Architecting ML systems

Welcome to Architecting ML systems, the second module of the Production Machine Learning Systems course.

In this module, we’ll explore what makes up an architecture as well as

why and how to make good systems design decisions.

Let me ask you a question.
What percent of system code does the ML model account for?
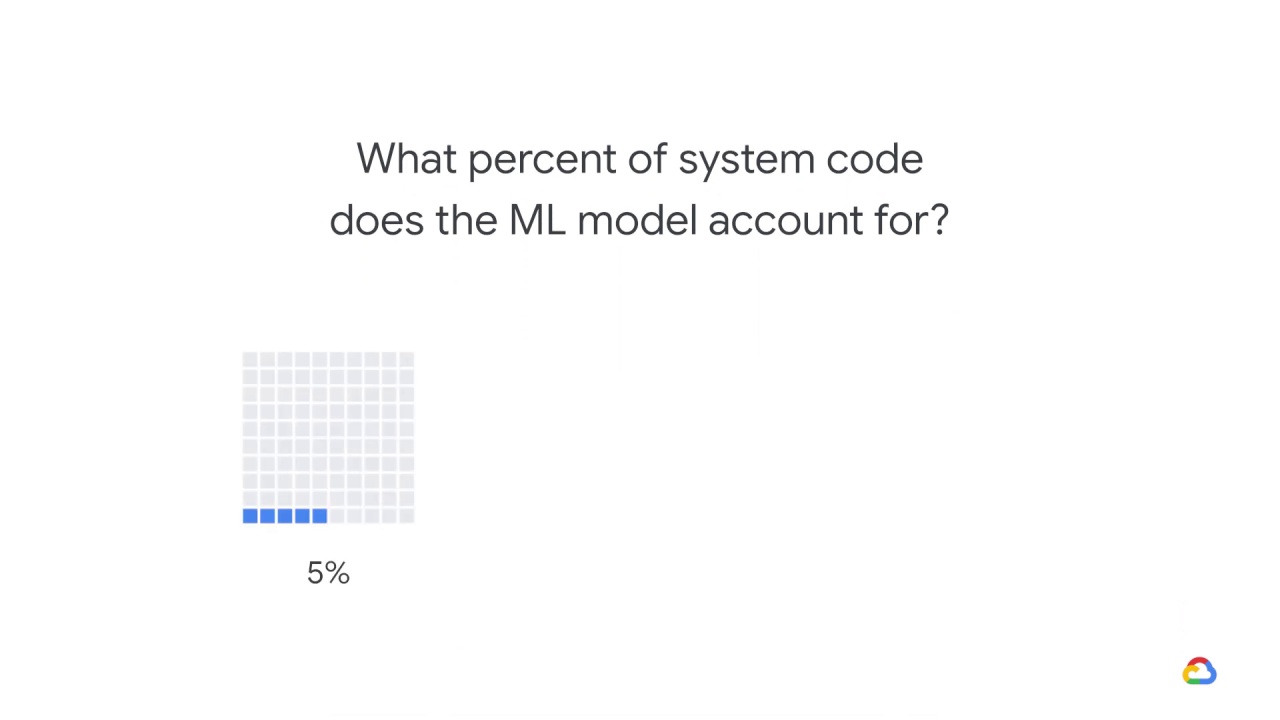
5%
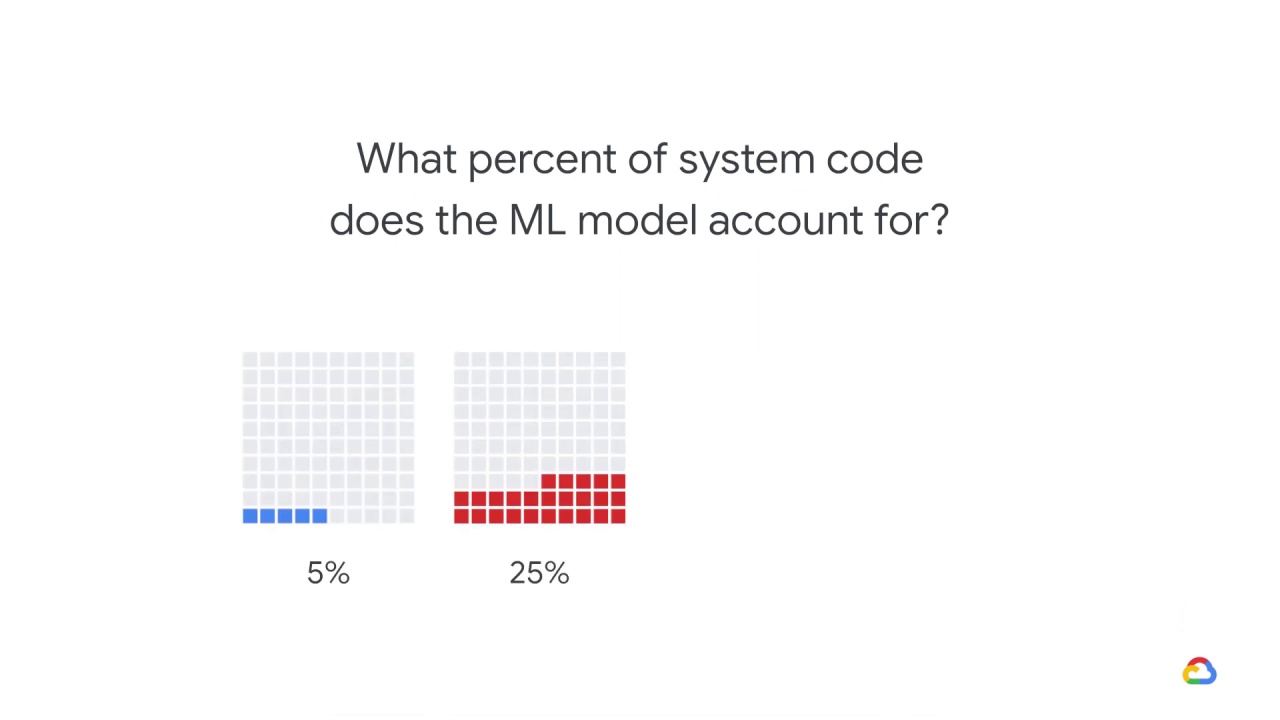
25%
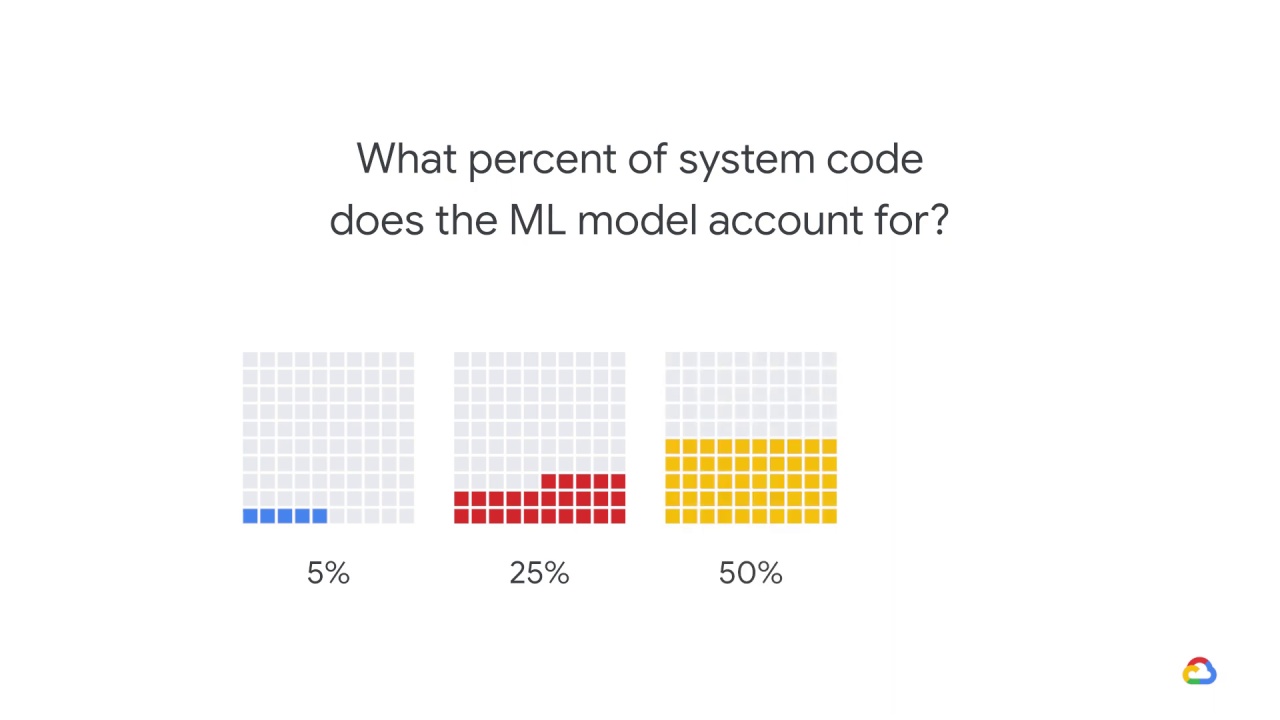
50%
