Word embeddings
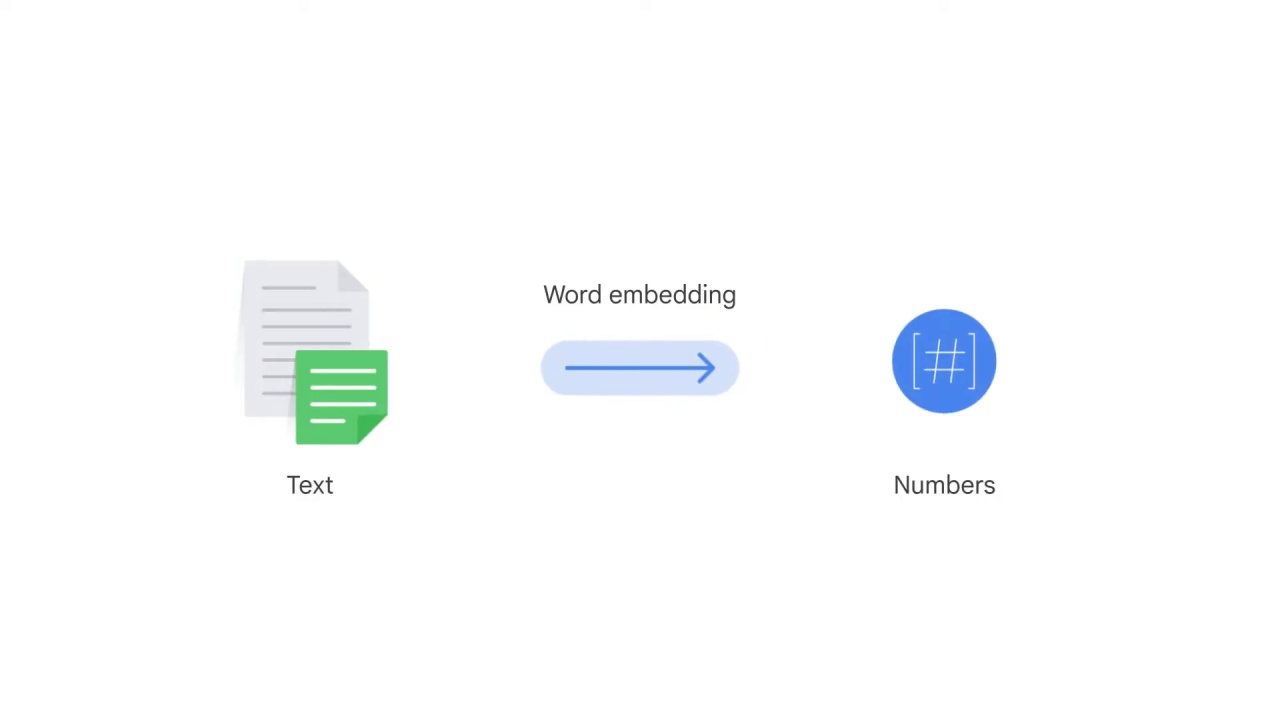
You’ll learn how word embeddings encode text to numbers that convey meanings.
Let’s start with intuition.
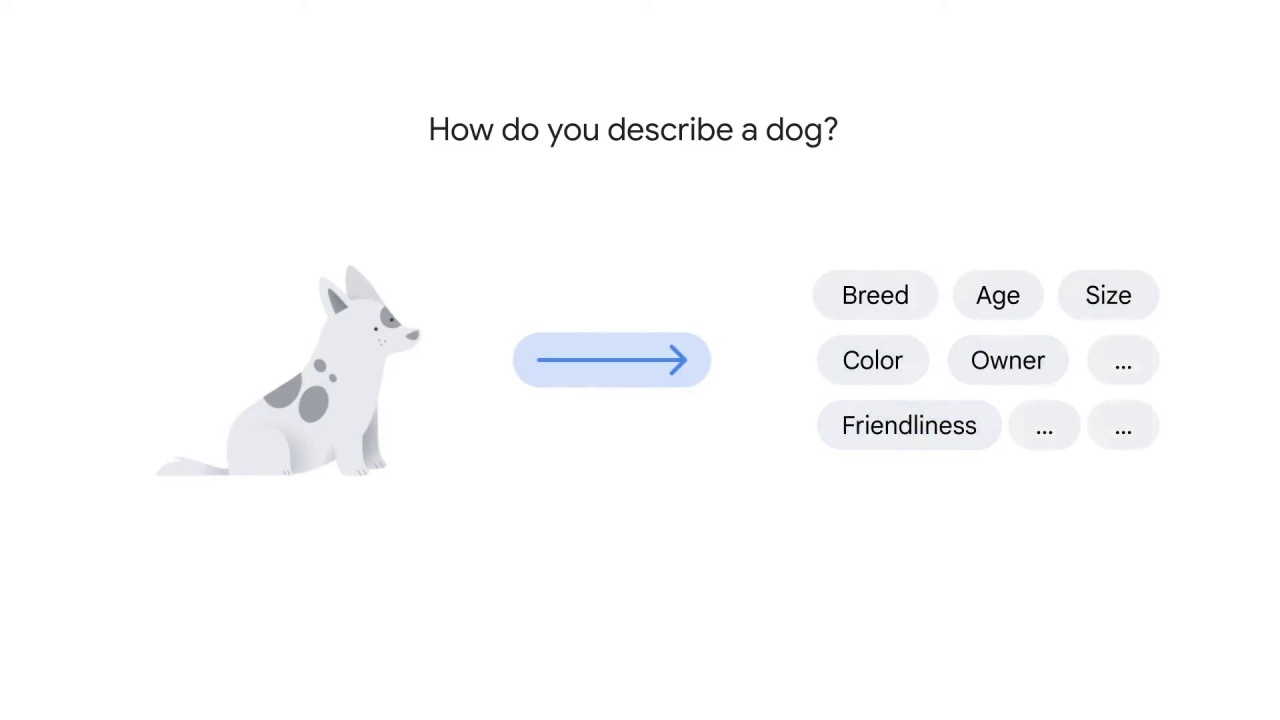
How would you describe a dog?
You might mention its breed, age, size, color, owner, and friendliness.
