Using Vertex AI
As you’ve seen, the machine learning ecosystem requires decision making at every stage.
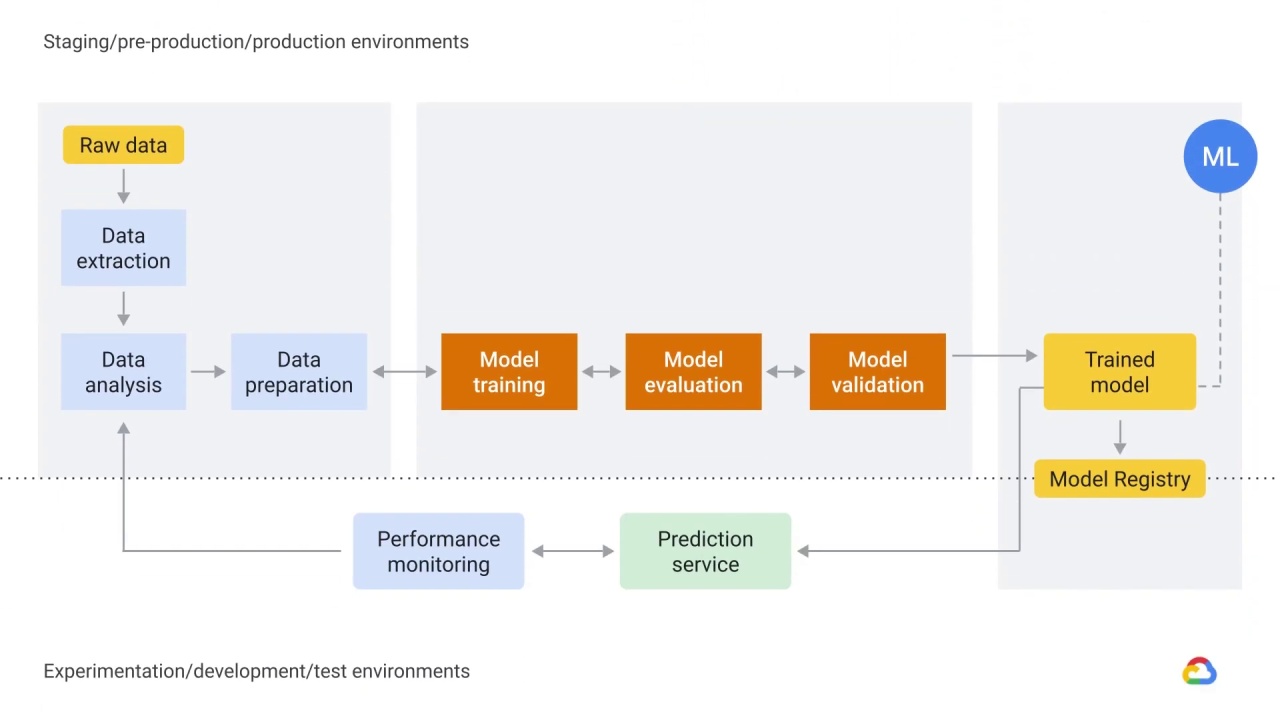
You need to determine how to handle and prepare data, and also how to design, build, evaluate, train, and monitor a model’s performance.
Decisions around workflow processes, how to implement or execute those processes, and the management of the workflow itself are required to solve machine learning problems.
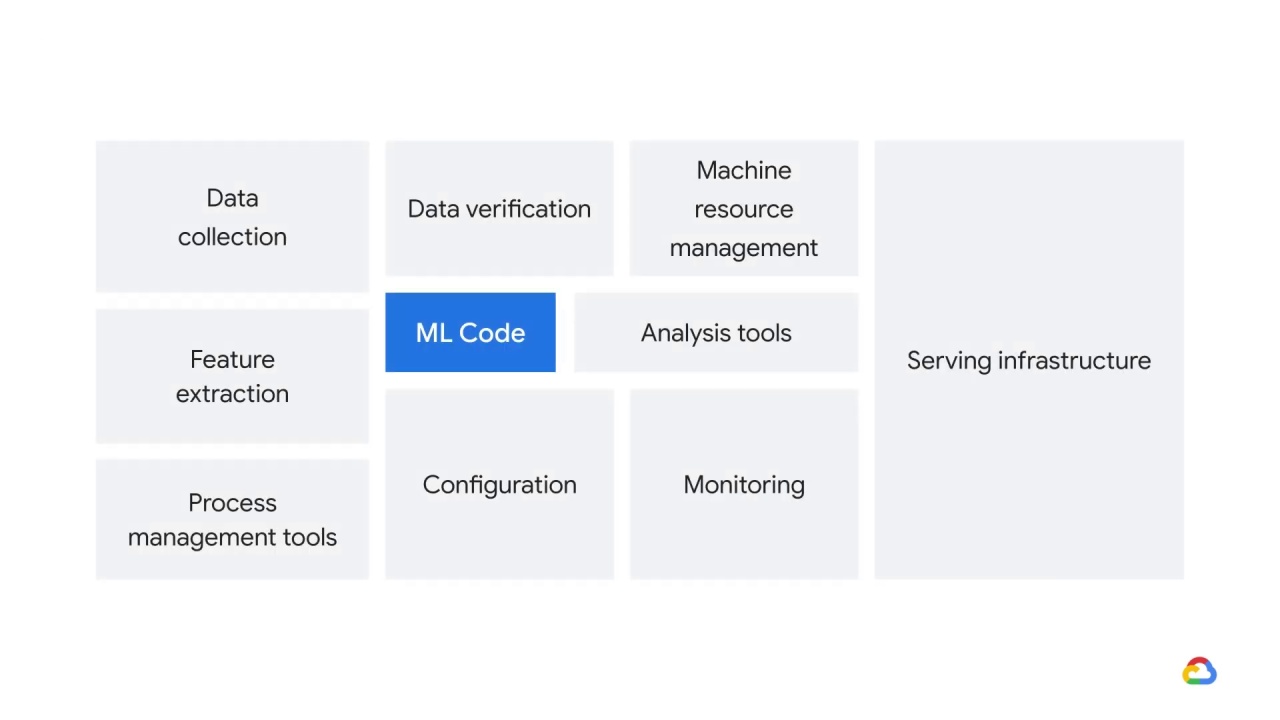
One of the most interesting details about the ML ecosystem is that ML code accounts for only a small percentage of it.
To keep a system running in production requires a lot more than just computing the model’s outputs for a given set of inputs.
This means that each component of the ML ecosystem requires not only decisions and processes, but also people.

According to the International Data Corporation, in 2020, a lack of staff with the right expertise, a lack of production-ready data, and a lack of an integrated development environment were reported as primary reasons that machine learning technologies fail.

So, how do you ensure success for your machine learning or AI use case?
