Why distributed training is needed

In this module, we’ll explore how to run a distributed training job with TensorFlow.

We’ll begin with understanding
why distributed training is needed
After that, we’ll explore
distributed training architectures.
Then lastly, we’ll provide an overview of
TensorFlow distributed training strategies
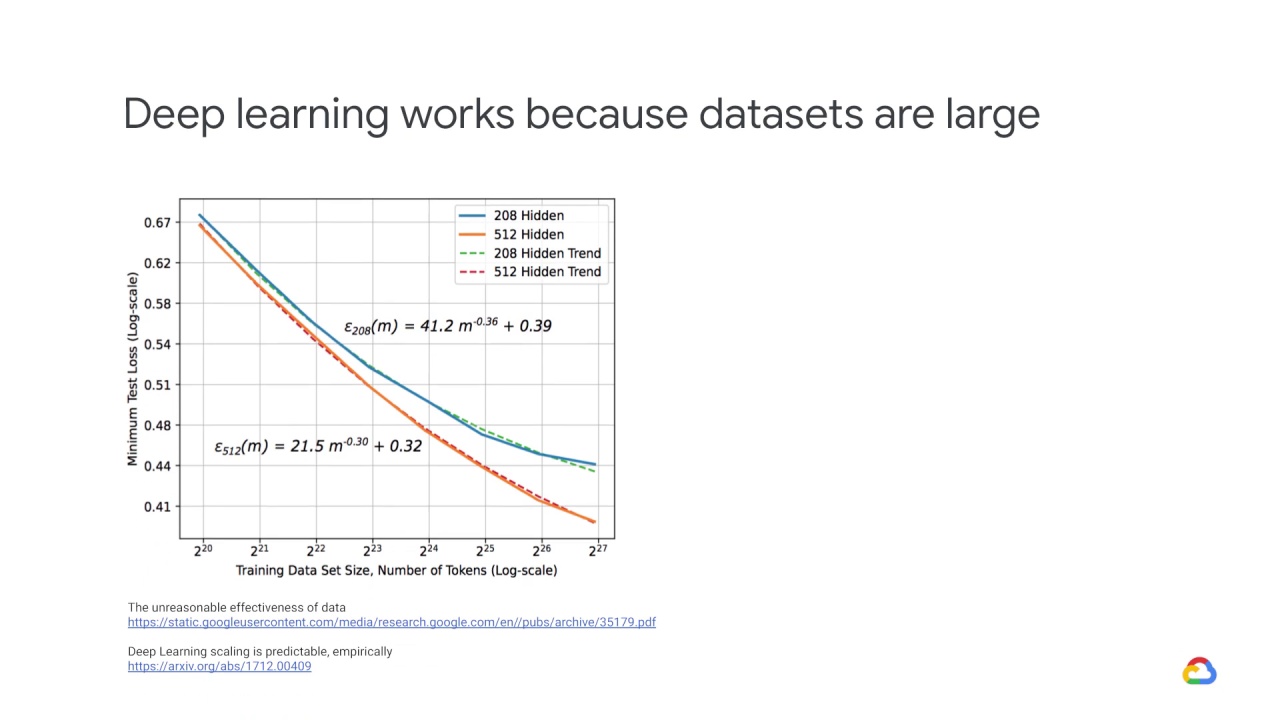
Deep learning works because datasets are large.