You can easily think of at least ten different dimensions.
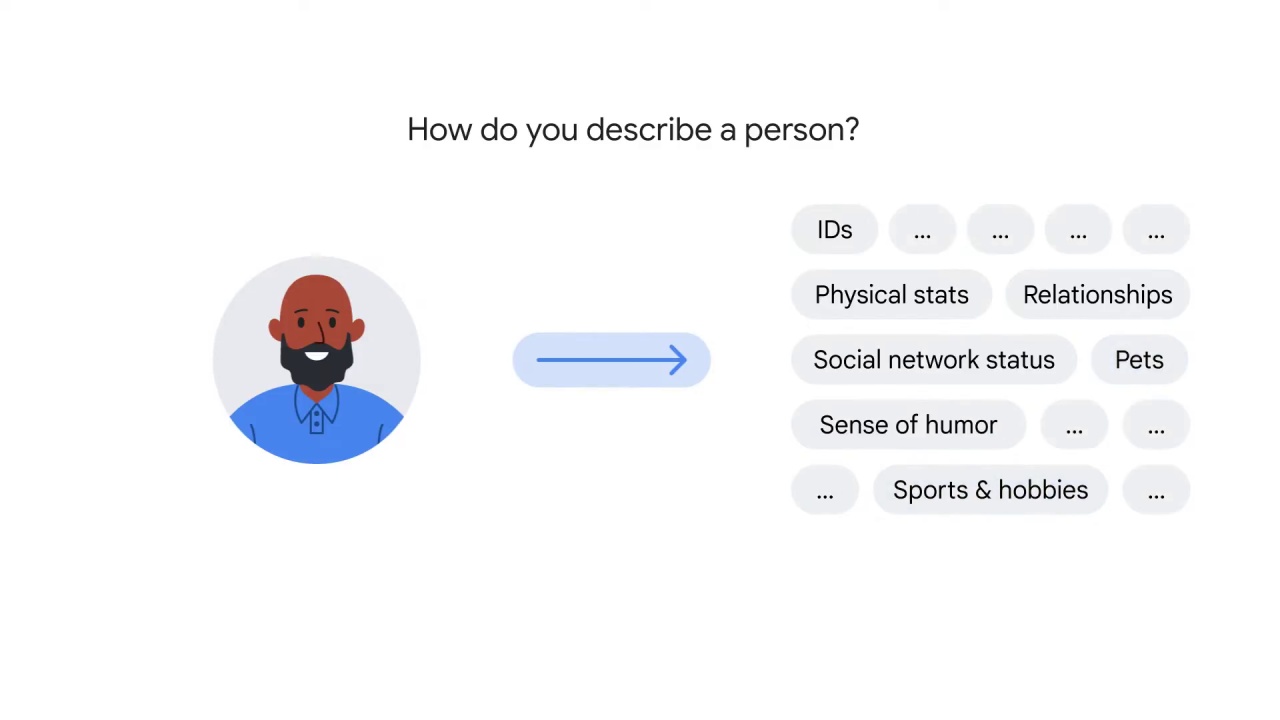
How would you describe a person?
You can again, easily think of at least 20 different dimensions to describe a person.
You might now guess the direction.