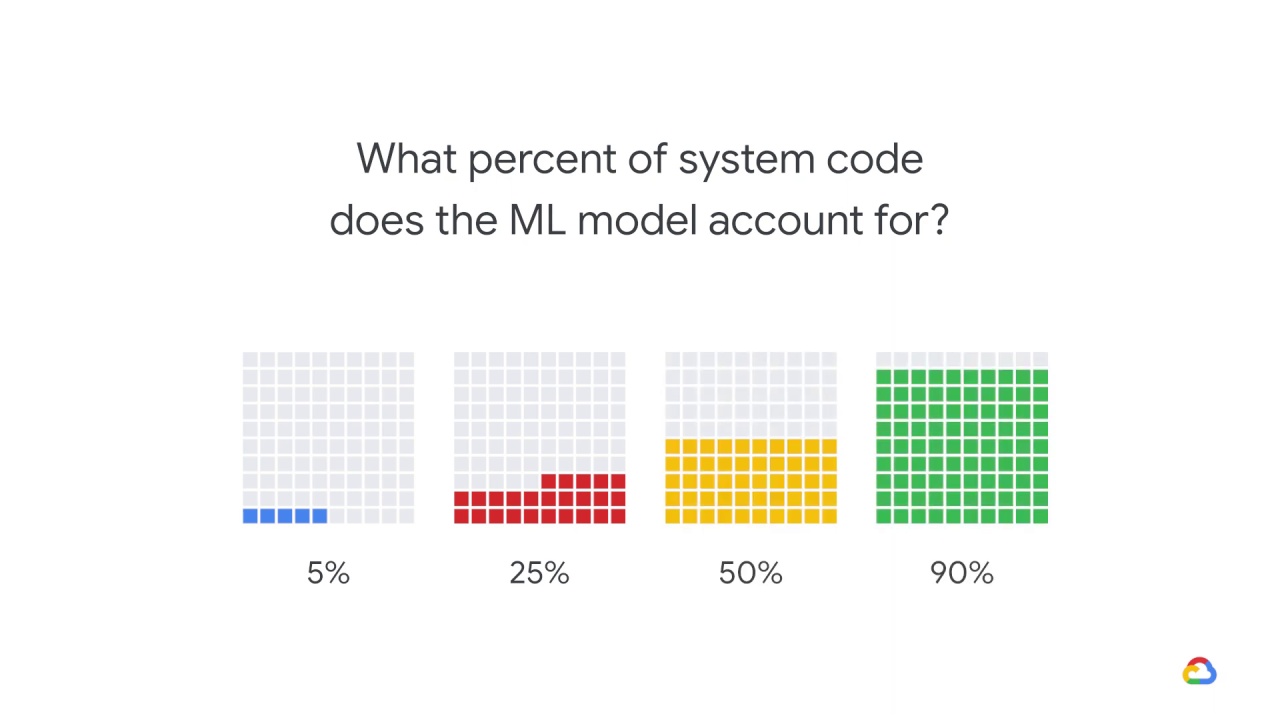
90%
You’ll recall from earlier in this specialization, we showed how time gets distributed among the different tasks necessary to launch an ML model and, surprisingly, modeling accounted for far less than most people expect.
