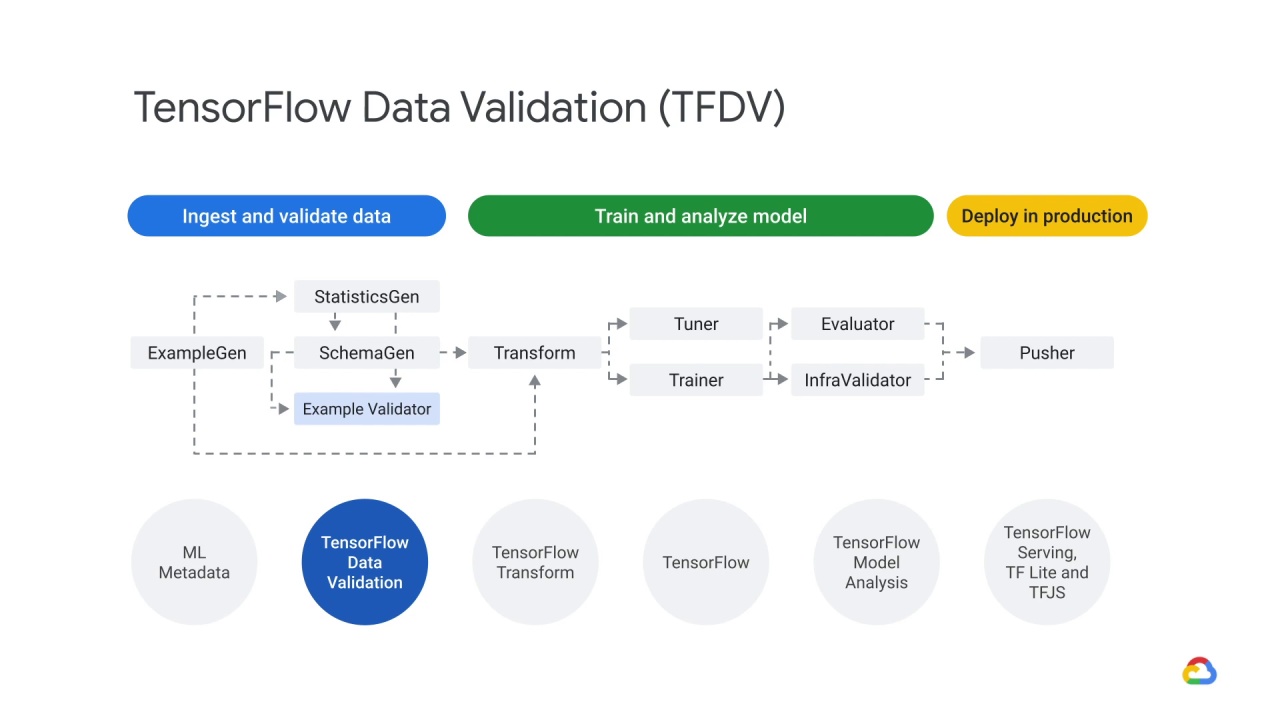
Components of TensorFlow data validation

TensorFlow Data Validation is a library for analyzing and validating machine learning data, for which there are three components:
The Statistics Generation component
The Schema Generation component

The Example Validator component
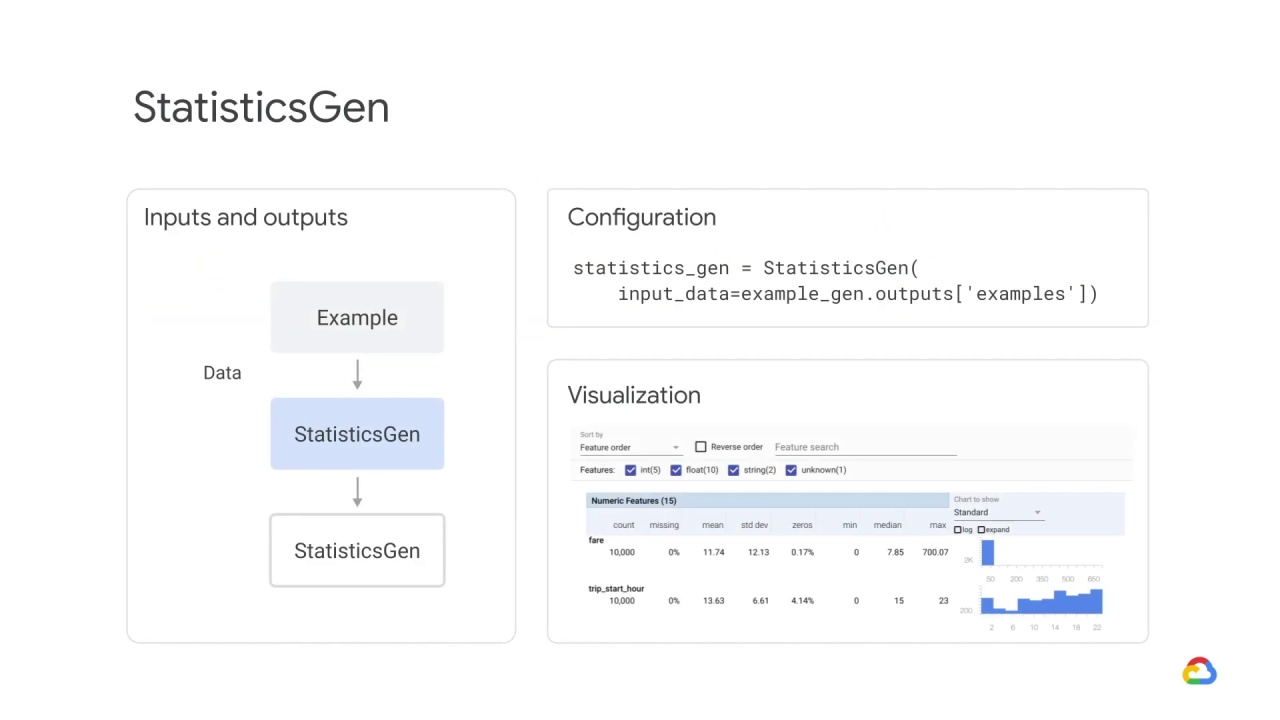
The StatisticsGen component generates features statistics and random samples over training data, which can be used for visualization and validation.
It requires minimal configuration.
For example, StatisticsGen takes as input a dataset ingested using ExampleGen.
After StatisticsGen finishes running, you can visualize the outputted statistics.

In an example using taxi data, the StatisticsGen component has generated data statistics for the numeric features.

For the trip_start_hour feature, it appears there is not that much data in the early morning hours.
It appears that the trip_start_hour column, where the time window is between 2:00am to 6:00am, has data missing.
This helps determine the area we need to focus on to fix any data-related problems.
We’ll need to get more data, otherwise, the prediction for 4:00am data will be overgeneralized.

Let’s look at another example, this time using a consumer spending score dataset.
Here we are generating statistics for both a training dataset, that may have arrived on day one, and a new dataset, that may have arrived on day two.
These statistics are being generated from a Pandas DataFrame.
You can also generate statistics from a CSV file or a TF.Record formatted file.
By comparing both datasets, you can analyze how big of a difference there is between the two, and then determine if that difference matters.

StatisticsGen generates both numeric and categorical features.
In this example, our dataset has two numerical features, Work_Experience and Family_Size.
Our dataset also has three categorical features: Graduated, Profession, and Spending_Score.
Notice that for our categorical features, in addition to seeing the number of missing values, we also see the number of unique values.
