ML lifecycle
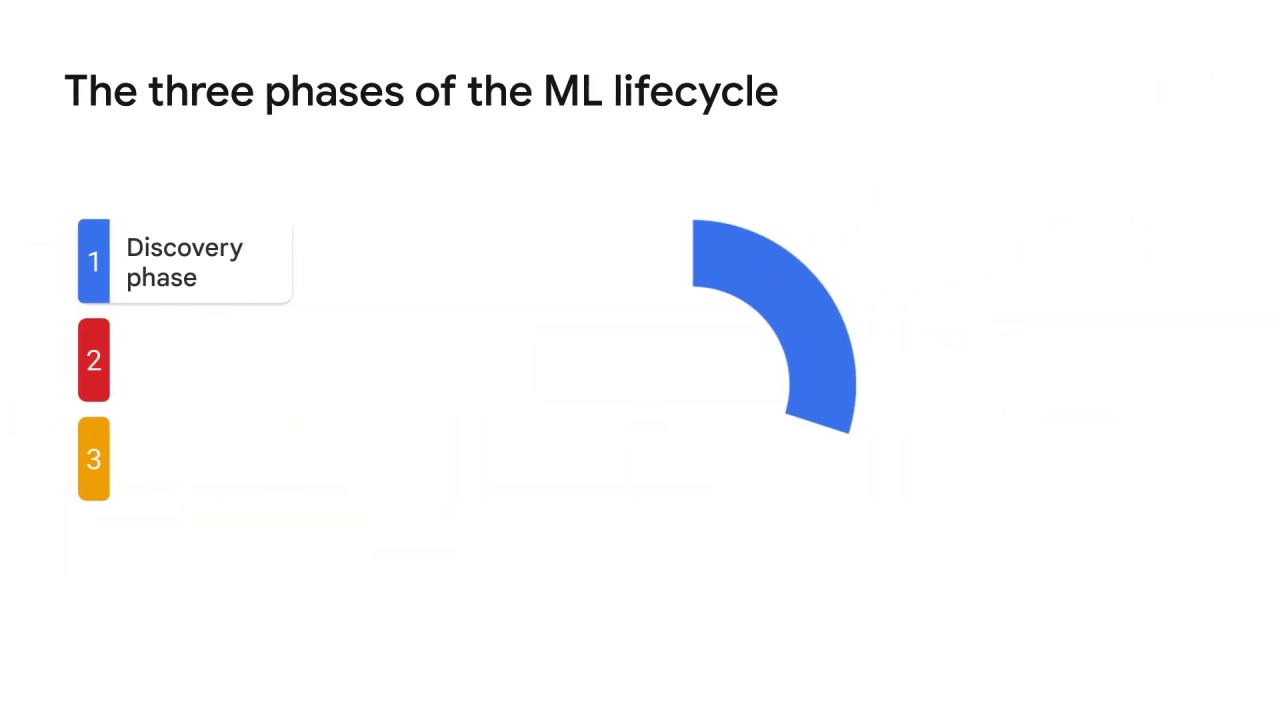
The first is the discovery phase,
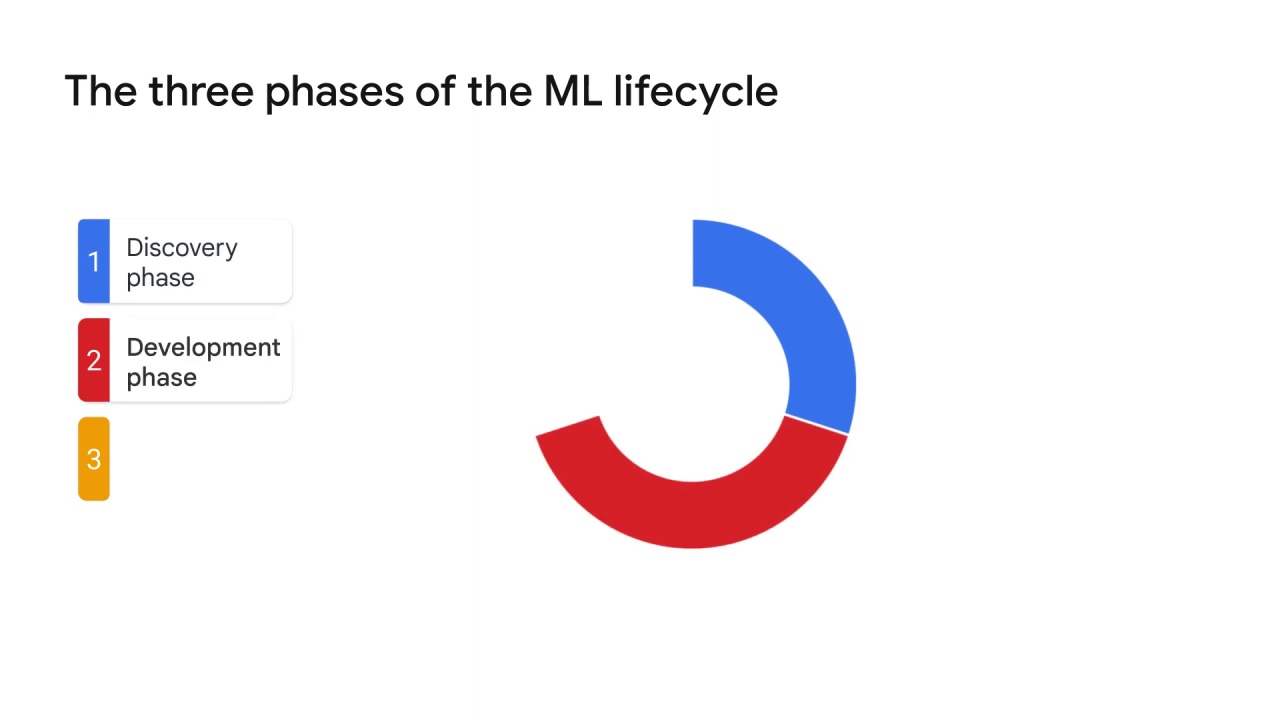
the second one is the development phase,
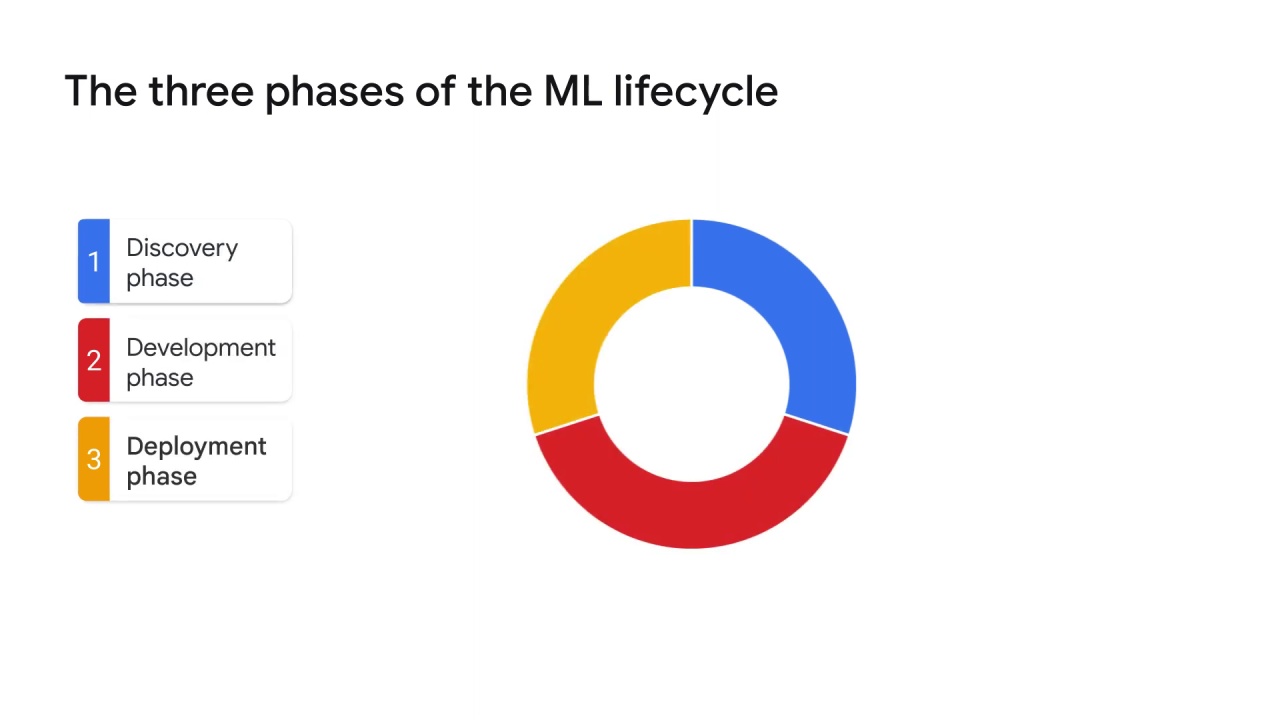
and the third one is the deployment phase.
The discovery phase is where the problem is defined and the desired outcome is identified.
Some of the tasks performed in this phase can be the following:
Business use case definition: Identifying the business need and the desired outcome allows for a clear plan of what a machine learning model will help achieve.
Contextual understanding:
The discovery phase also includes gaining contextual understanding of the people who are using or may be affected by the solution.
This critical information can help further define the problem or task that needs to be solved.
Use case feasibility:
It’s also important to assess whether the problem that you’re trying to solve can actually be solved with machine learning.
Let’s say that you have historical data that can’t be accessed during inference time.
If that’s the case, ML might not be a feasible option to solve your problem.
You’ll probably need to perform a more comprehensive analysis before moving forward.
Data accessibility and data exploration:
During this phase, it’s important to determine which datasets are needed for the ML model, and whether that data is readily available and good enough to train the model.
And if external datasets are needed, you must decide how to acquire them.