The same is true with respect to the code.
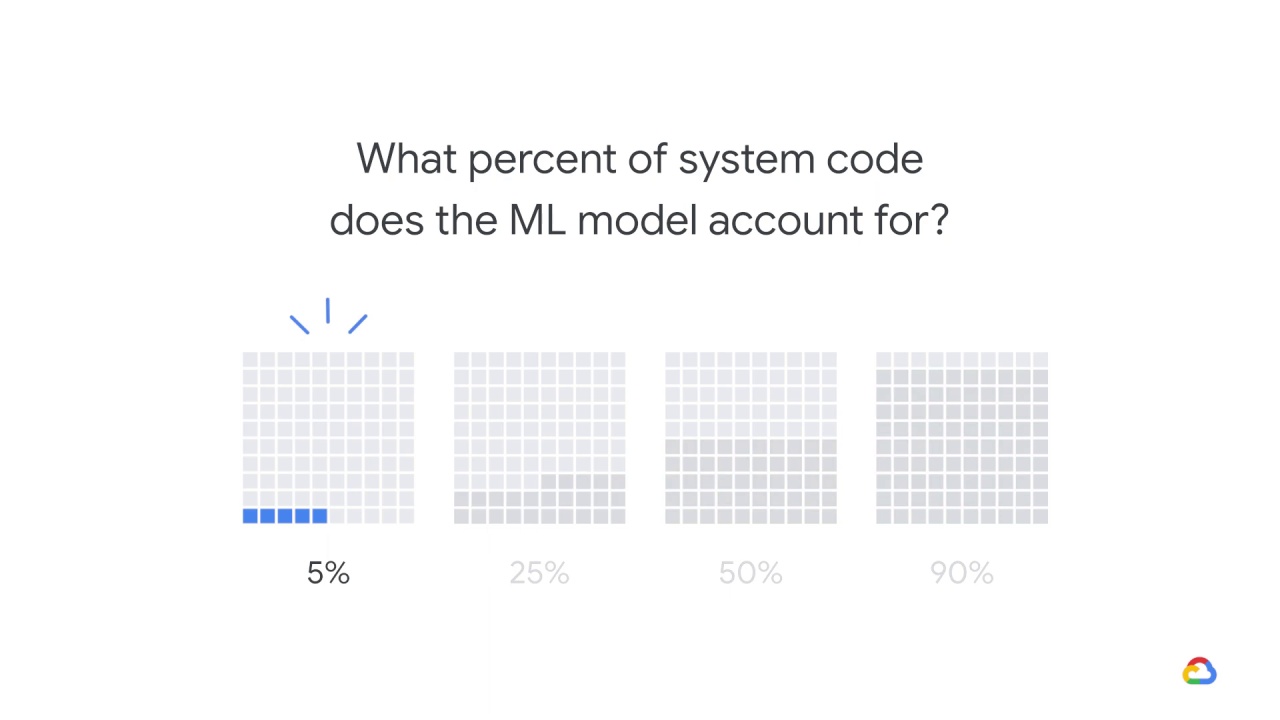
So, the answer is that ML model code typically accounts for about 5% of the overall code base.
