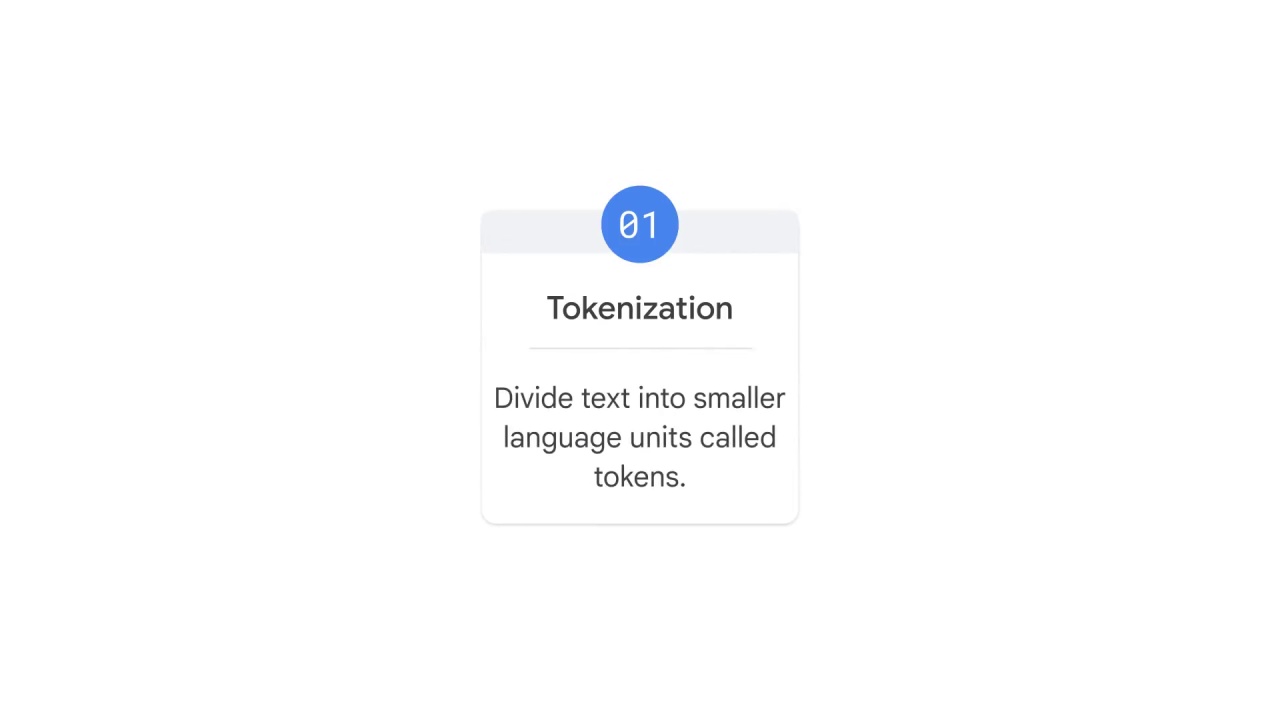
Tokenization
You may recall the end-to-end NLP workflow and the three major stages in developing an NLP project:
data preparation,
model training,
model serving
In the first stage of data preparation, you must engineer the data for model training.
As you know, a computer only takes digits
and you can only feed an NLP model with numbers.
Here, you encounter a significant challenge for NLP:

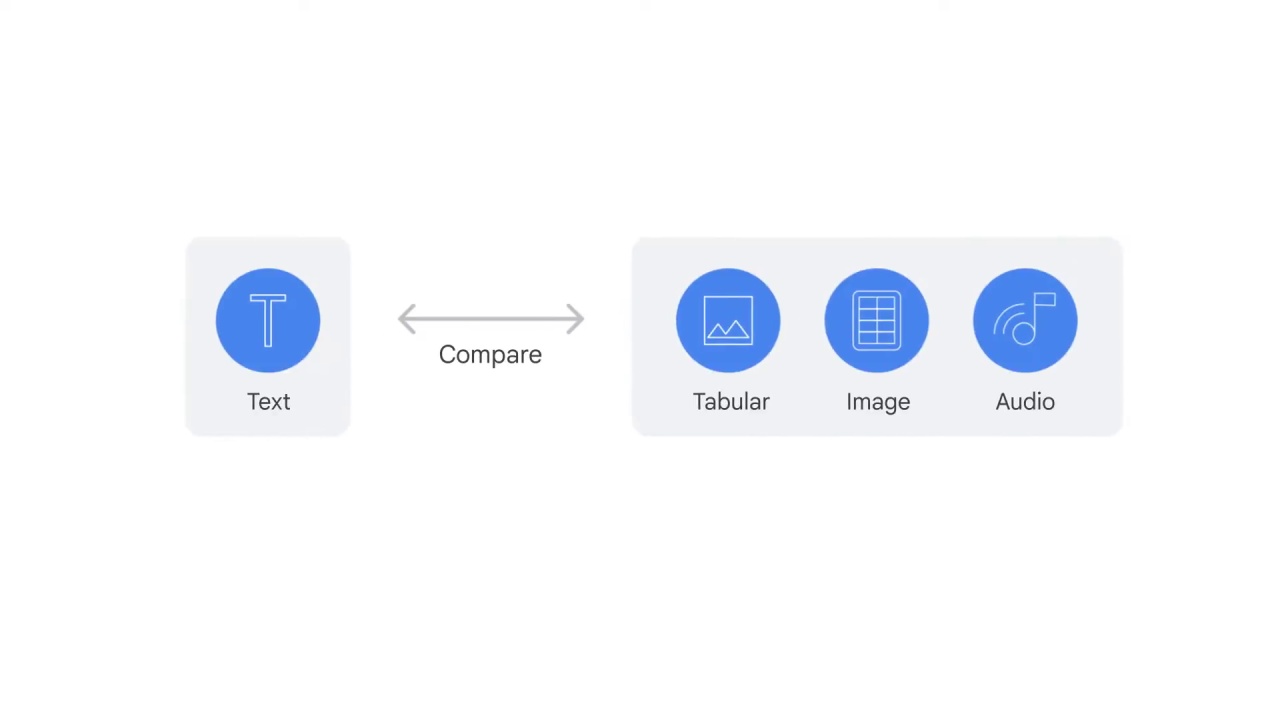
To better understand the challenge of text representation in NLP, let’s compare text data with other data types such as tabular, image, and audio.
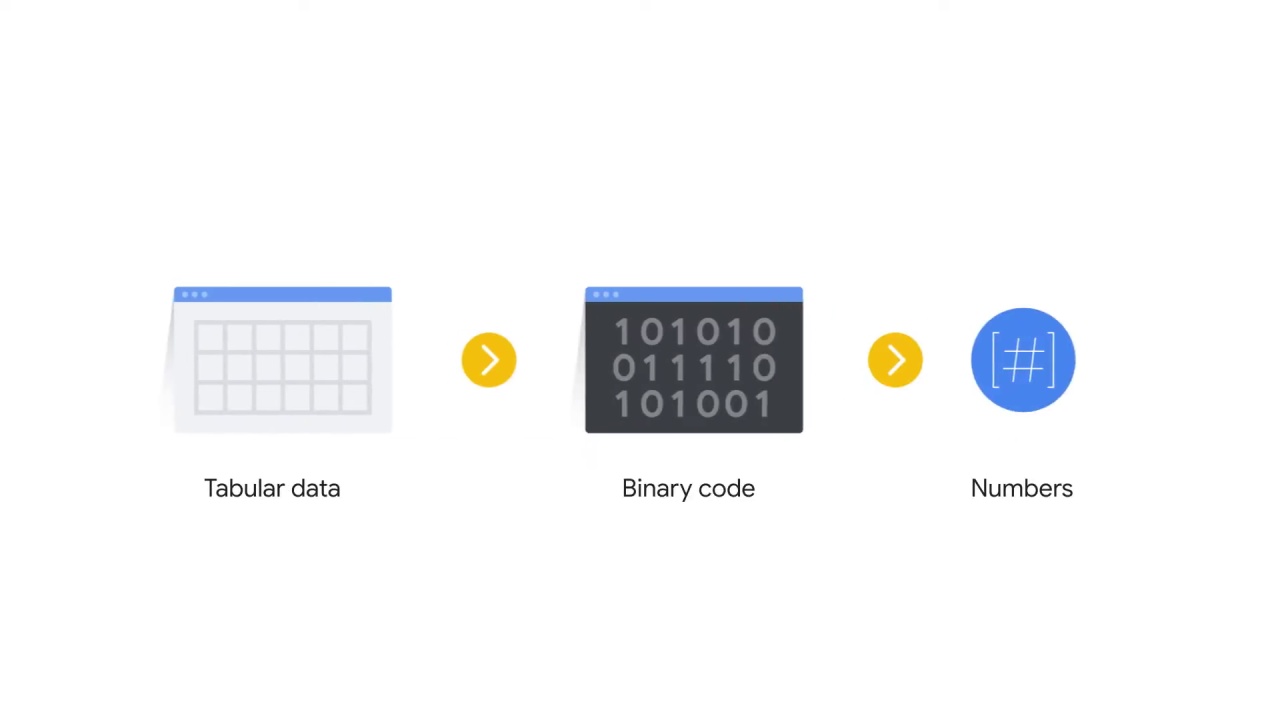
Tabular data might be the easiest to feed into an ML model because most of them is already numeric, and the columns which are not numbers can be easily converted into numeric values.

How about image data?
How can you convert an image into numbers?
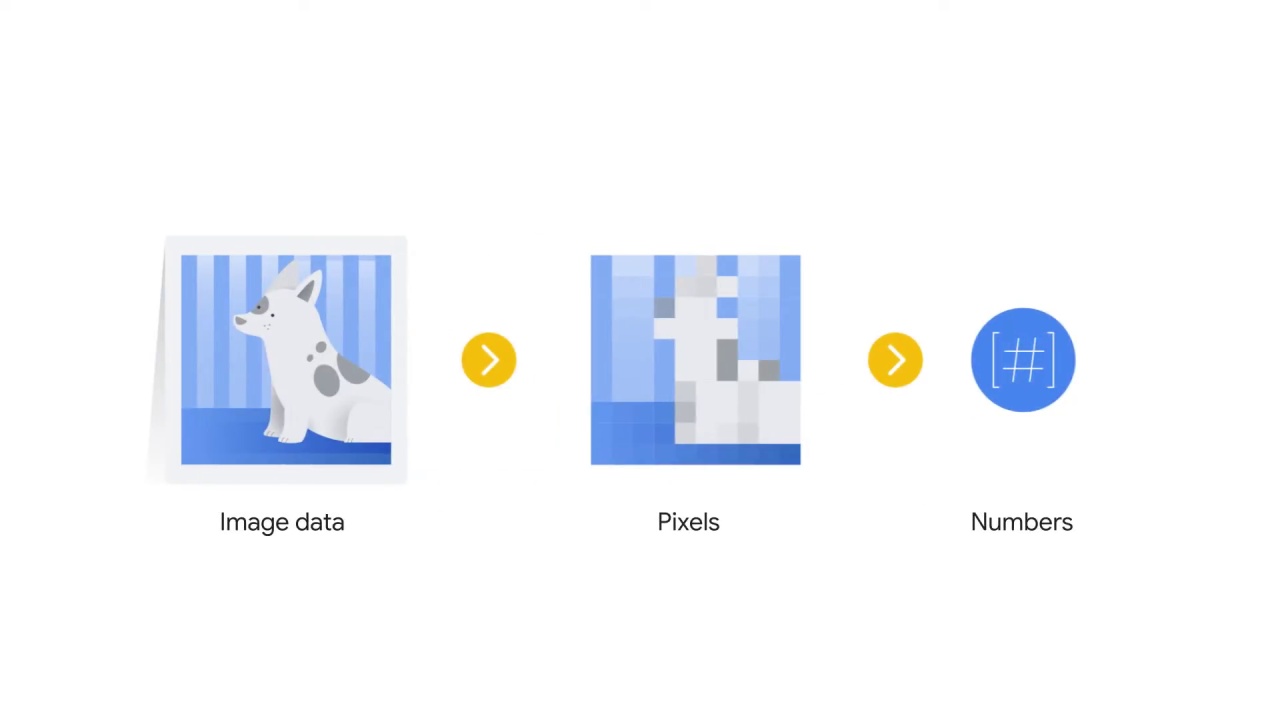
You can take advantage of pixels.