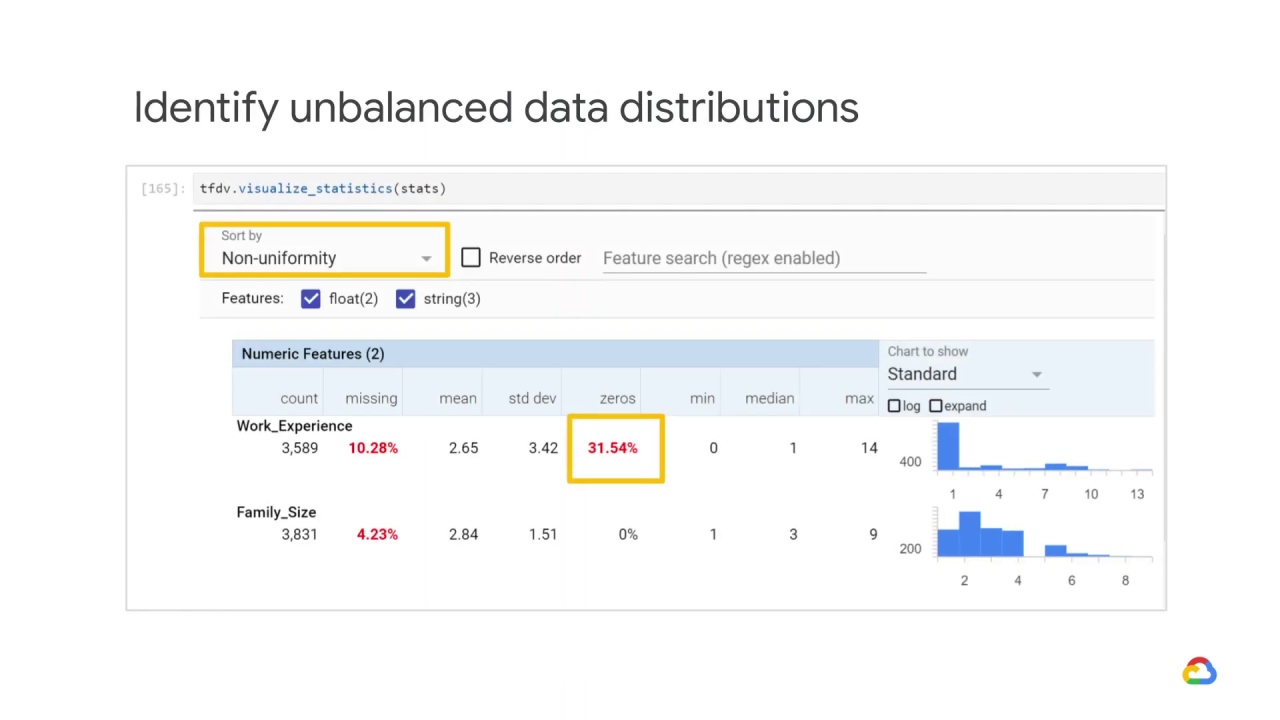
TensorFlow Data Validation can also help you identify unbalanced data distributions.
For example, if you have a dataset you are using for a classification problem and you see that one feature has a lower percentage of values than the other, you can use TensorFlow Data Validation to detect this “unbalance”.
The most unbalanced features will be listed at the top of each feature-type list.
For example, the following screenshot shows Work_Experience with zero has a data value - which means that 31.54% of the values in this feature are zeroes.