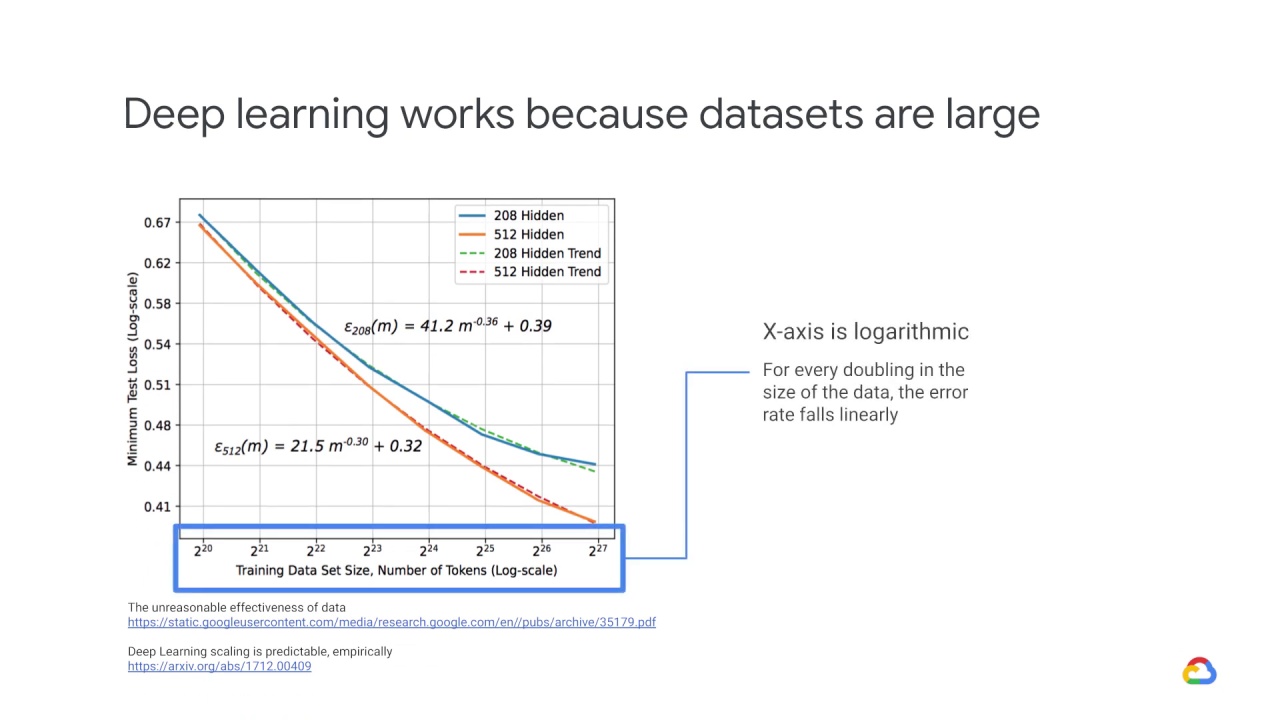
Notice that the x-axis here is logarithmic.
For every doubling in the size of the data, the error rate falls linearly.
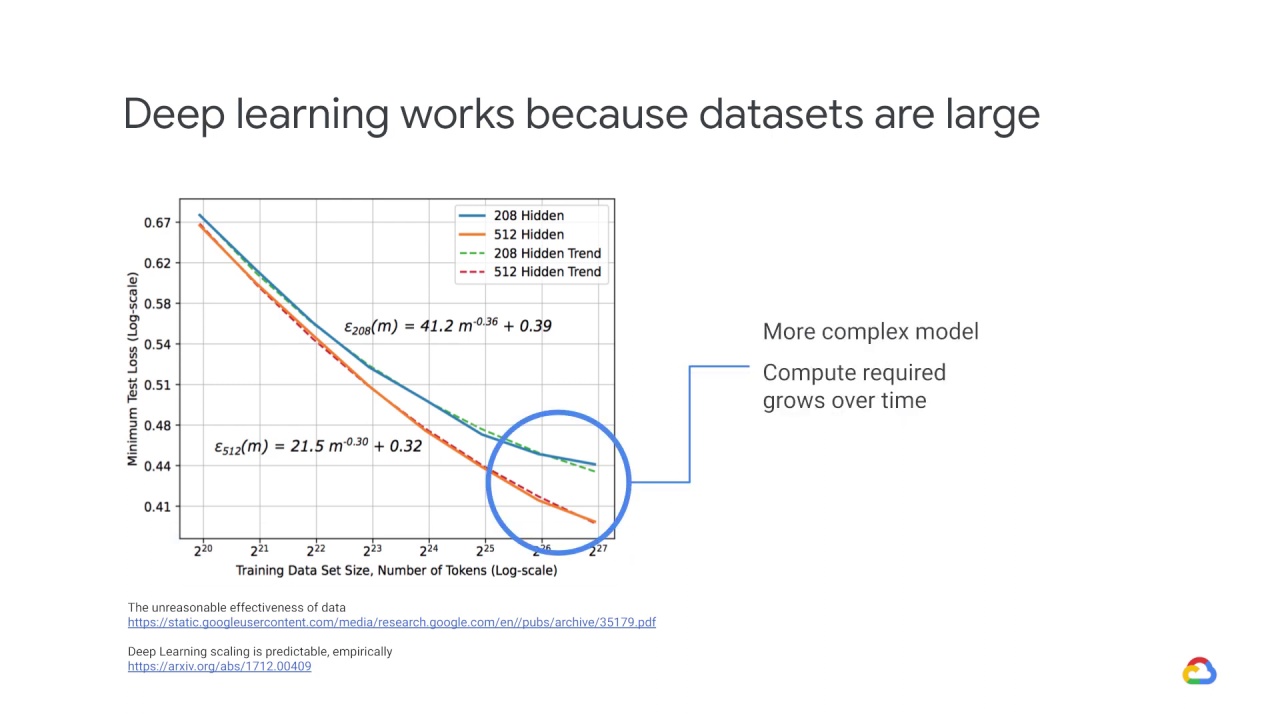
A more complex model also helps – that is the jump from the blue line to the orange line – but