C3W4: Predicting the next word
C3W4: Predicting the next word#
Shakespeare’s sonnets
2000 lines of text extracted from Shakespeare’s sonnets
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import layers, losses
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
dataset_path = '../../../data/sonnets.txt'
with open(dataset_path) as f:
data = f.read()
corpus = data.lower().split('\n')
print(f'{len(corpus)} lines of sonnetts')
2159 lines of sonnetts
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index)
def n_gram_seqs(corpus, tokenizer):
input_sequences = []
for line in corpus:
seq = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(seq)):
input_sequences.append(seq[:i+1])
return input_sequences
first_example_sequence = n_gram_seqs([corpus[0]], tokenizer)
print("n_gram sequences for first example look like this:")
first_example_sequence
n_gram sequences for first example look like this:
[[34, 417],
[34, 417, 877],
[34, 417, 877, 166],
[34, 417, 877, 166, 213],
[34, 417, 877, 166, 213, 517]]
next_3_examples_sequence = n_gram_seqs(corpus[1:4], tokenizer)
print("n_gram sequences for next 3 examples look like this:")
next_3_examples_sequence
n_gram sequences for next 3 examples look like this:
[[8, 878],
[8, 878, 134],
[8, 878, 134, 351],
[8, 878, 134, 351, 102],
[8, 878, 134, 351, 102, 156],
[8, 878, 134, 351, 102, 156, 199],
[16, 22],
[16, 22, 2],
[16, 22, 2, 879],
[16, 22, 2, 879, 61],
[16, 22, 2, 879, 61, 30],
[16, 22, 2, 879, 61, 30, 48],
[16, 22, 2, 879, 61, 30, 48, 634],
[25, 311],
[25, 311, 635],
[25, 311, 635, 102],
[25, 311, 635, 102, 200],
[25, 311, 635, 102, 200, 25],
[25, 311, 635, 102, 200, 25, 278]]
input_sequences = n_gram_seqs(corpus, tokenizer)
max_sequence_len = max([len(x) for x in input_sequences])
print(f"len(input_sequences): {len(input_sequences)}")
print(f"max_sequence_len: {max_sequence_len}")
len(input_sequences): 15462
max_sequence_len: 11
def pad_seqs(input_sequences, maxlen):
padded_sequences = pad_sequences(input_sequences, maxlen=maxlen)
return padded_sequences
first_padded_seq = pad_seqs(first_example_sequence, len(first_example_sequence))
first_padded_seq
array([[ 0, 0, 0, 34, 417],
[ 0, 0, 34, 417, 877],
[ 0, 34, 417, 877, 166],
[ 34, 417, 877, 166, 213],
[417, 877, 166, 213, 517]])
max_sequence_len_3 = max([len(s) for s in next_3_examples_sequence])
next_3_padded_seq = pad_seqs(next_3_examples_sequence, max_sequence_len_3)
next_3_padded_seq
array([[ 0, 0, 0, 0, 0, 0, 8, 878],
[ 0, 0, 0, 0, 0, 8, 878, 134],
[ 0, 0, 0, 0, 8, 878, 134, 351],
[ 0, 0, 0, 8, 878, 134, 351, 102],
[ 0, 0, 8, 878, 134, 351, 102, 156],
[ 0, 8, 878, 134, 351, 102, 156, 199],
[ 0, 0, 0, 0, 0, 0, 16, 22],
[ 0, 0, 0, 0, 0, 16, 22, 2],
[ 0, 0, 0, 0, 16, 22, 2, 879],
[ 0, 0, 0, 16, 22, 2, 879, 61],
[ 0, 0, 16, 22, 2, 879, 61, 30],
[ 0, 16, 22, 2, 879, 61, 30, 48],
[ 16, 22, 2, 879, 61, 30, 48, 634],
[ 0, 0, 0, 0, 0, 0, 25, 311],
[ 0, 0, 0, 0, 0, 25, 311, 635],
[ 0, 0, 0, 0, 25, 311, 635, 102],
[ 0, 0, 0, 25, 311, 635, 102, 200],
[ 0, 0, 25, 311, 635, 102, 200, 25],
[ 0, 25, 311, 635, 102, 200, 25, 278]])
input_sequences = pad_seqs(input_sequences, max_sequence_len)
print(f"padded corpus has shape: {input_sequences.shape}")
padded corpus has shape: (15462, 11)
def features_and_labels(input_sequences, total_words):
list_features = []
labels = []
for seq in input_sequences:
list_features.append(seq[:-1])
labels.append(seq[-1] - 1)
features = np.array(list_features)
one_hot_labels = to_categorical(labels, num_classes=total_words)
return features, one_hot_labels
first_features, first_labels = features_and_labels(first_padded_seq, total_words)