There are a number of StatisticsGen data validation checks that you should be aware of.
These include:
Feature
min,max,mean,mode, andmedian
Feature correlations
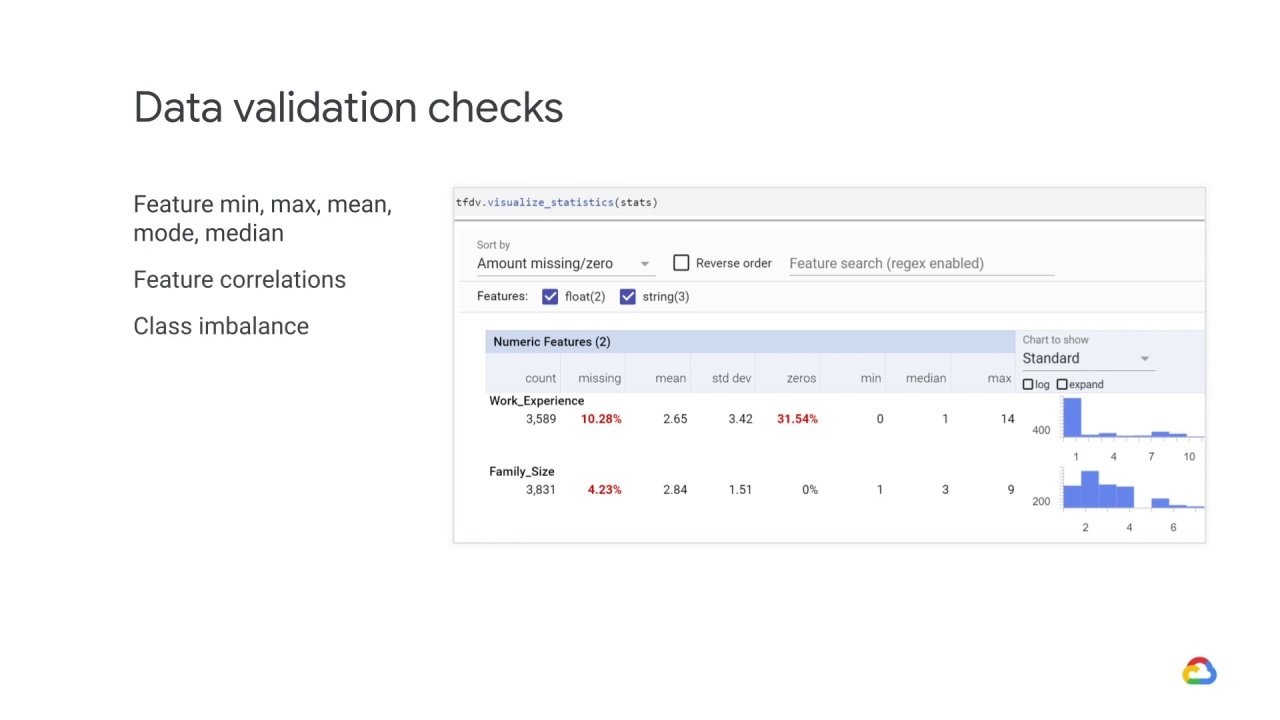
Class imbalance
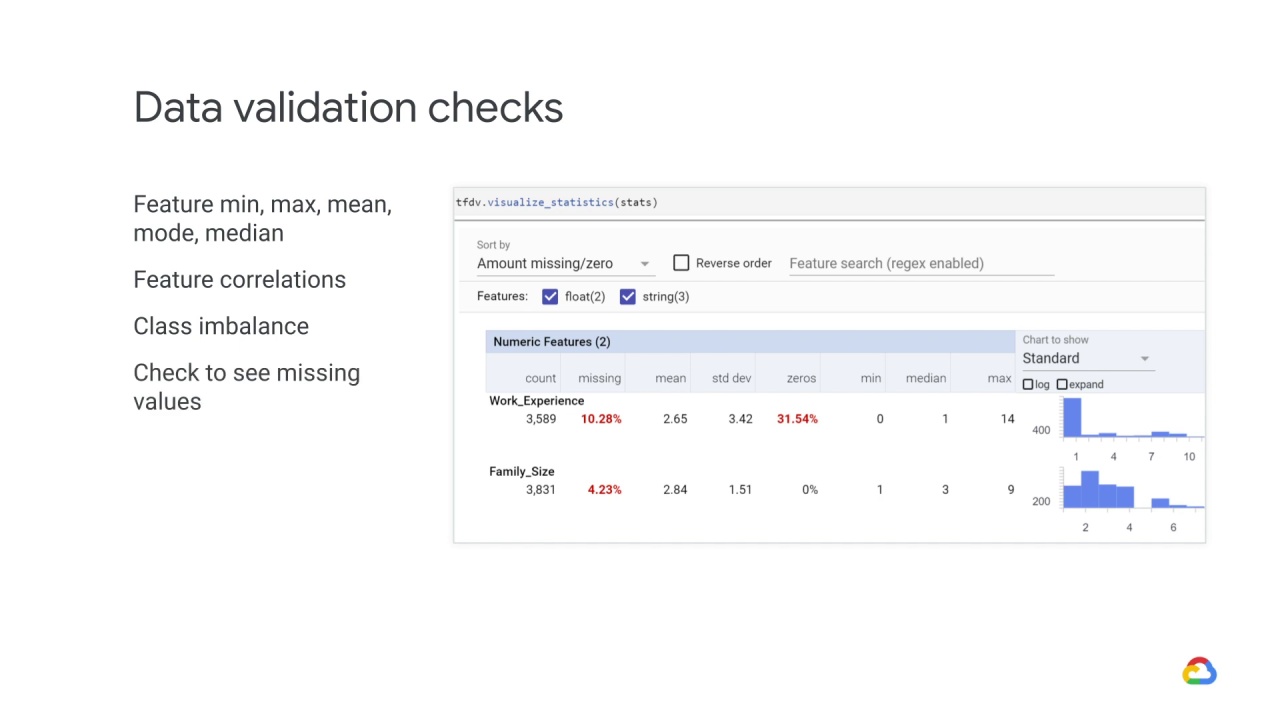
Check to see missing values
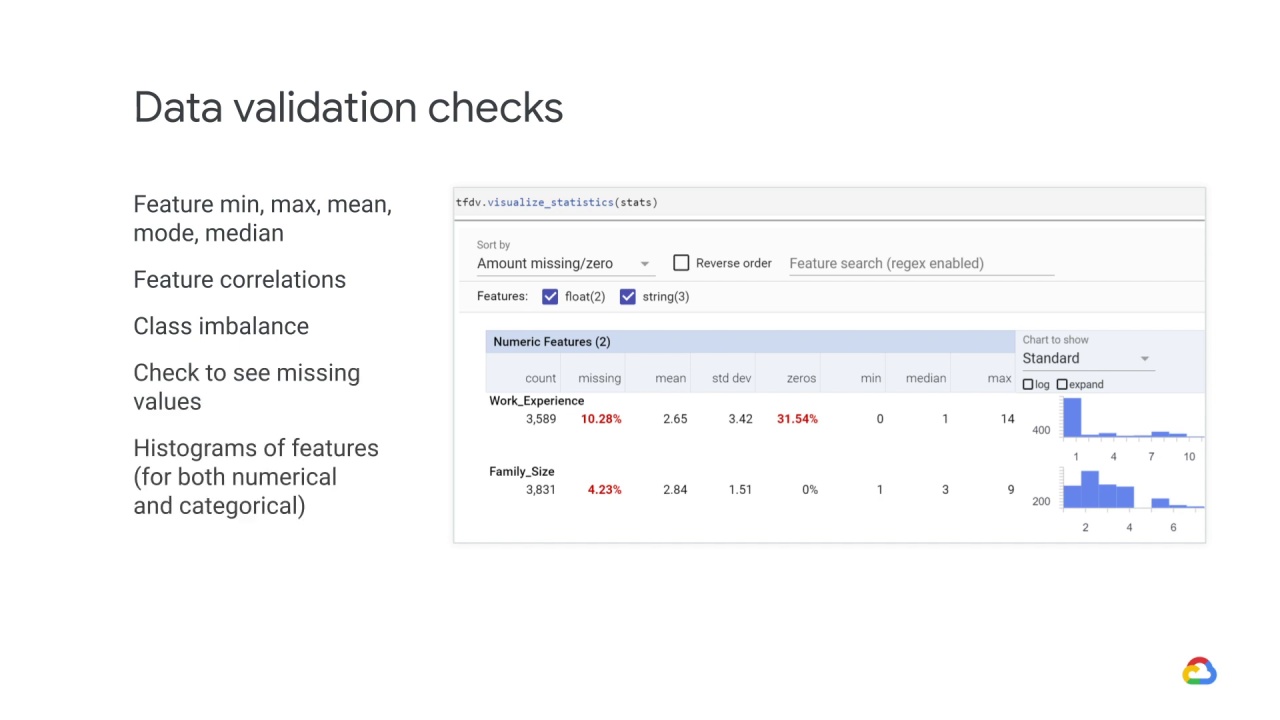
Histograms of features (for both numerical and categorical)

The SchemaGen TFX pipeline component can specify data types for feature values, whether a feature has to be present in all examples, allowed value ranges, and other properties.
A SchemaGen pipeline component will automatically generate a schema by inferring types, categories, and ranges from the training data.
In essence, SchemaGen is looking at the data type of the input, is it an int, float, categorical, etc.
If it is categorical then what are the valid values?
It also comes with a visualization tool to review the inferred schema and fix any issues.

In this example visualization:

Type indicates the feature datatype.