And how can you or your team

prepare and manage your data,

build your models
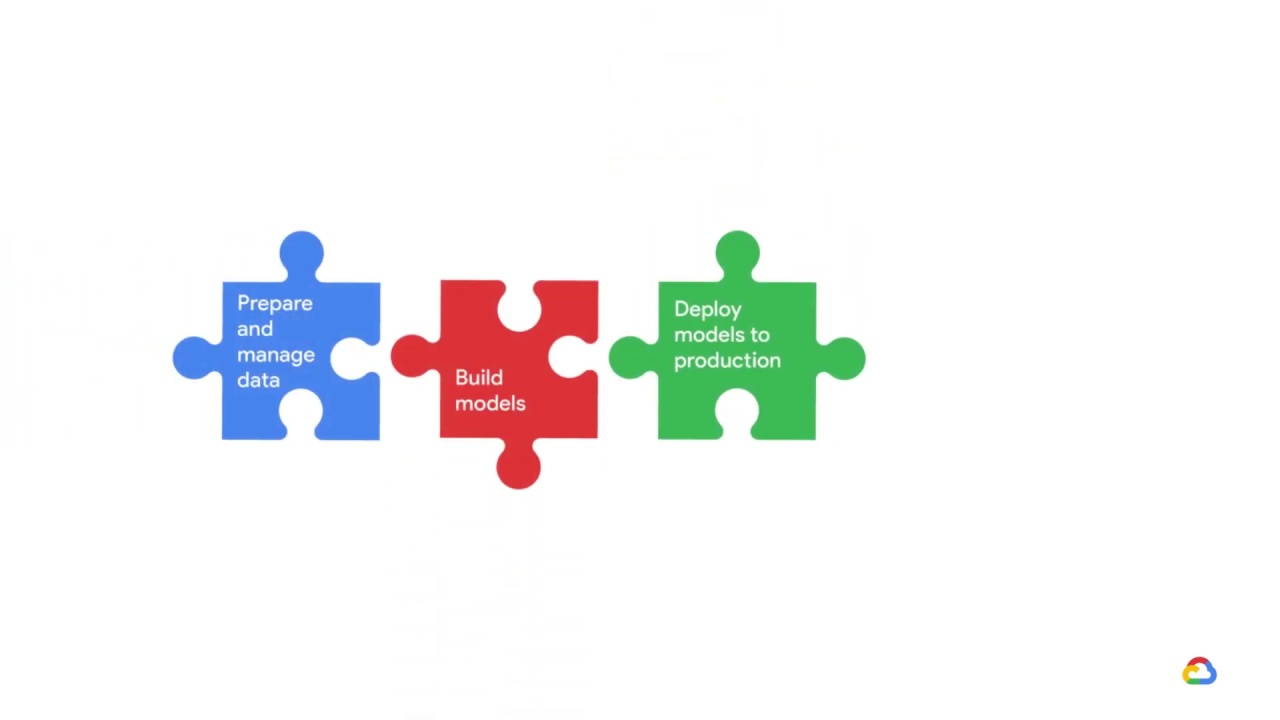
deploy them into production,
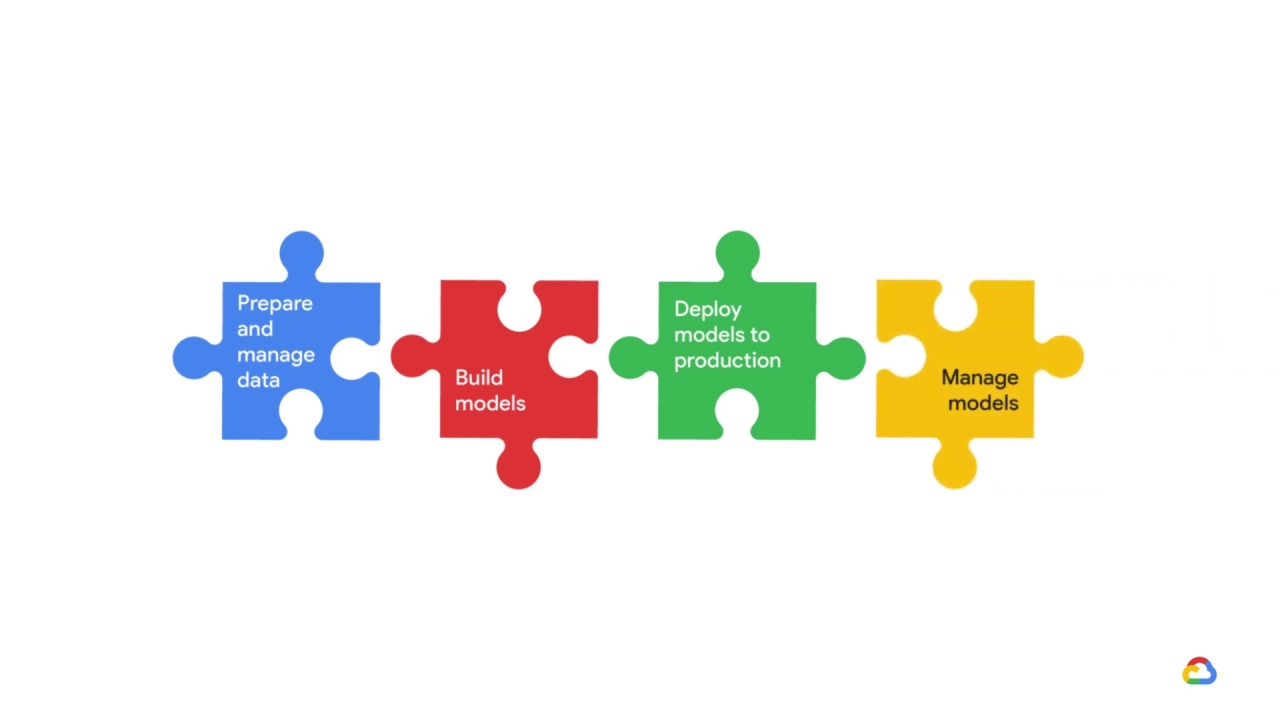
and then manage them?

A solution is to use a unified platform that brings all the components of the machine learning ecosystem and workflow together.

And in this case, that platform is Vertex AI.
Vertex AI brings together the Google Cloud services for building ML under one unified user interface and application programming interface, or API.