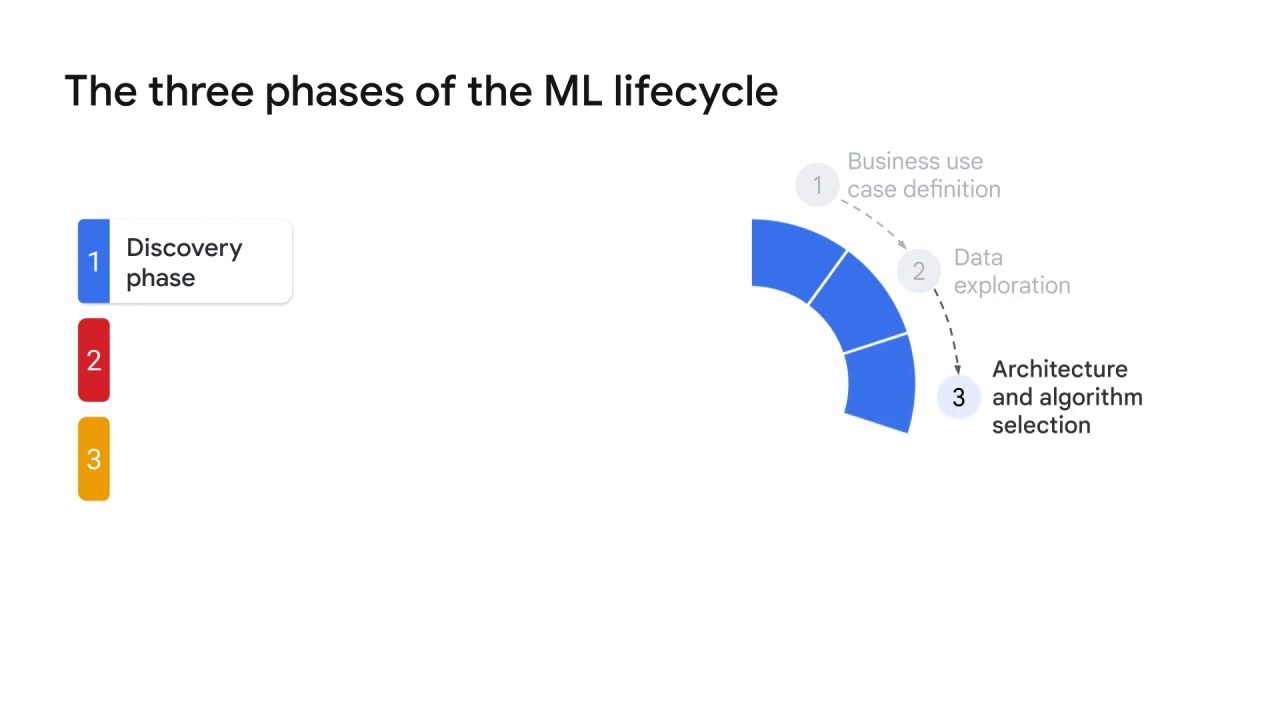
Architecture and algorithm selection:
Then, depending on the task that will be performed, the team chooses an architecture and a machine learning algorithm.
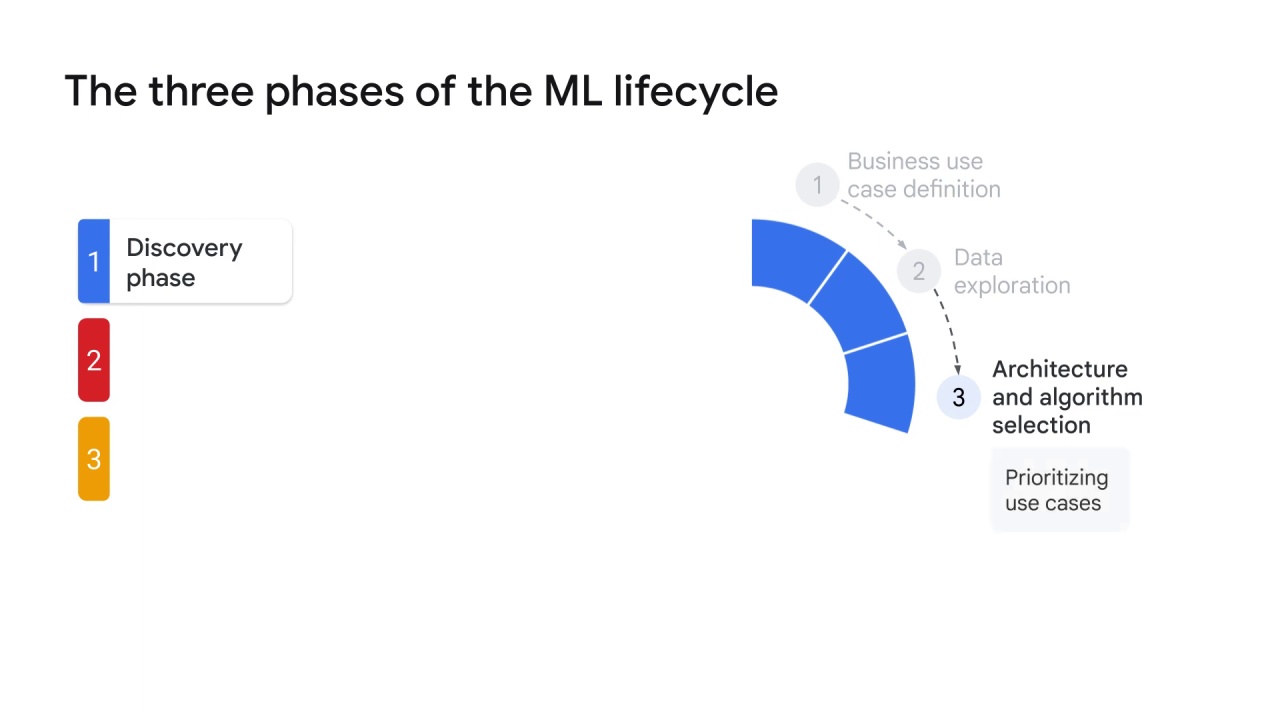
Prioritizing use cases:
Another aspect of the discovery phase is prioritizing the different use cases that the business has as potential ML projects.