Each cell in the matrix of pixels represents the intensity of the corresponding pixel in the image.

How about audio?
How do you convert a song into numbers?

You can use waves.
You can sample the wave and record its amplitude (the height).
The audio then can be represented by an array of amplitude at fixed-time intervals.
How about text?
Can you think of a way to turn a sentence into numbers?
The answer is not that obvious.
Well, let’s divide the feature engineering in NLP into smaller steps.
Please note:
___ You must call the right functions at the right time.
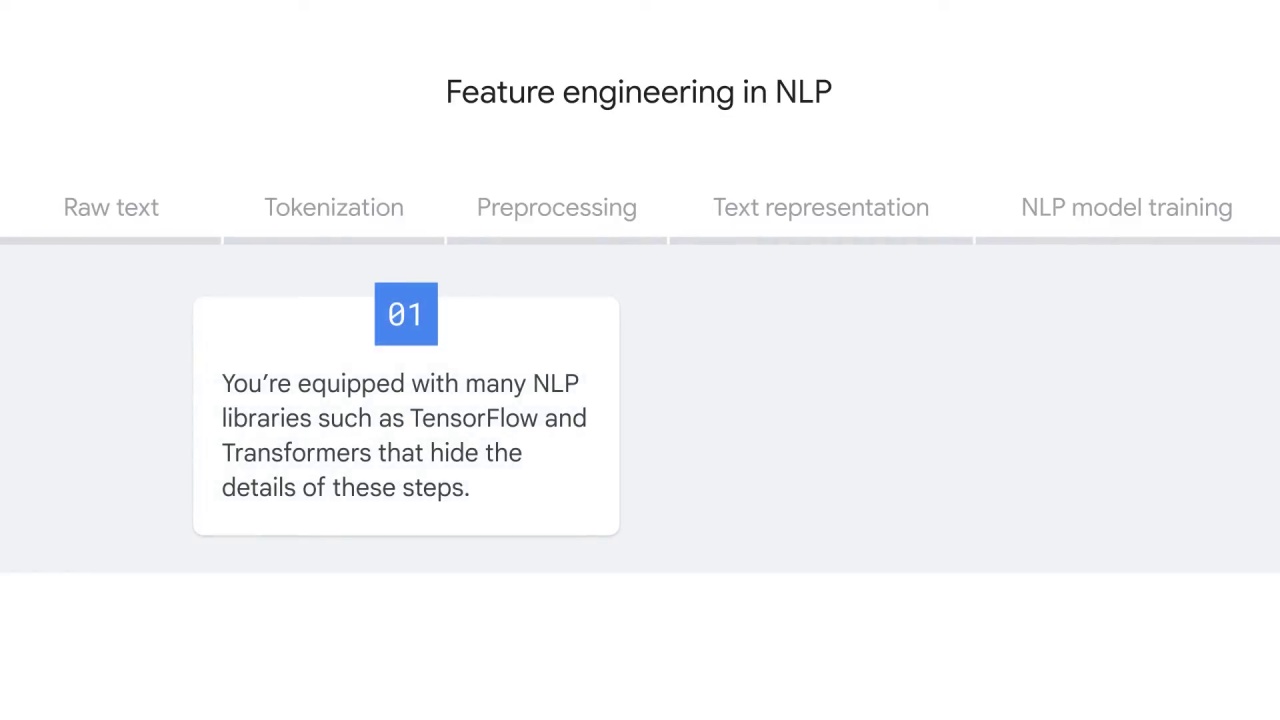
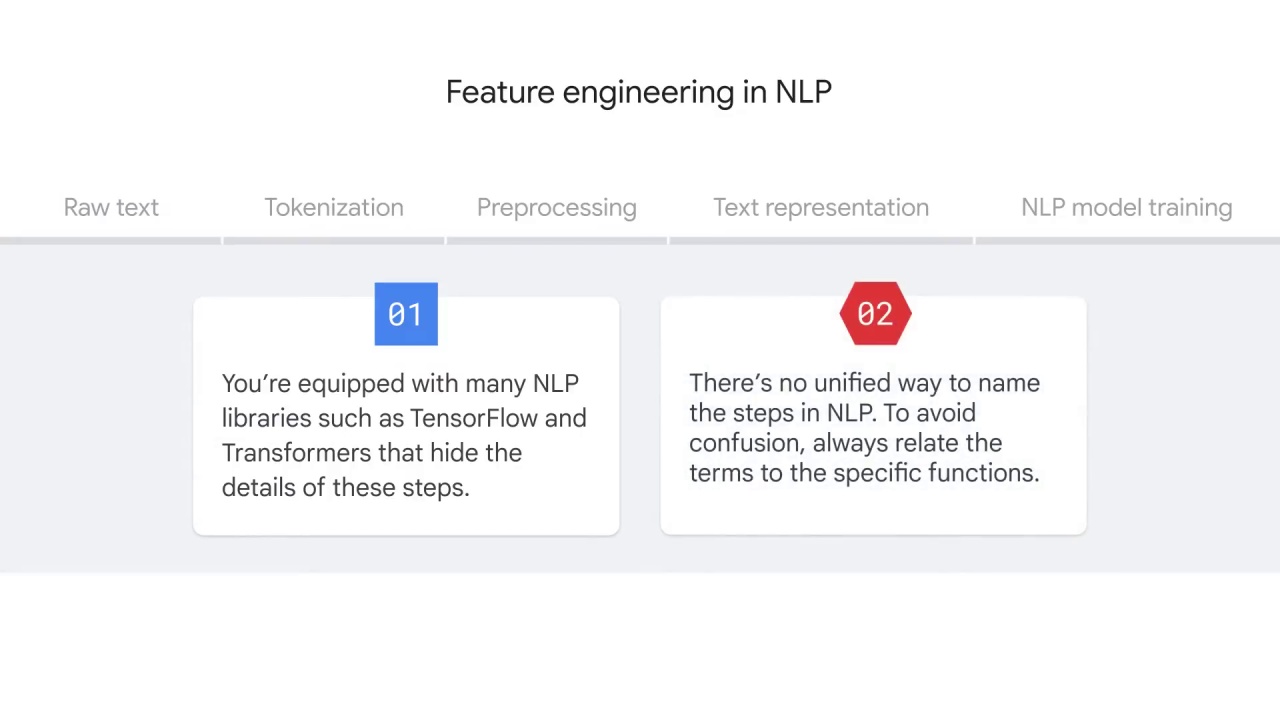
The following explanation is to uncover how these libraries work and assumes you might want to build your own NLP applications from the beginning.
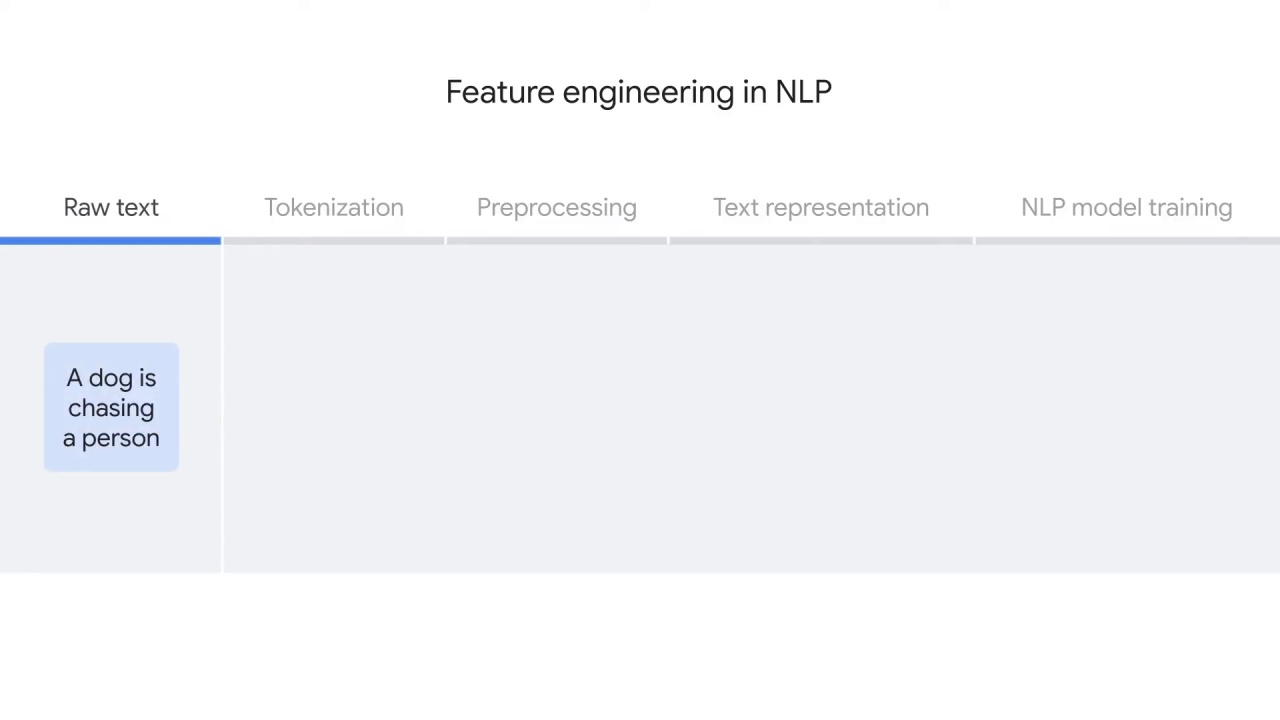
Assuming you already uploaded raw text,

You’ll then tokenize the text, which basically means to divide the text into smaller language units such as words.
This is how a computer reads text.
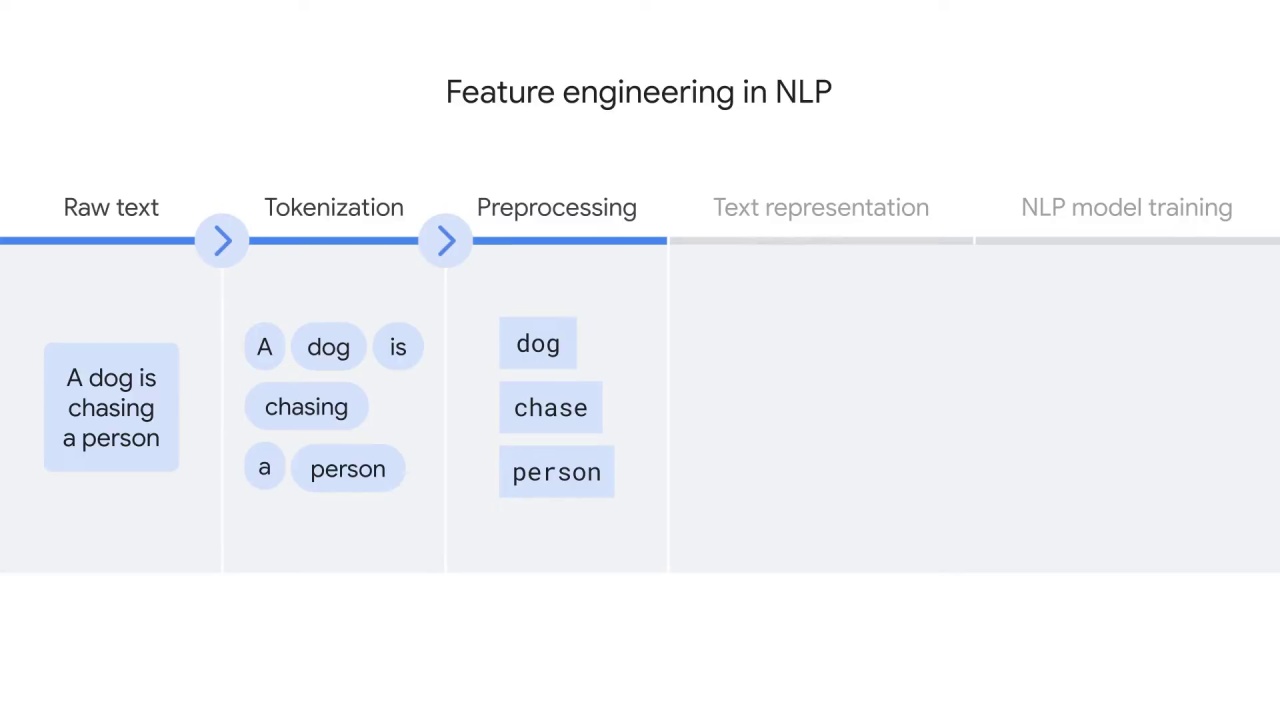
After that, you’ll preprocess the language units, for example, by only keeping the root of each word and removing punctuation.