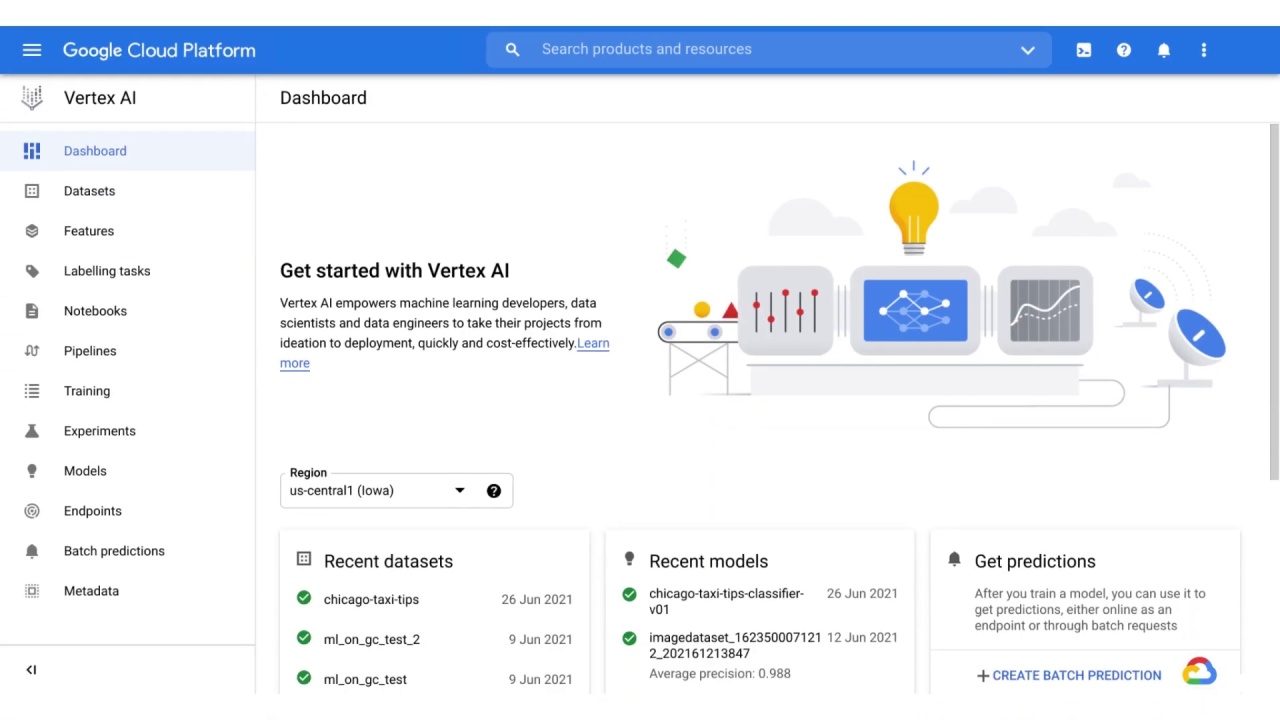
With Vertex AI, you can access a, dashboard, datasets, features, labeling tasks, notebooks, pipelines, training, experiments, models, endpoints, batch predictions, and metadata.
Let’s take a closer look at the Datasets, Notebooks, Training, and Models sections of the Vertex AI navigation bar that help you to prepare your data and build and deploy your models.
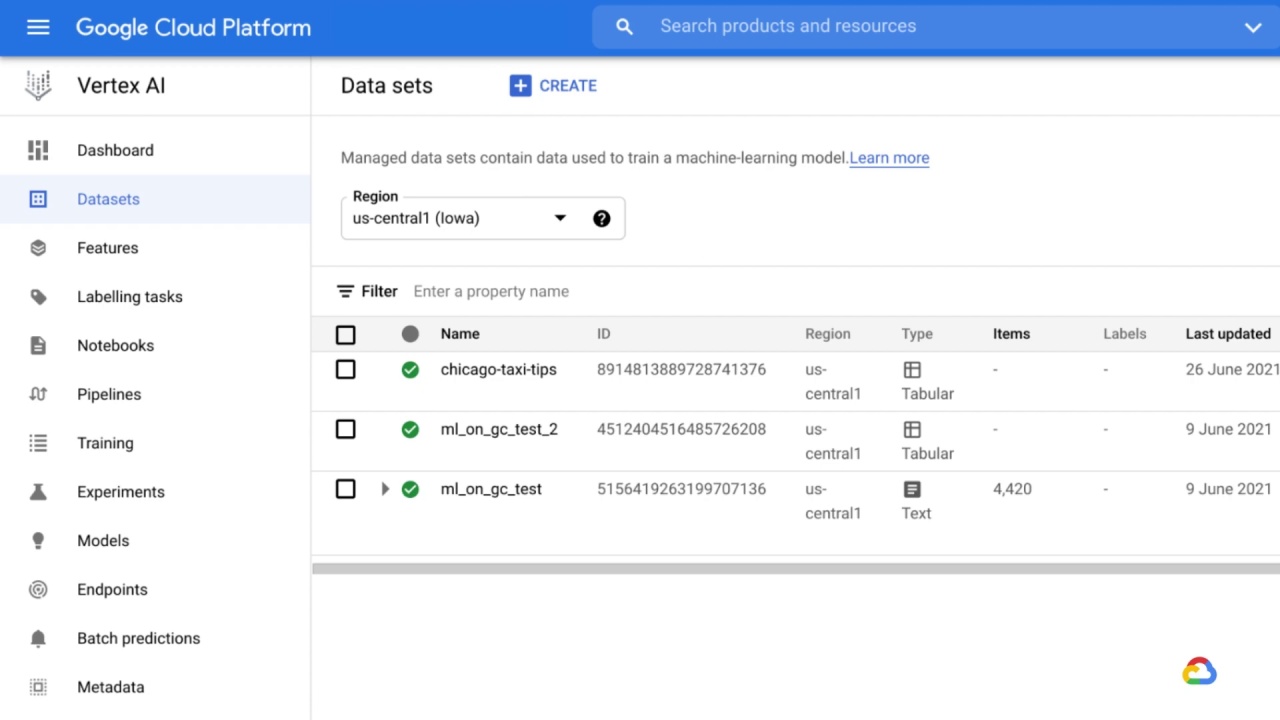
Vertex AI has a unified data preparation tool that supports image, tabular, text, and video content.
Uploaded datasets are stored in a Cloud Storage bucket that acts as an input for both AutoML and custom training jobs.

