Data extraction, analysis, and preparation


After you define the business use case
and establish the success criteria,
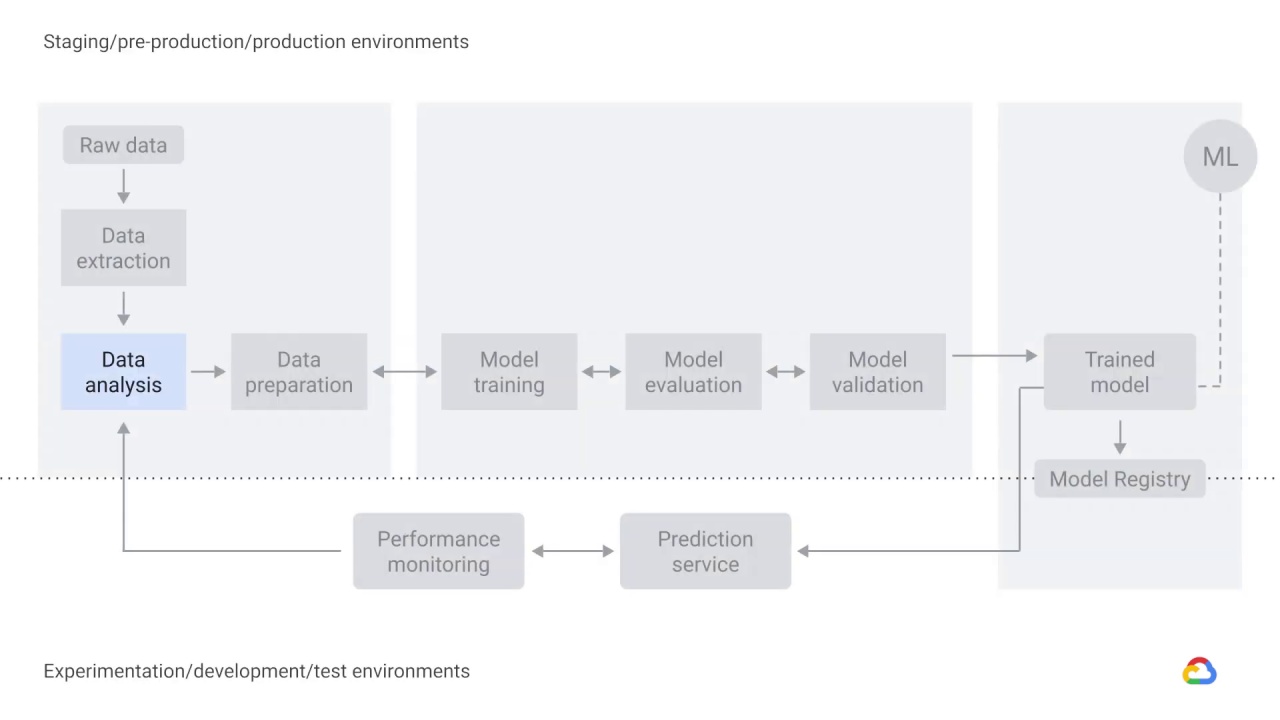
the process of delivering an ML model to production typically involves several steps,
which can be completed manually or by an automated pipeline.
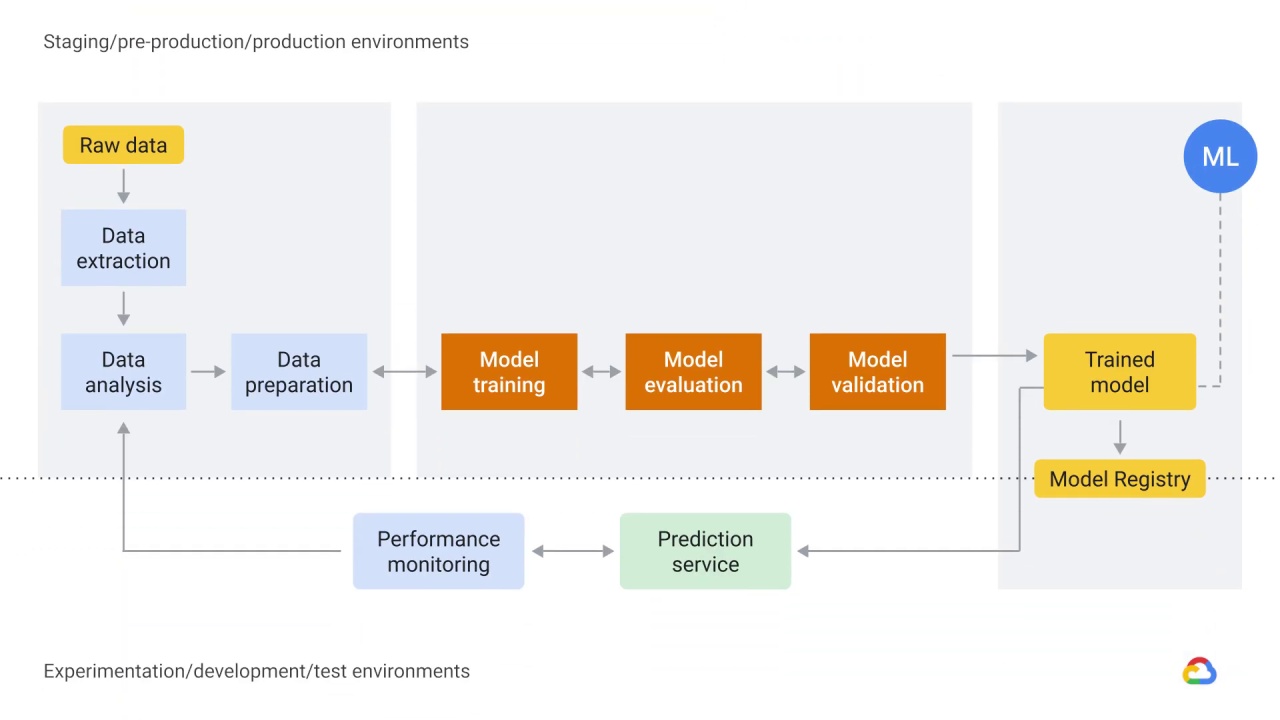
The first three steps deal with data.