Check the Managing Machine Learning Projects with Google Cloud course to learn more about identifying business value for using ML.
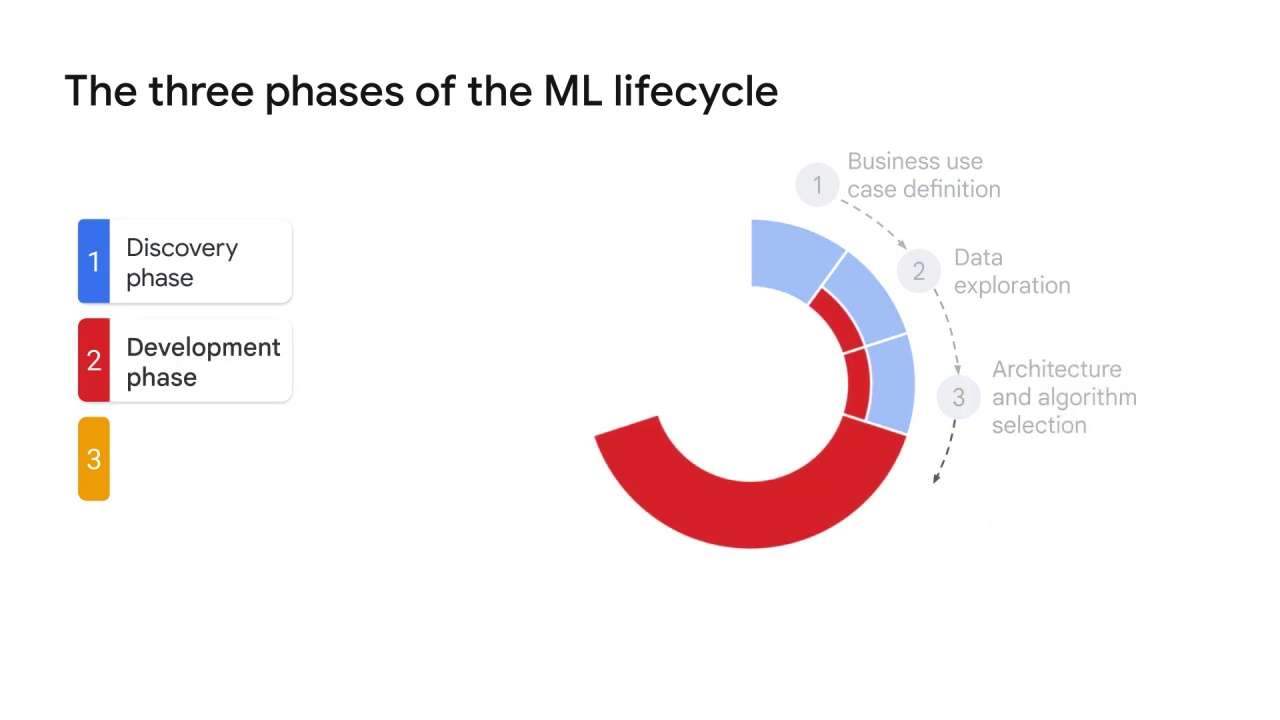
The development phase:
the second phase of the Machine Learning lifecycle is the development phase.
After the feasibility assessment is complete and you’ve got the go ahead, development can start.
However, sometimes you might see that the development phase starts during data exploration, which is part of the discovery phase.
Then you might ask this question: shouldn’t we wait until the results of the feasibility study are available?
However, in reality, even for data exploration and algorithm selection, some proof of concepts might need to be developed, and that is why the development phase and discovery phase overlap during the data exploration.
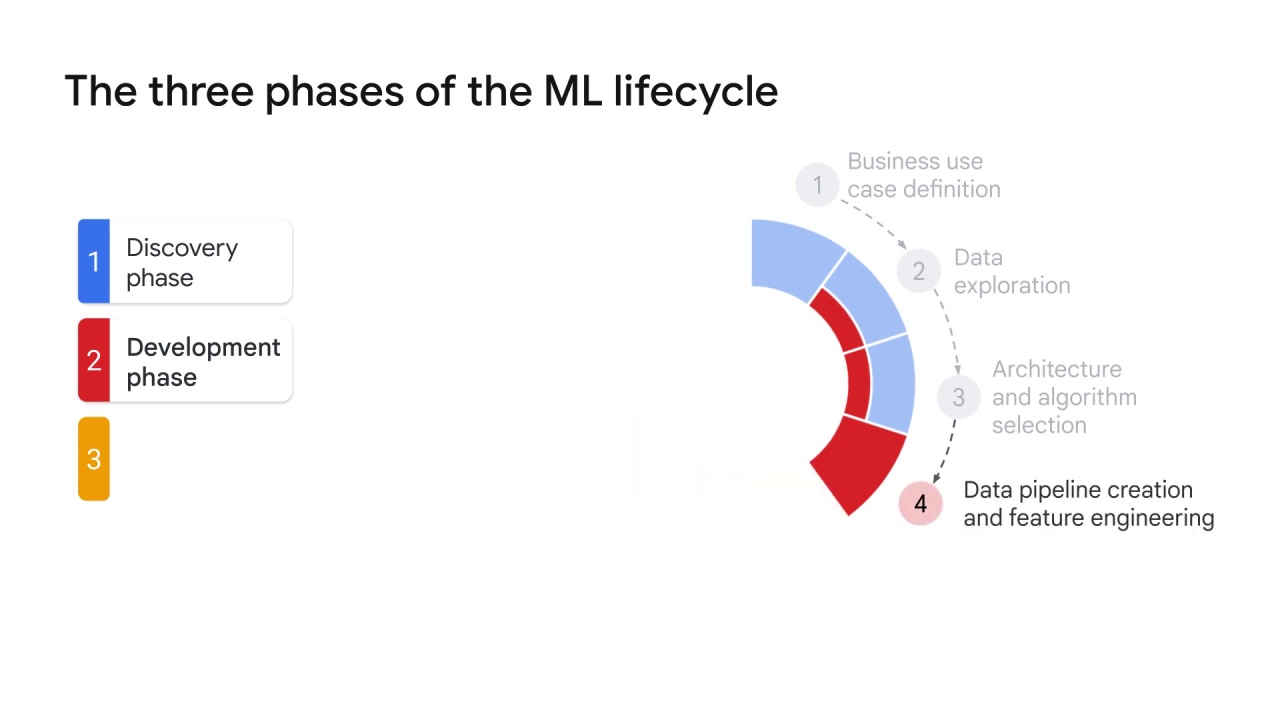
It starts with a data pipeline creation and feature engineering.