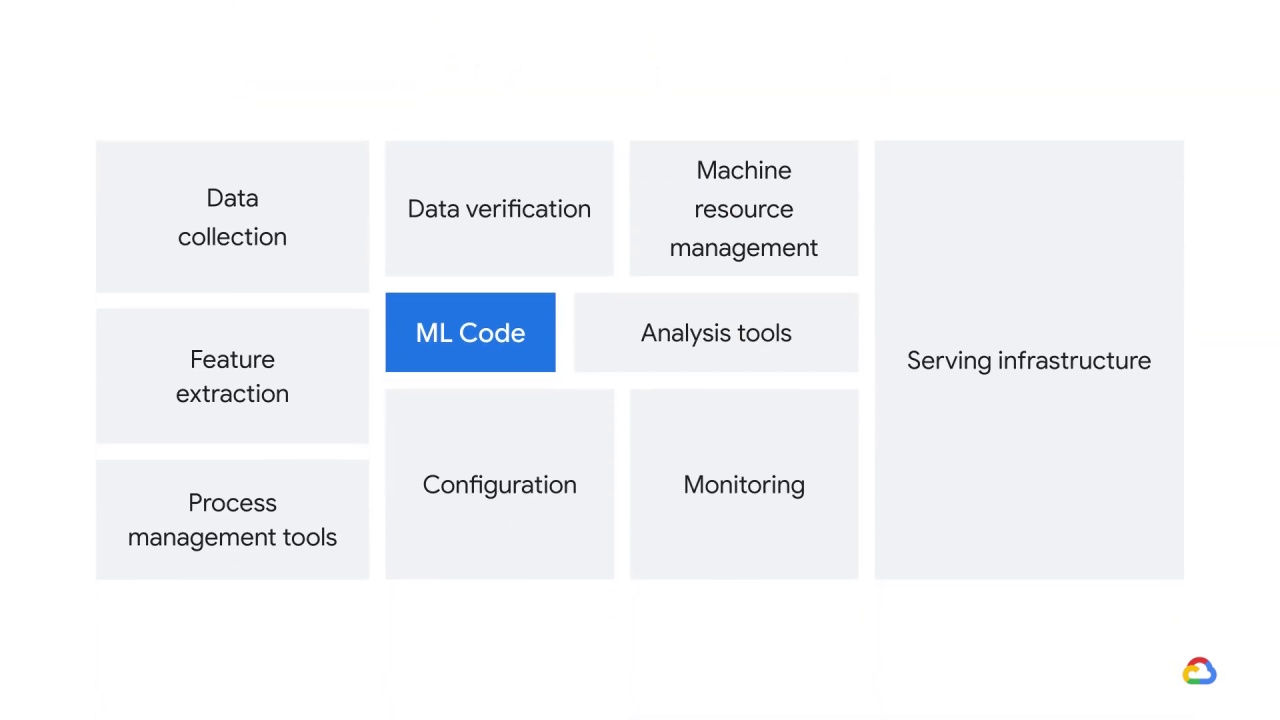
The reason that ML models account for such a small percentage is that to keep a system running in production requires doing a lot more than just computing the model’s outputs for a given set of inputs.
In this module, you’ll see what else a production ML system needs to do and how you can meet those needs.
Upon completing this module, you should acquire the knowledge to
choose an appropriate training and serving paradigm,
serve ML models scalably,
and design an architecture from scratch
And while our focus is on “Google Cloud”, it’s important that you always try and reuse generic systems when possible–many of which are open-source frameworks.