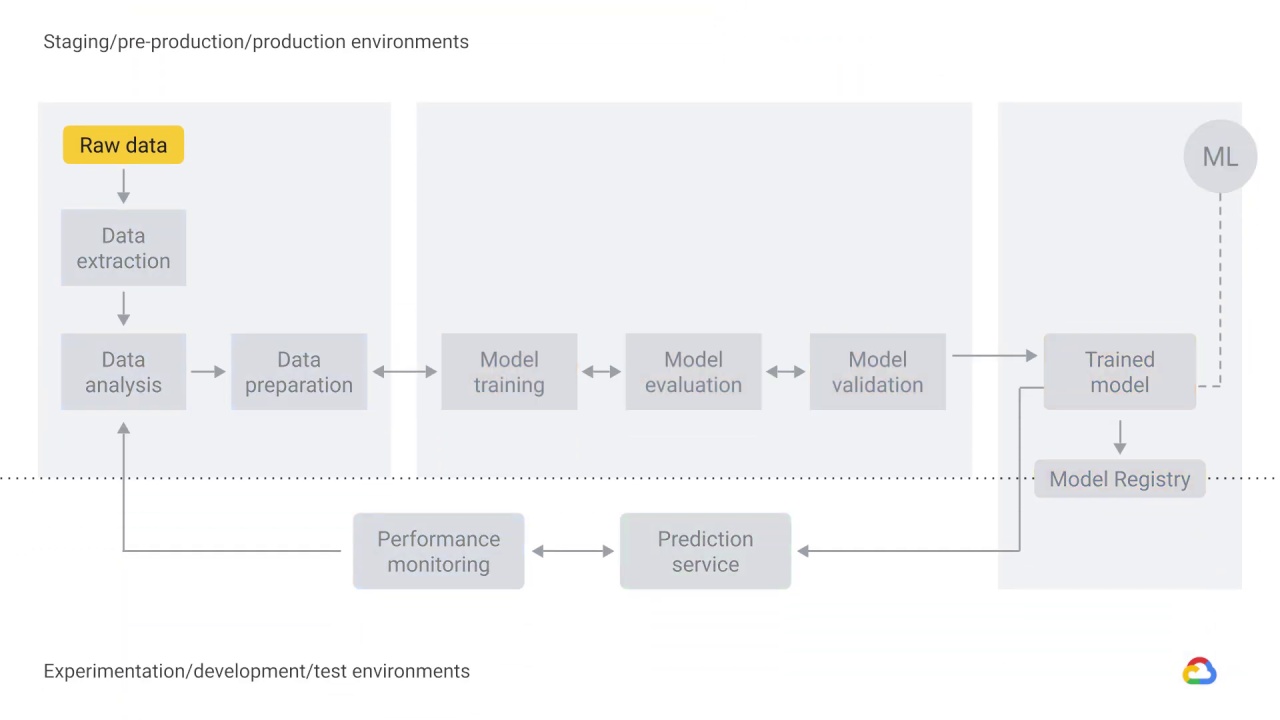
Data needs to be ingested, which means it’s extracted from a raw data source.
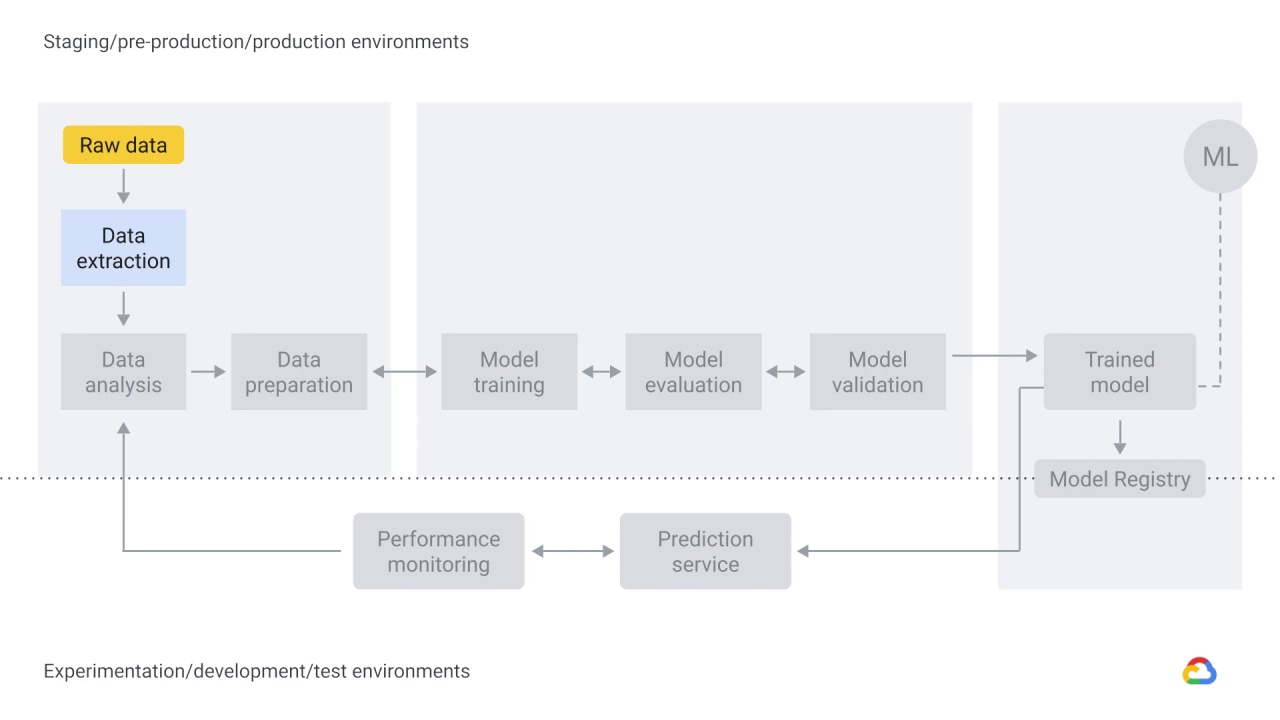
With data extraction, you retrieve data from various sources.
Those sources can be “streaming”, in “real-time”, or “batch”.
For example, you may extract data from a customer relationship management system, or CRM, to analyze customer behavior

This data may be
“structured”, where the file type is a .csv, .txt. JSON, or .XML
format, or,
you may have an “unstructured” data source where you have images of your customers, or text comments from chat sessions with your customers.
You may have to extract “streaming” data from your company’s transportation vehicles that are equipped with sensors that transmit data in real time.
If the data you want to train your model on or get predictions for is structured, you might retrieve it from a data warehouse – such as BigQuery.
Or, you can use Apache Beam’s IO module.
In this Dataflow example we’re loading data from BigQuery, calling predict on every record,
and then writing the results back into BigQuery.
In data analysis, you analyze the data you’ve extracted.

For example, you can use exploratory data analysis (or EDA).

This involves using graphics and basic sample statistics to explore your data,

such as looking for outliers

or anomalies,
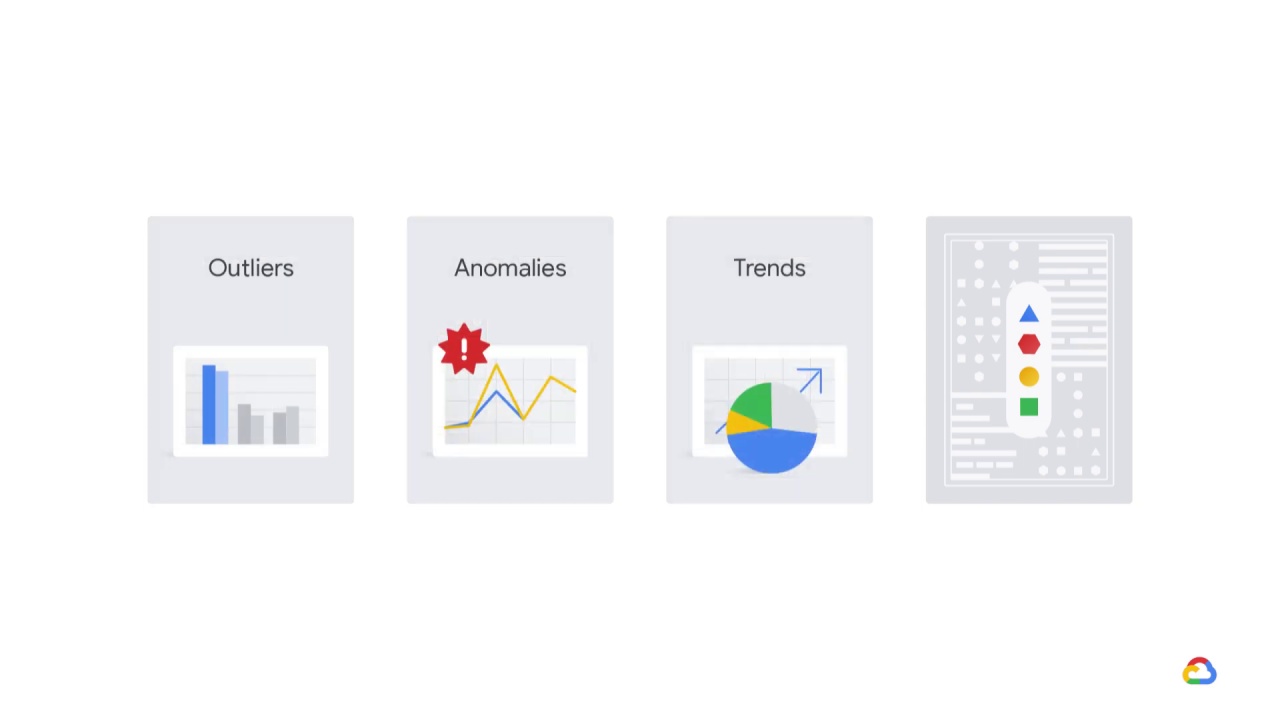
trends,

and data distributions.