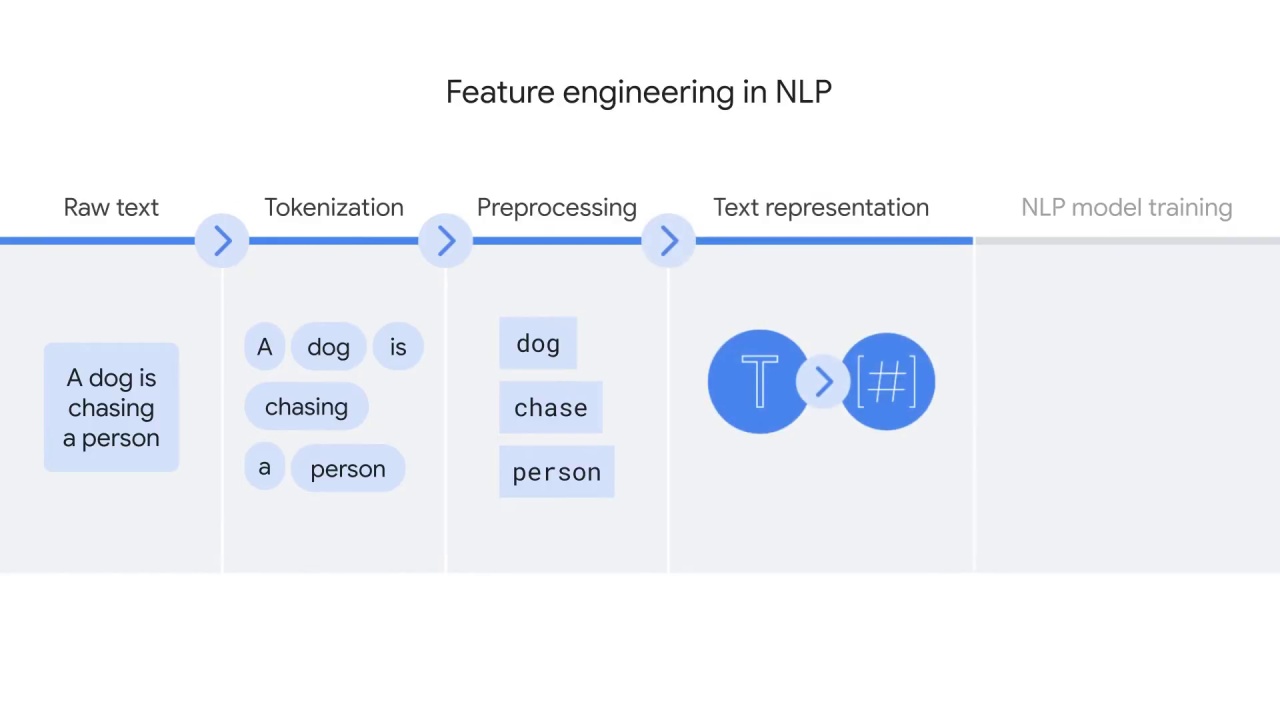
You’ll then turn the preprocessed language units into numbers that represent some meanings.
This step is often called text representation, and it’s where a computer understands text in addition to reading it.
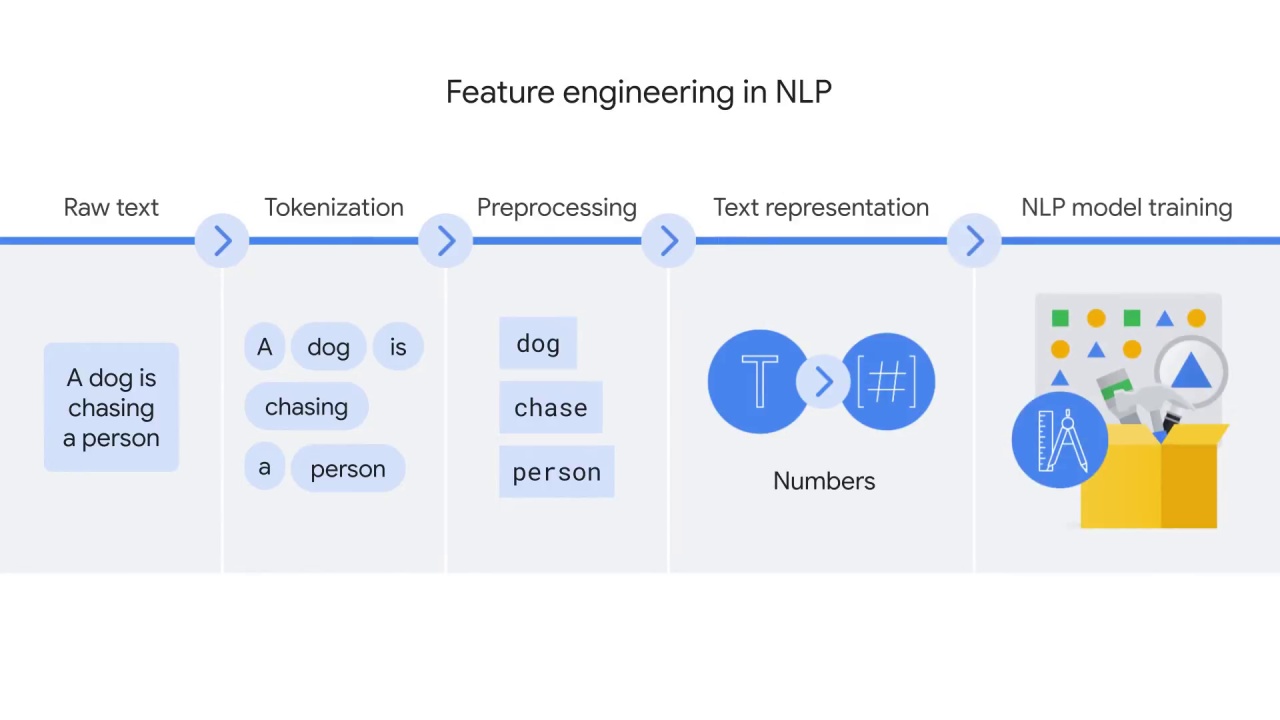
The output of text representation is normally vectors that can be fed into ML models to solve specific tasks.
Before exploring different techniques for text representation and various NLP models,
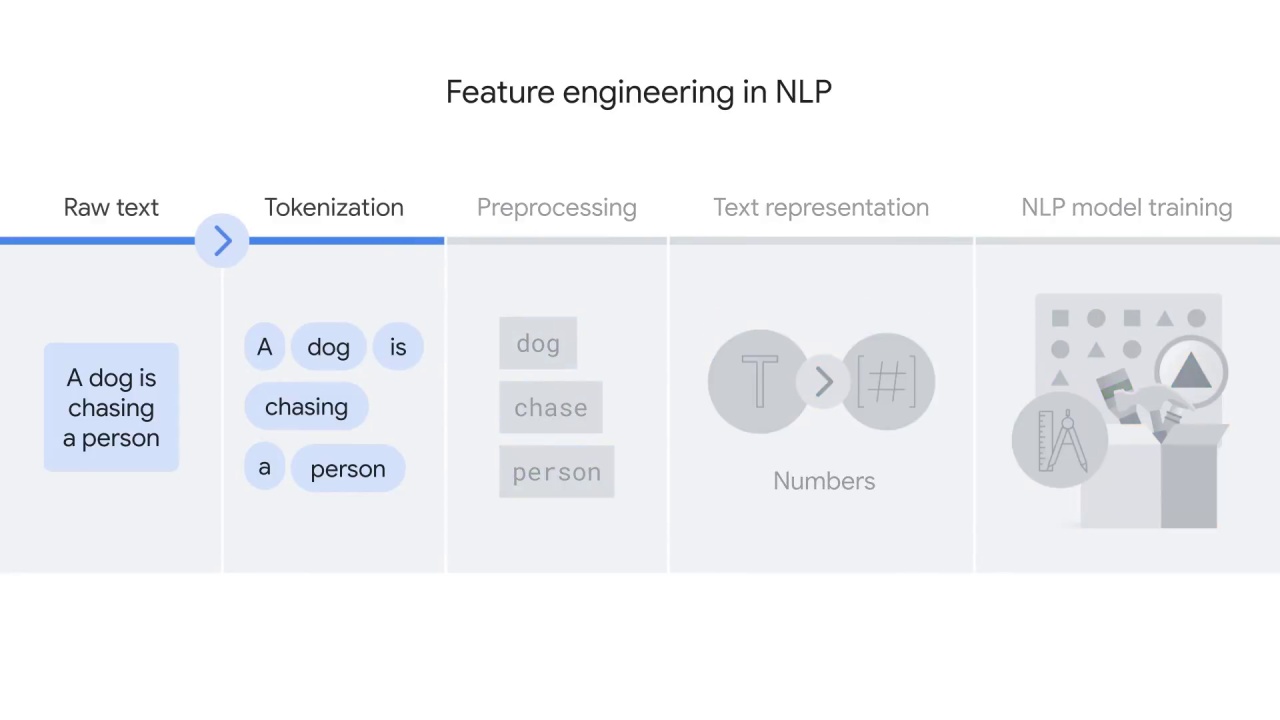
let’s start with tokenization and explore how a computer reads text.
Tokenization is the first step to prepare text for ML models.