What’s true of software frameworks like TensorFlow
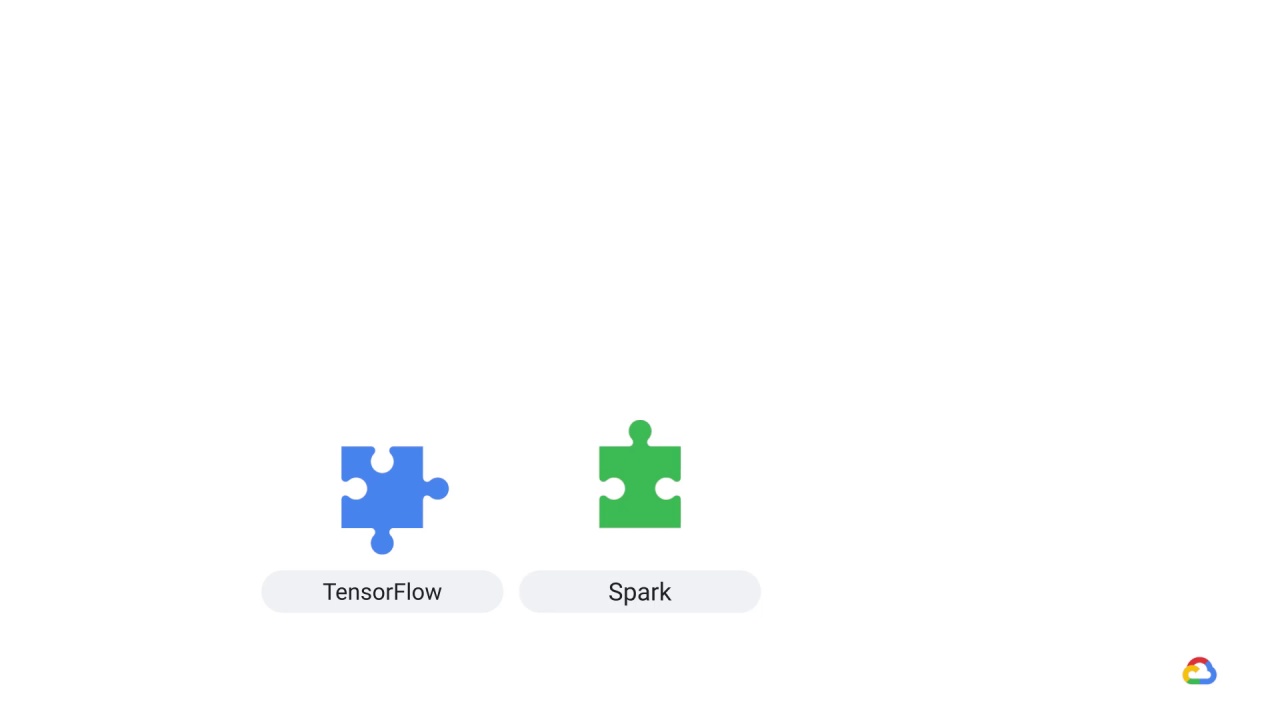
Spark,
or Apache Beam is also true of the underlying infrastructure on which you execute them.