It may not be apparent how changes in the distribution of your data could affect your model, so let’s consider a scenario.

In this scenario, an upstream data source encodes a categorical feature using a number, such as a product number
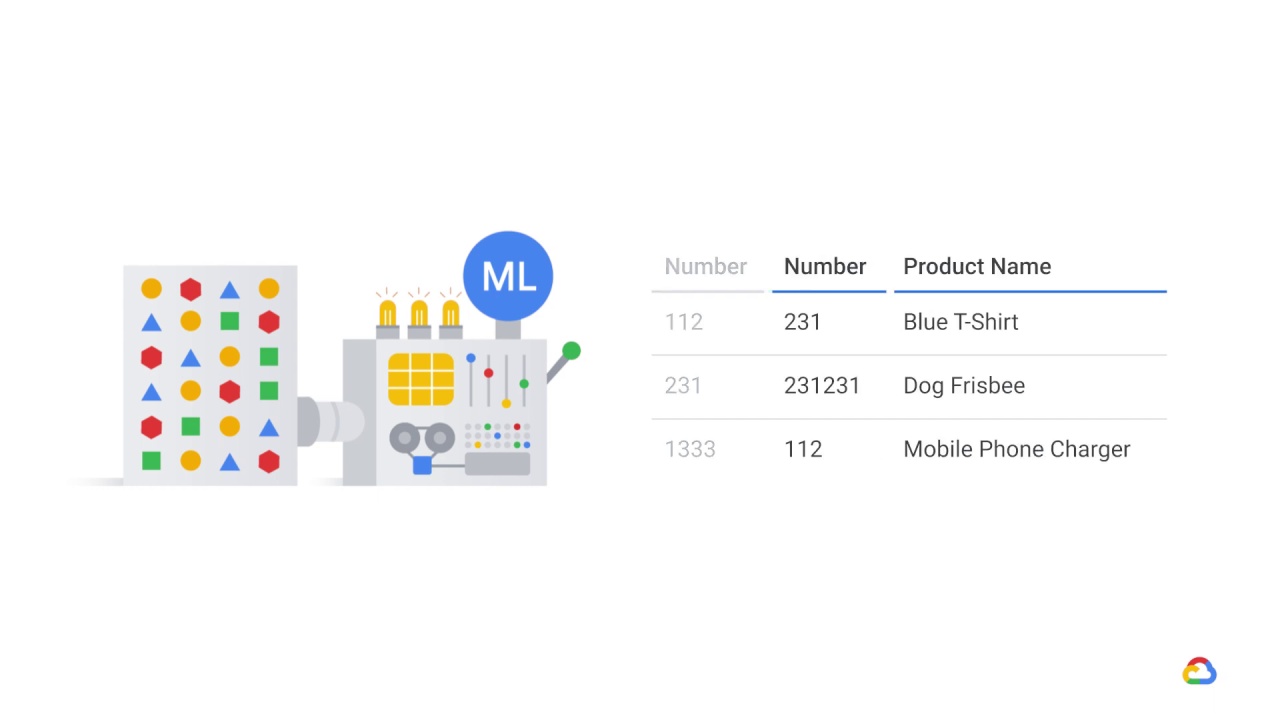
One day, the product numbering convention changes and now the customer uses a totally different mapping, using some old numbers and some new numbers.

How would you know that this had happened?

How would you debug your ML model?
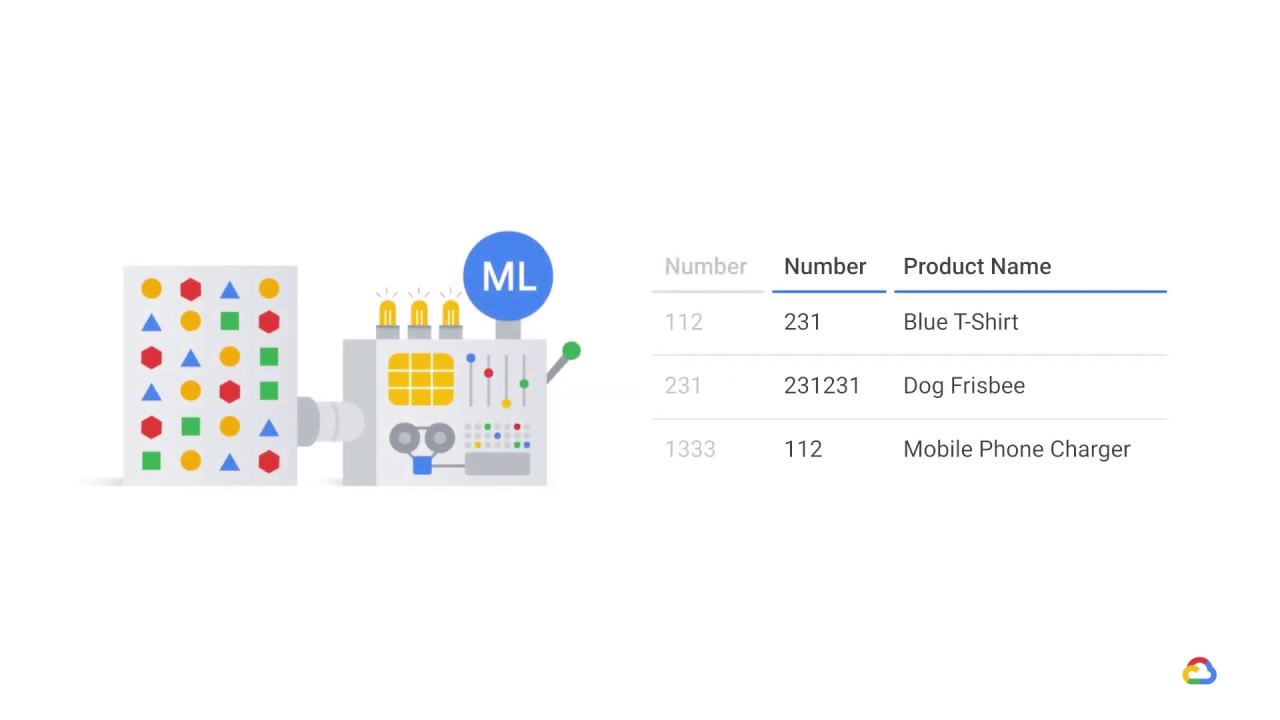
The output of your model would tell you if there’s a drop in performance, but it won’t tell you why.