This is when all of the necessary data is cleaned, extracted, analyzed, and transformed for us in the model.
A data pipeline helps ensure that all data operations will perform as expected–for both offline and stream data–and avoid data skew.
You can visit the data preprocessing for ML documentation to learn more about best practices for preprocessing data in an ML pipeline.
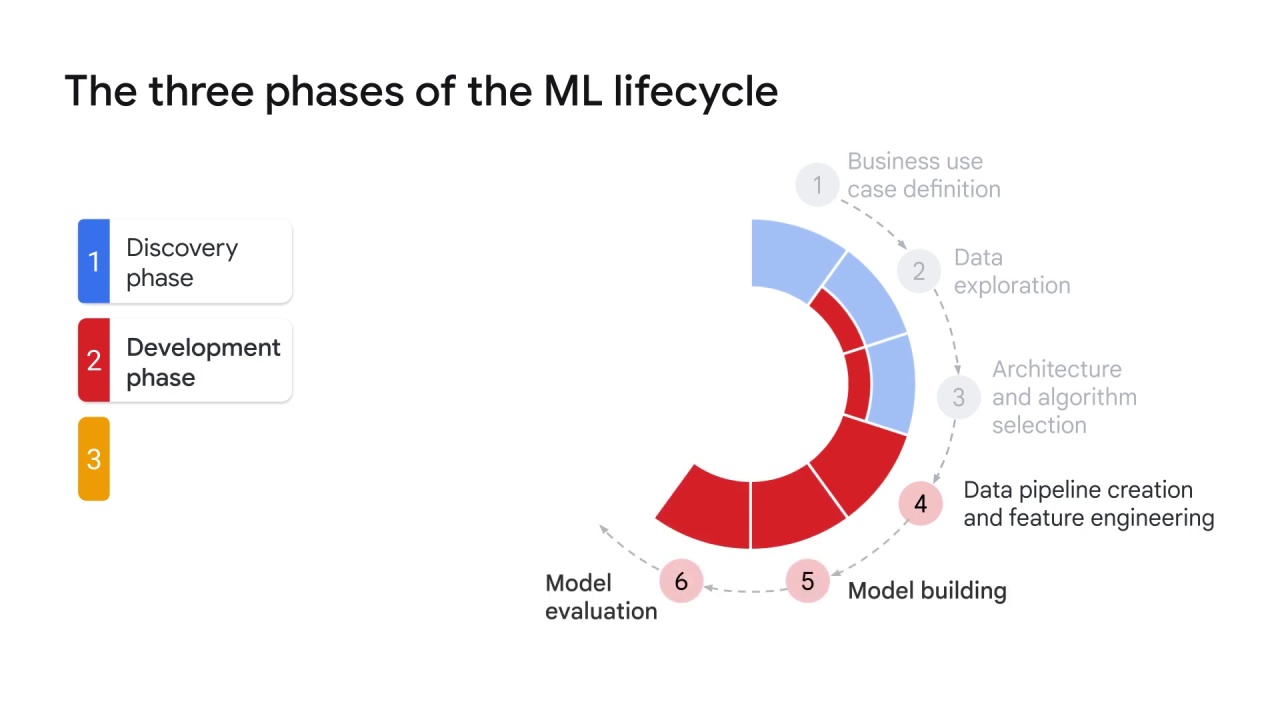
After the data is ready, model building and the model evaluation begins.
