Best practices for model monitoring
In this lesson, we provided an overview of best practices for machine learning model monitoring.
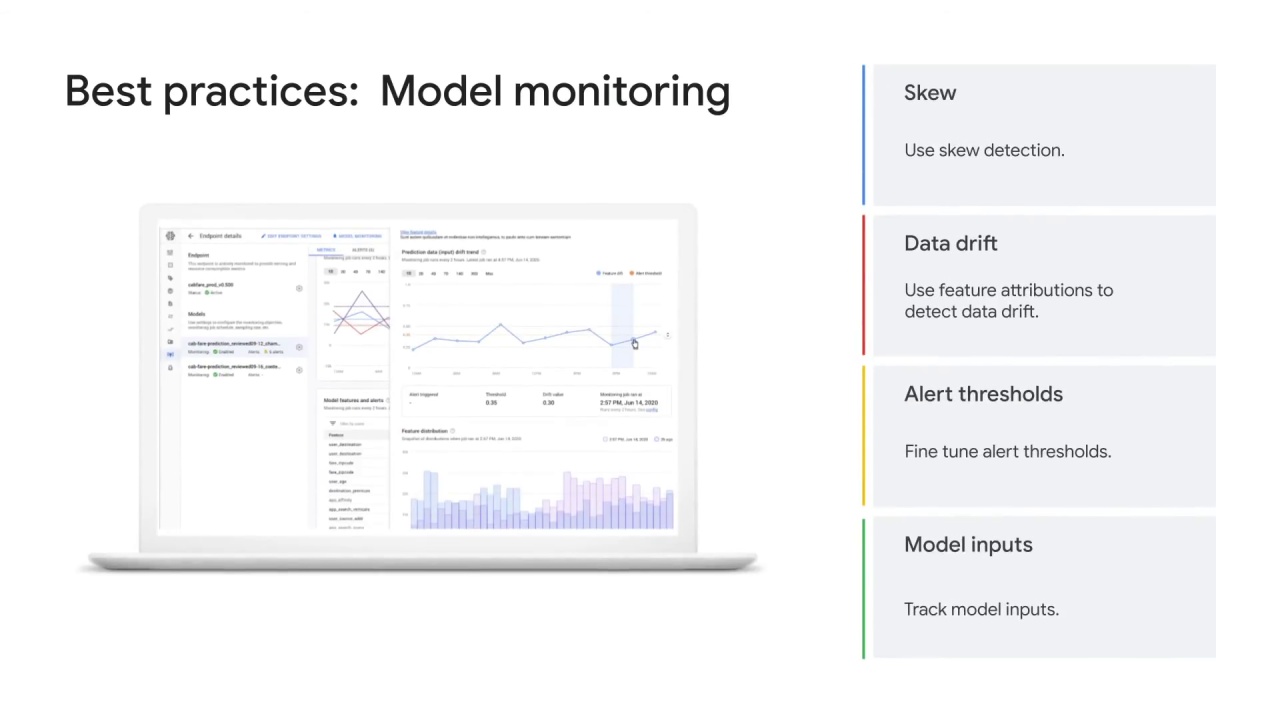
Best practices for model monitoring include using:
skew detection,
fine-tuning alert thresholds,
using feature attributions to detect data drift or skew and tracking outliers.
Note, model monitoring works for structured data like numerical or categorical features but not for unstructured data like images.

After you deploy your model into production, you need to monitor performance to ensure that the model is performing as expected.
Vertex AI provides two ways to monitor your ML models:
skew detection
and drift detection.
Skew detection looks for the degree of distortion between your model training and production data.
As much as possible, use skew detection because knowing that your production data has deviated from your training data is a strong indicator that your model isn’t performing as expected in production.
For skew detection, set up the model monitoring job by providing a pointer to the training data that you used to train your model.

Drift detection, in this type of monitoring, you’re looking for drift in your production data.
Drift occurs when the statistical properties of the inputs and the target which the model is trying to predict, change over time in unforeseen ways.
This causes problems because the predictions could become less accurate as time passes.
If you don’t have access to the training data, turn on drift detection so that you’ll know when the inputs change over time.

Alert thresholds are determined by the use case, the user’s domain expertise and initial model monitoring metrics.
Tune the thresholds used for alerting so you know when skew or drift occurs in your data.
In addition to deploying the model, you’ll need to determine how you’re going to pass inputs to the model.
If you’re using batch prediction, you can fetch data from the data lake or from Vertex AI Feature Store batch serving API.
If you’re using online prediction, you can send input instances to the service, and it returns your predictions in the response.
Note, you can use feature attributions to detect model degradation regardless of the type of feature your model takes as input.
This is particularly useful for complex feature types like embeddings and time series which are difficult to compare using traditional skew and drift methods.
With Vertex Explainable AI, feature attributions can indicate when model performance is degrading.