It aims to ___
For example, tokenization will split the sentence “a dog is chasing a person,”
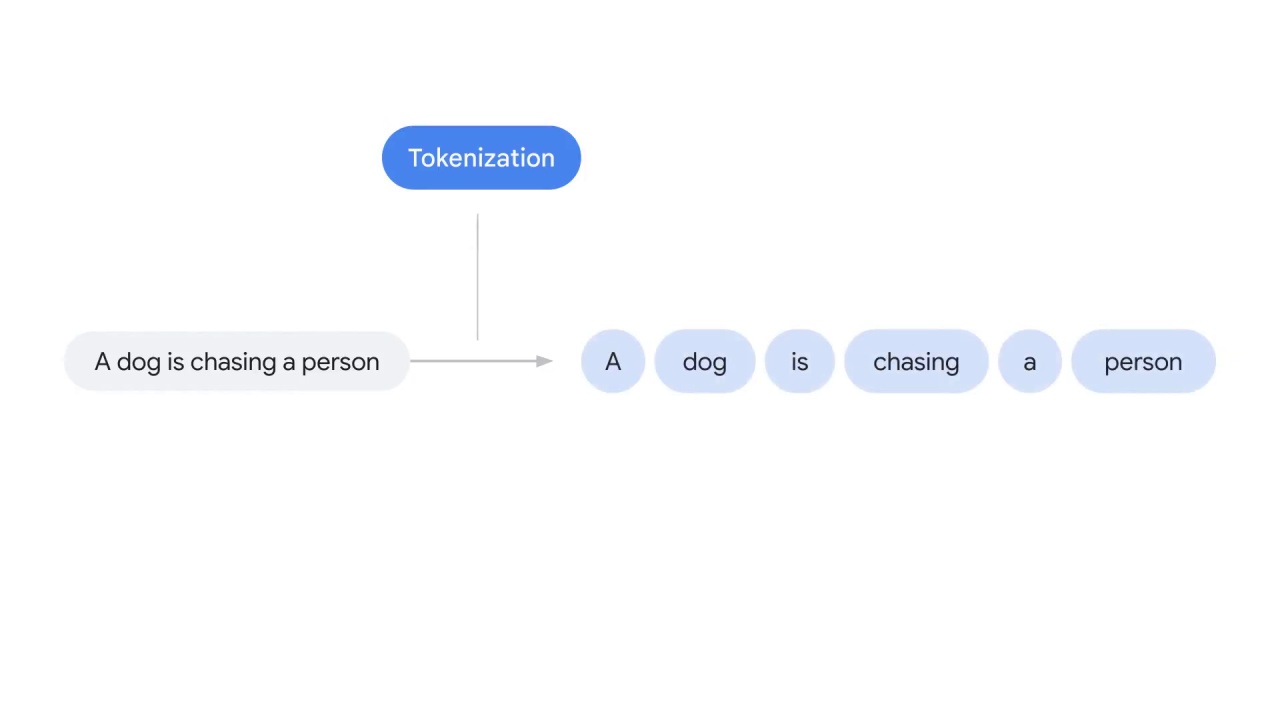
into separate words.
This step is often overlooked and underappreciated, simply because English is easy to tokenize
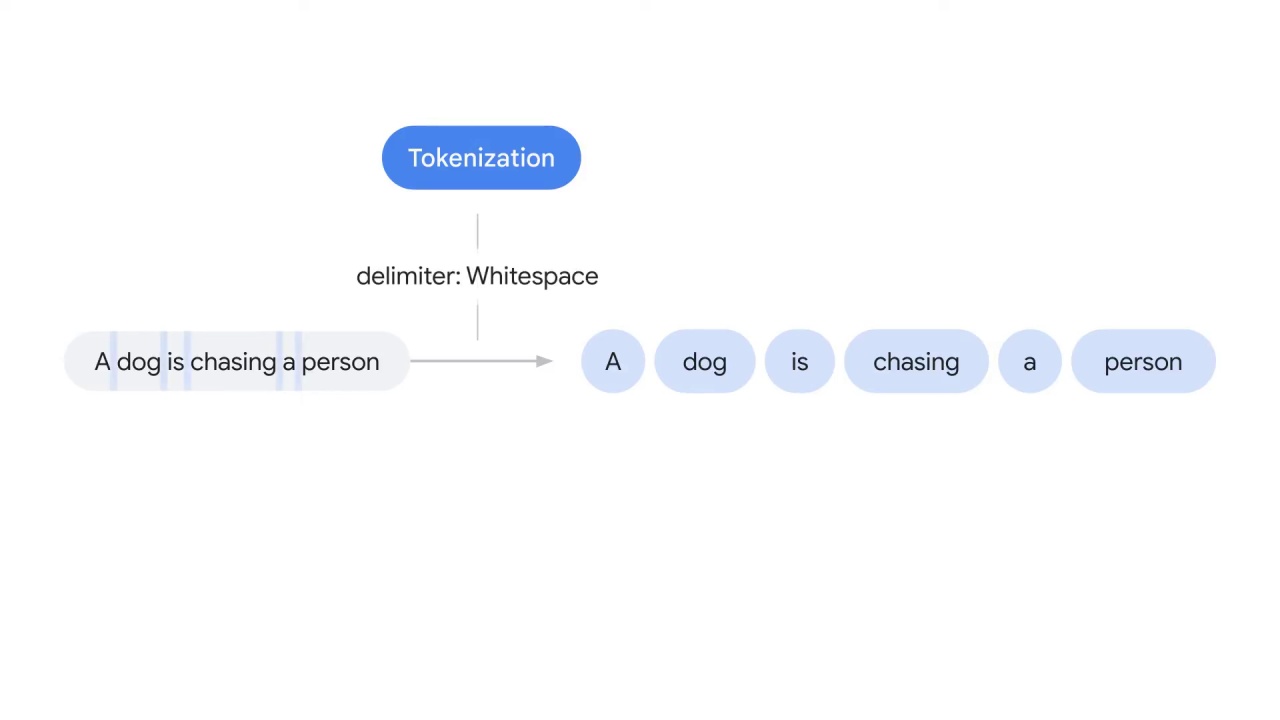
with a delimiter such as a whitespace.
However, if you take a moment to think about it,
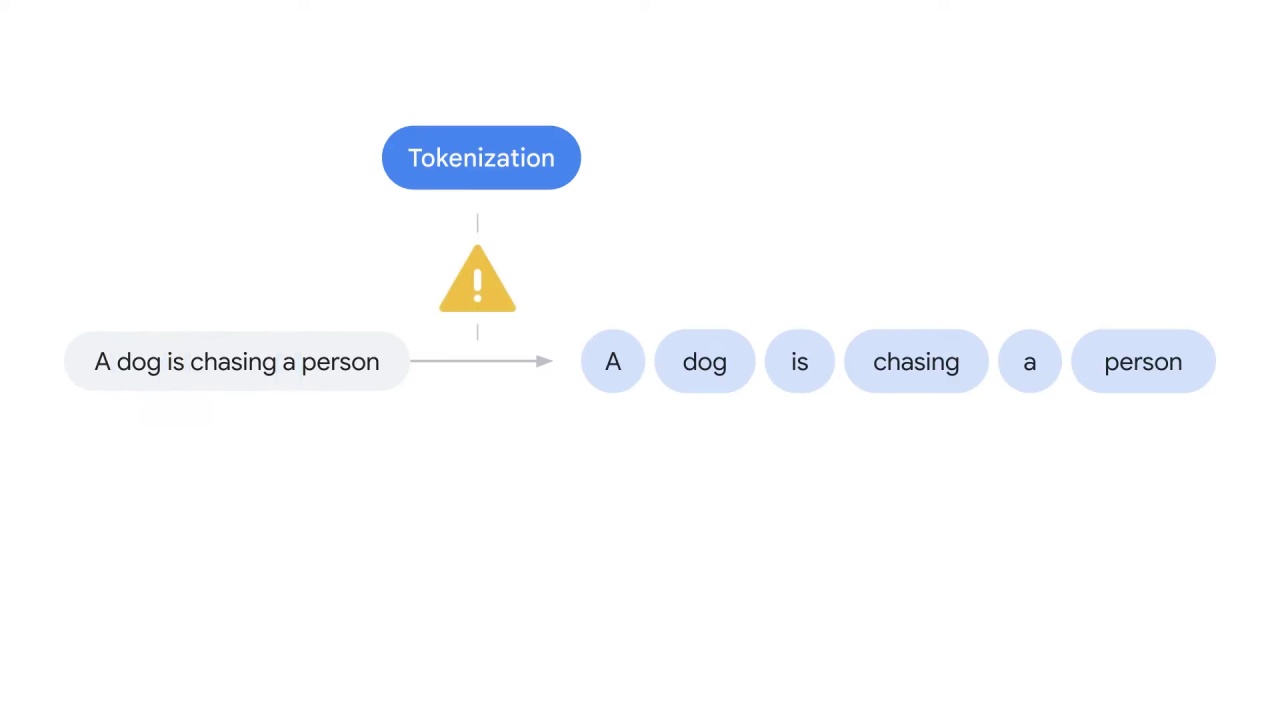
you’ll find the problem is not as obvious as it looks.

First of all, what about other languages such as Chinese?
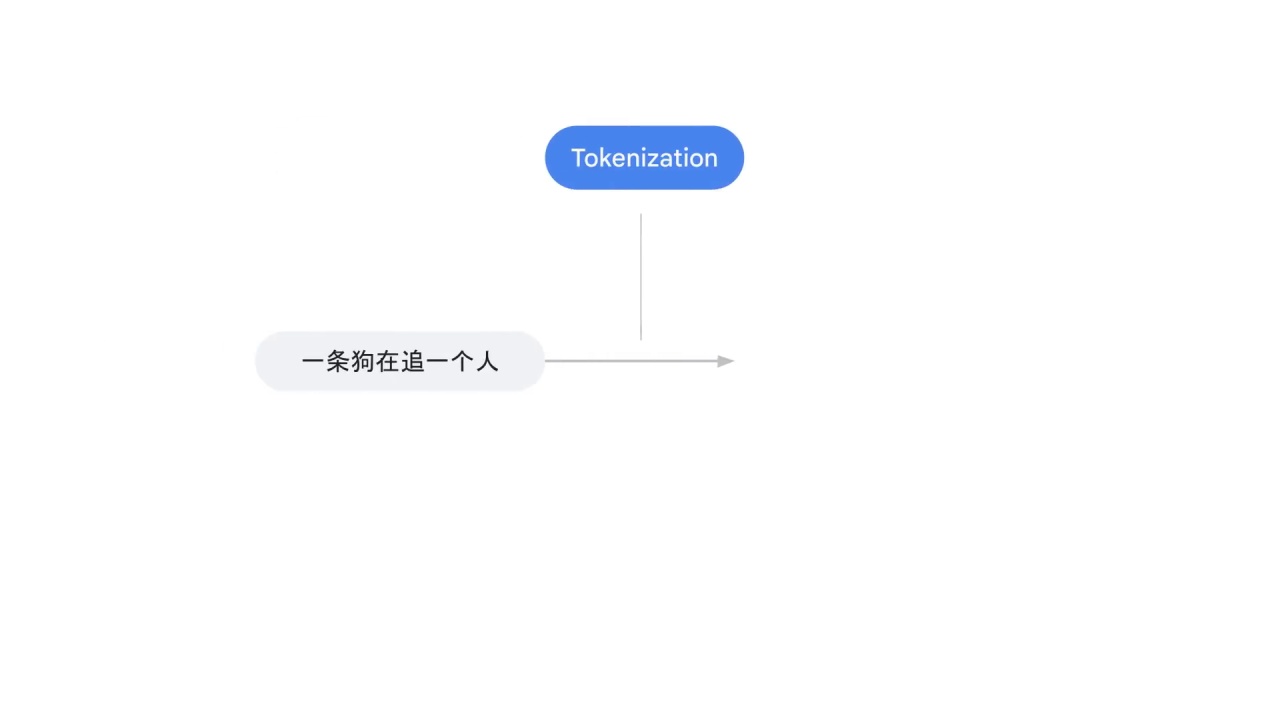