The word “begins” is used here because these steps might require a couple of iterations
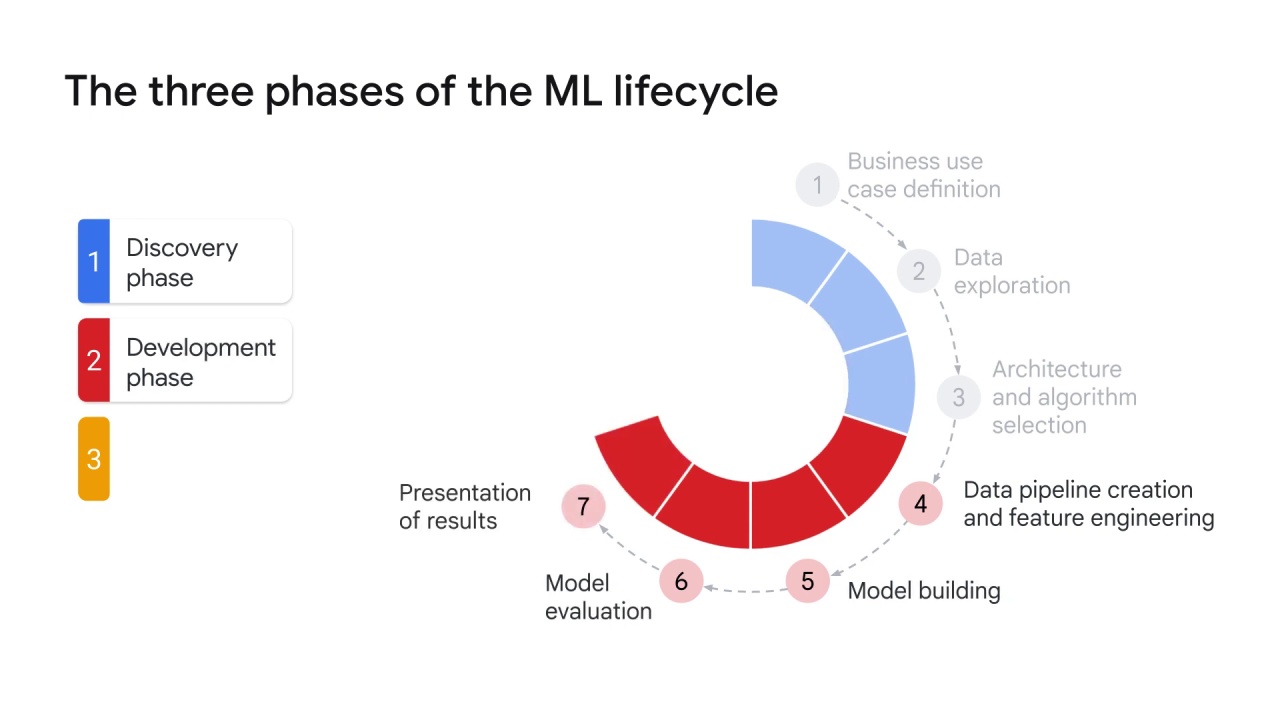
until the ML practitioners are happy with the results and are ready to present them to the main stakeholders.
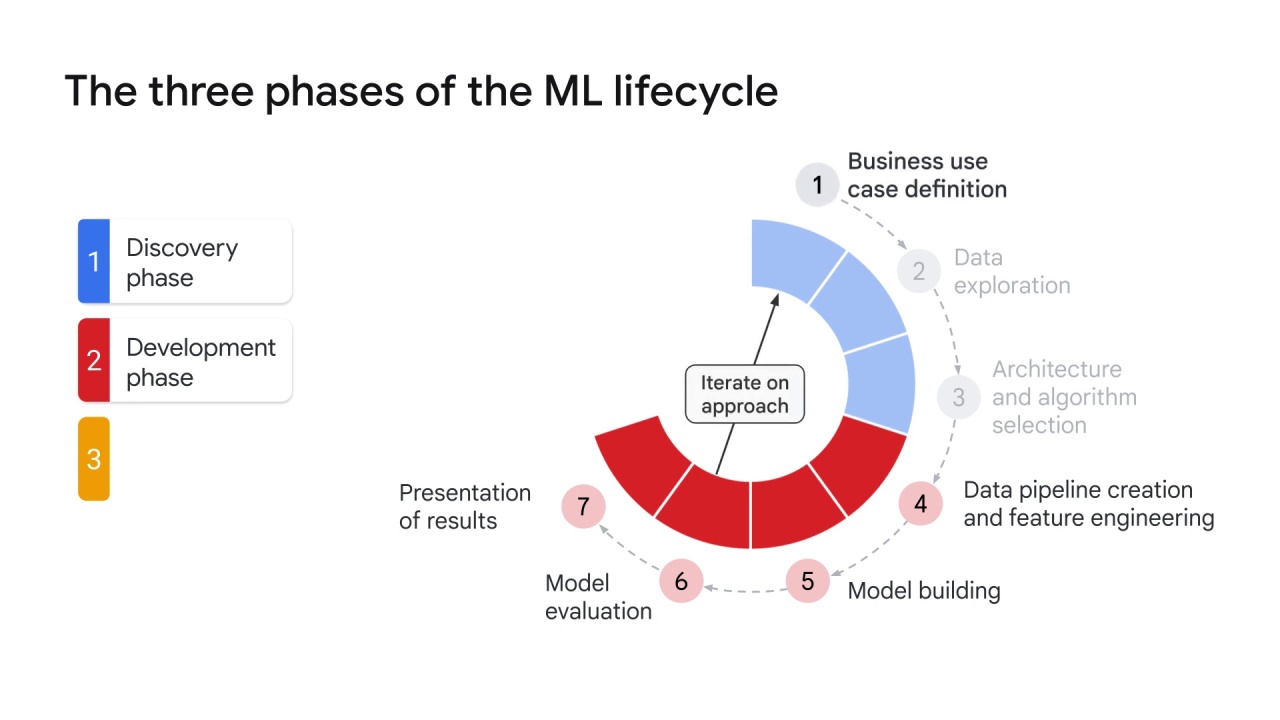
Iteration is a central concept of machine learning.