The raw inputs themselves would appear valid because we’re still getting numbers.
In order to recognize this change, you would need to look at changes in the distribution of your inputs.

In doing so, you might find that while earlier, the most commonly occurring value might have been a 4, in the new distribution, 4 might never even occur and the most commonly occurring value might be a 10
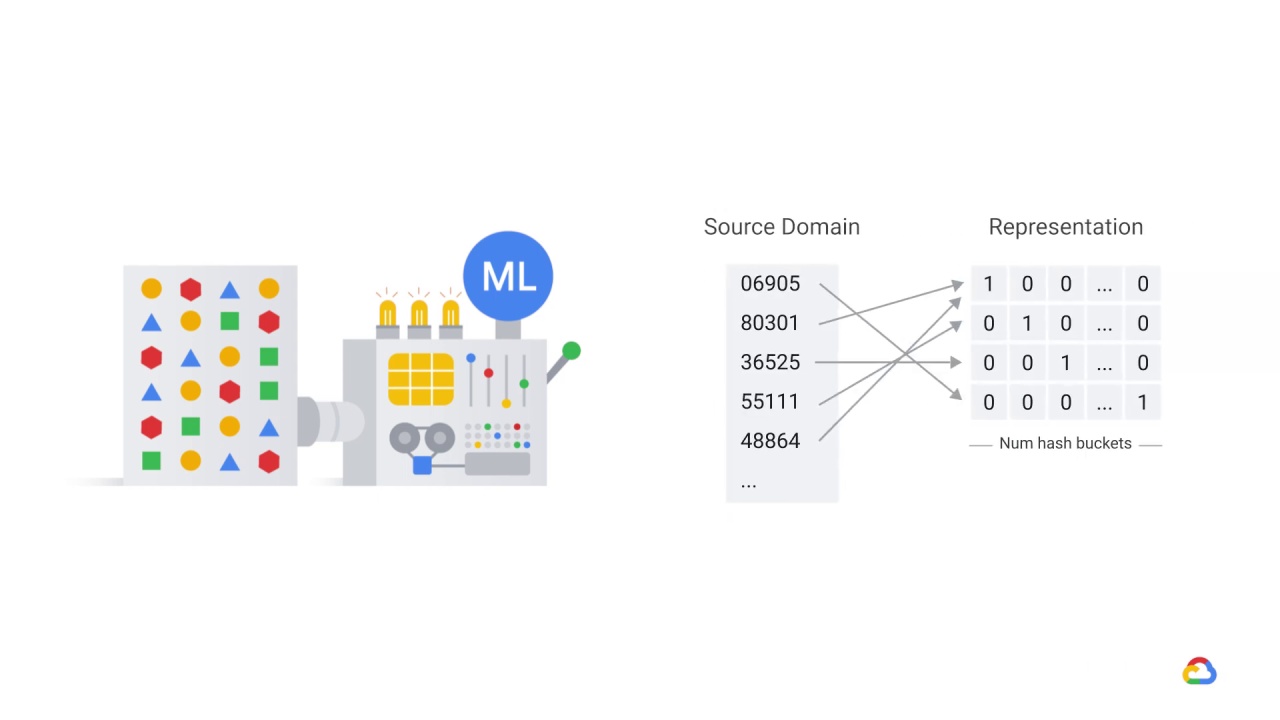
Depending on how you implemented your feature columns, these new values might be mapped to one component of a one-hot encoded vector or to many components.
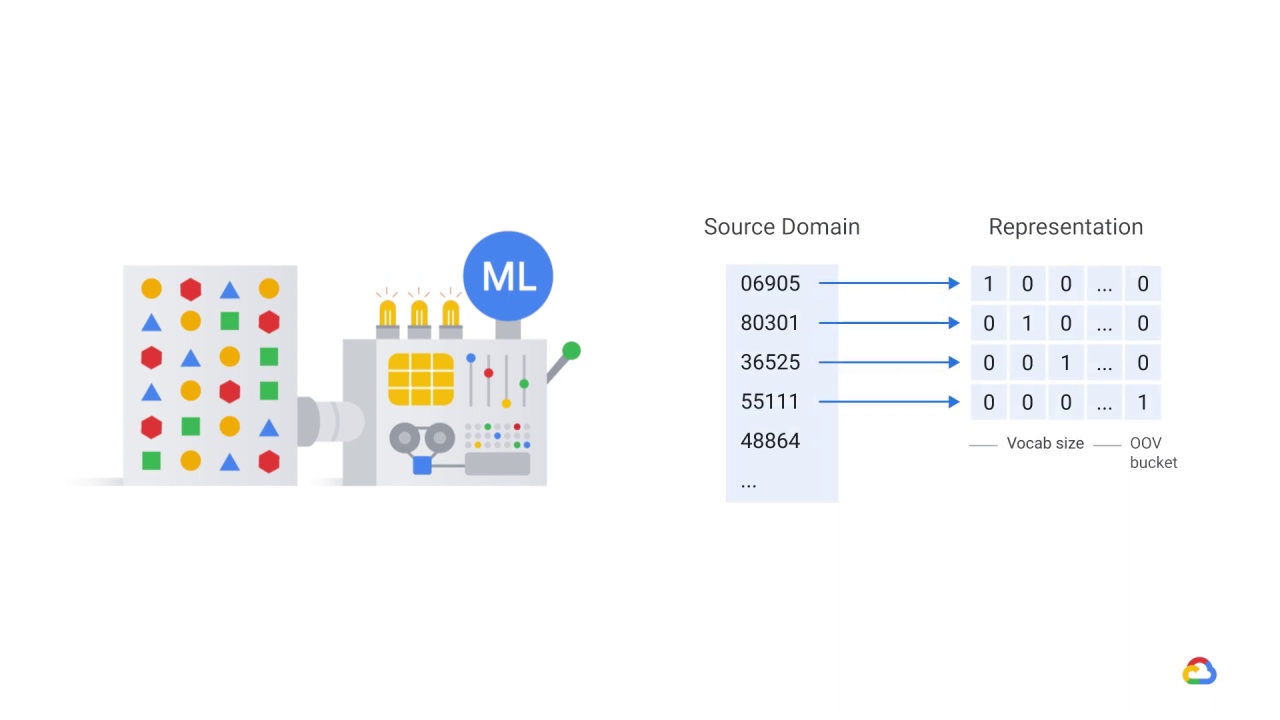
If, for example, you used a categorical column with a hash bucket, the new values would be distributed according to the hash function, and so one hash bucket might now get more and different values than before.
If you used a vocabulary, then the new values would map to OOV buckets.