In this example, 一条狗在追一个人
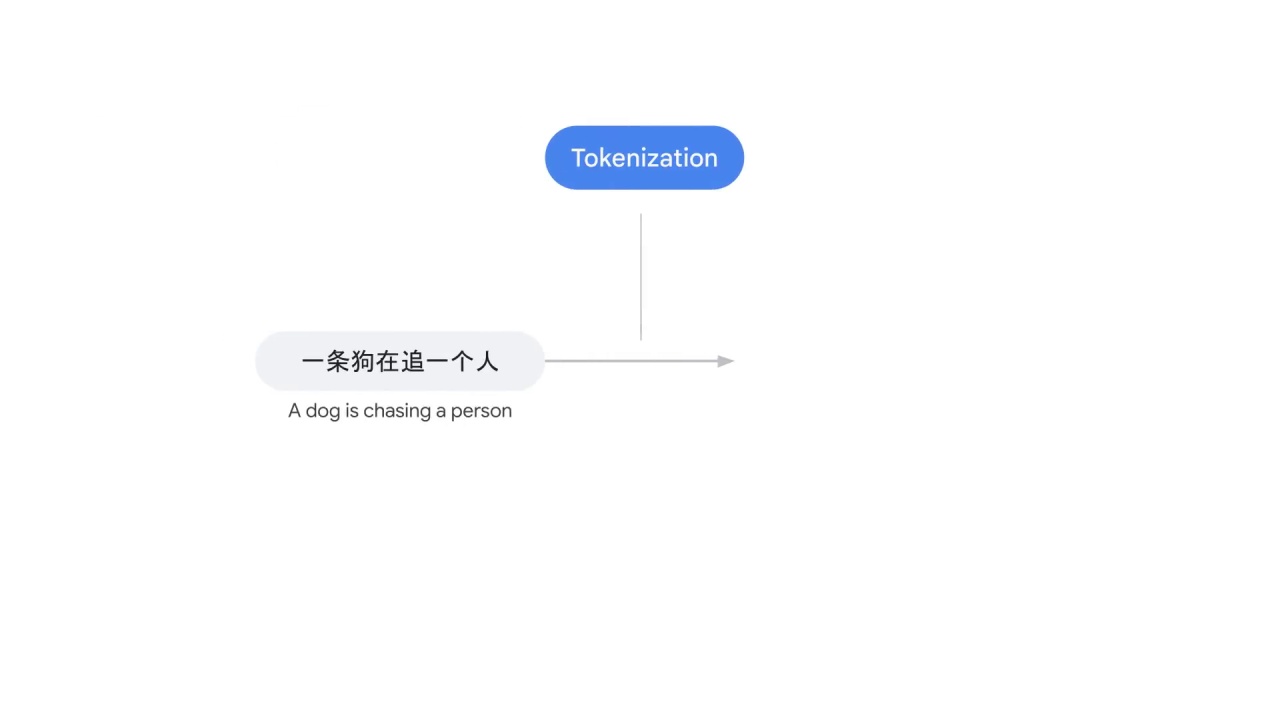
which is the Chinese translation of “A dog is chasing a person”
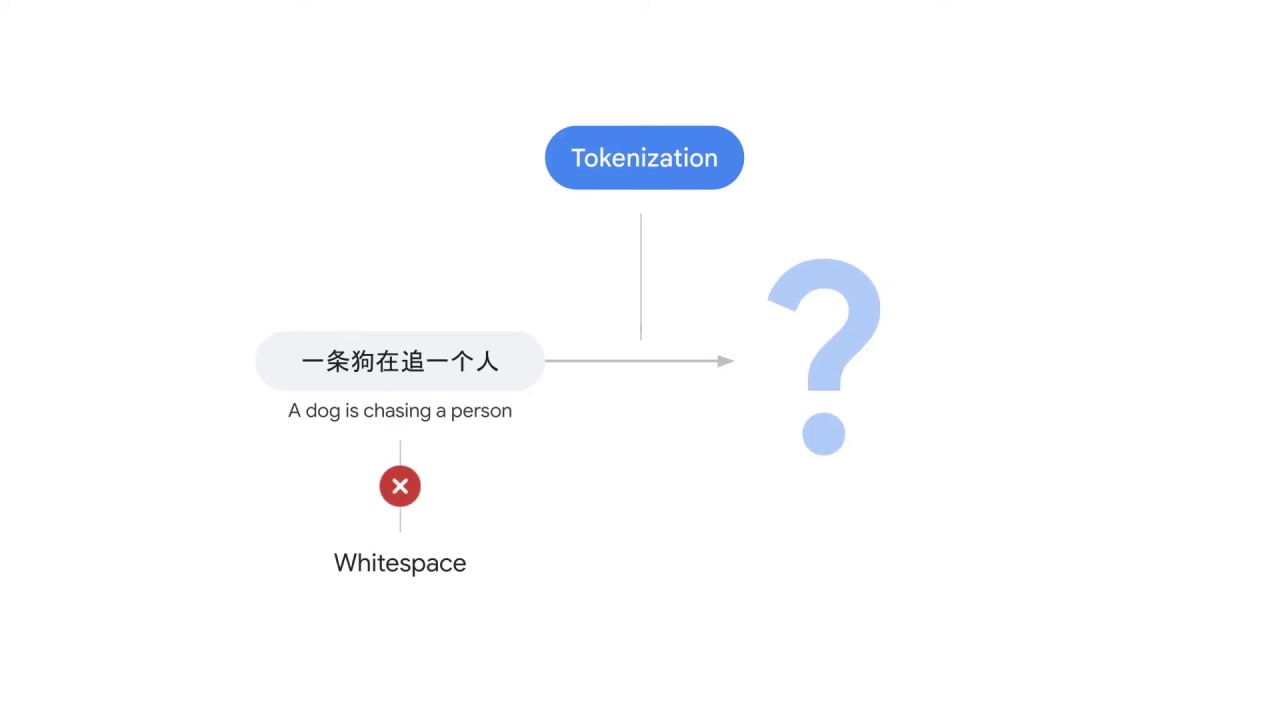
there’s no space between characters, so how do you split the sentence?
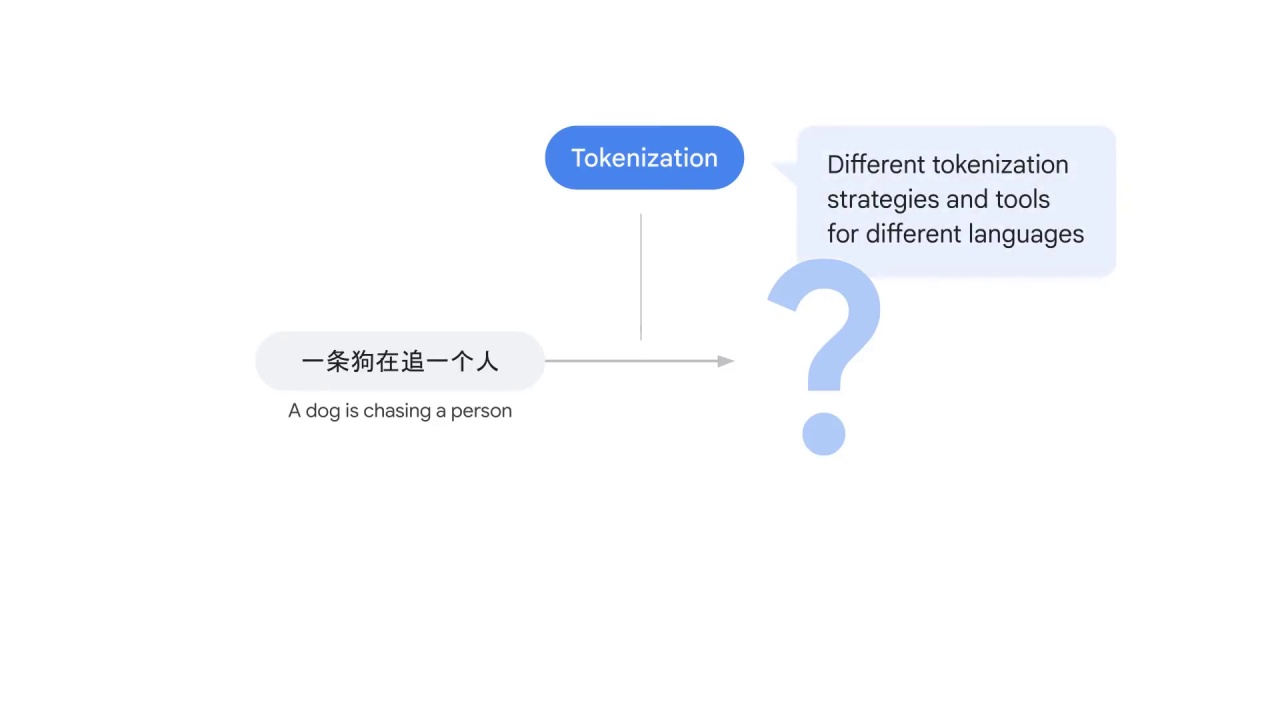
To solve this problem, people must develop different tokenization strategies and tools for different languages.

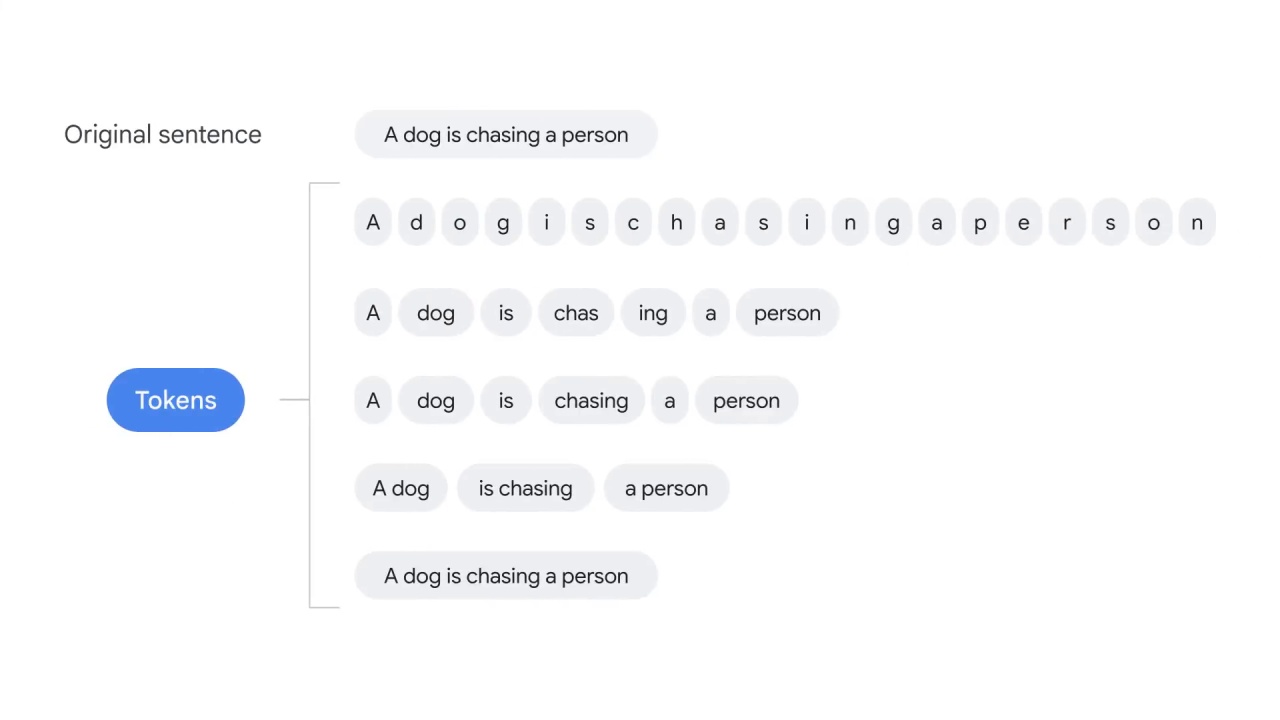
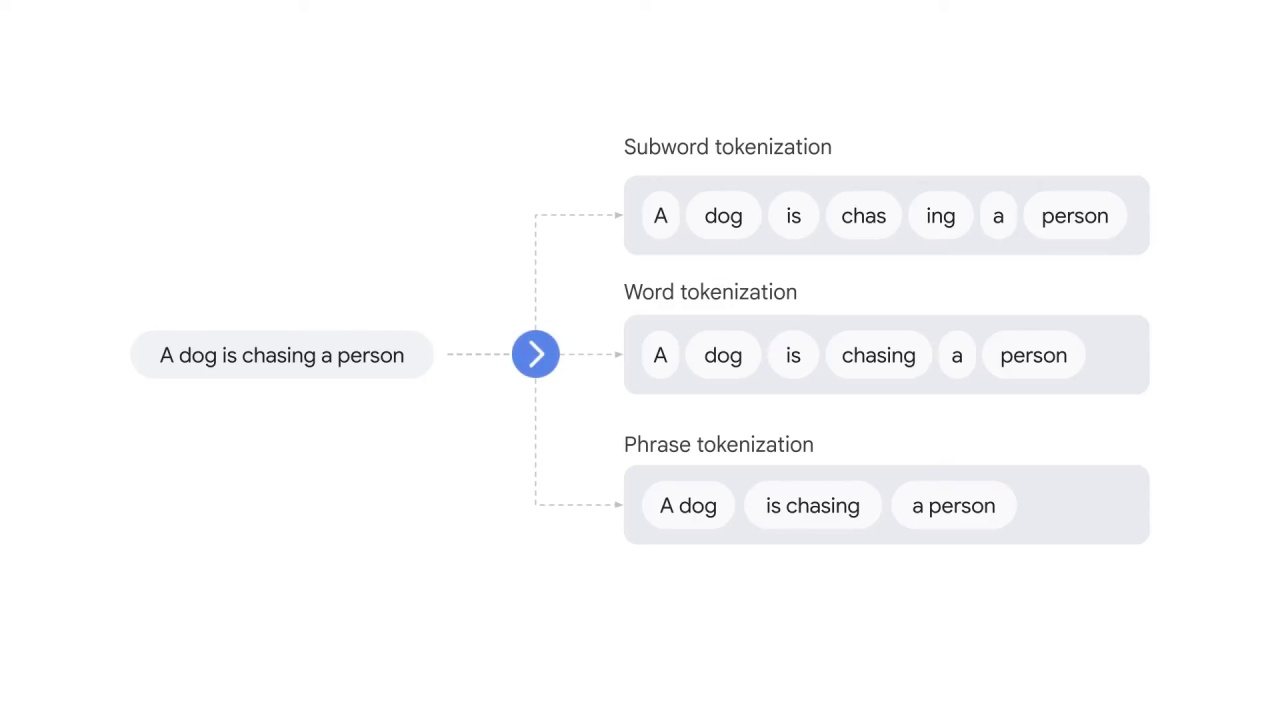
Smaller language units, which are called tokens in tokenization, can exist at different levels.