Rather than spend time and effort provisioning infrastructure,
you can use managed services such as such as
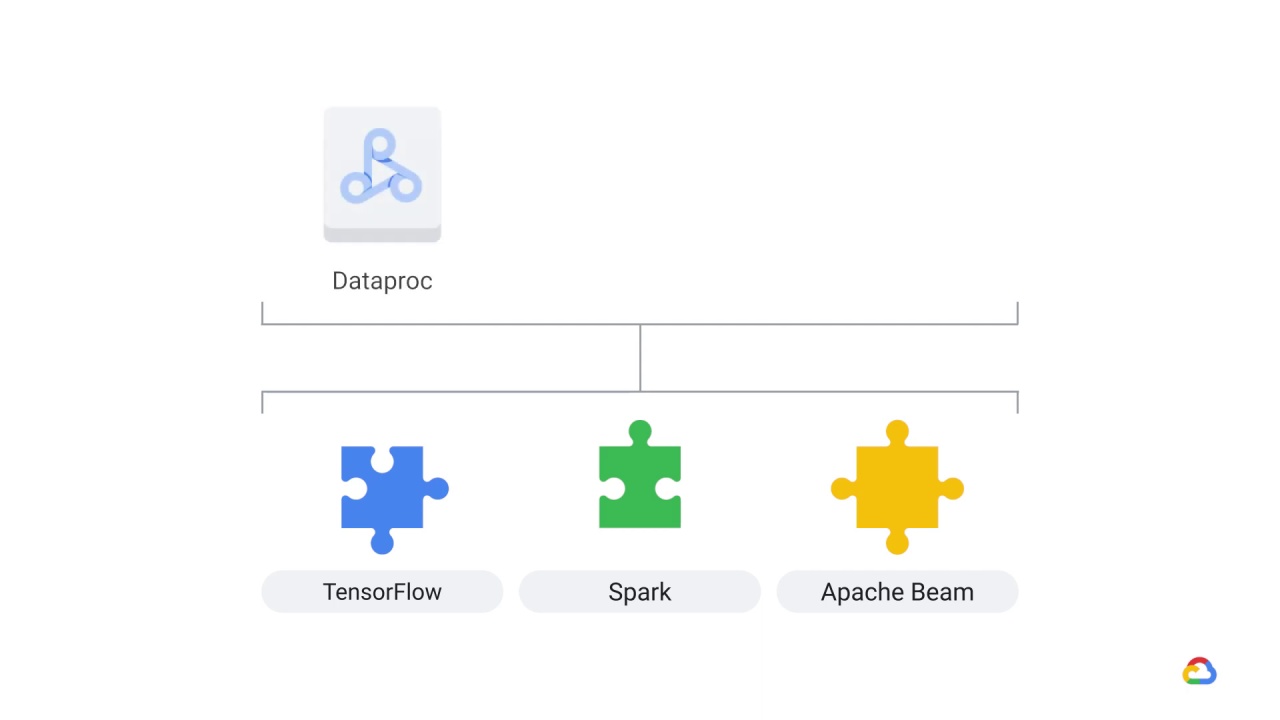