Constant iteration, tuning, and improvement is often required to ensure that a model performs as planned.
During this phase, it might be helpful to perform some, or all, of the following activities.
First, revisit the model use case.
Because the ML algorithm might not identify data patterns for your use case in the first iteration, you might want to ensure that the model will still help you achieve your goal.
Revisit the chosen dataset to determine whether the model requires a higher volume or new features.
Data should be revisited because the model either needs more of it or it needs additional aspects or new features from the existing data.
And finally, it might be helpful to consider whether additional data transformations are needed to improve the model quality, or whether a different algorithm might be better.
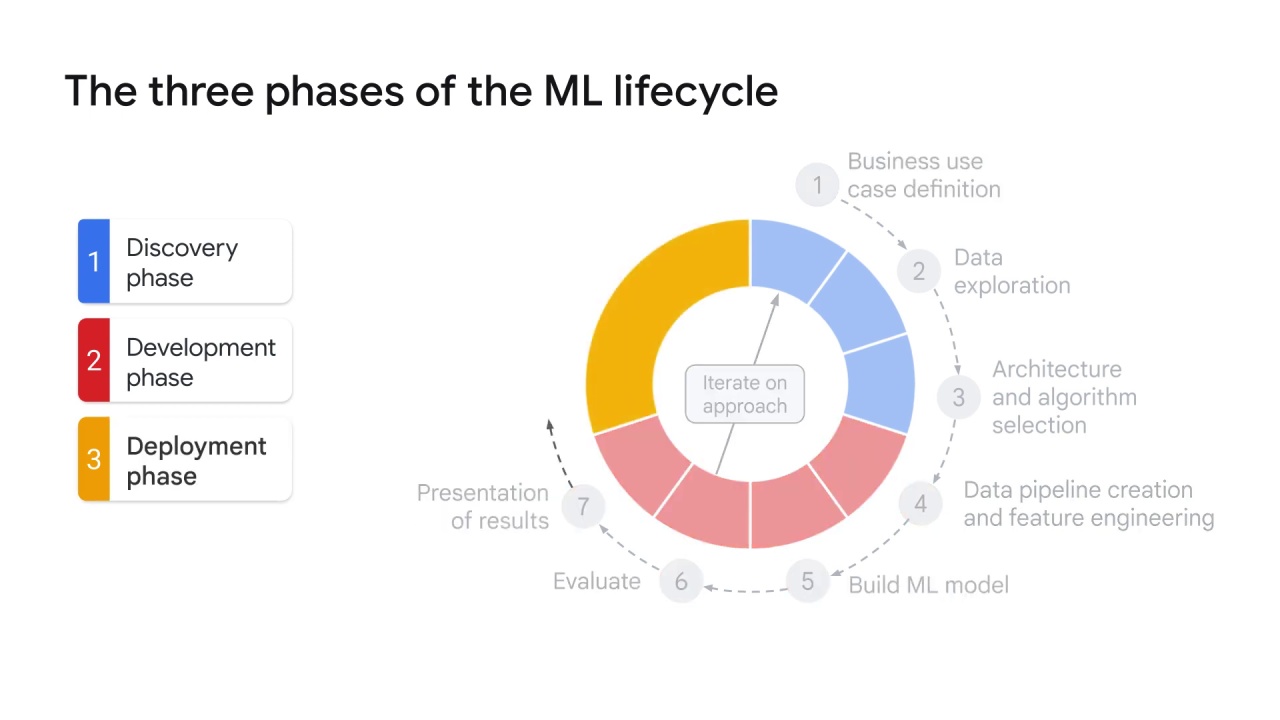
The deployment phase:
The last phase of the ML lifecycle is the deployment phase.