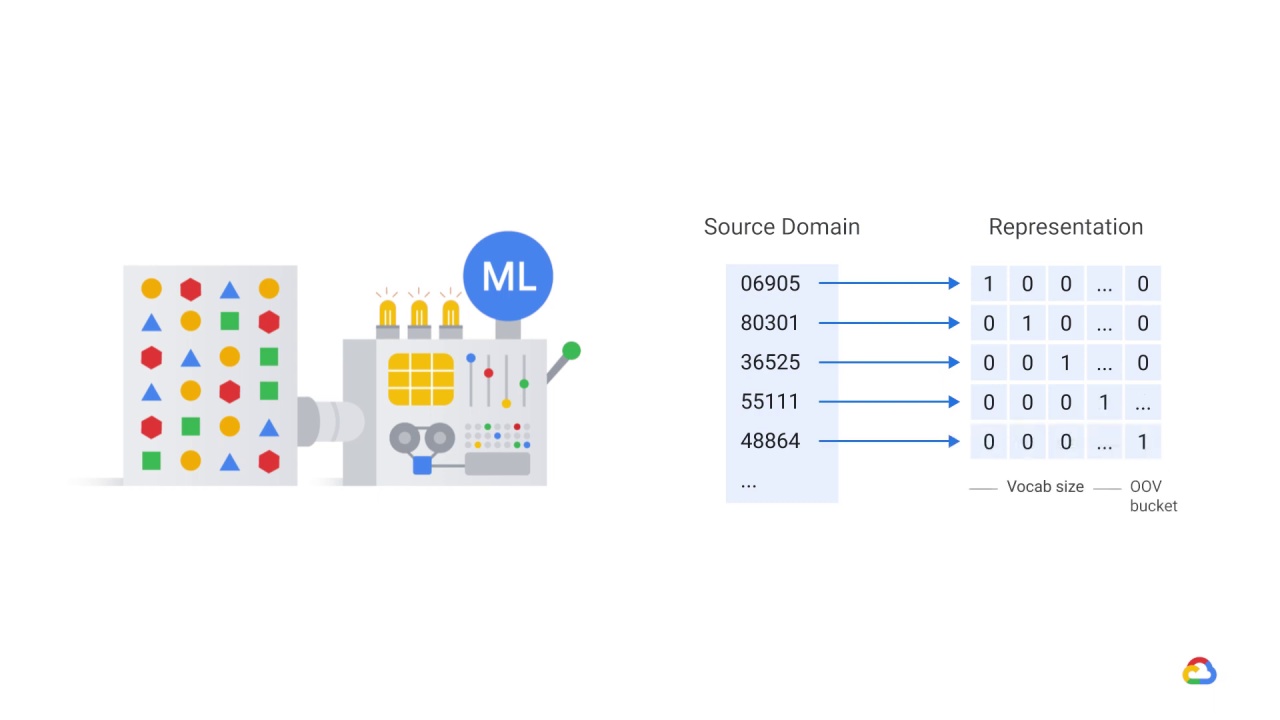
But what’s important is that, for a given tensor, its relationship to the label before, and its relationship to the label now, are likely to be very different.
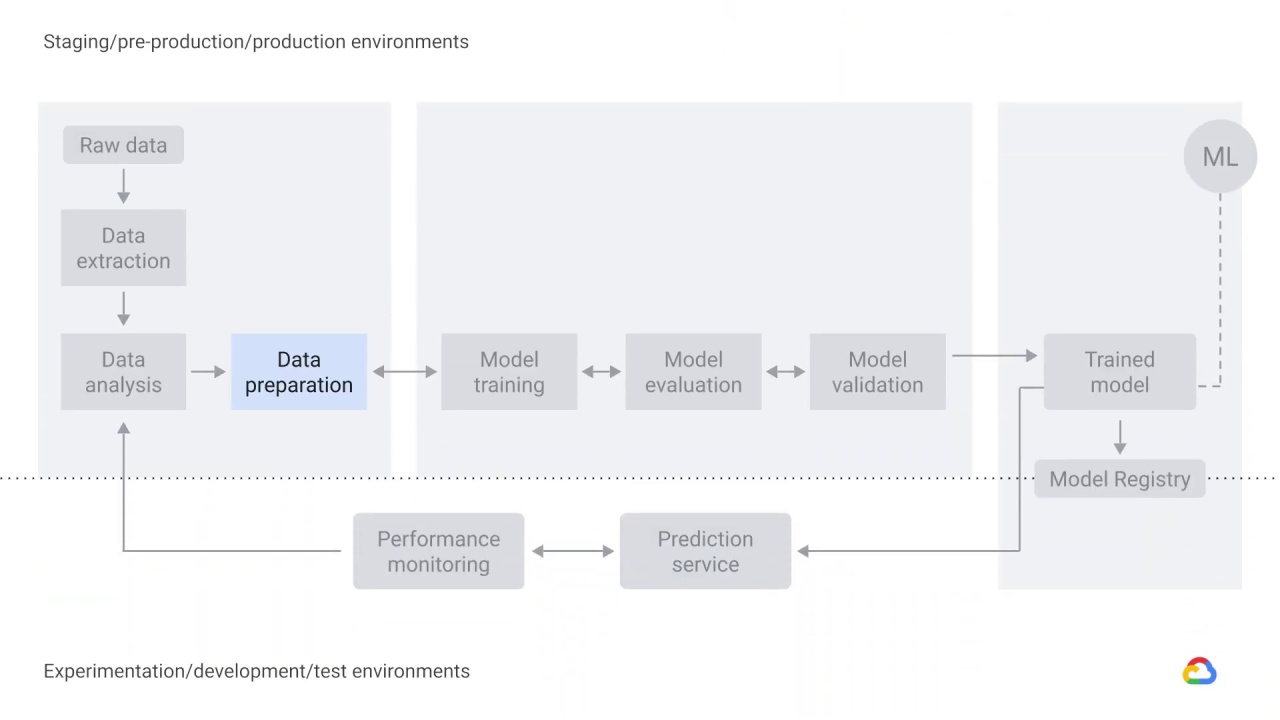
So, after you’ve extracted and analyzed your data, the next step in the process is data preparation.
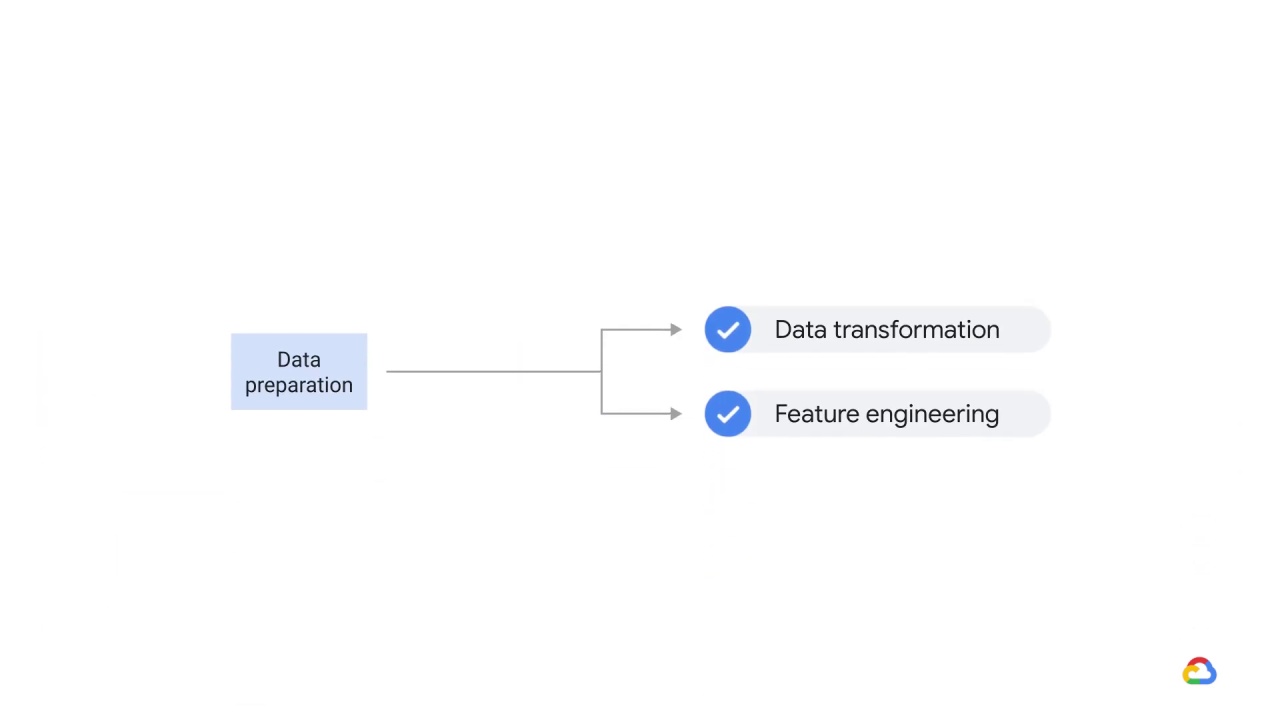
Data preparation includes data transformation and feature engineering, which is the process of changing, or converting, the format, structure, or values of data you’ve extracted, into another format or structure.