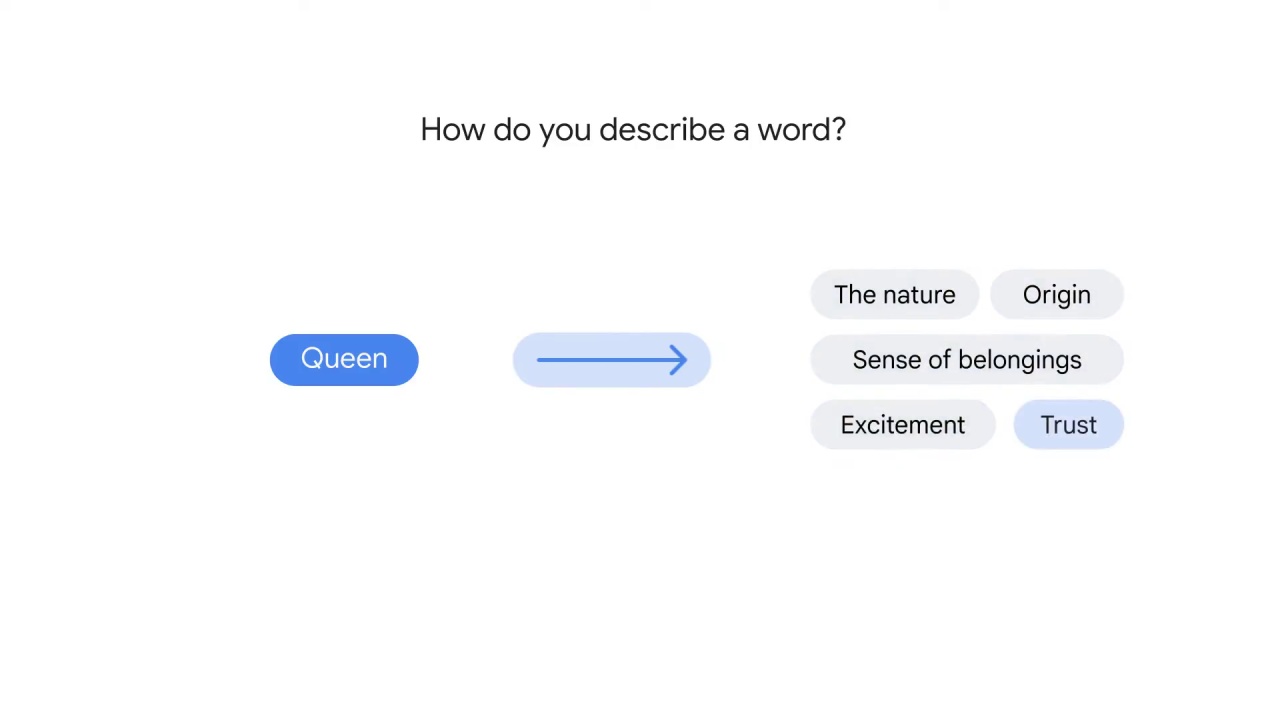
How would you describe a word then?
You can use dimensions, and in math, a vector space.
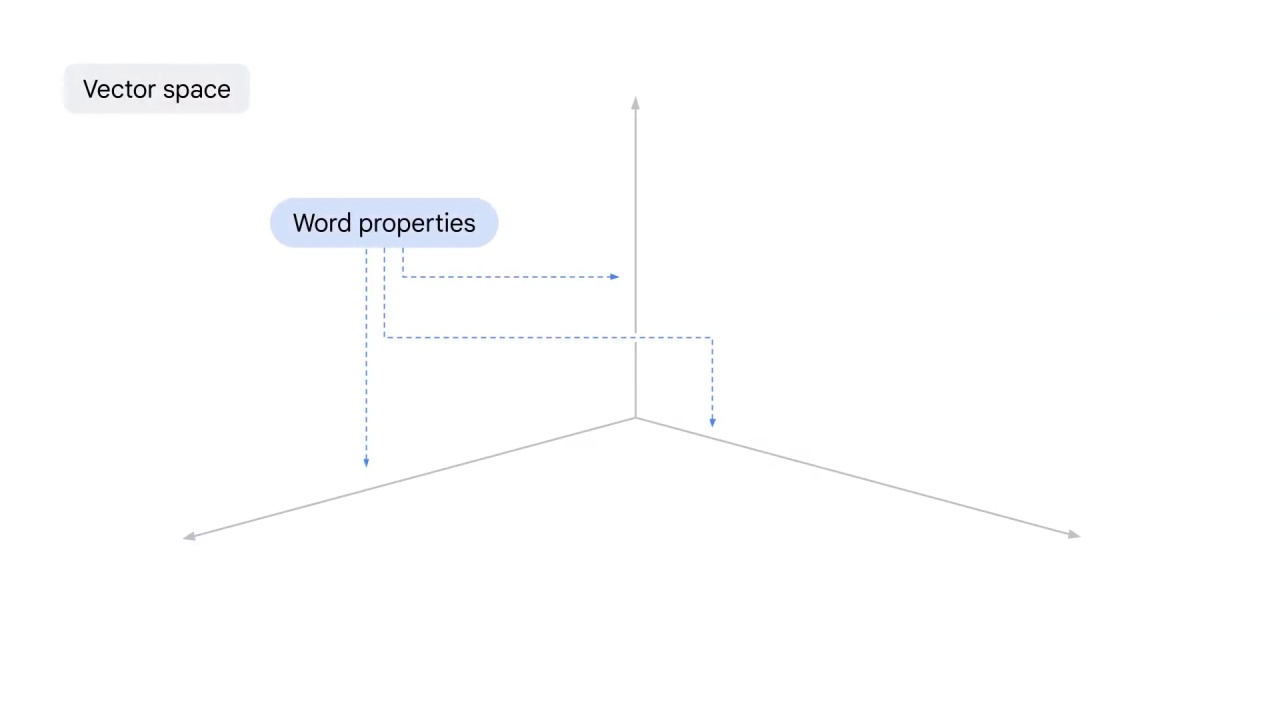
You can now generate an idea: how about representing a word in a vector space with dimensions to describe its properties?