more data is even more helpful in this situation.
As a consequence of both of these trends, in terms of larger data sizes and more complex models, the compute required to build state-of-the-art models has grown over time.
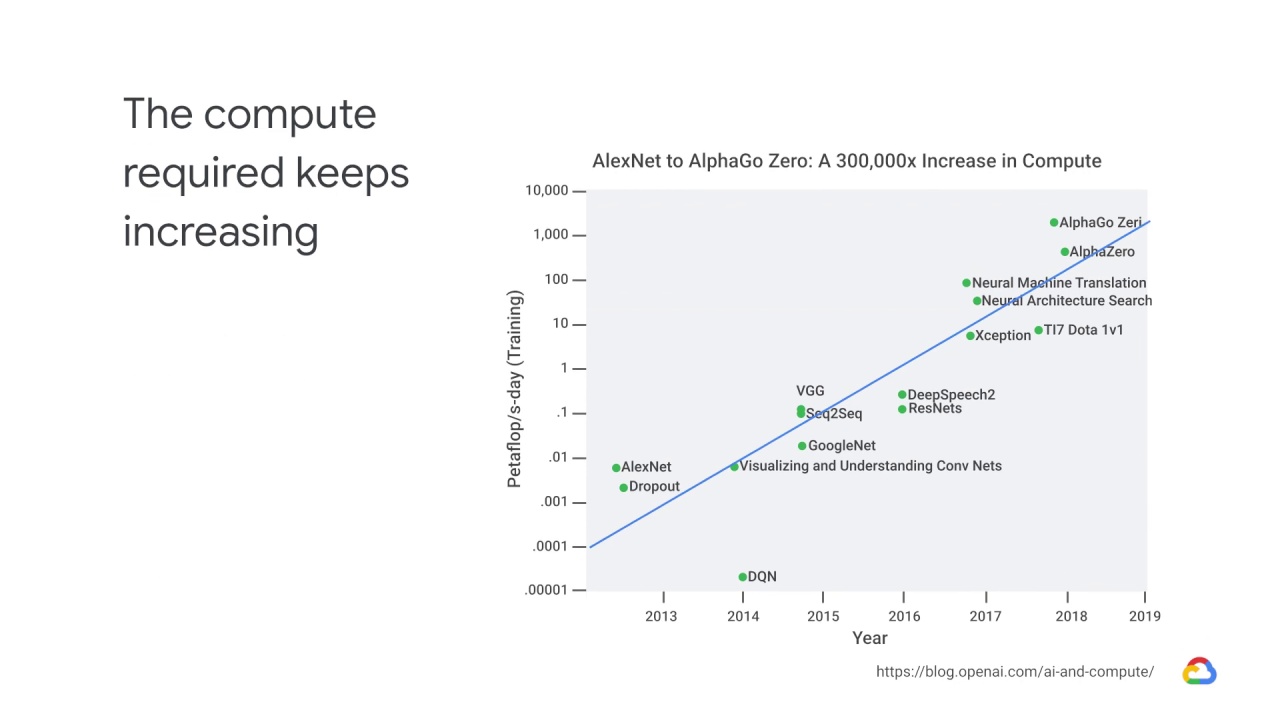
This growth is exponential as well.