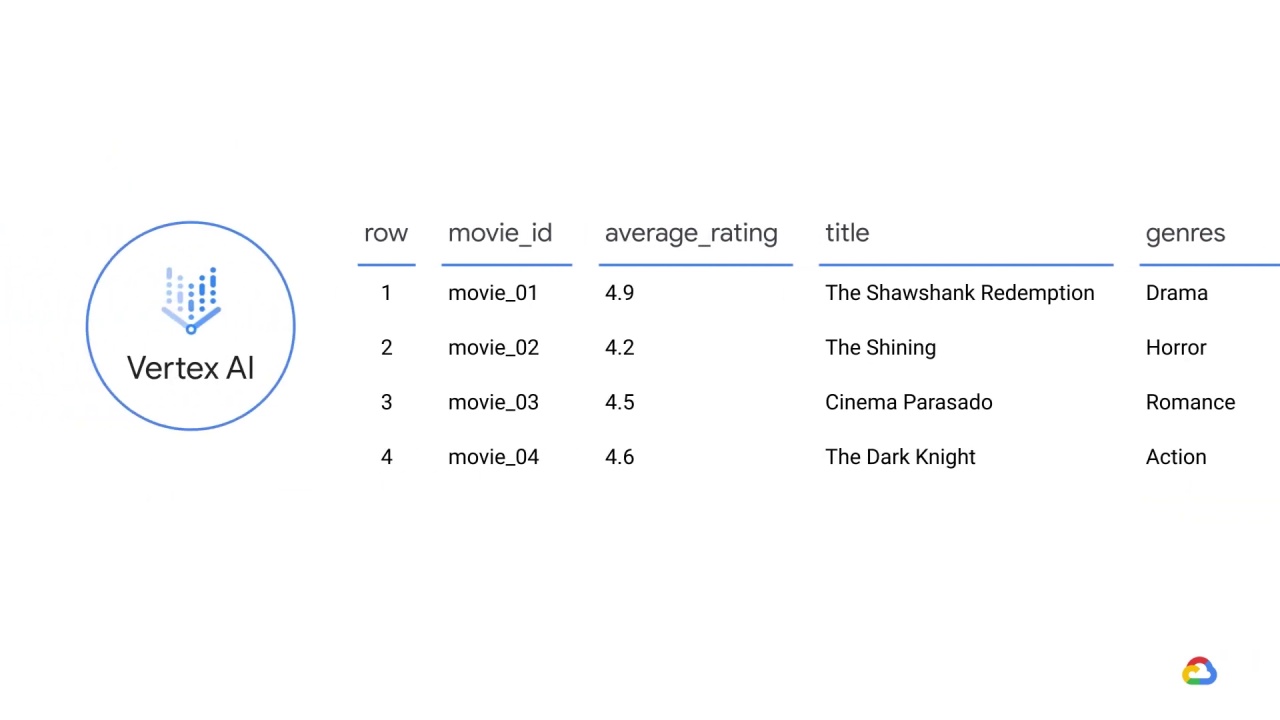
Let’s explore an example where you have sample source data from a BigQuery table about movies and their features.

First, there is a movie_id column header that can map to an entity type called movie.

For each movie entity, features include an average_rating, title, and genres.

The values in each column map to specific instances of an entity type or features,

which are called entities and feature values.

The update_time column indicates when the feature values were generated.
In the Feature store, the timestamps are an attribute of the feature values, not a separate resource type.
If all feature values were generated at the same time, you don’t need to have a timestamp column.
You can specify the timestamp as part of your ingestion request.
When you use the data to train a model, Vertex AI examines the source data type and feature values and infers how it will use that feature in model training.

This is called the transformation for that feature.
If needed, you can specify a different supported transformation for any feature.
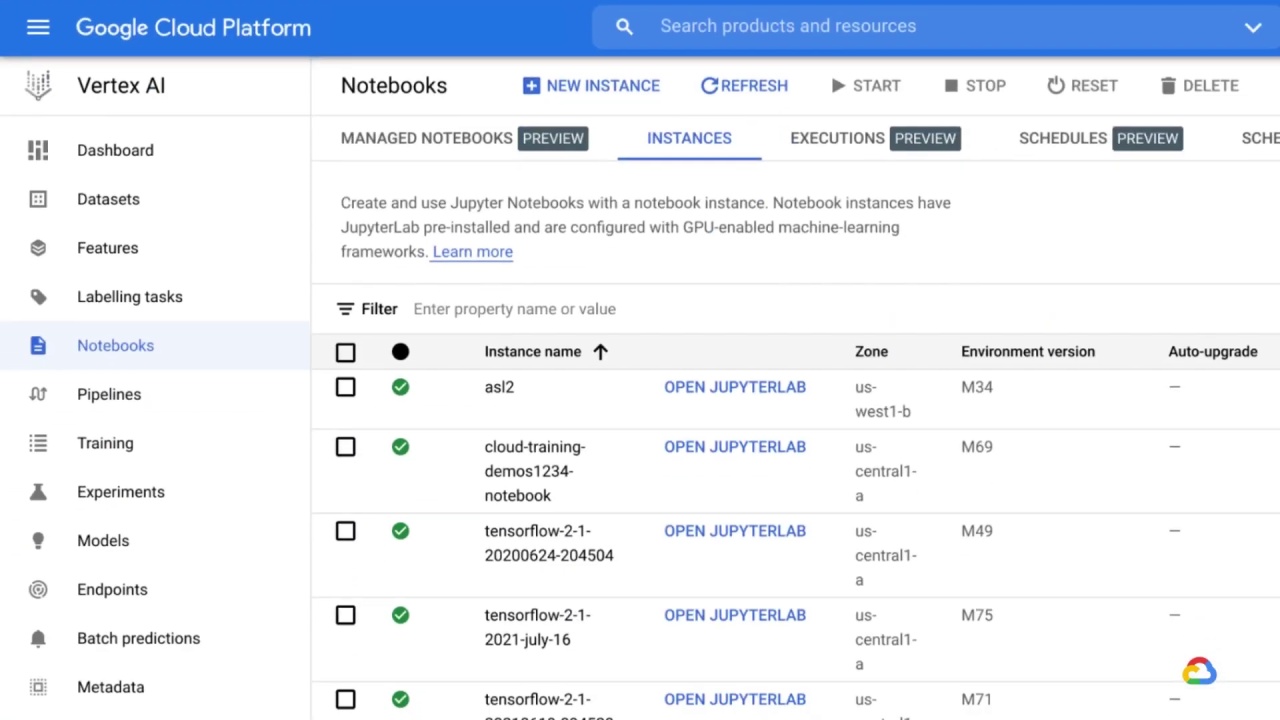
After you prepare your dataset, you can develop models using Notebooks.
Notebooks is a managed service that offers an integrated and secure JupyterLab environment for data scientists and machine learning developers to experiment, develop, and deploy models into production.
Notebooks enable you to create and manage virtual machine (VM) instances because they come pre-installed with the latest data science and machine learning frameworks.