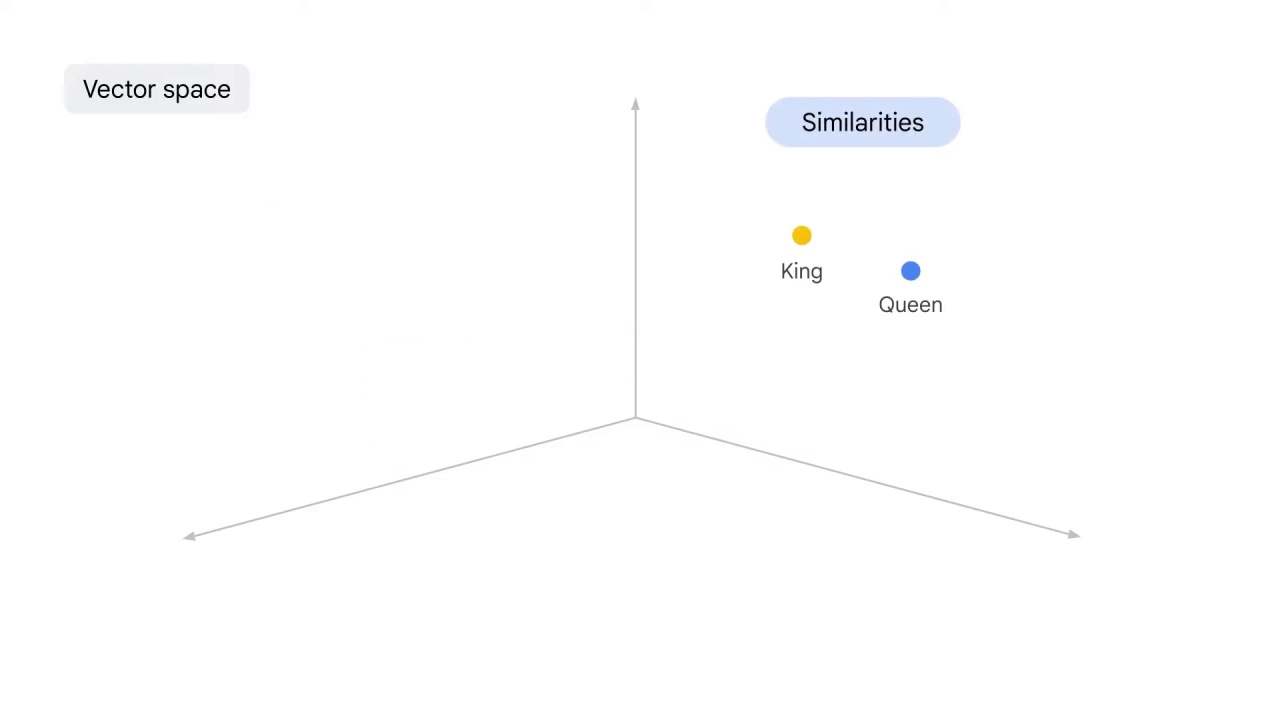
Not only that, you want the distance between the words to indicate the similarities between them.