print(f"labels have shape: {first_labels.shape}")
print("\nfeatures look like this:\n")
first_features
labels have shape: (5, 3210)
features look like this:
array([[ 0, 0, 0, 34],
[ 0, 0, 34, 417],
[ 0, 34, 417, 877],
[ 34, 417, 877, 166],
[417, 877, 166, 213]])
features, labels = features_and_labels(input_sequences, total_words)
print(f"features have shape: {features.shape}")
print(f"labels have shape: {labels.shape}")
features have shape: (15462, 10)
labels have shape: (15462, 3210)
def create_model(total_words, max_sequence_len):
embedding_dim = 100
lstm_dim = 128
model = tf.keras.Sequential([
layers.Embedding(total_words, embedding_dim, input_length=max_sequence_len),
layers.Bidirectional(layers.LSTM(lstm_dim)),
layers.Dense(total_words)
])
model.compile(optimizer='adam',
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
model = create_model(total_words, max_sequence_len-1)
history = model.fit(features, labels, epochs=50, verbose=1)
Epoch 1/50
484/484 [==============================] - 11s 12ms/step - loss: 6.8855 - accuracy: 0.0238
Epoch 2/50
484/484 [==============================] - 5s 11ms/step - loss: 6.4448 - accuracy: 0.0325
Epoch 3/50
484/484 [==============================] - 6s 12ms/step - loss: 6.2318 - accuracy: 0.0400
Epoch 4/50
484/484 [==============================] - 5s 11ms/step - loss: 5.9839 - accuracy: 0.0455
Epoch 5/50
484/484 [==============================] - 5s 11ms/step - loss: 5.7049 - accuracy: 0.0604
Epoch 6/50
484/484 [==============================] - 5s 11ms/step - loss: 5.3748 - accuracy: 0.0739
Epoch 7/50
484/484 [==============================] - 5s 10ms/step - loss: 5.0123 - accuracy: 0.0924
Epoch 8/50
484/484 [==============================] - 5s 10ms/step - loss: 4.6417 - accuracy: 0.1150
Epoch 9/50
484/484 [==============================] - 5s 10ms/step - loss: 4.2685 - accuracy: 0.1535
Epoch 10/50
484/484 [==============================] - 5s 10ms/step - loss: 3.8965 - accuracy: 0.2056
Epoch 11/50
484/484 [==============================] - 6s 11ms/step - loss: 3.5550 - accuracy: 0.2654
Epoch 12/50
484/484 [==============================] - 5s 11ms/step - loss: 3.2320 - accuracy: 0.3252
Epoch 13/50
484/484 [==============================] - 6s 11ms/step - loss: 2.9419 - accuracy: 0.3773
Epoch 14/50
484/484 [==============================] - 5s 11ms/step - loss: 2.6818 - accuracy: 0.4324
Epoch 15/50
484/484 [==============================] - 5s 11ms/step - loss: 2.4436 - accuracy: 0.4783
Epoch 16/50
484/484 [==============================] - 6s 12ms/step - loss: 2.2404 - accuracy: 0.5184
Epoch 17/50
484/484 [==============================] - 6s 13ms/step - loss: 2.0522 - accuracy: 0.5605
Epoch 18/50
484/484 [==============================] - 6s 13ms/step - loss: 1.8852 - accuracy: 0.5995
Epoch 19/50
484/484 [==============================] - 7s 14ms/step - loss: 1.7328 - accuracy: 0.6348
Epoch 20/50
484/484 [==============================] - 7s 14ms/step - loss: 1.5934 - accuracy: 0.6641
Epoch 21/50
484/484 [==============================] - 7s 14ms/step - loss: 1.4765 - accuracy: 0.6908
Epoch 22/50
484/484 [==============================] - 7s 14ms/step - loss: 1.3572 - accuracy: 0.7182
Epoch 23/50
484/484 [==============================] - 7s 15ms/step - loss: 1.2559 - accuracy: 0.7386
Epoch 24/50
484/484 [==============================] - 7s 15ms/step - loss: 1.1739 - accuracy: 0.7542
Epoch 25/50
484/484 [==============================] - 7s 14ms/step - loss: 1.0938 - accuracy: 0.7704
Epoch 26/50
484/484 [==============================] - 7s 14ms/step - loss: 1.0224 - accuracy: 0.7861