Each y-axis tick on this graph
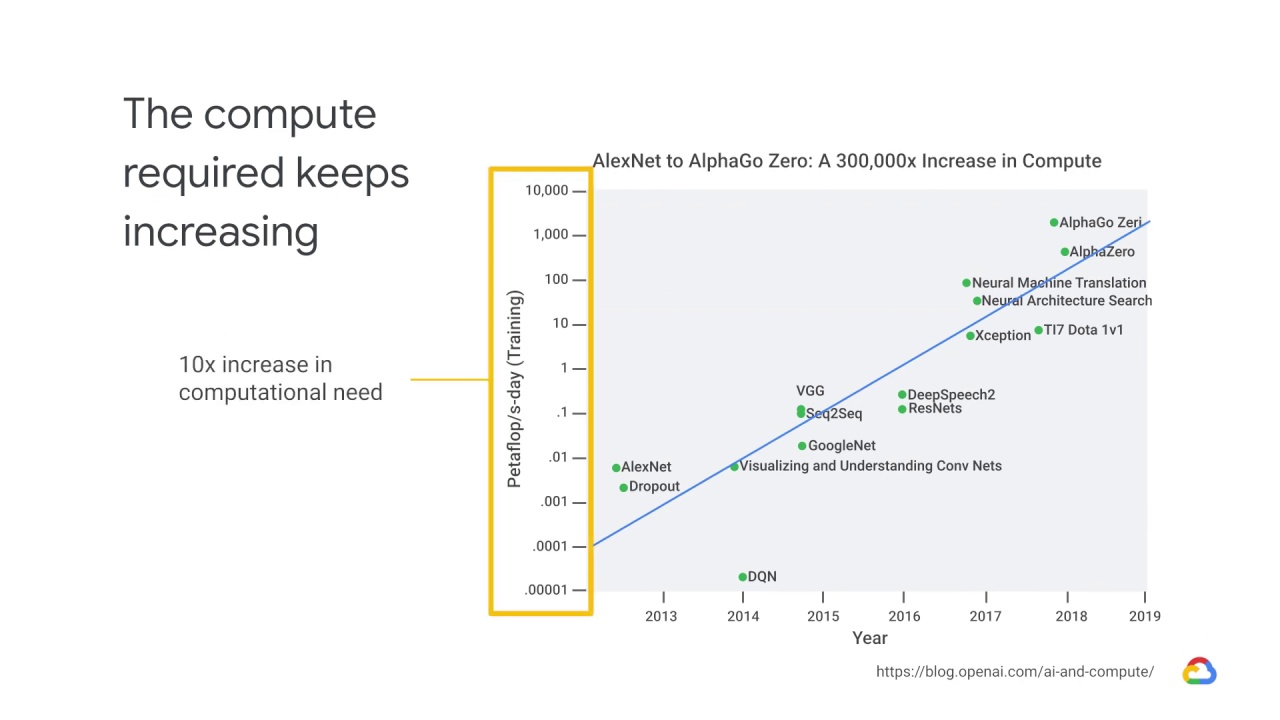
shows a 10x increase in computational need
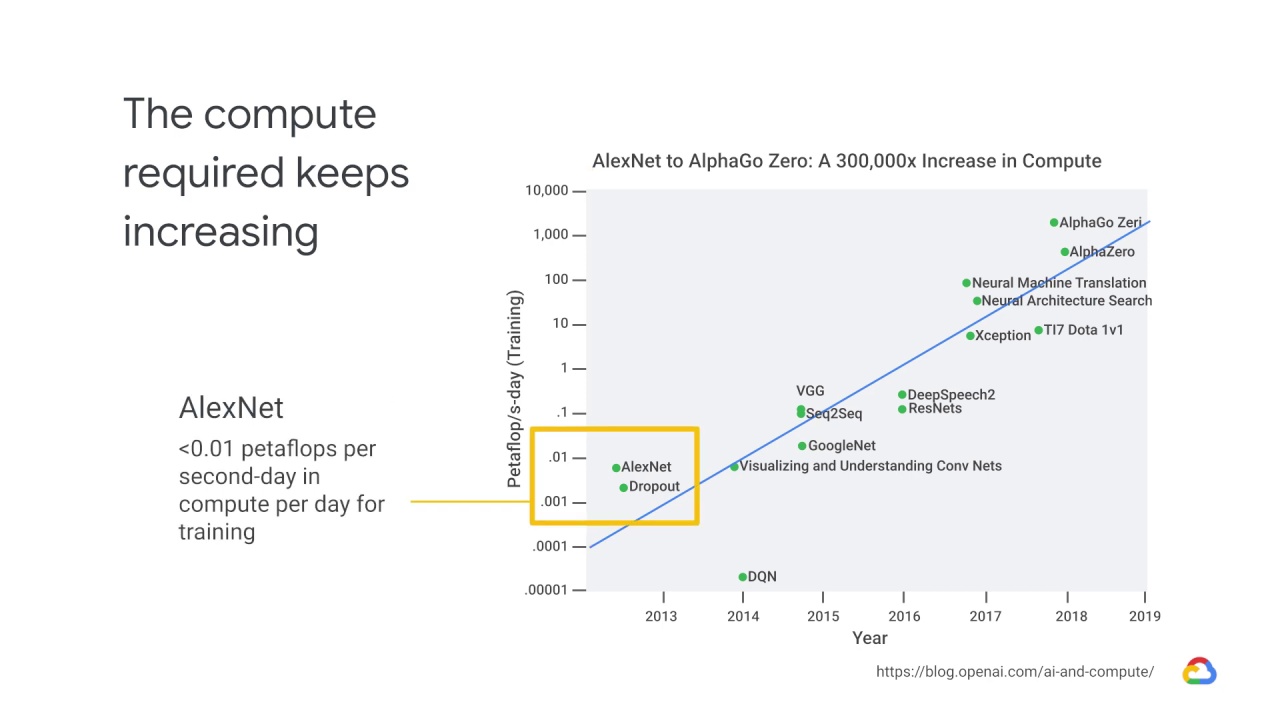
AlexNet, which started the deep learning revolution in 2013, required less than 0.01
petaflops per second-day in compute per day for training.