Dataproc,
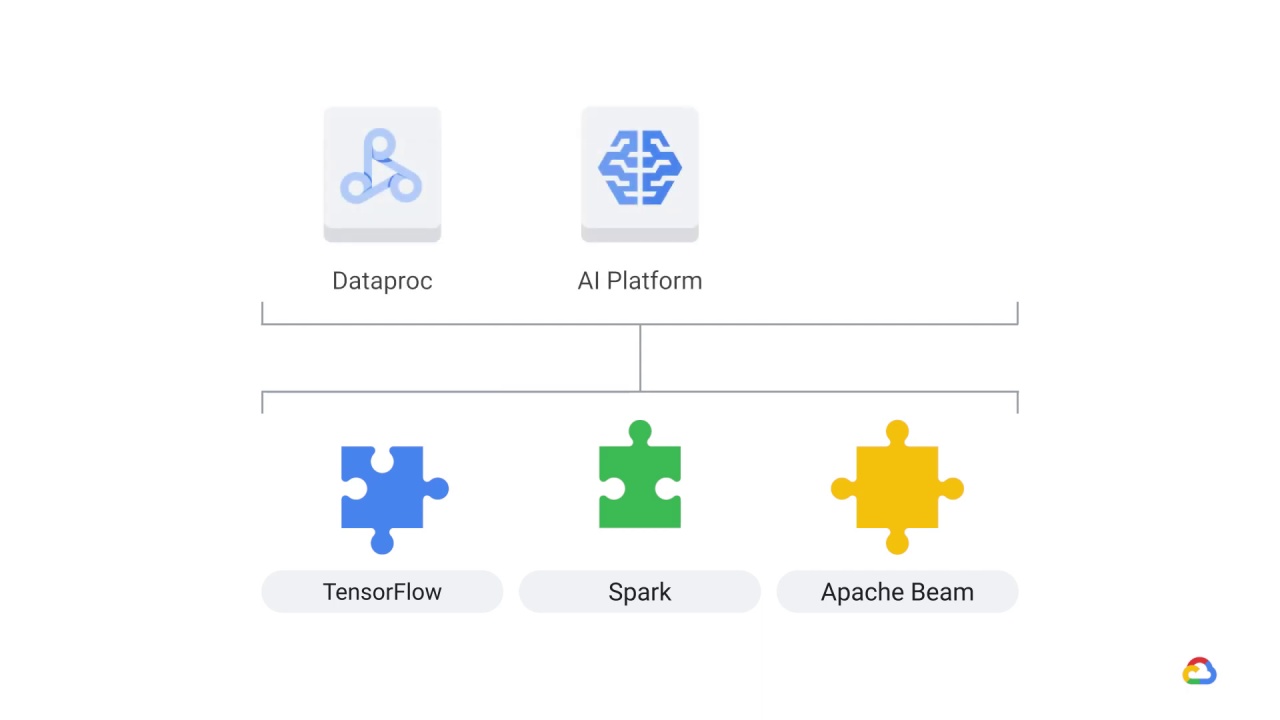
AI Platform,
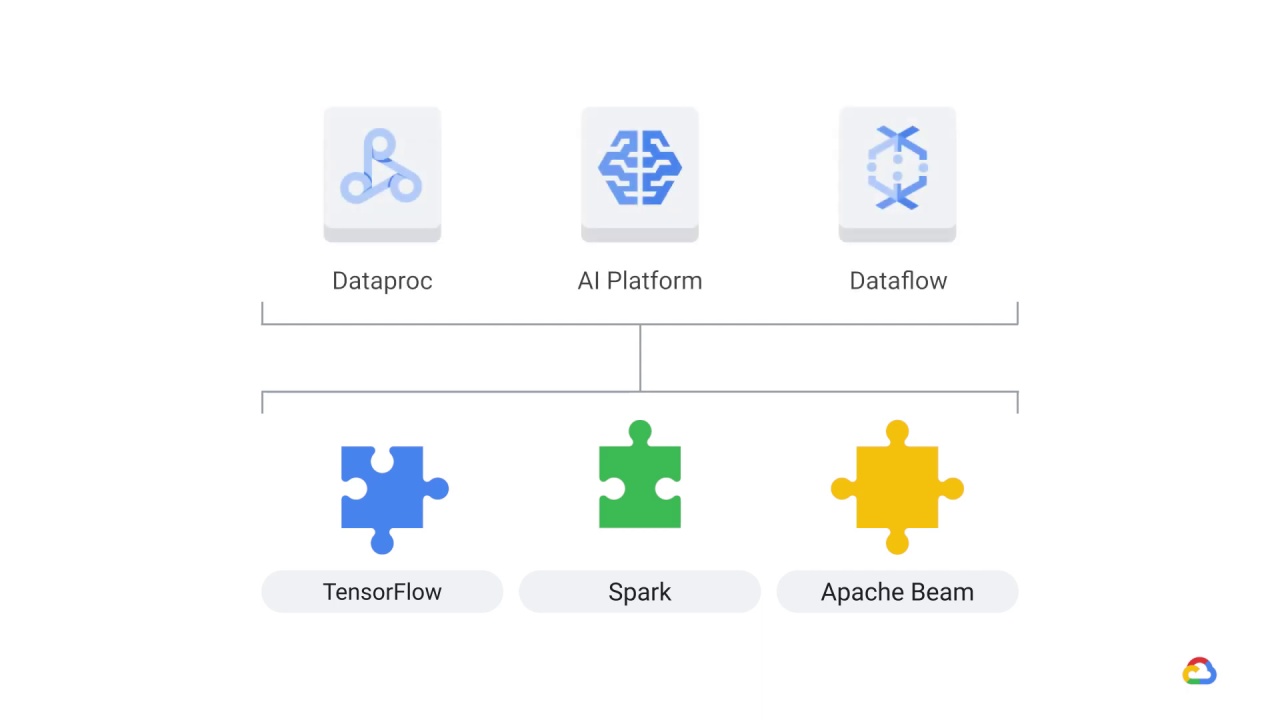
or Dataflow to execute your Spark, TensorFlow, and Beam code.