For example:
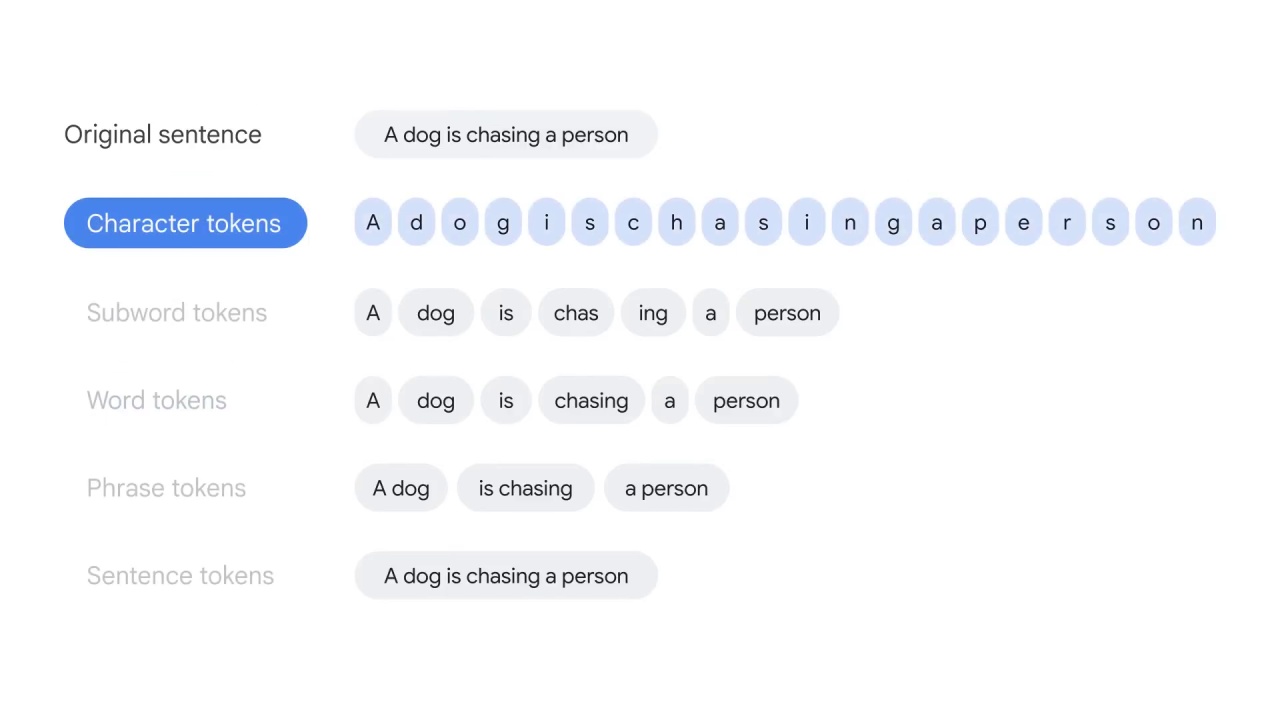
Character tokens split the text at the character level, for instance,
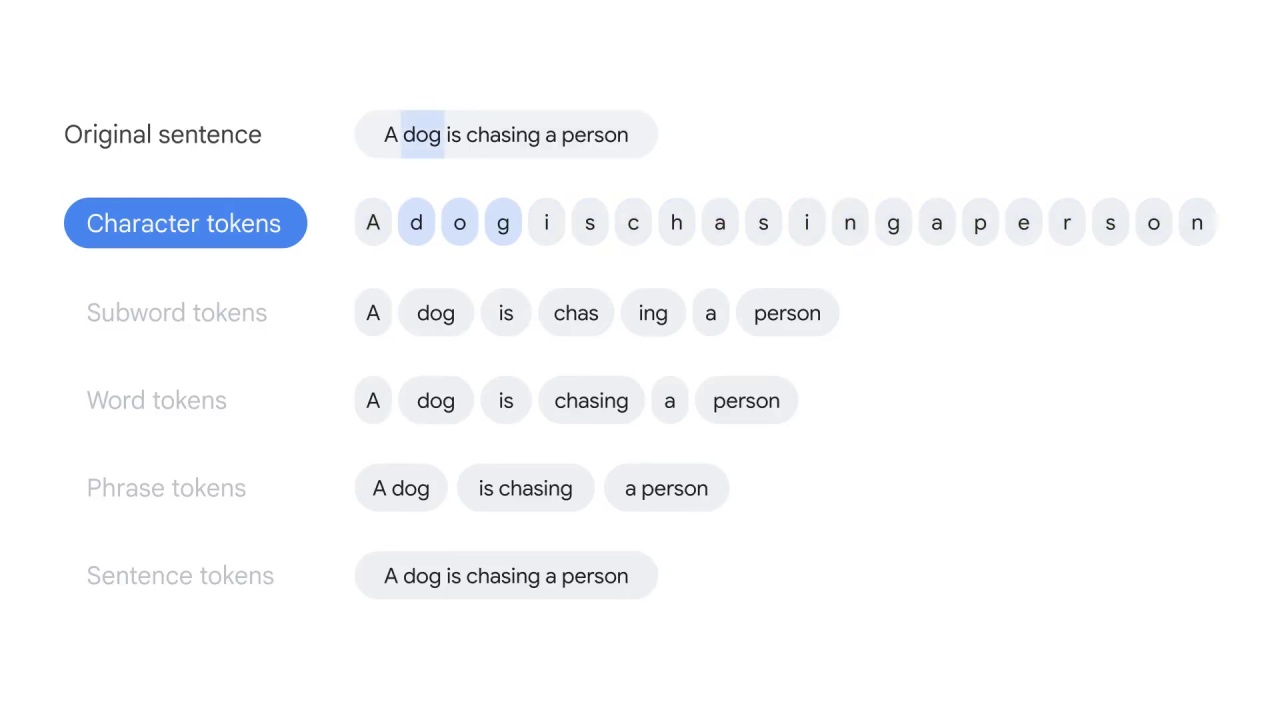
dog is split into d-o-g.
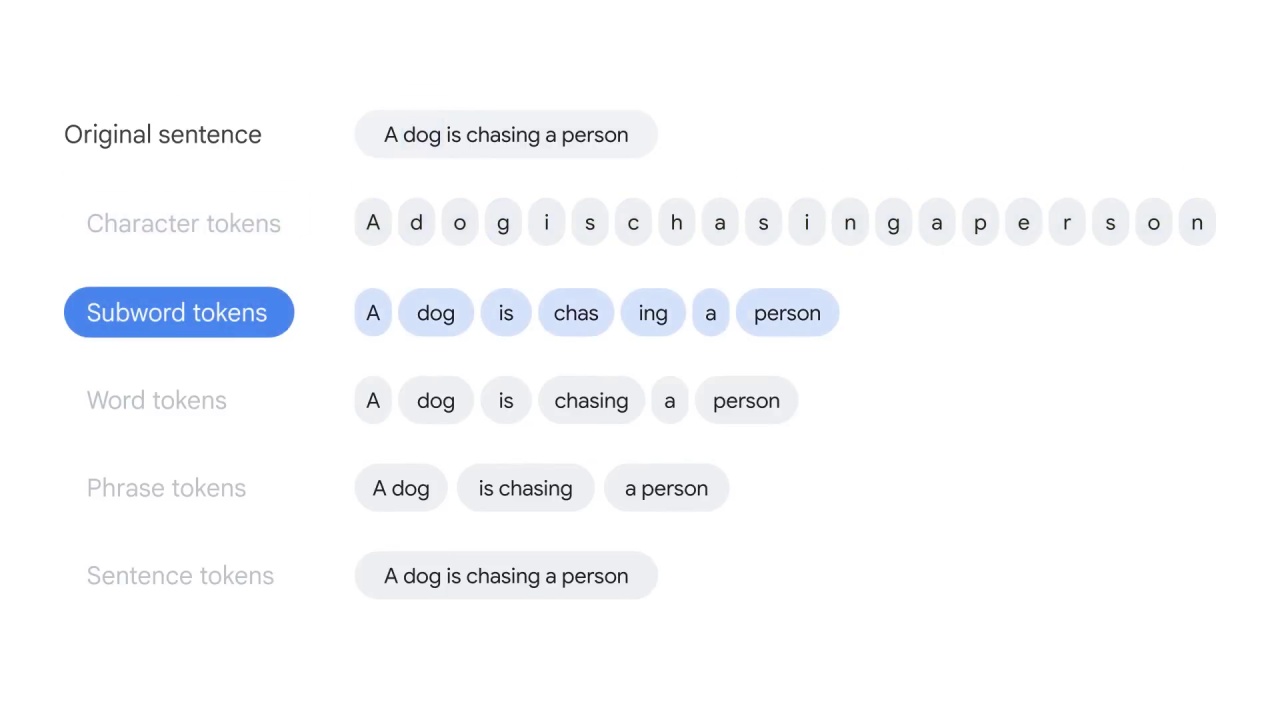
Subword tokens split the text at the root word level,
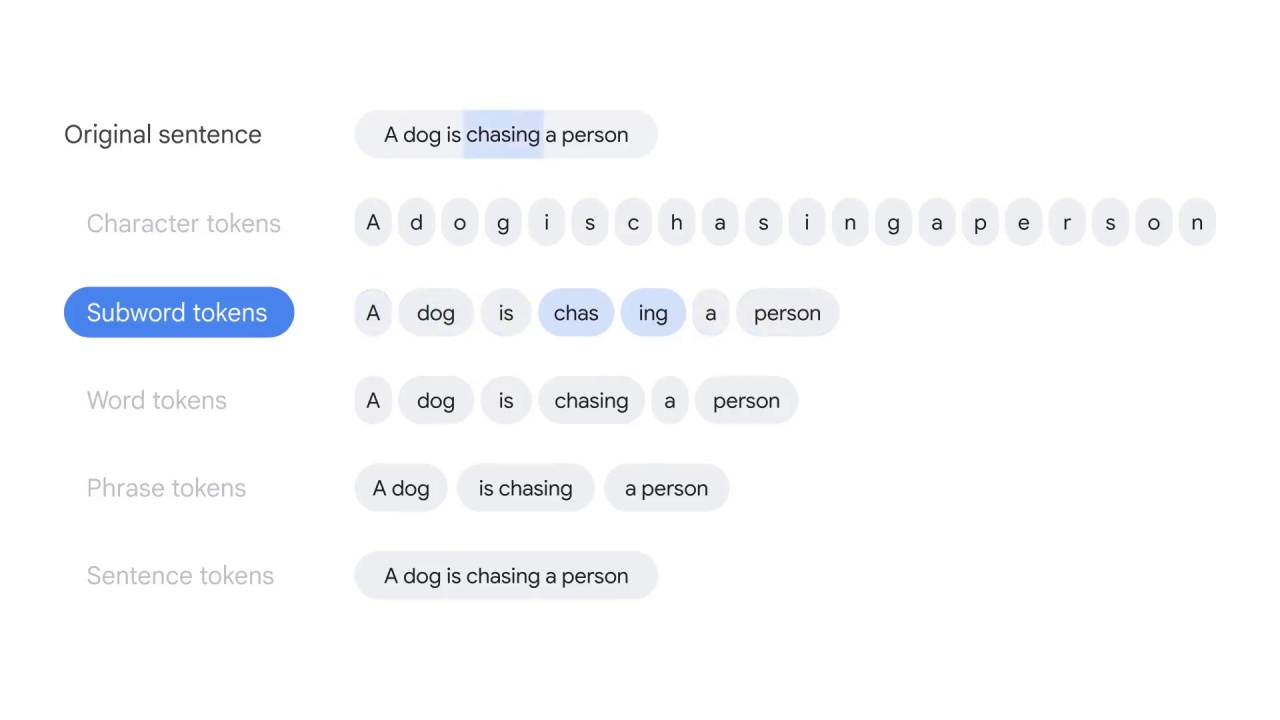
for example, “chasing” is split into “chase” and “ing.”