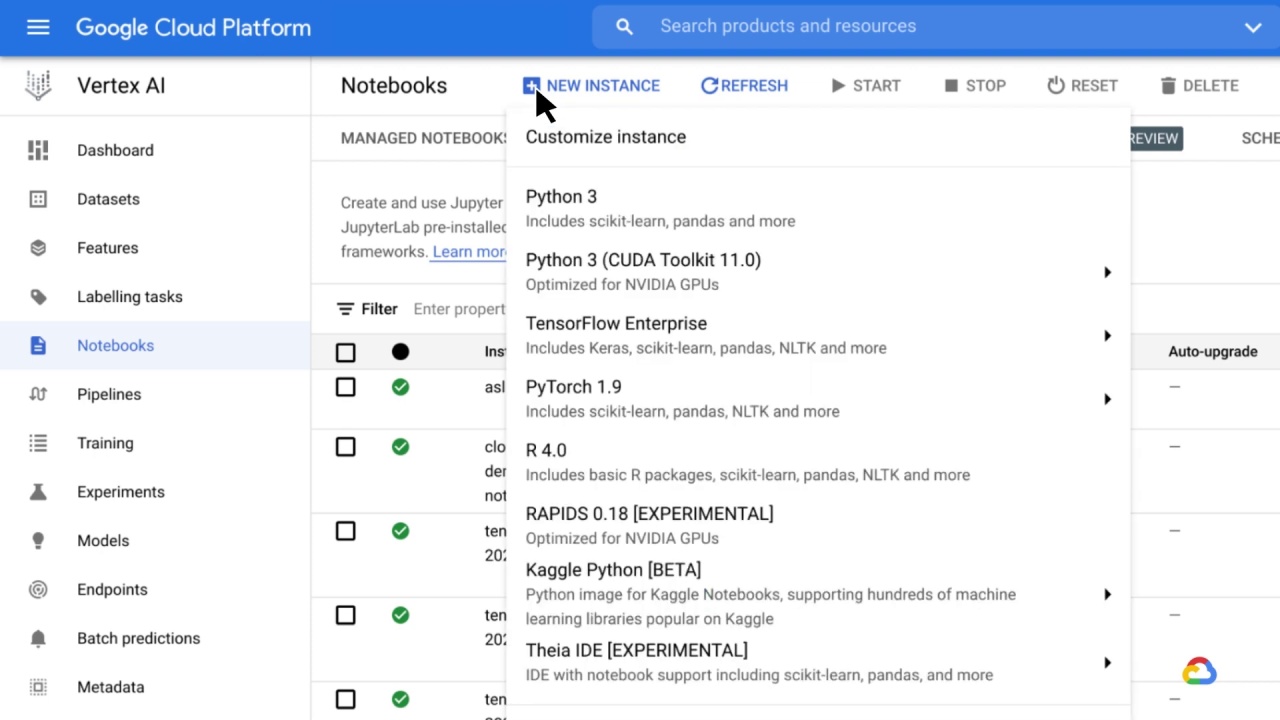
They also come with a pre-installed suite of deep learning packages, including support for the TensorFlow and PyTorch frameworks.
Either can be configured for CPU-only or GPU-enabled instances.
With regard to security, Notebooks instances are protected by Google Cloud authentication and authorization and are available using a Notebooks instance URL, which is part of the metadata of the VM.
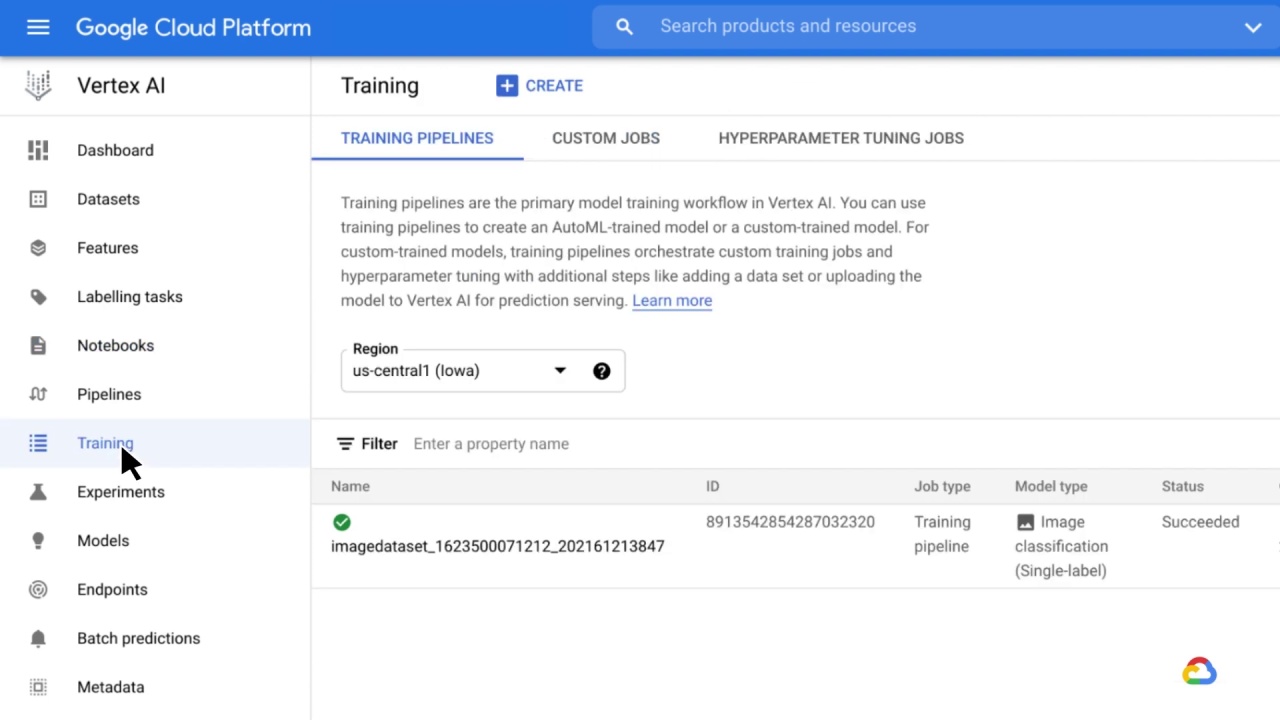
Now let’s shift our focus to training.
With Vertex AI, you can train and compare models using AutoML or custom code training, with all models stored in one central model repository.
Training pipelines are the primary model training workflow in Vertex AI, which can use training pipelines to create an AutoML-trained model or a custom-trained model.
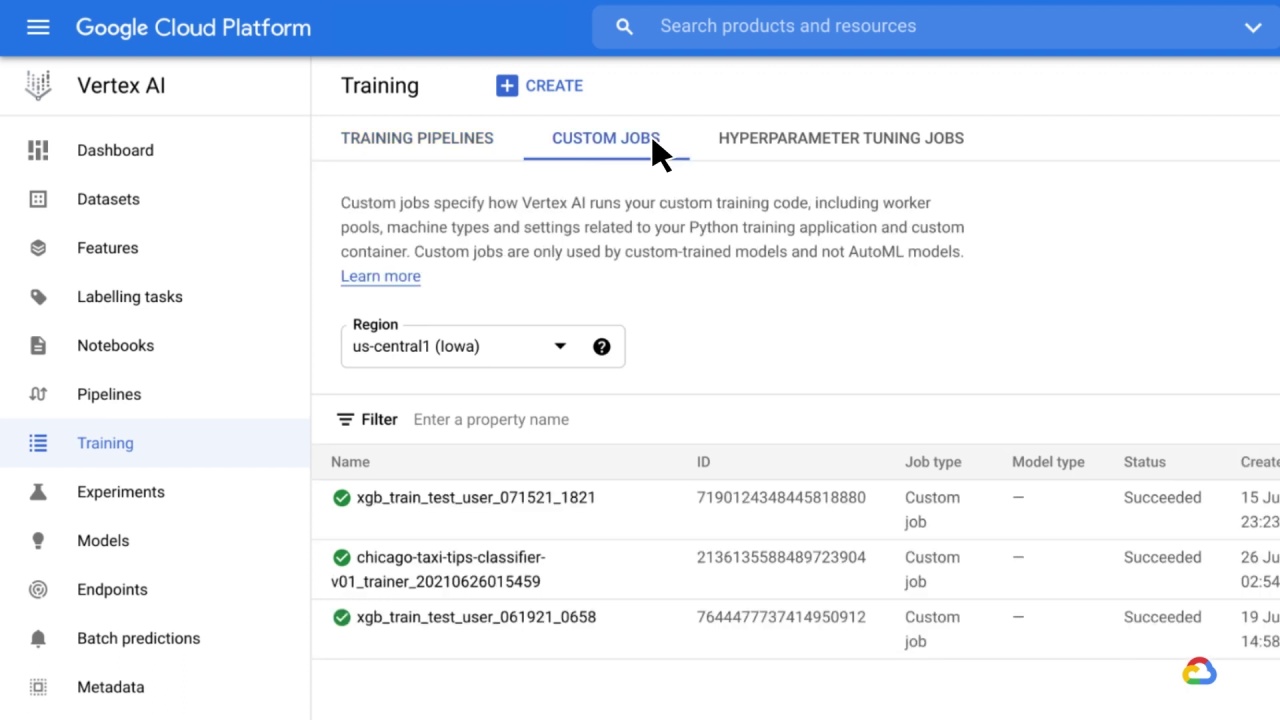
For custom-trained models, training pipelines orchestrate custom training jobs and hyperparameter tuning in conjunction with steps like adding a dataset or uploading the model to Vertex AI for prediction serving.