Some of the tasks performed in this phase can be the following:
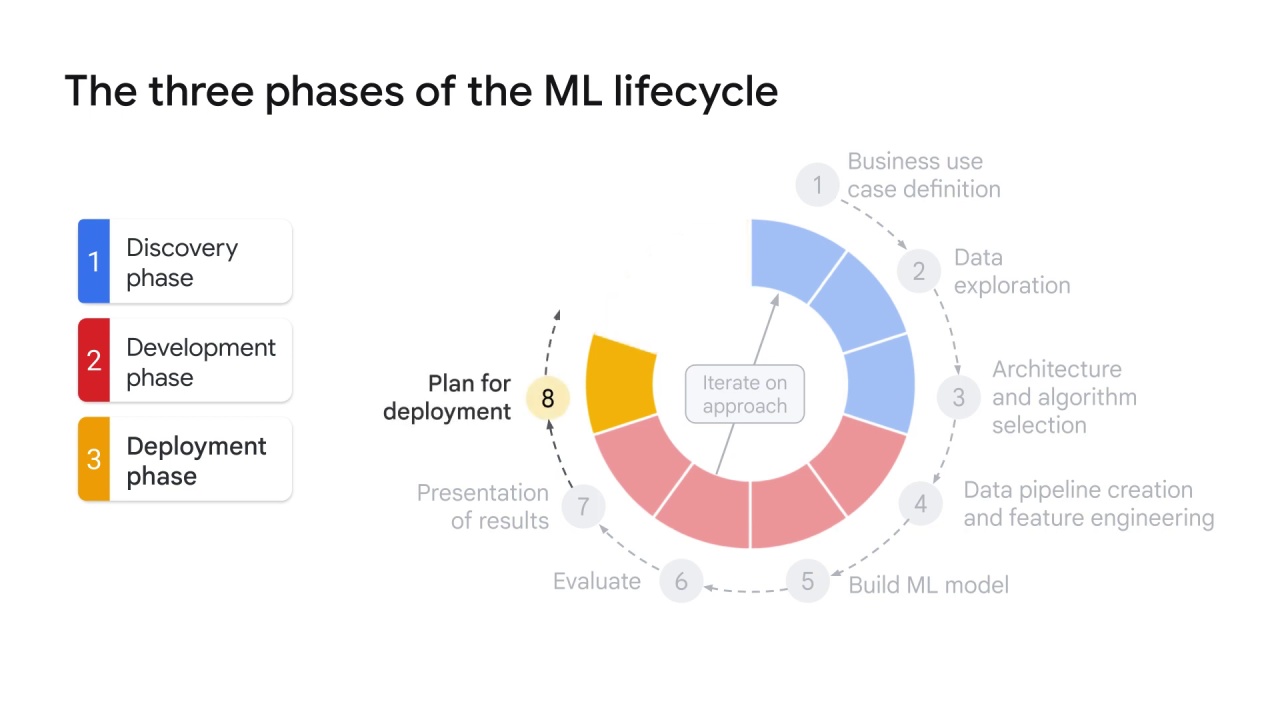
Plan for deployment:
After results are presented to the stakeholders and all parties are satisfied with the model performance, it’s time to plan for model deployment.
This is when the following questions can arise:
Which platform should host the model?
Which ML model serving tools are needed?
And how many nodes are needed for the cluster to scale the model in a cost-effective manner?
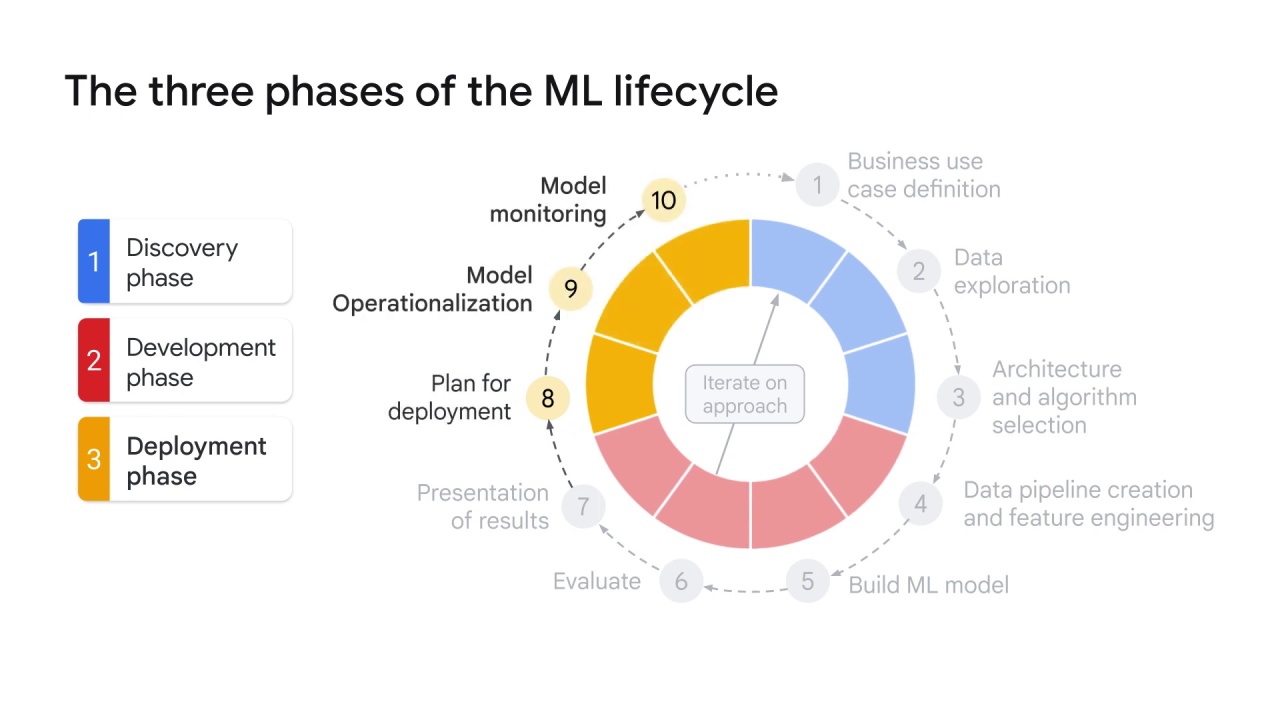
Model Operationalization and Monitoring:
As previously mentioned, operationalizing and monitoring a model helps with maintenance and avoiding model decay.
Implementing a strategy to detect a concept or data drift allows signaling when the model needs to be retrained or when the data needs to be adjusted or augmented.
Many people could be reliant on your model’s predictions, so it’s important to ensure that your pipeline accounts for all the necessary health checks and alerts.