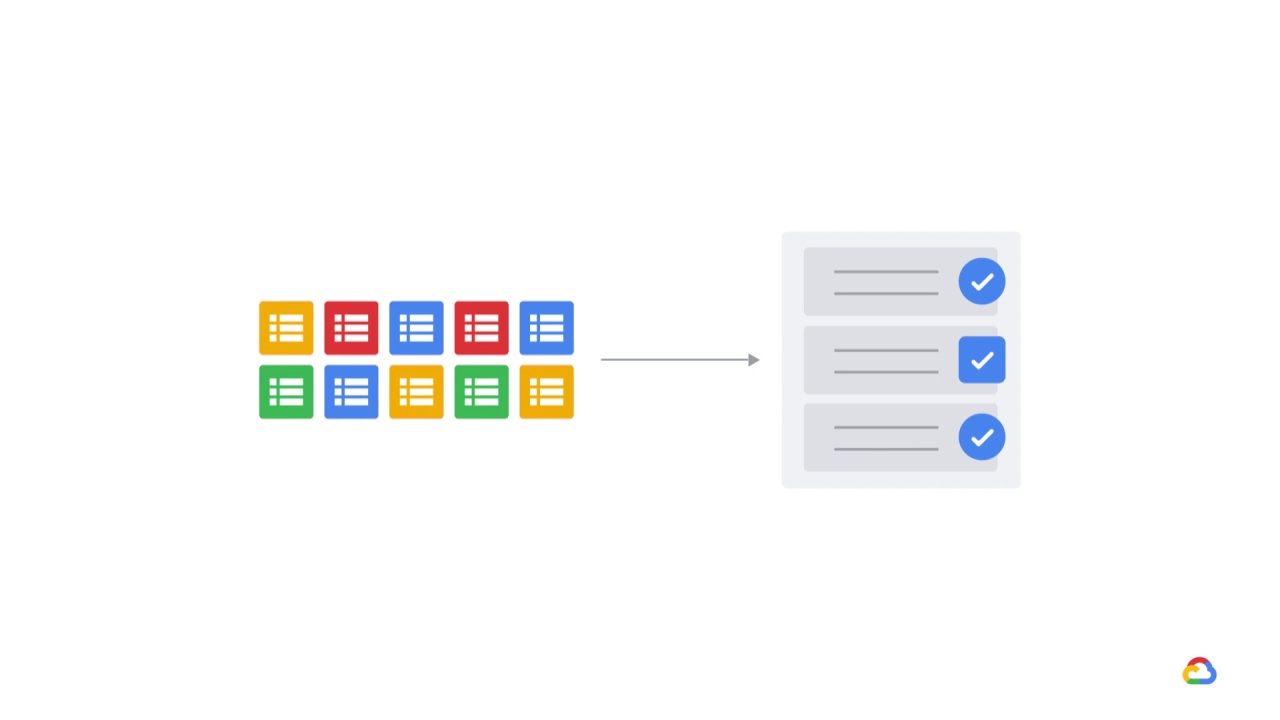
Most ML models require categorical data
to be in a numerical format,
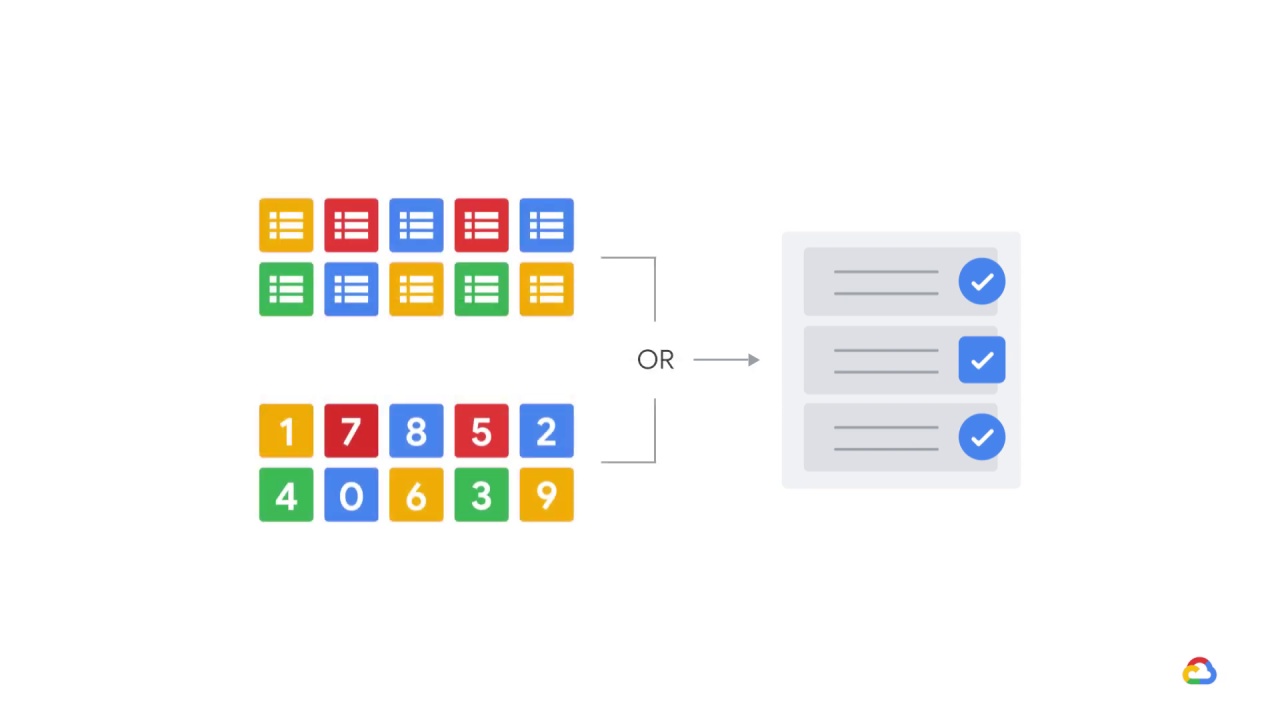
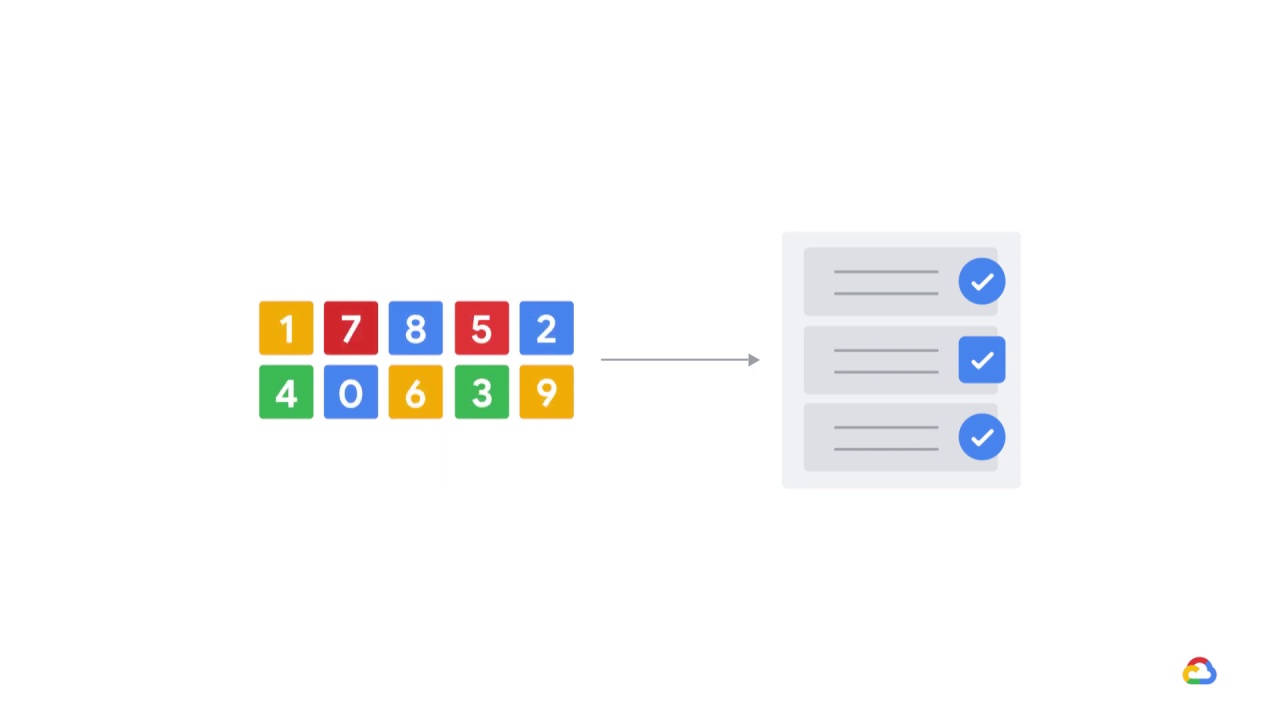
but some models work either with numeric or categorical features,
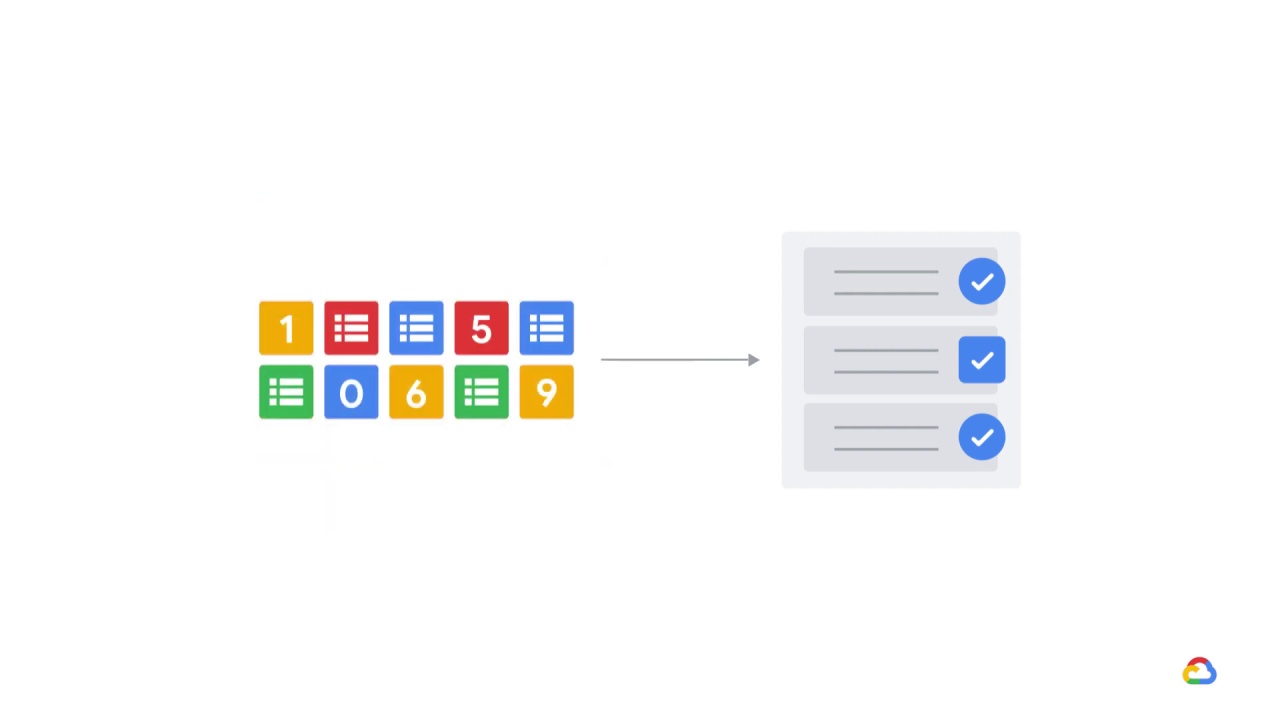