Custom jobs specify how Vertex AI runs custom training code, including worker pools, machine types, and settings related to a Python training application and custom container.
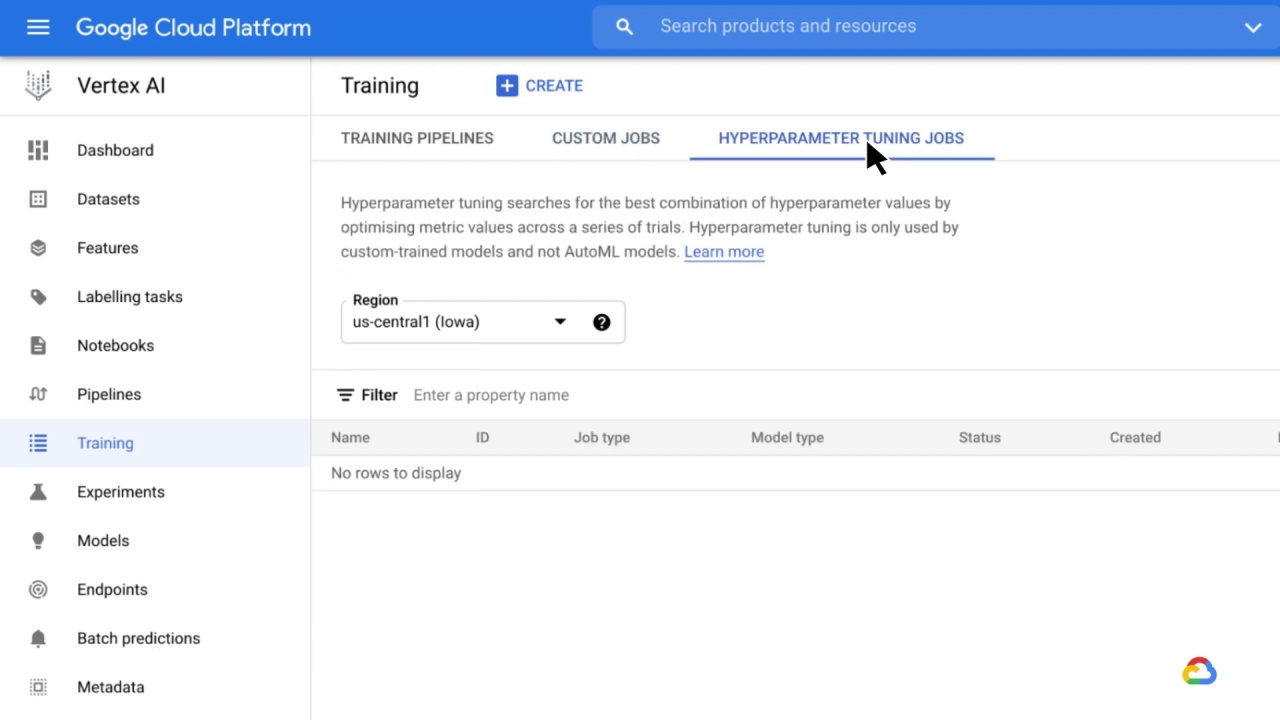
Alternatively, hyperparameter tuning searches for the best combination of hyperparameter values by optimizing metric values across a series of trials.
Both custom jobs and hyperparameter tuning, however, are only used by custom-trained models.
They are not used by AutoML models.
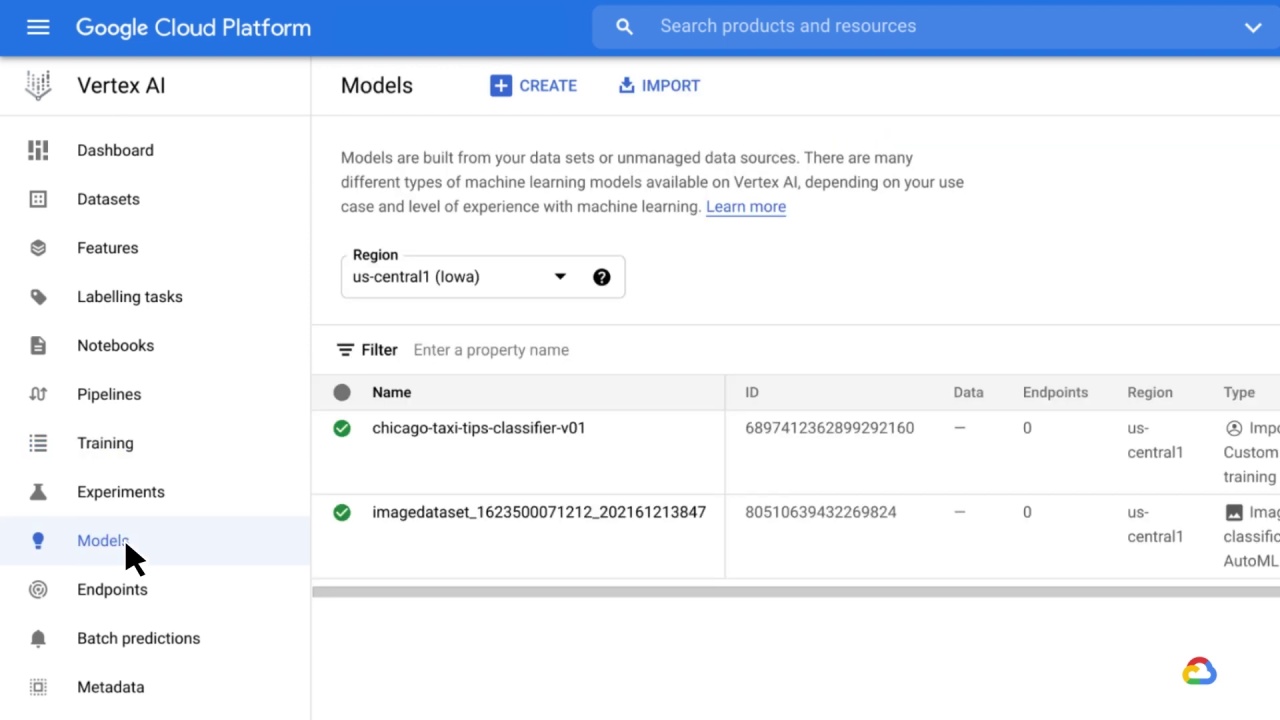
Next up are models.