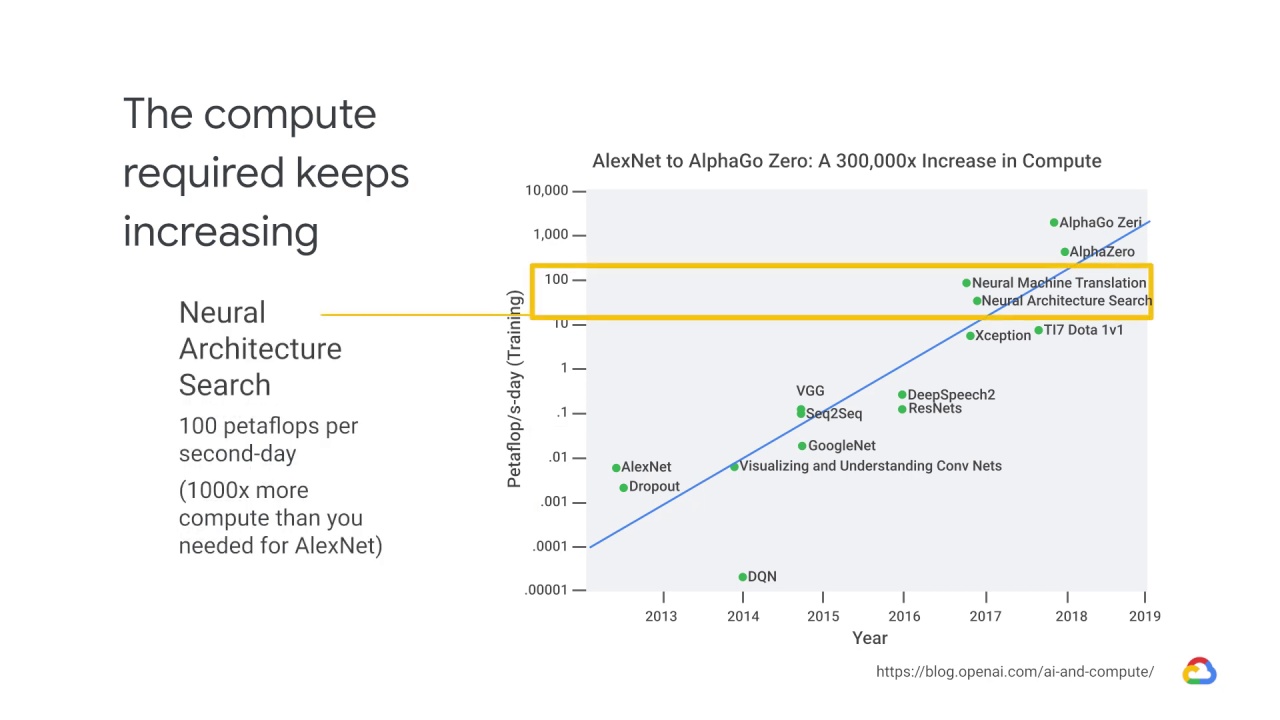
By the time you get to Neural Architecture Search, the learn-to-learn model published
by Google in 2017, you need about 100 petaflops per second-day or 1000x more
compute than you needed for AlexNet.
This growth in algorithm complexity and data size means