while others can handle mixed-type features.
For example, here are three types of preprocessing for dates using SQL in BigQuery ML, where we are:
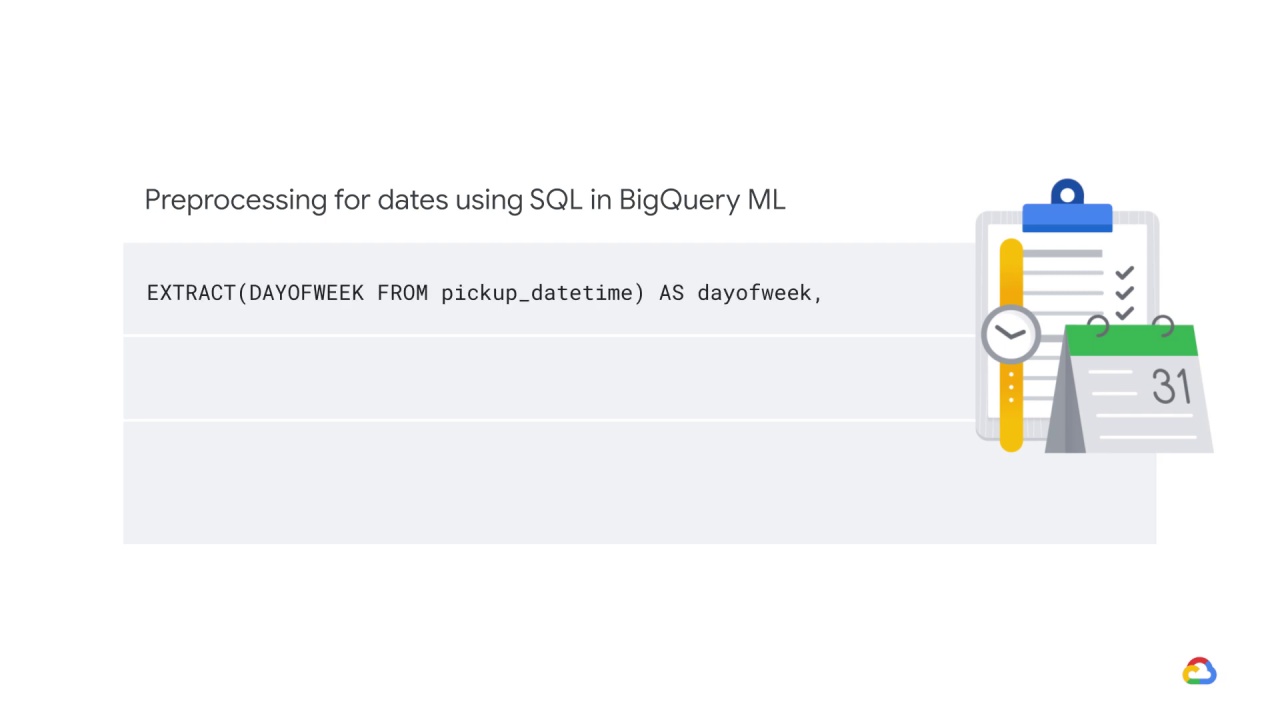
Extracting the parts of the date into different columns: Year, month, day, etc.