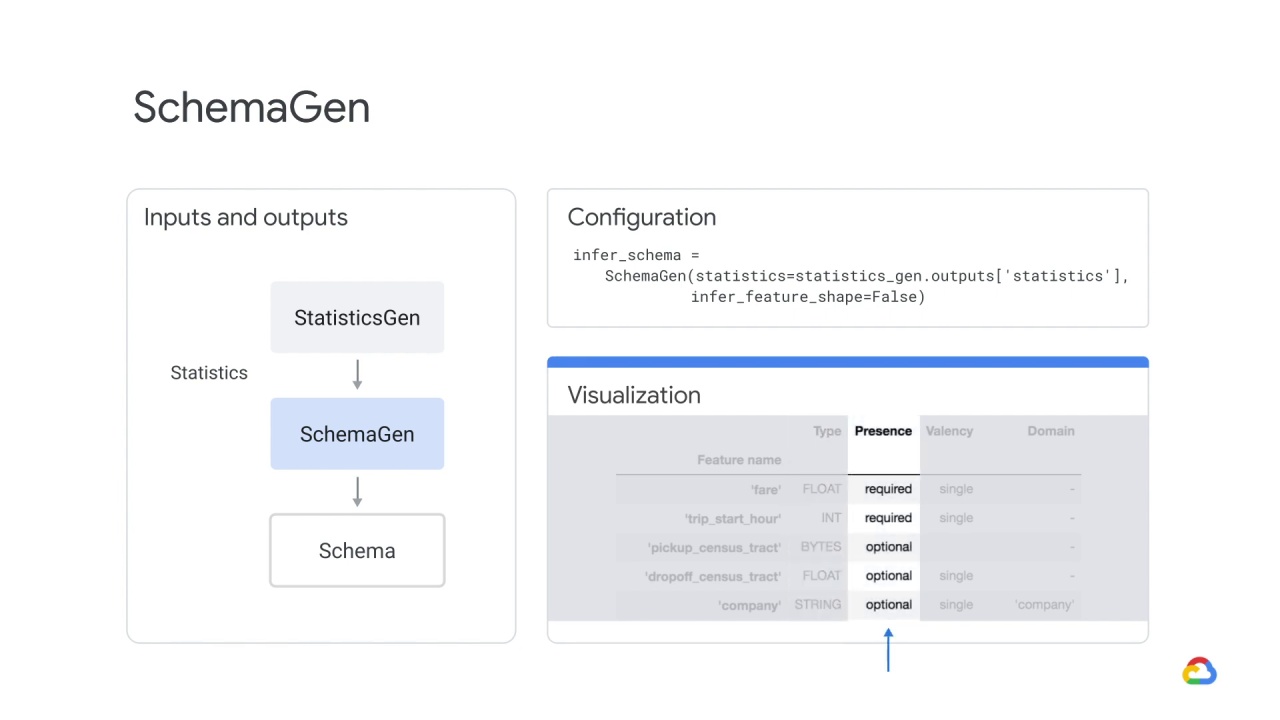
Presence indicates whether the feature must be present in 100% of examples (required) or not (optional).
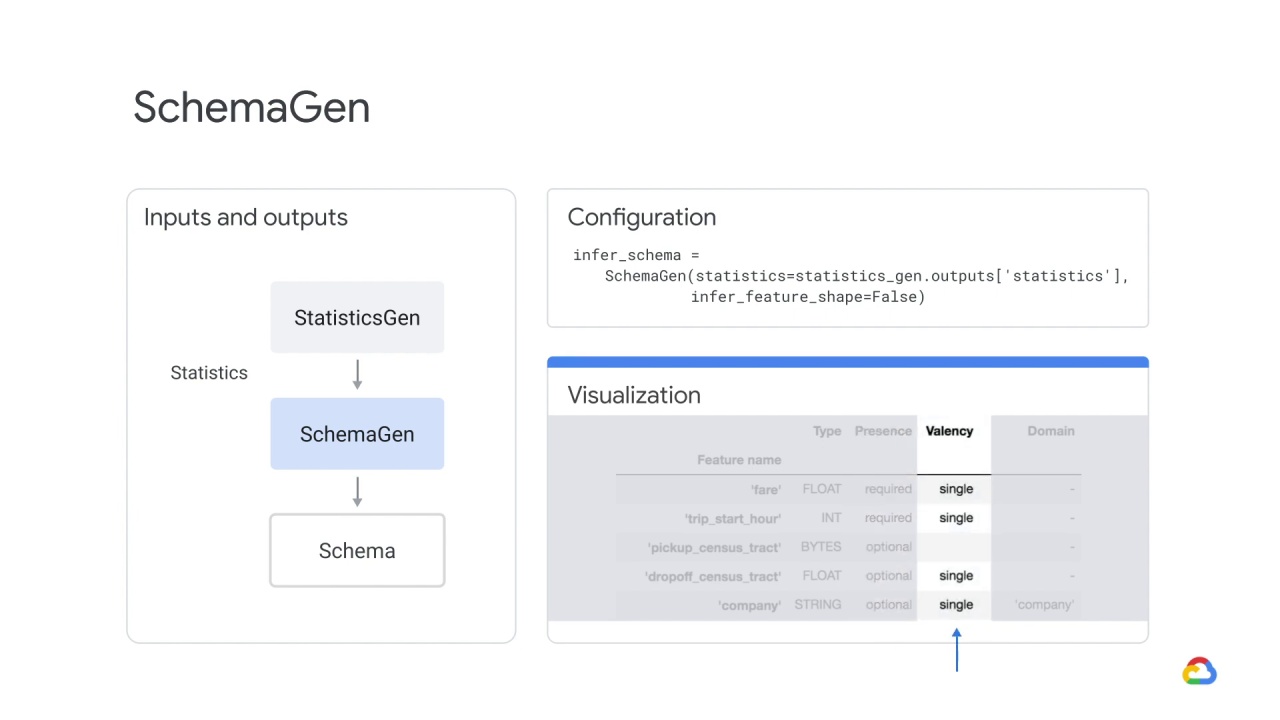
Valency indicates the number of values required per training example.
