Best practices for artifact organization

In this lesson, we provide an overview of best practices for artifact organization.

An artifact lineage describes all the factors that resulted in an artifact such as training data or hyperparameters used for model training.
By using artifact lineage, you can understand differences in performance or accuracy over several pipeline runs.

For example, a model’s lineage could include the following:

The training, test and evaluation data used to train the model.

The hyperparameters used during model training.

The code that was used to train the model.

Metadata recorded from the training and evaluation process, such as the model’s accuracy,

and artifacts that descend from this model, such as the results of batch predictions.
Note that each pipeline run produces metadata and ML artifacts such as models or datasets.
By using artifact lineage, you can understand differences in performance or accuracy over several pipeline runs.
Vertex ML metadata stores artifacts and metadata for pipelines run using Vertex AI pipelines.

Artifacts are outputs resulting from each step in the ML workflow.
It’s a best practice to organize them in a standardized way.
You can use Git to version control your ML pipelines and the custom components you build for those pipelines.

Use Artifact Registry to store, manage, and secure your dock of container images without making them publicly visible.

Artifacts can be organized by: source control repo location, where artifacts such as notebooks and pipeline source code can be stored;
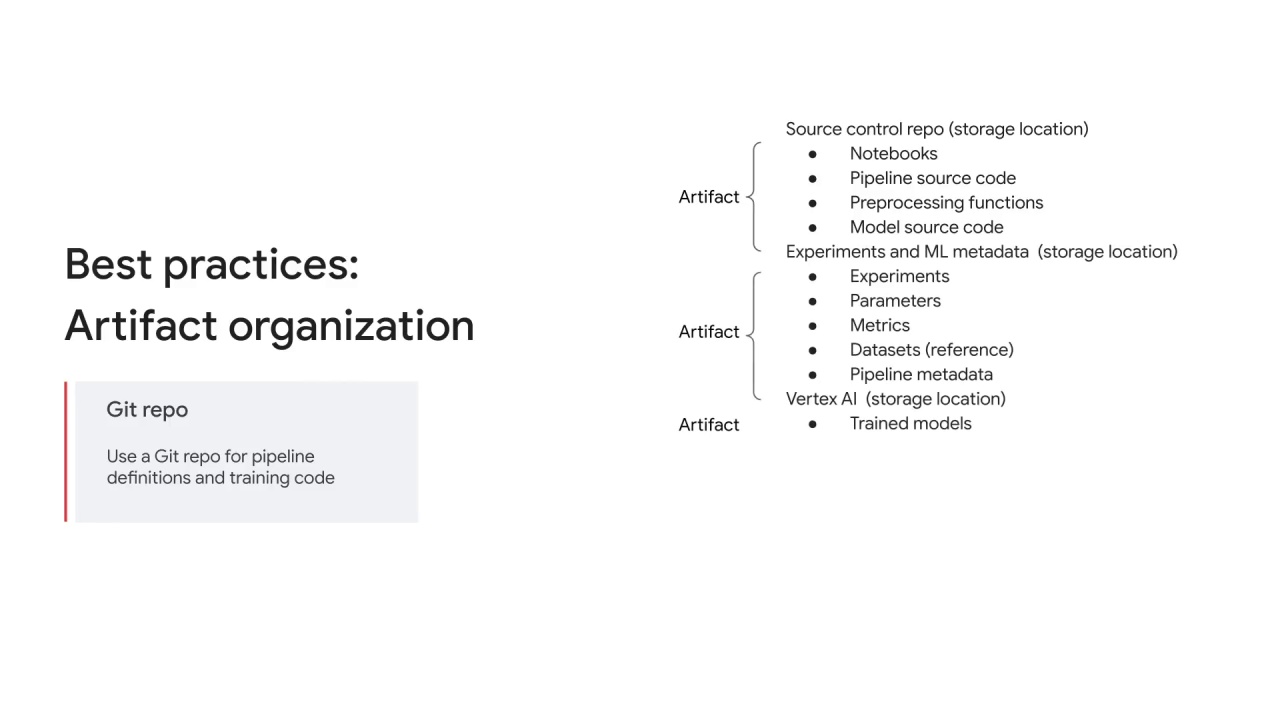
experiments and ML metadata, where artifacts such as experiments, parameters, and metrics can be stored;
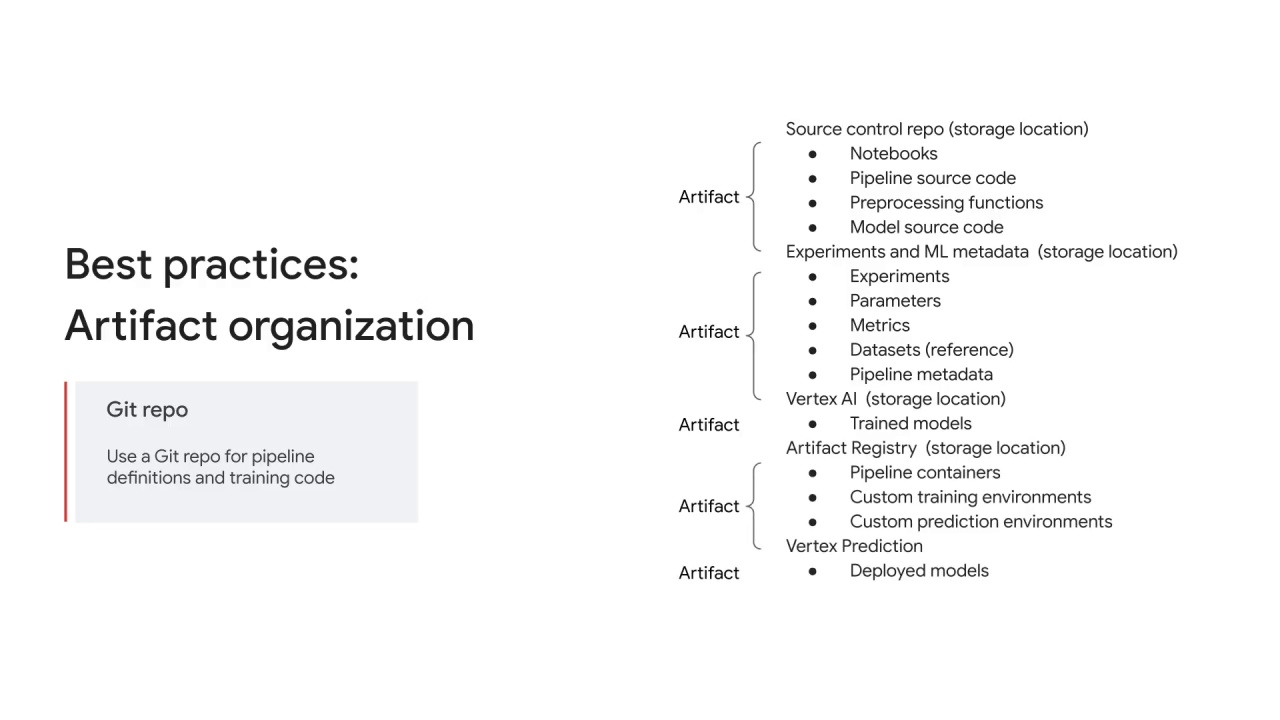
and Artifact Registry, where artifacts such as pipeline containers and custom training environments are stored.