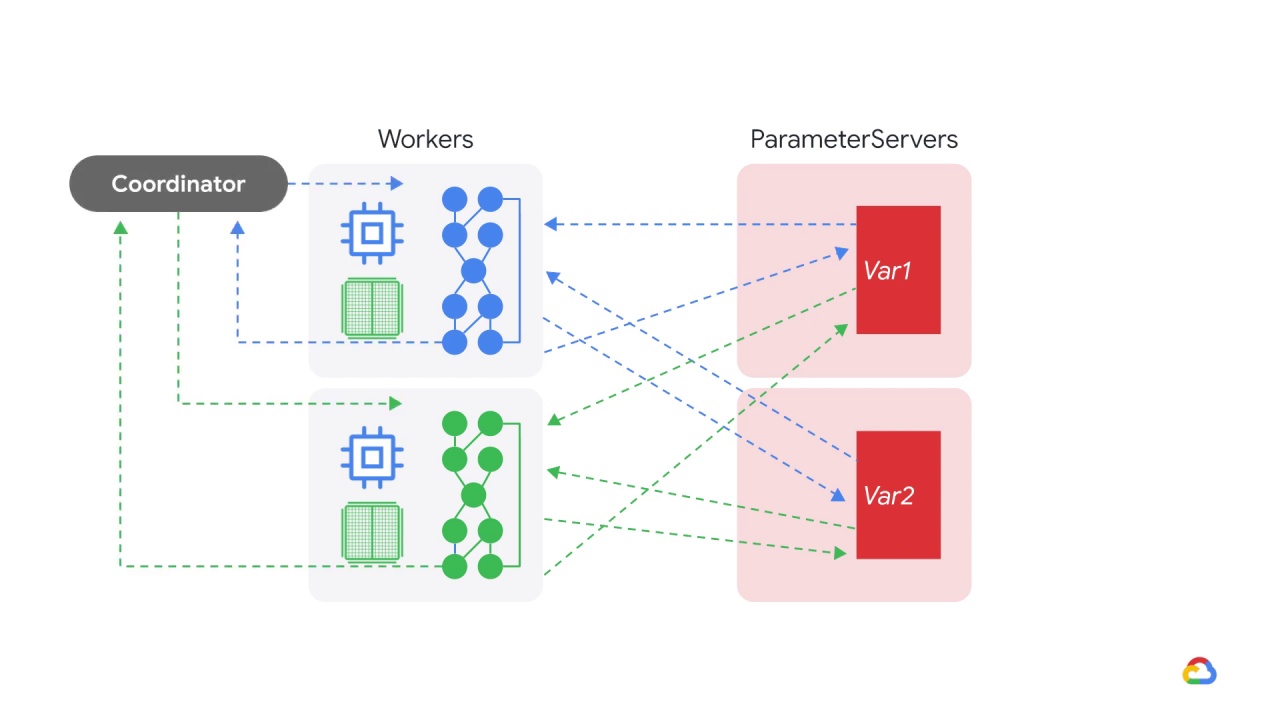
The TensorFlow parameter server strategy, introduces a central coordinator.
The coordinator is a special task type that creates resources, dispatches training tasks, writes checkpoints, and deals with task failures.
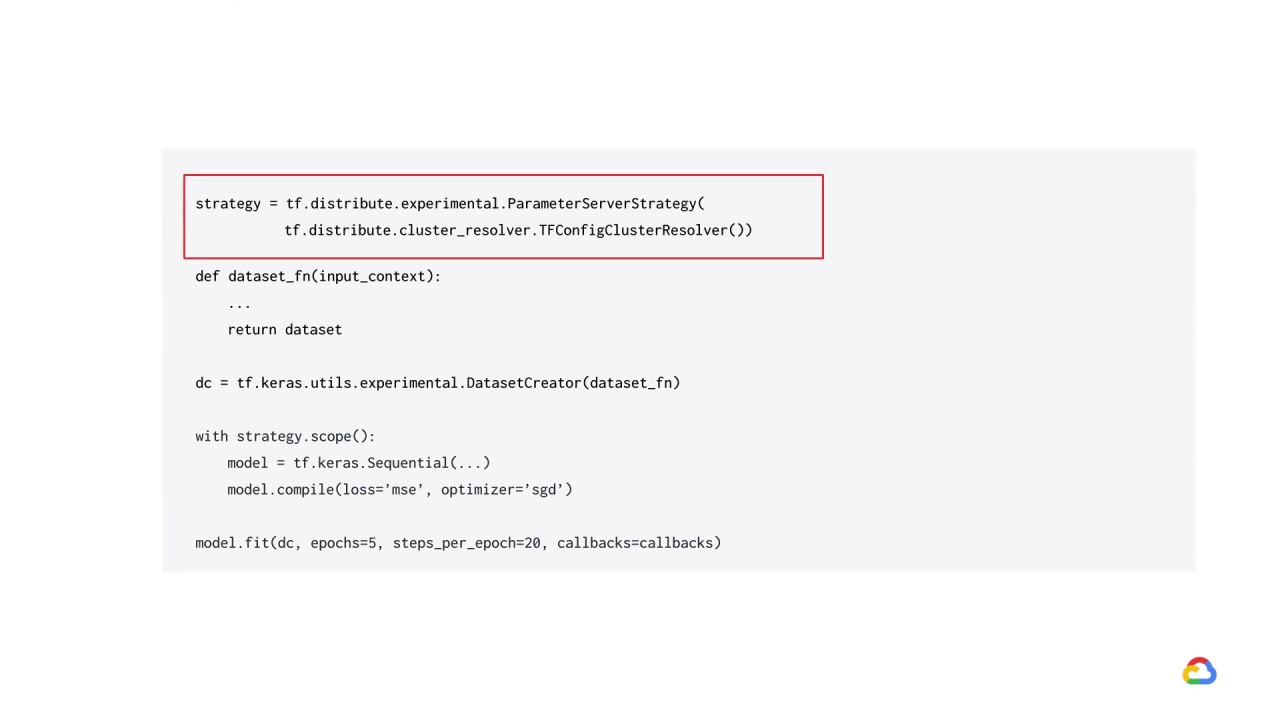
You can create your parameter server strategy object just like you would for the other strategies.