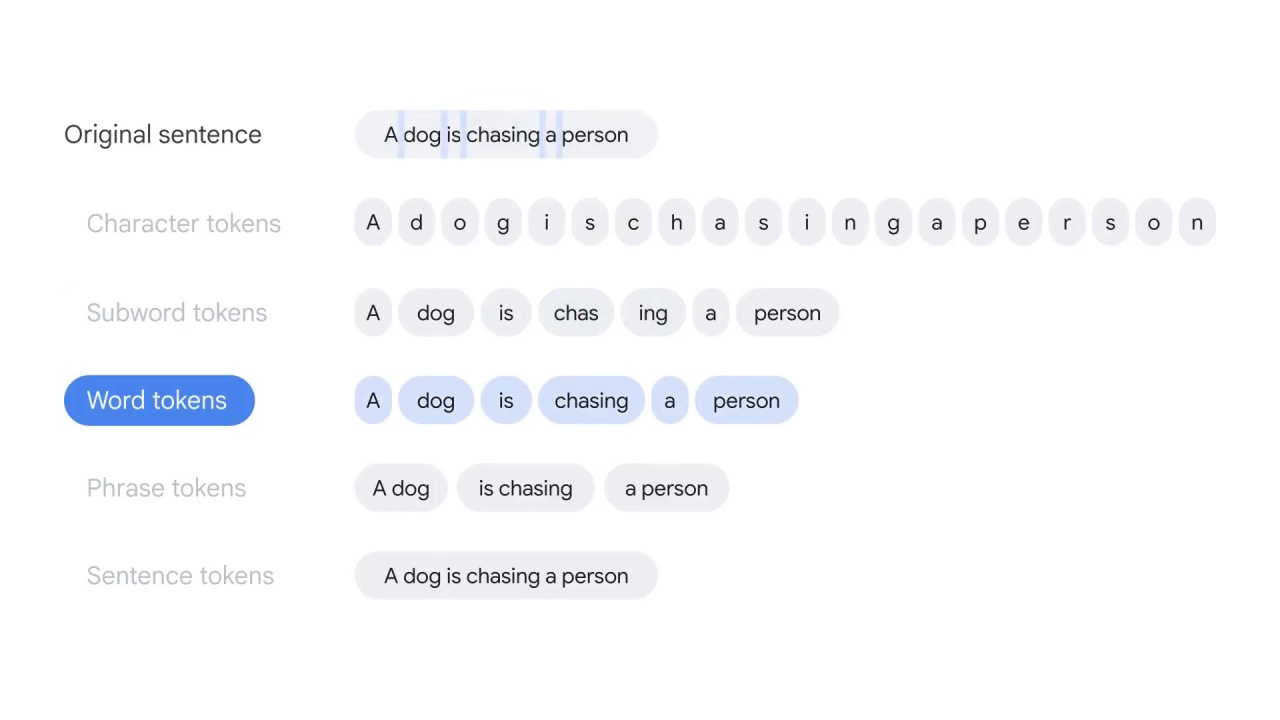
Word tokens split the text by whitespaces.
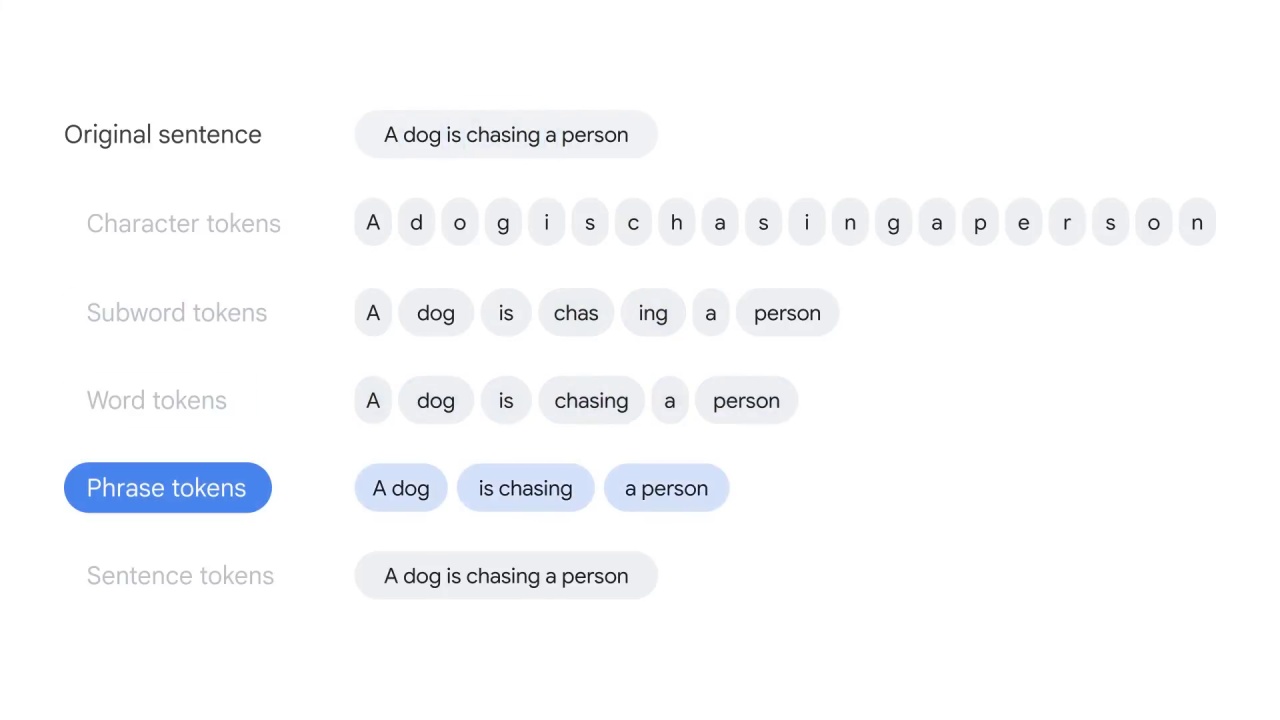
Phrase tokens split the text by phrases, for example, “a dog” and “is chasing.”
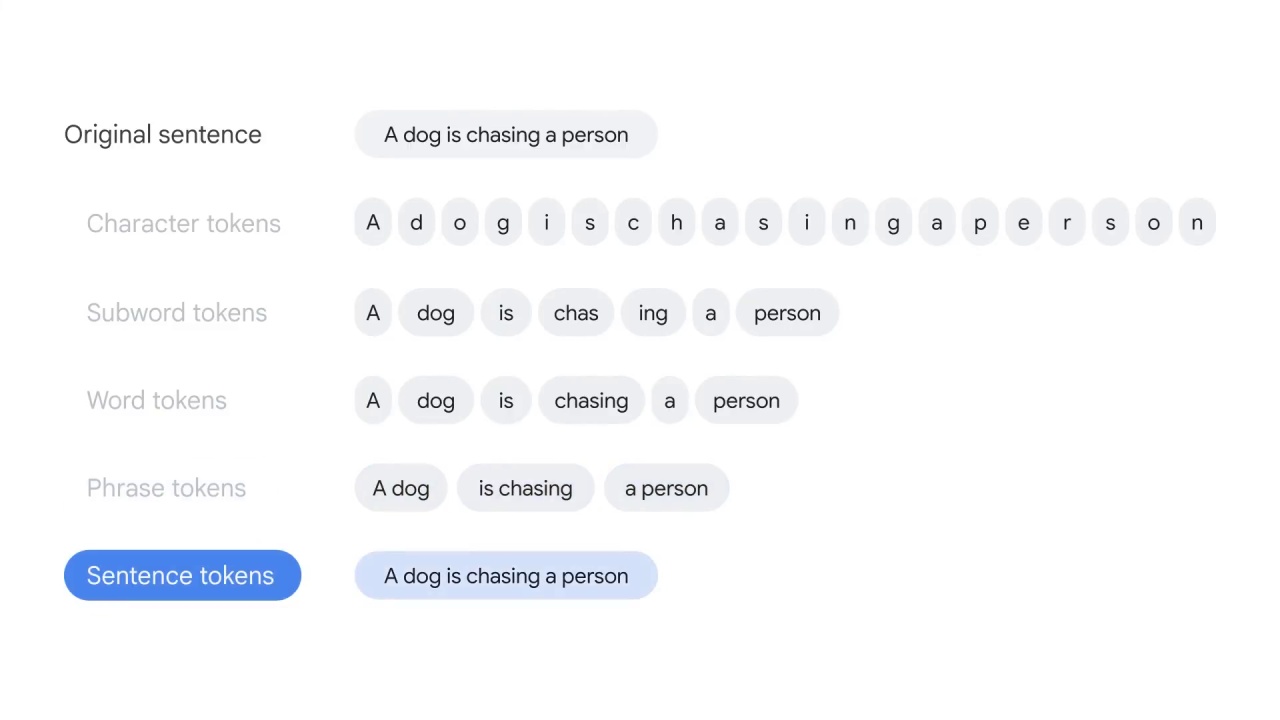
And finally, sentence tokens split the text by punctuation.