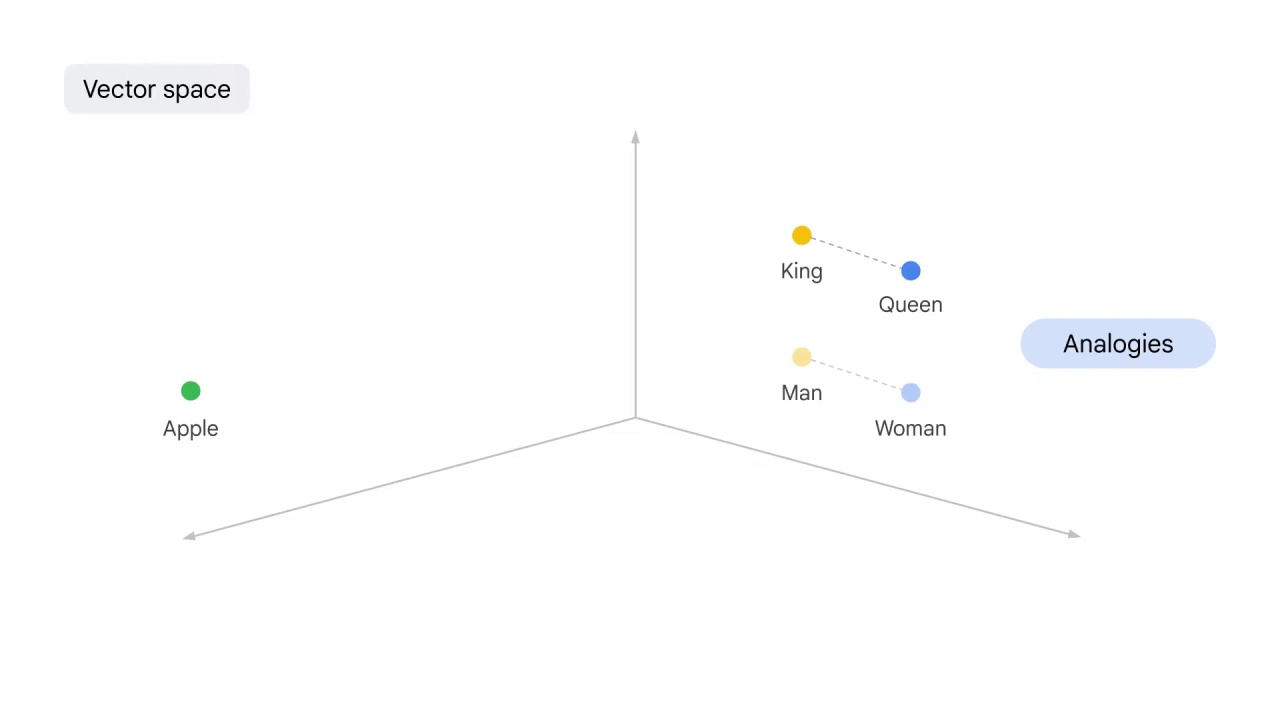
You want this representation to capture the analogy between words.
For example, the distance between king and queen is similar to the distance between man and woman.
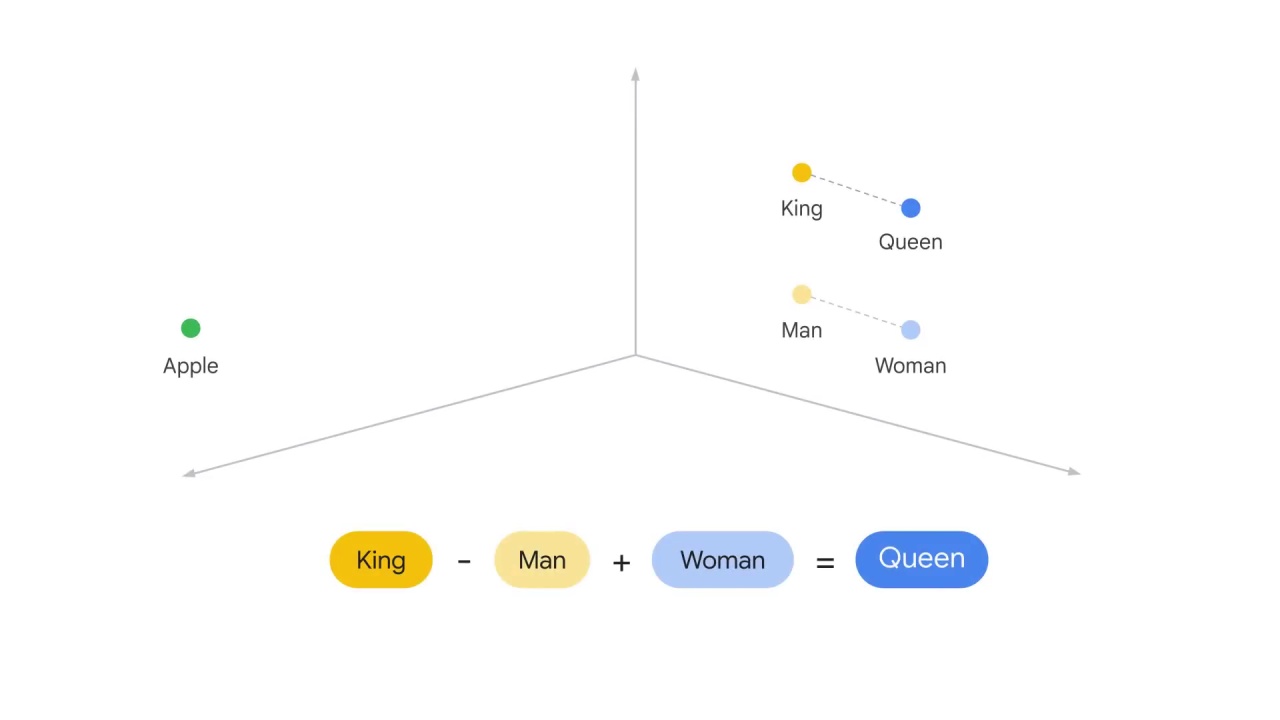
Now you have King - Man + Woman = Queen
Isn’t it amazing to play with words in the same way you play with numbers?