Note that you will need to pass in the cluster resolver argument and if training with AI platform, this is just a simple TFConfigClusterResolver.

Using model fit with parameter server training requires that the input data be provided in a callable object that takes a single argument of type tf.distribute.InputContext and returns a tf.data.Dataset.
We then need to wrap our dataset function in tf.keras.utils.experimental.DatasetCreator.
The code in dataset_fn will be invoked on the input device, which is usually the CPU on each of the worker machines.
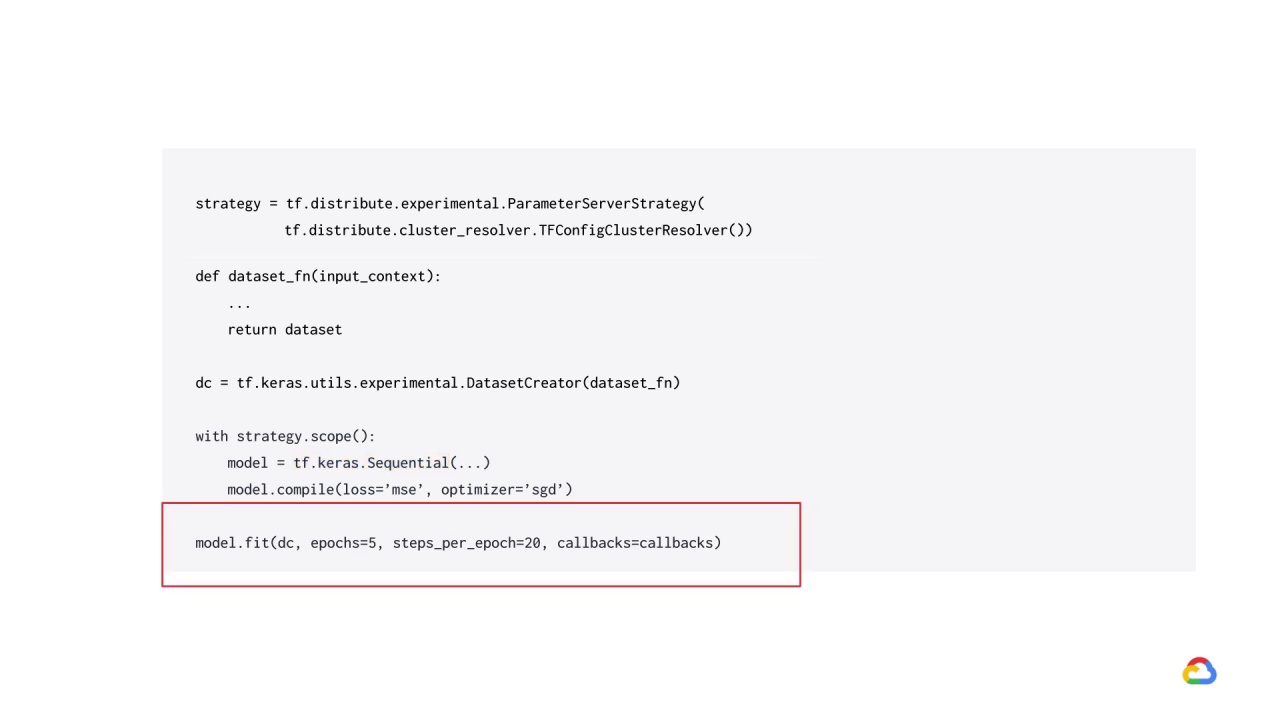
When using parameter service strategy, it is recommended that you shuffle and repeat your dataset and pass in the steps_per_epoch argument to model.fit.