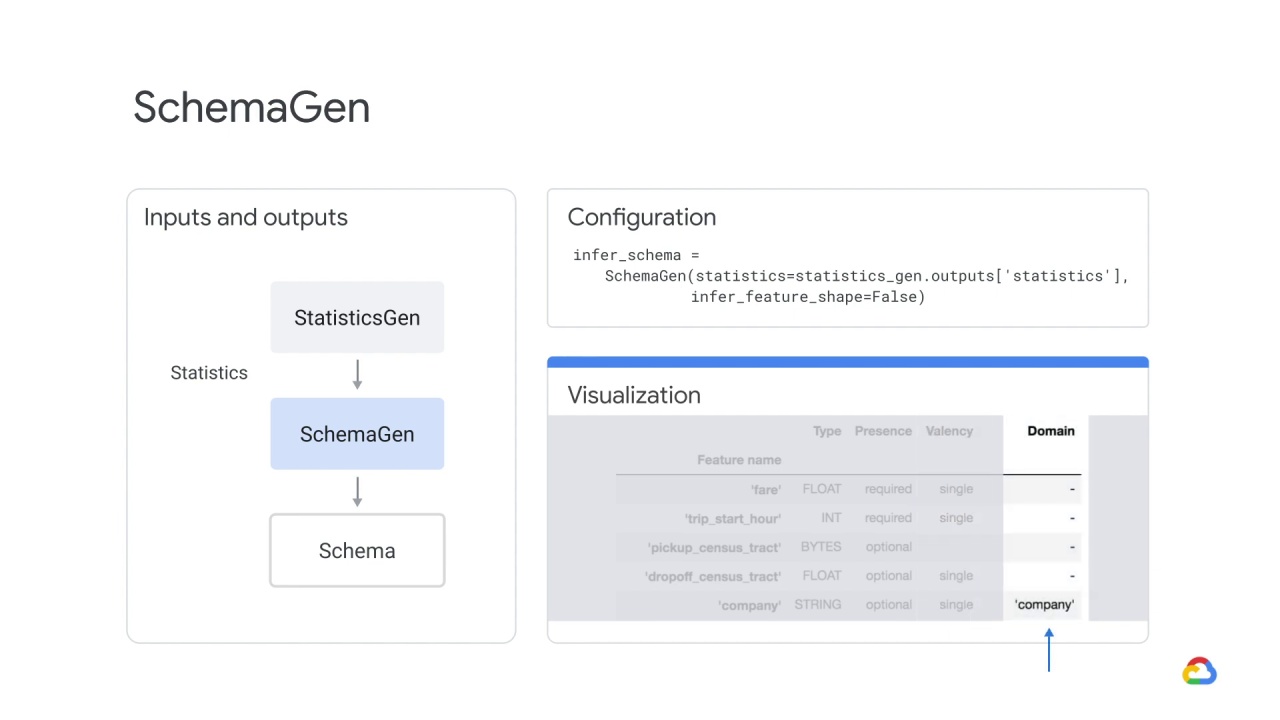
Domain and Values indicates the feature domain and its values.
In the case of categorical features, single indicates that each training example must have exactly one category for the feature.

The ExampleValidator pipeline component identifies anomalies in training and serving data.
It can detect different classes of anomalies in the data and emit validation results.
The ExampleValidator pipeline component identifies any anomalies in the example data by comparing data statistics computed by the StatisticsGen pipeline component against a schema.
It takes the inputs and looks for problems in the data, like missing values, and reports any anomalies.
As we’ve explored, TensorFlow Data Validation is a component of TensorFlow Extended and it helps you to analyze and validate your data.
Data validation checks include identifying feature correlations, checking for missing values, and identifying class imbalances.