Word embedding is technique to encode text into meaningful vectors.
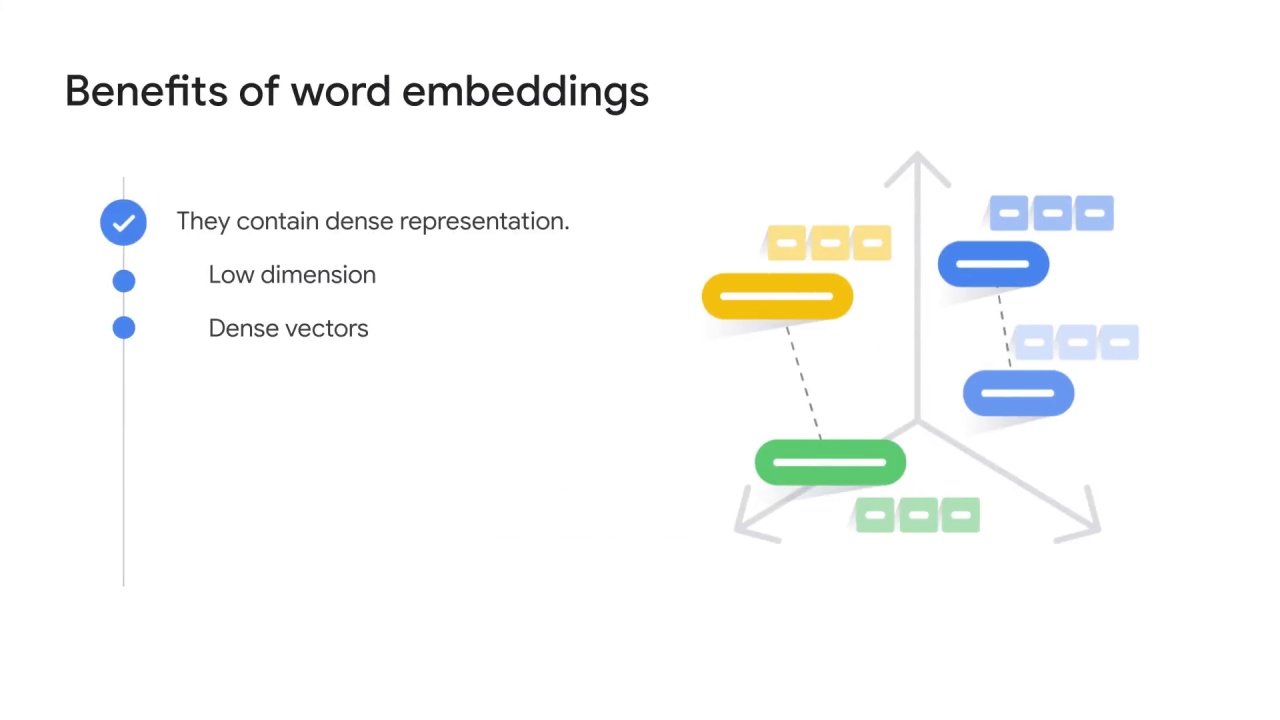
The technique lets you represent text with low-dimensional, dense vectors.
Each dimension is supposed to capture a feature of a word.
A higher dimensional embedding captures detailed relationships between words.
However, it takes more data and resources to train.
You don’t have sparse vectors anymore.