Models are built from datasets or unmanaged data sources.
Many different types of machine learning models are available with Vertex AI.
The right choice will depend on the use case and your level of experience with machine learning.
A new model can be trained, or an existing model can be imported.
After the model has been imported into Vertex AI, it can be deployed to an endpoint and then used to request predictions.
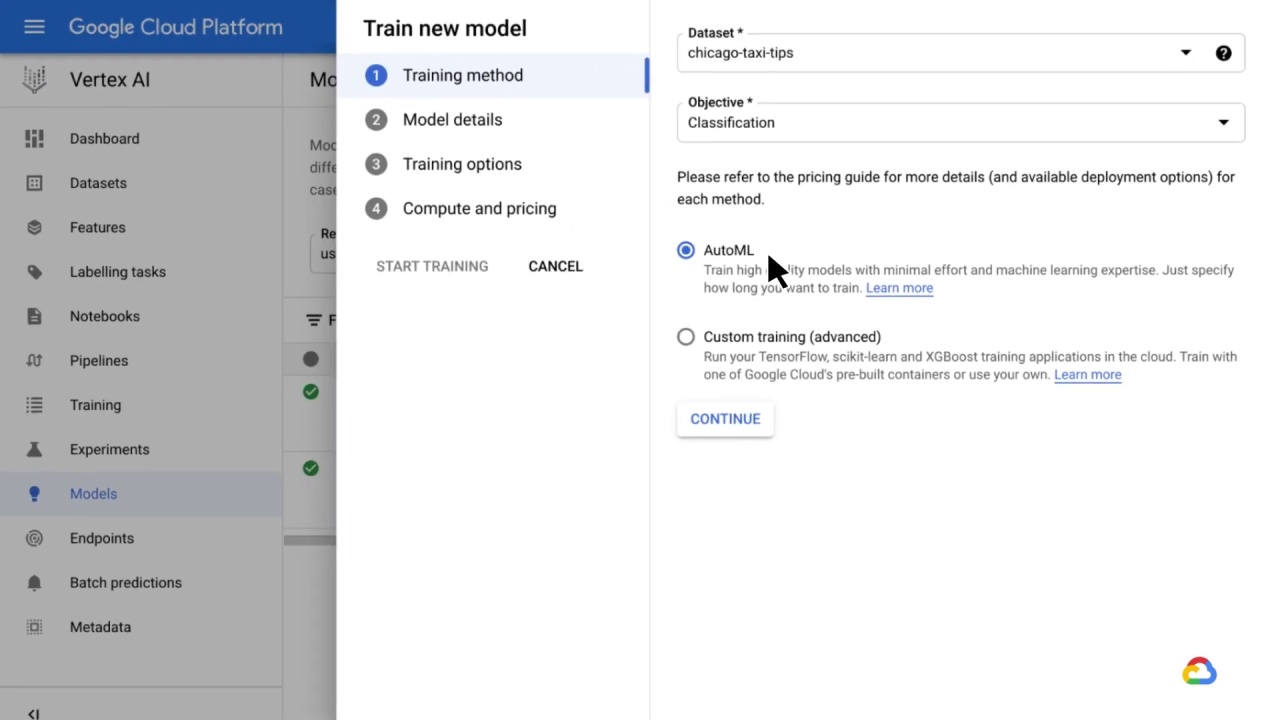
AutoML can be used to train a new model with minimal technical effort.
It can be used to quickly prototype models and explore new datasets before investing in development.
For example, you might use AutoML to determine the good features in a dataset.
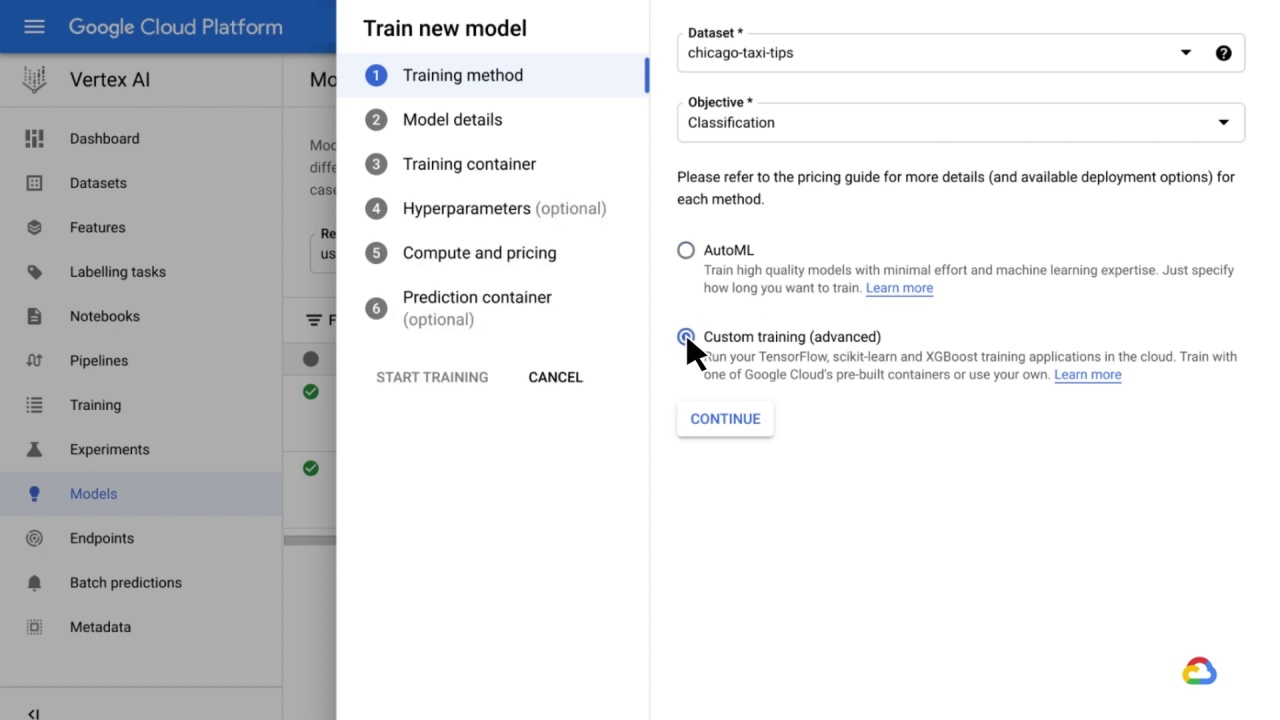
Generally speaking, custom training is used to create a training application optimized for a targeted outcome, because it allows for complete control over training application functionality.