that, with complex models and large data volumes, distributed systems are pretty much a necessity when it comes to machine learning.
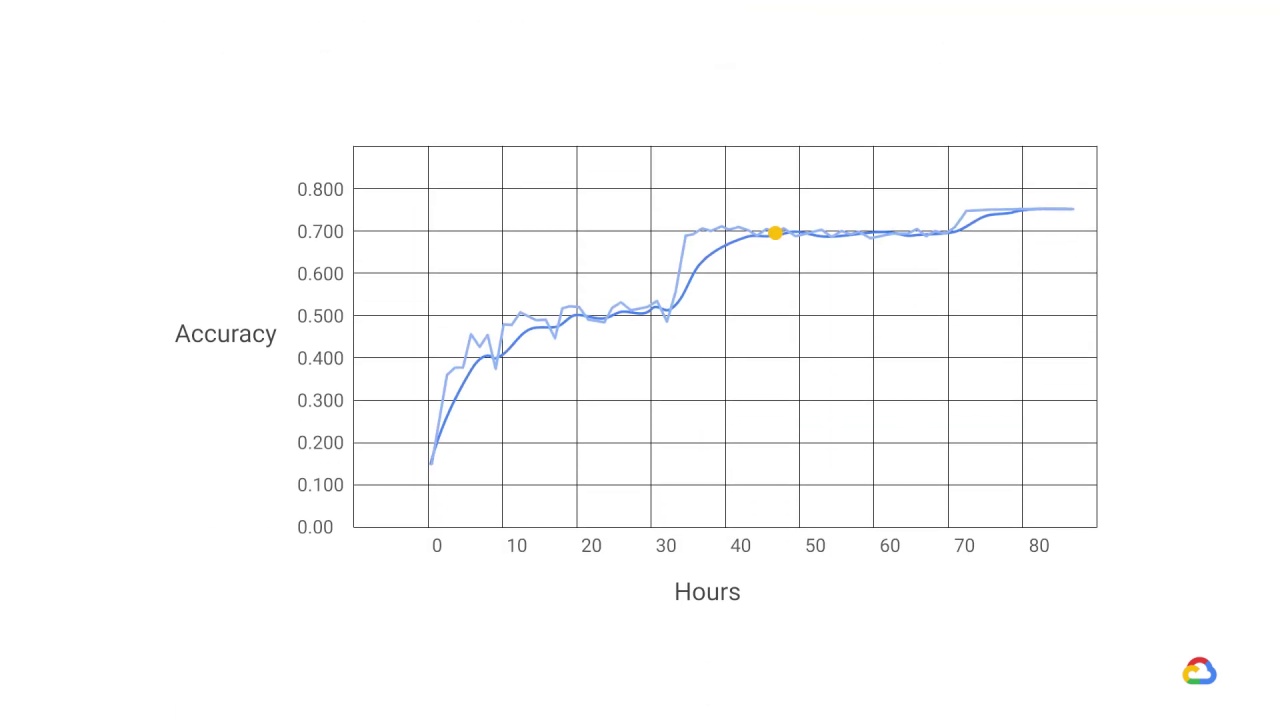
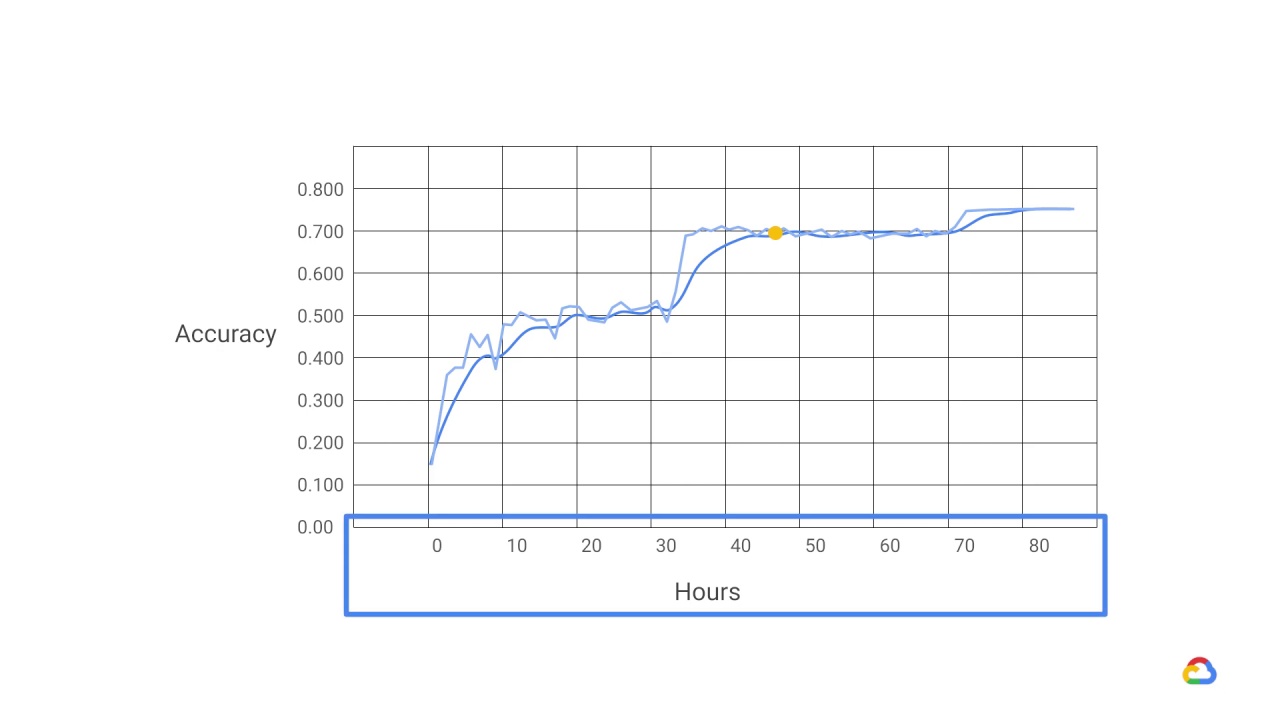
Training complex networks with large amounts of data can often take a long time.