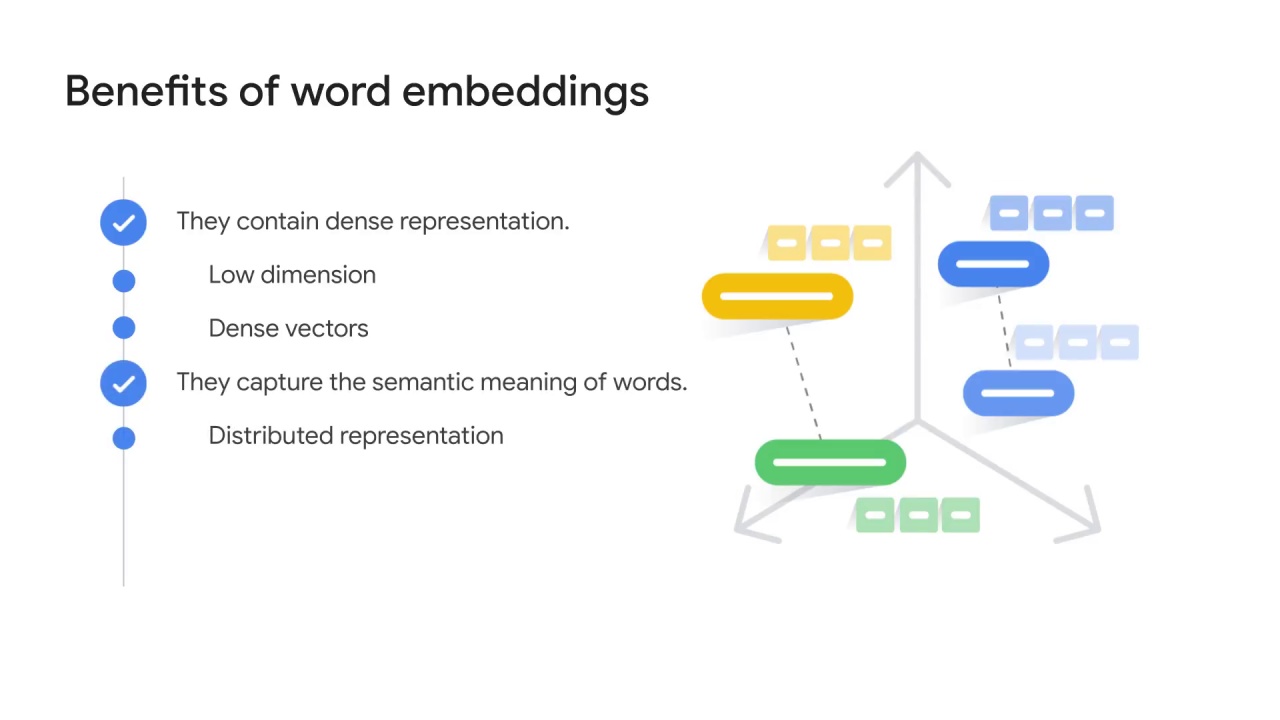
The vectors capture the relationships between words where similar words have a similar encoding.
Word embedding is sometimes called a technique of distributed representation, indicating that the meanings of a word are distributed across dimensions.
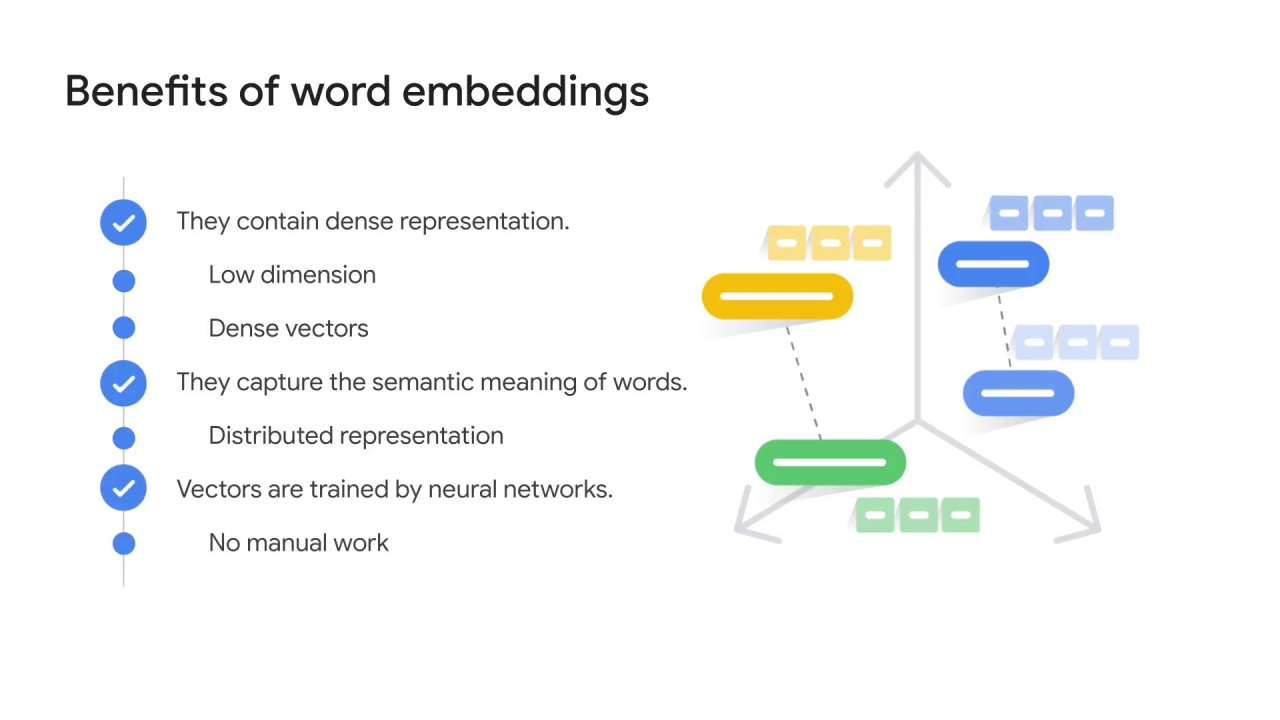
Instead of specifying the values for the embedding manually, you train a neural network to learn those numbers.