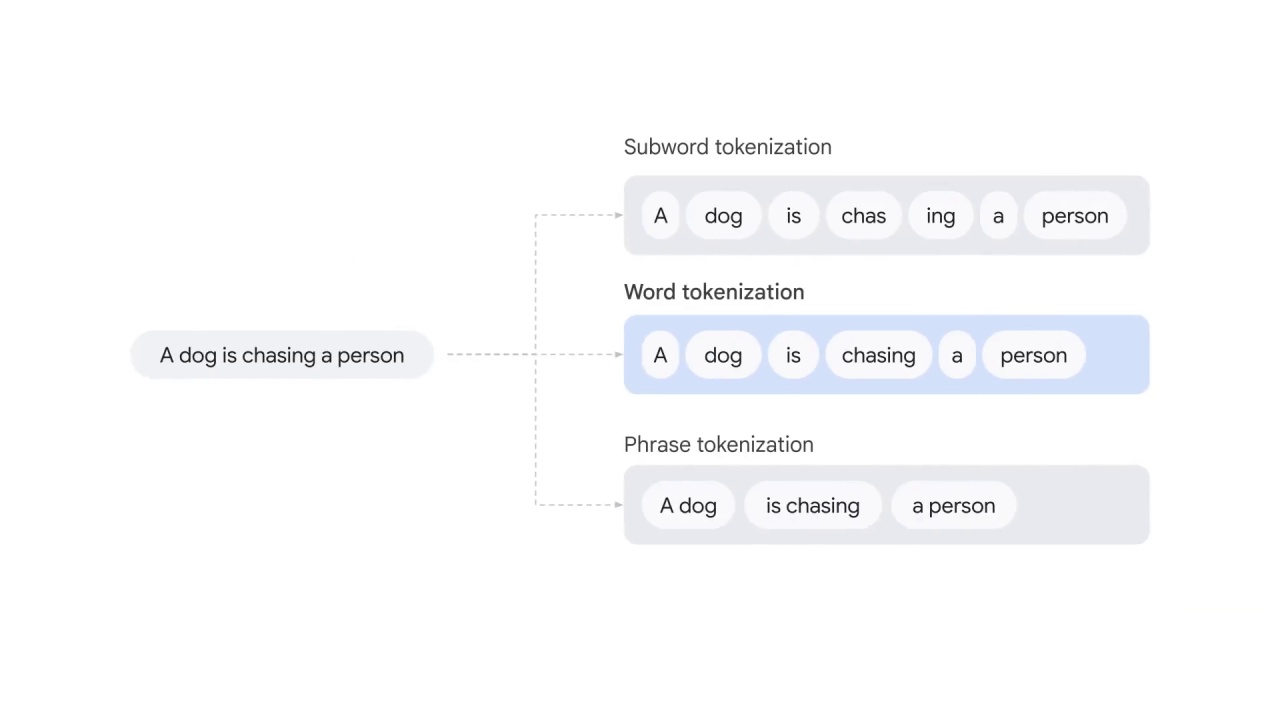
Word tokenization is the most commonly used algorithm for splitting text;
however, each tokenization has its own advantages and disadvantages.
The choice of the tokenization type mainly depends on
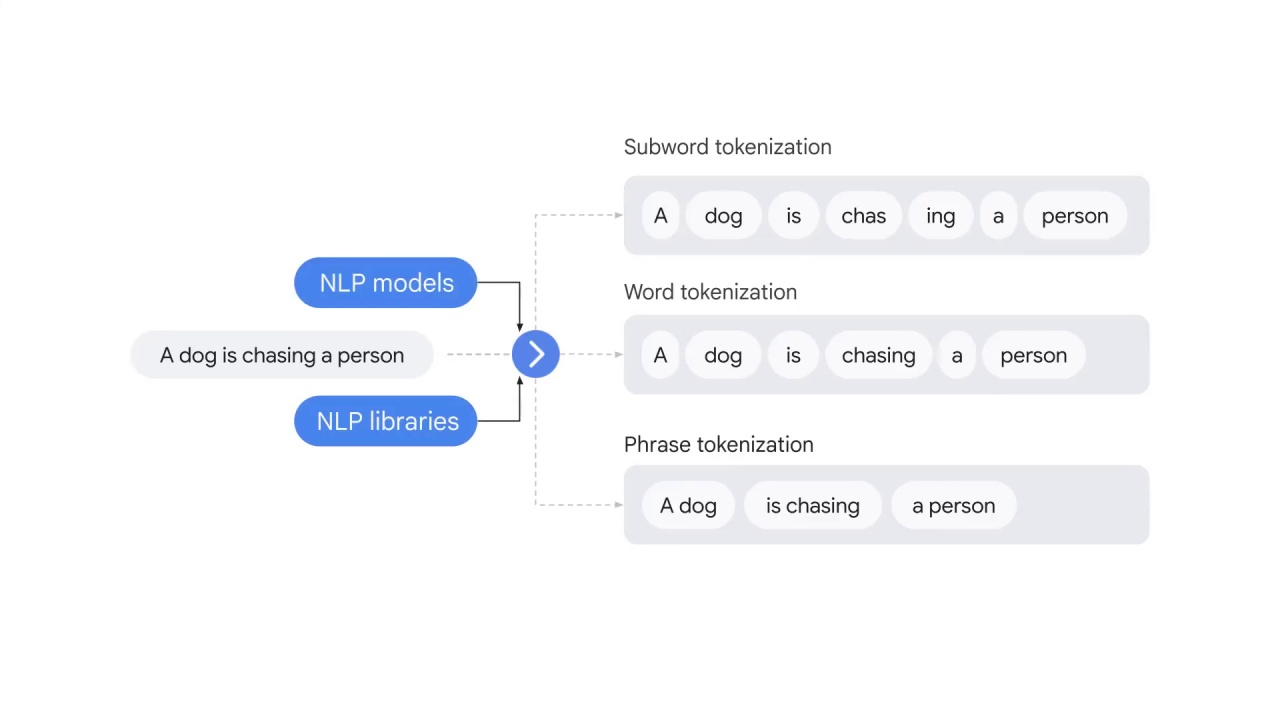
the NLP libraries and the NLP models you’re using.
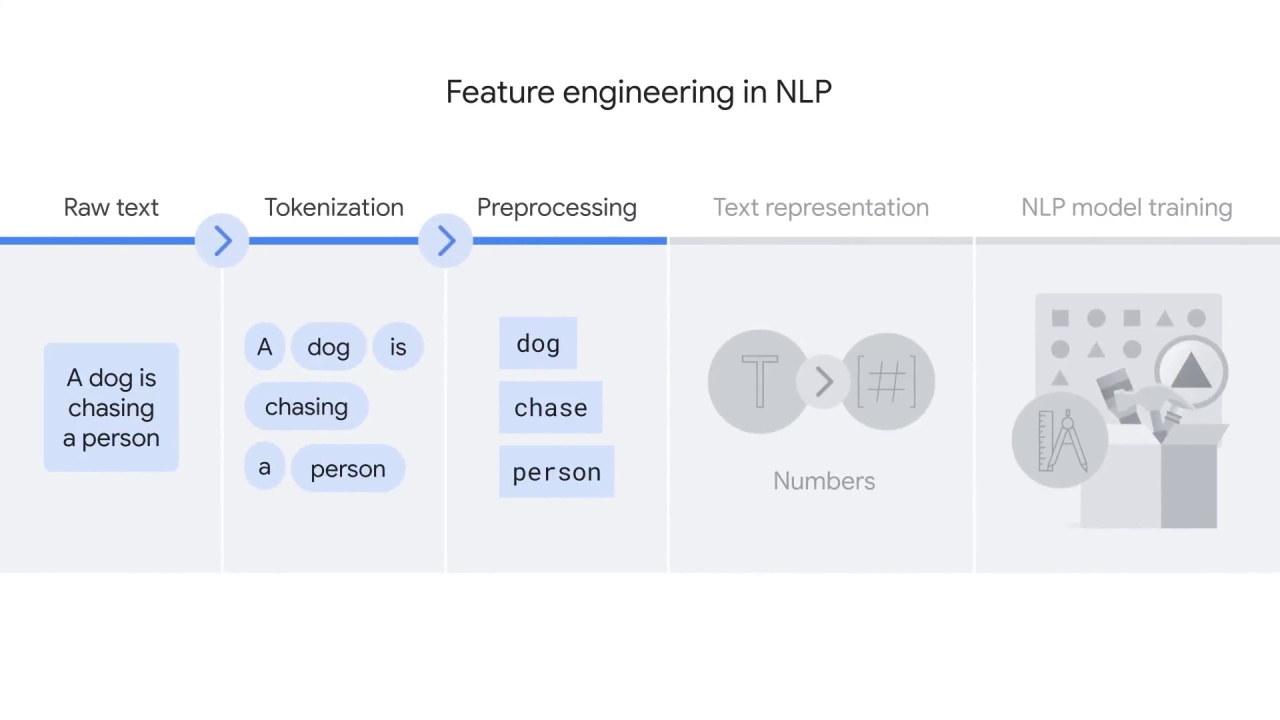
After tokenization, you must further prepare the text.
It’s called preprocessing.

Different things you can do in this step, for example, ___



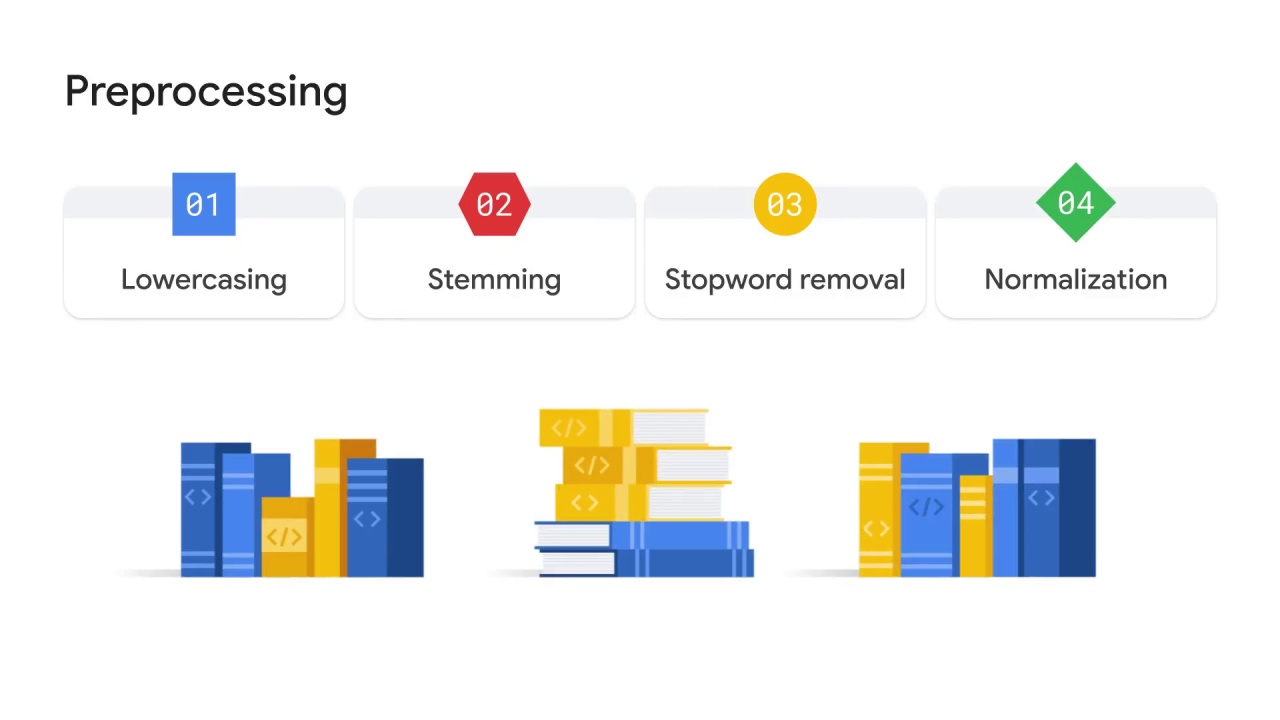
You have various NLP libraries to help you complete these preprocessing tasks automatically.

For example,TensorFlow provides a new text preprocessing layer using TextVectorization API.

It maps text features to integer sequences including the functions such as

preprocessing, tokenization, and even the vectorization.
Using this new API, you can do all the text preparation work in one place.