You can target any objective, use any algorithm, develop your own loss functions or metrics, or carry out any other customization.
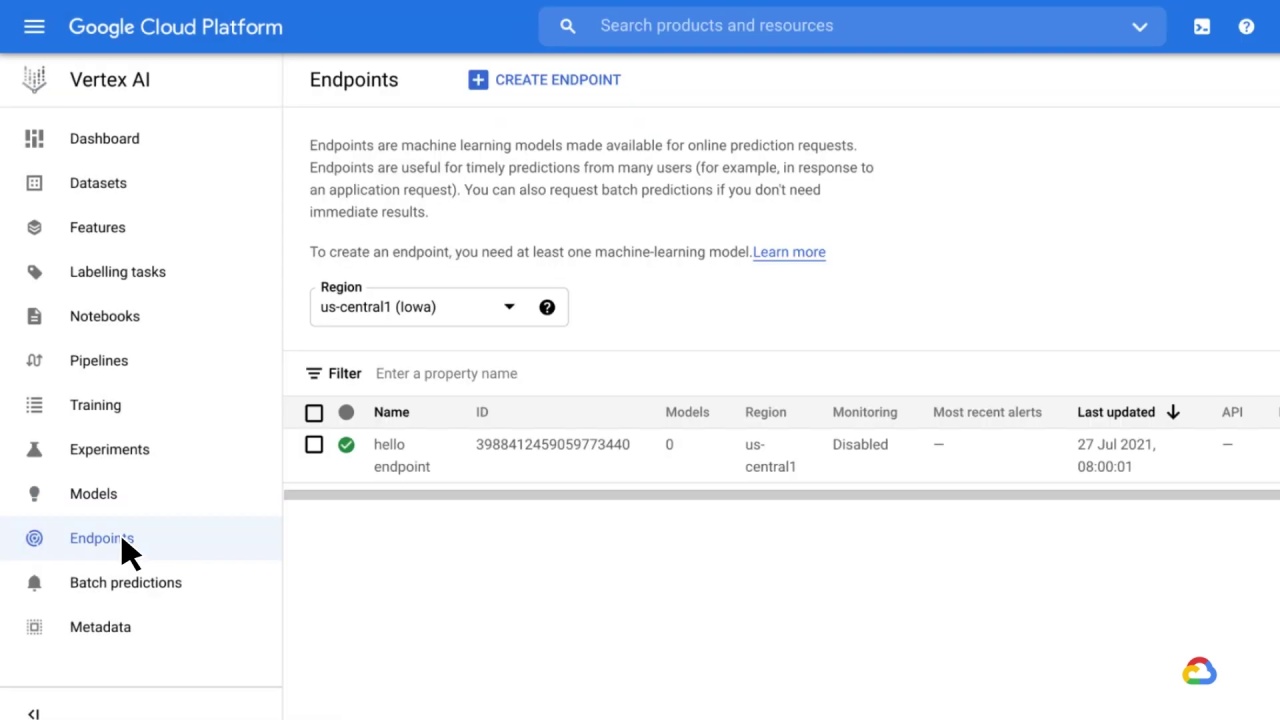
And finally, let’s explore Endpoints.
Endpoints are machine learning models made available for online prediction requests.
An endpoint is an HTTPS endpoint that clients can call to receive the inferencing (scoring) output of a trained model.
They can provide timely predictions from many users, for example, in response to an application request.
They can also request batch predictions if immediate results aren’t required.
Multiple models can be deployed to an endpoint, and a single model can be deployed to multiple endpoints to split traffic.
You might deploy a single model to multiple endpoints to test out a new model before serving it to all traffic.
Either way, it’s important to emphasize that a model must be deployed to an endpoint before that model can be used to serve online predictions.
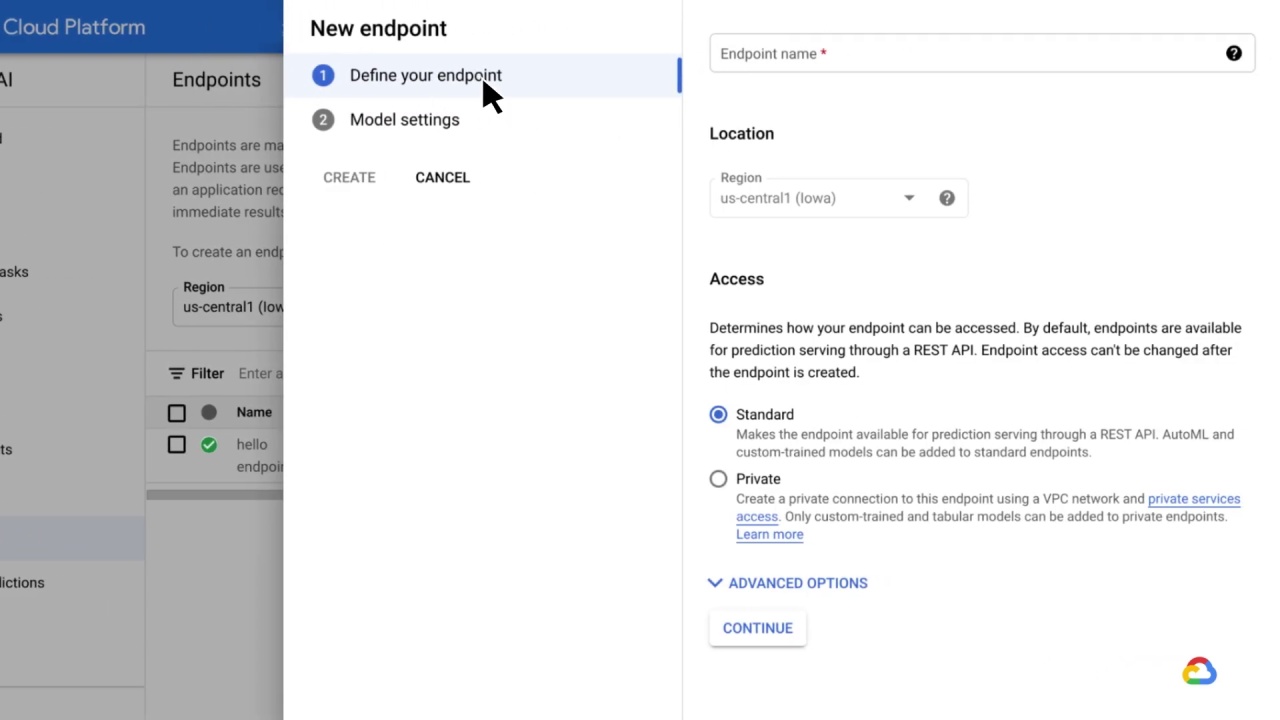
To make that happen, you must define an endpoint in Vertex AI by giving it a name and location and deciding whether the access is Standard, which makes the endpoint available for prediction serving through a REST API.

This has been a brief introduction to Vertex AI, Google Cloud’s unified ML platform.
For more information, please see cloud.google.com/vertex-ai.