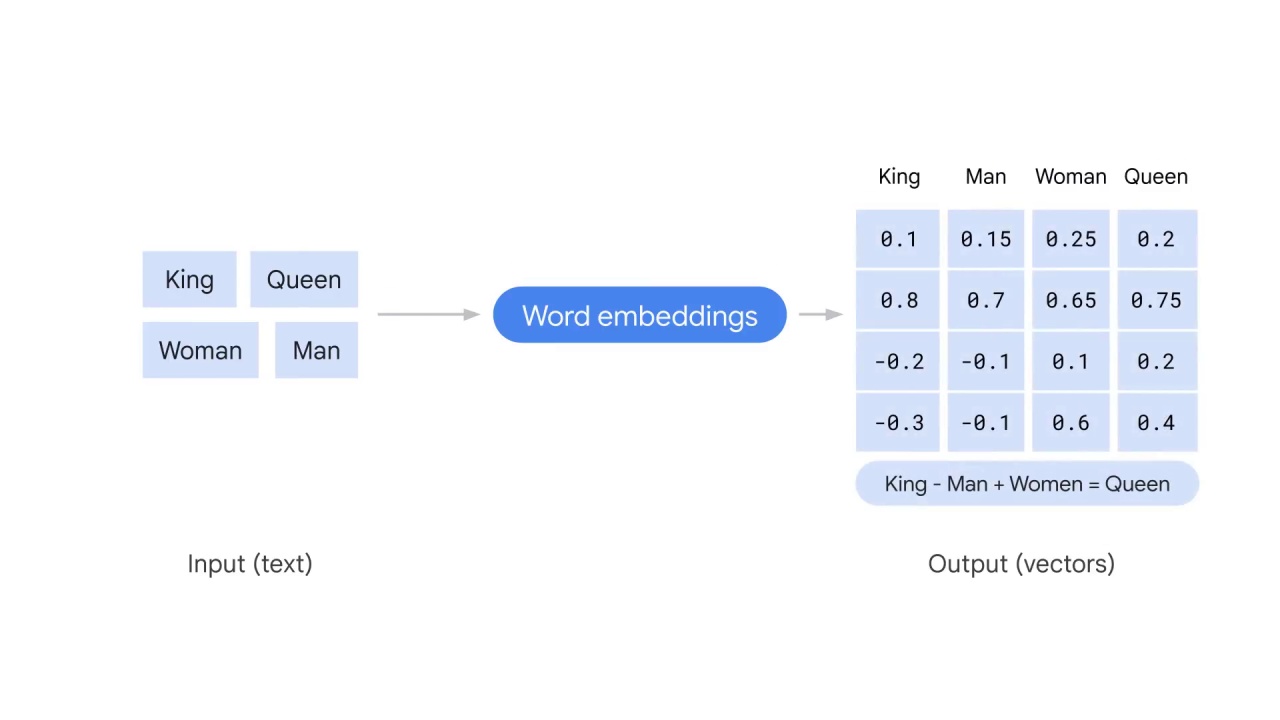
How do word embeddings do the magic to convert words such as king, queen, man, and woman to vectors that convey the semantic similarities?
Word embedding is an abstract term or a technique that includes a few concrete algorithms or models such as
word2vec by Google, which is considered a breakthrough for applying neural networks to text representations.
GloVe by Stanford,
FastText by Facebook, etc.