This graph shows training time on the x-axis plotted against
the accuracy of
predictions on the y-axis, when training an image recognition model on a GPU.
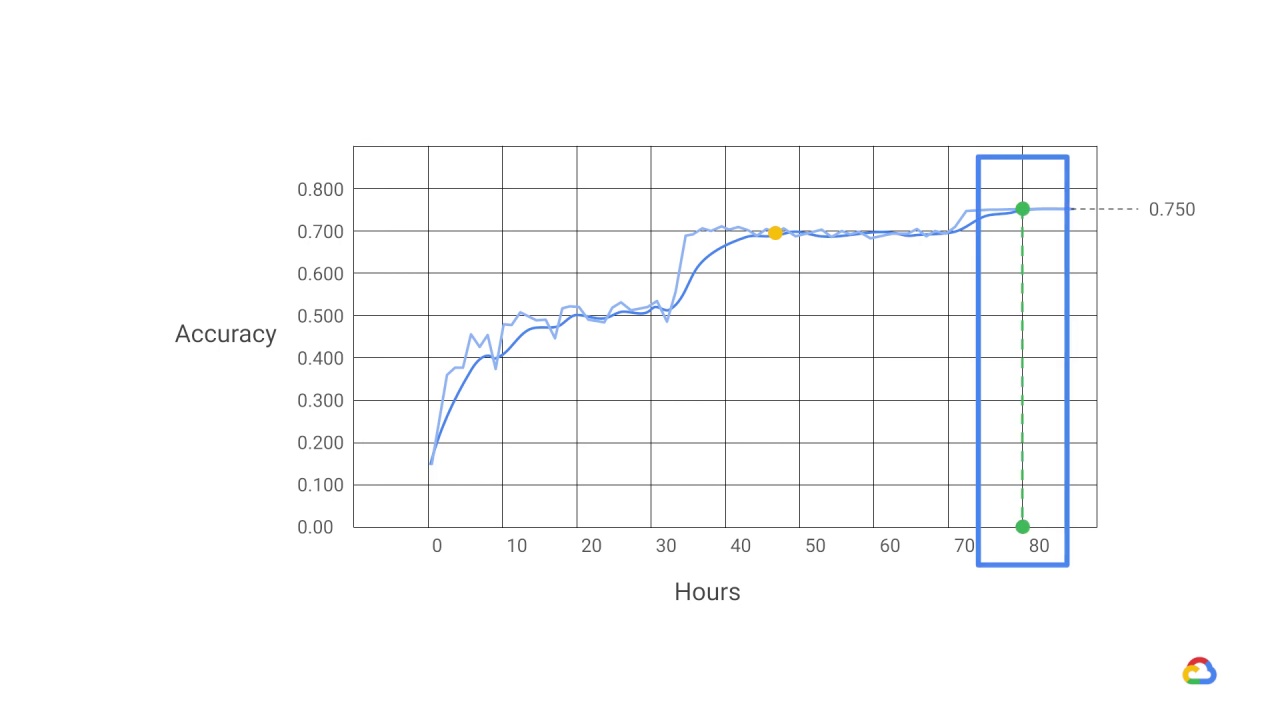
As the dotted line shows, it took around 80 hours to reach 75% accuracy.
If your training takes a few minutes to a few hours, it will make you productive and happy, and you can try out different ideas fast.
If the training takes a few days, you could still deal with that by running a few ideas in parallel.
If the training starts to take a week or more, your progress will slow down because you can’t try out new ideas quickly.

And if it takes more than a month… Well that’s probably not even worth thinking about!
And this is no exaggeration.
Training deep neural networks such as ResNet50 can
take up to a week on one GPU.

A natural question to ask is - how can you make training faster?

You can use a more powerful device such as
TPUorGPU(accelerator).

You can optimize your input pipeline.

Or, you can try out distributed training.