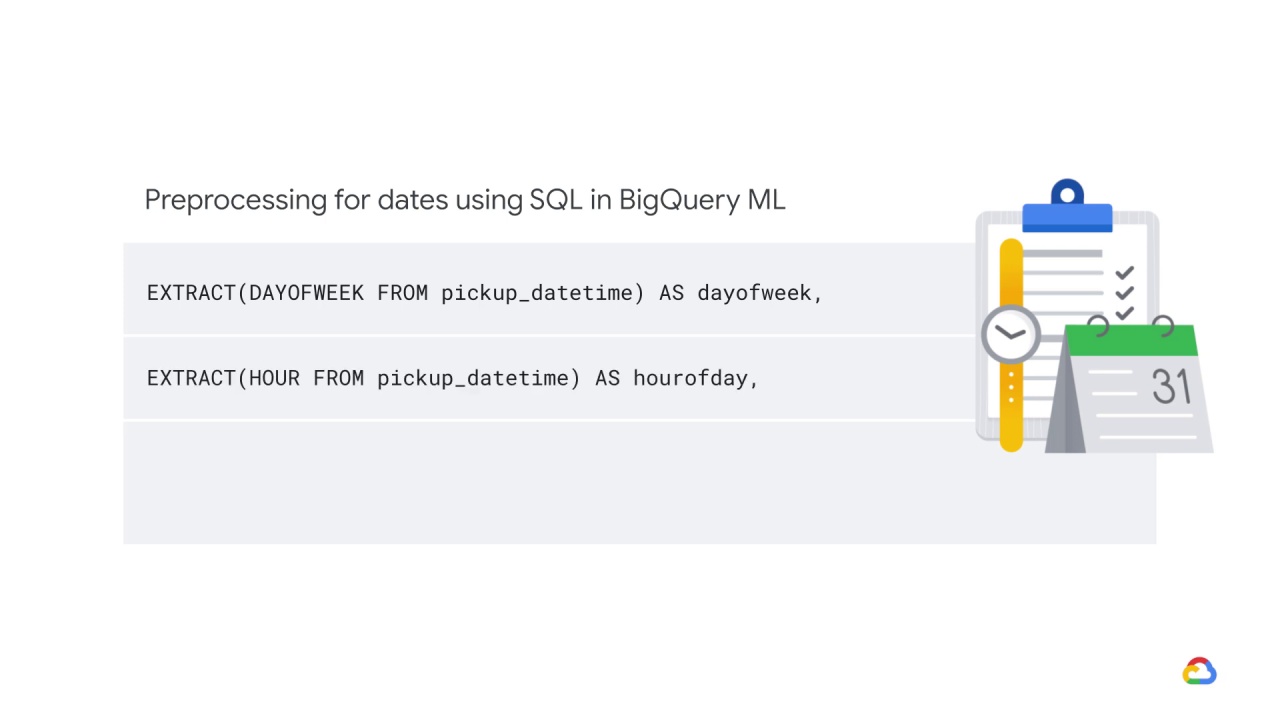
Extracting the time period between the current date and columns in terms of years, months, days, etc
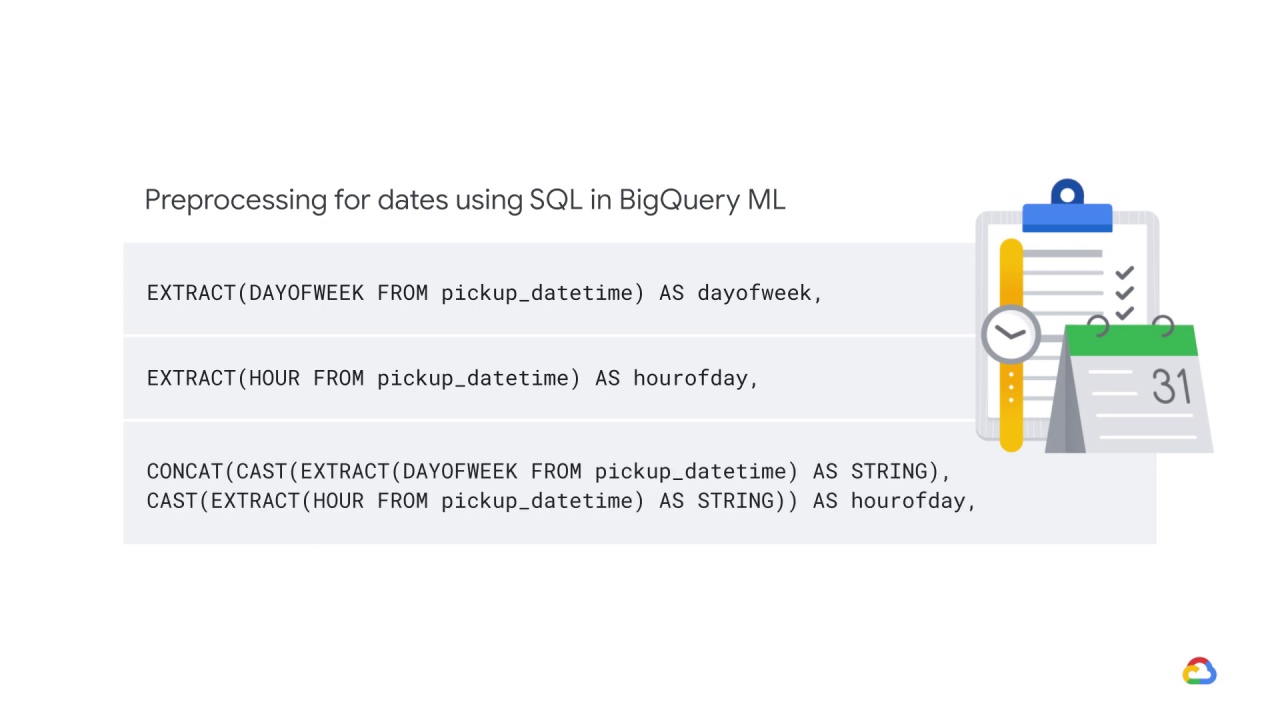
And extracting some specific features from the date: Name of the weekday, weekend or not, holiday or not, etc.
Now here is an example of the dayofweek and hourofday queries extracted using
SQL and visualized as a table in Data Studio.

Please note that for all non-numeric columns, other than TIMESTAMP, BigQuery ML performs a one-hot encoding transformation.
This transformation generates a separate feature for each unique value in the column.