Epoch 27/50
484/484 [==============================] - 7s 14ms/step - loss: 0.9632 - accuracy: 0.7994
Epoch 28/50
484/484 [==============================] - 7s 14ms/step - loss: 0.9088 - accuracy: 0.8072
Epoch 29/50
484/484 [==============================] - 6s 13ms/step - loss: 0.8611 - accuracy: 0.8152
Epoch 30/50
484/484 [==============================] - 7s 14ms/step - loss: 0.8203 - accuracy: 0.8221
Epoch 31/50
484/484 [==============================] - 7s 14ms/step - loss: 0.7882 - accuracy: 0.8272
Epoch 32/50
484/484 [==============================] - 7s 14ms/step - loss: 0.7572 - accuracy: 0.8291
Epoch 33/50
484/484 [==============================] - 6s 13ms/step - loss: 0.7308 - accuracy: 0.8359
Epoch 34/50
484/484 [==============================] - 6s 13ms/step - loss: 0.7040 - accuracy: 0.8366
Epoch 35/50
484/484 [==============================] - 7s 13ms/step - loss: 0.6881 - accuracy: 0.8403
Epoch 36/50
484/484 [==============================] - 6s 13ms/step - loss: 0.6729 - accuracy: 0.8407
Epoch 37/50
484/484 [==============================] - 7s 14ms/step - loss: 0.6577 - accuracy: 0.8430
Epoch 38/50
484/484 [==============================] - 7s 14ms/step - loss: 0.6424 - accuracy: 0.8444
Epoch 39/50
484/484 [==============================] - 7s 14ms/step - loss: 0.6399 - accuracy: 0.8443
Epoch 40/50
484/484 [==============================] - 7s 15ms/step - loss: 0.6332 - accuracy: 0.8445
Epoch 41/50
484/484 [==============================] - 7s 14ms/step - loss: 0.6161 - accuracy: 0.8465
Epoch 42/50
484/484 [==============================] - 8s 16ms/step - loss: 0.6089 - accuracy: 0.8470
Epoch 43/50
484/484 [==============================] - 6s 13ms/step - loss: 0.6022 - accuracy: 0.8453
Epoch 44/50
484/484 [==============================] - 7s 15ms/step - loss: 0.6002 - accuracy: 0.8468
Epoch 45/50
484/484 [==============================] - 6s 13ms/step - loss: 0.5906 - accuracy: 0.8479
Epoch 46/50
484/484 [==============================] - 6s 13ms/step - loss: 0.5897 - accuracy: 0.8479
Epoch 47/50
484/484 [==============================] - 7s 14ms/step - loss: 0.5813 - accuracy: 0.8491
Epoch 48/50
484/484 [==============================] - 7s 14ms/step - loss: 0.5825 - accuracy: 0.8478
Epoch 49/50
484/484 [==============================] - 7s 14ms/step - loss: 0.5796 - accuracy: 0.8476
Epoch 50/50
484/484 [==============================] - 6s 13ms/step - loss: 0.5701 - accuracy: 0.8489
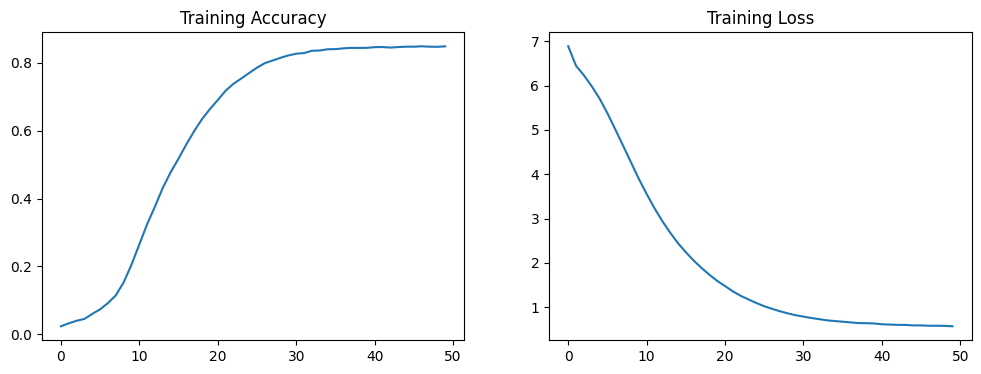
acc = history.history['accuracy']
loss = history.history['loss']
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(acc)
plt.title('Training Accuracy')
plt.subplot(1, 2, 2)
plt.plot(loss)
plt.title('Training Loss')
plt.show()
seed_text = "Help me Obi Wan Kenobi, you're my only hope"
next_words = 100
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict(token_list, verbose=0)
predicted = np.argmax(predicted, axis=-1).item() + 1
output_word = tokenizer.index_word[predicted]
seed_text += " " + output_word
print(seed_text)
Help me Obi Wan Kenobi, you're my only hope of good antique part place of me are dead dead or give none none cured thievish undivided undivided hurt or body large page page up willing ruin'd drops of friend grace to thee leave is so true aright is writ ' prove not seen decay live told to find away thee friend's rare more bright find room so more so strong report new can lose hell truth than one wrong breathers of blood ' lie in my age eye even so in my way mind much right their mind out out cheek my moan of brow myself alone had stol'n