C3W4: Predicting the next word
Contents
C3W4: Predicting the next word#
https-deeplearning-ai/tensorflow-1-public/C3/W4/assignment/C3W4_Assignment.ipynb
Commit
63eaec8on Feb 22, 2023 - Compare
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
!gdown --id 108jAePKK4R3BVYBbYJZ32JWUwxeMg20K
SONNETS_FILE = './sonnets.txt'
with open('./sonnets.txt') as f:
data = f.read()
corpus = data.lower().split("\n")
print(f"There are {len(corpus)} lines of sonnets\n")
print(f"The first 5 lines look like this:\n")
for i in range(5):
print(corpus[i])
There are 2159 lines of sonnets
The first 5 lines look like this:
from fairest creatures we desire increase,
that thereby beauty's rose might never die,
but as the riper should by time decease,
his tender heir might bear his memory:
but thou, contracted to thine own bright eyes,
Tokenizing the text#
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
corpus[0]
tokenizer.texts_to_sequences([corpus[0]])
tokenizer.texts_to_sequences([corpus[0]])[0]
Generating n_grams#
def n_gram_seqs(corpus, tokenizer):
input_sequences = []
for line in corpus:
seq = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(seq)):
input_sequences.append(seq[:i+1])
return input_sequences
first_example_sequence = n_gram_seqs([corpus[0]], tokenizer)
print("n_gram sequences for first example look like this:\n")
first_example_sequence
n_gram sequences for first example look like this:
[[34, 417],
[34, 417, 877],
[34, 417, 877, 166],
[34, 417, 877, 166, 213],
[34, 417, 877, 166, 213, 517]]
next_3_examples_sequence = n_gram_seqs(corpus[1:4], tokenizer)
print("n_gram sequences for next 3 examples look like this:\n")
next_3_examples_sequence
n_gram sequences for next 3 examples look like this:
[[8, 878],
[8, 878, 134],
[8, 878, 134, 351],
[8, 878, 134, 351, 102],
[8, 878, 134, 351, 102, 156],
[8, 878, 134, 351, 102, 156, 199],
[16, 22],
[16, 22, 2],
[16, 22, 2, 879],
[16, 22, 2, 879, 61],
[16, 22, 2, 879, 61, 30],
[16, 22, 2, 879, 61, 30, 48],
[16, 22, 2, 879, 61, 30, 48, 634],
[25, 311],
[25, 311, 635],
[25, 311, 635, 102],
[25, 311, 635, 102, 200],
[25, 311, 635, 102, 200, 25],
[25, 311, 635, 102, 200, 25, 278]]
input_sequences = n_gram_seqs(corpus, tokenizer)
max_sequence_len = max([len(x) for x in input_sequences])
print(f"n_grams of input_sequences have length: {len(input_sequences)}")
print(f"maximum length of sequences is: {max_sequence_len}")
n_grams of input_sequences have length: 15462
maximum length of sequences is: 11
Add padding to the sequences#
def pad_seqs(input_sequences, maxlen):
padded_sequences = pad_sequences(input_sequences, maxlen=maxlen)
return padded_sequences
first_padded_seq = pad_seqs(first_example_sequence, max([len(x) for x in first_example_sequence]))
first_padded_seq
array([[ 0, 0, 0, 0, 34, 417],
[ 0, 0, 0, 34, 417, 877],
[ 0, 0, 34, 417, 877, 166],
[ 0, 34, 417, 877, 166, 213],
[ 34, 417, 877, 166, 213, 517]], dtype=int32)
next_3_padded_seq = pad_seqs(next_3_examples_sequence, max([len(s) for s in next_3_examples_sequence]))
next_3_padded_seq
array([[ 0, 0, 0, 0, 0, 0, 8, 878],
[ 0, 0, 0, 0, 0, 8, 878, 134],
[ 0, 0, 0, 0, 8, 878, 134, 351],
[ 0, 0, 0, 8, 878, 134, 351, 102],
[ 0, 0, 8, 878, 134, 351, 102, 156],
[ 0, 8, 878, 134, 351, 102, 156, 199],
[ 0, 0, 0, 0, 0, 0, 16, 22],
[ 0, 0, 0, 0, 0, 16, 22, 2],
[ 0, 0, 0, 0, 16, 22, 2, 879],
[ 0, 0, 0, 16, 22, 2, 879, 61],
[ 0, 0, 16, 22, 2, 879, 61, 30],
[ 0, 16, 22, 2, 879, 61, 30, 48],
[ 16, 22, 2, 879, 61, 30, 48, 634],
[ 0, 0, 0, 0, 0, 0, 25, 311],
[ 0, 0, 0, 0, 0, 25, 311, 635],
[ 0, 0, 0, 0, 25, 311, 635, 102],
[ 0, 0, 0, 25, 311, 635, 102, 200],
[ 0, 0, 25, 311, 635, 102, 200, 25],
[ 0, 25, 311, 635, 102, 200, 25, 278]], dtype=int32)
input_sequences = pad_seqs(input_sequences, max_sequence_len)
print(f"padded corpus has shape: {input_sequences.shape}")
padded corpus has shape: (15462, 11)
Split the data into features and labels#
def features_and_labels(input_sequences, total_words):
features = []
labels = []
for seq in input_sequences:
features.append(seq[:-1])
labels.append(seq[-1])
features = np.array(features)
one_hot_labels = to_categorical(labels, num_classes=total_words)
return features, one_hot_labels
first_features, first_labels = features_and_labels(first_padded_seq, total_words)
print(f"labels have shape: {first_labels.shape}")
print("\nfeatures look like this:\n")
first_features
labels have shape: (5, 3211)
features look like this:
array([[ 0, 0, 0, 0, 34],
[ 0, 0, 0, 34, 417],
[ 0, 0, 34, 417, 877],
[ 0, 34, 417, 877, 166],
[ 34, 417, 877, 166, 213]], dtype=int32)
features, labels = features_and_labels(input_sequences, total_words)
print(f"features have shape: {features.shape}")
print(f"labels have shape: {labels.shape}")
features have shape: (15462, 10)
labels have shape: (15462, 3211)
Create the model#
def create_model(total_words, max_sequence_len):
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(128)))
model.add(Dense(total_words, 'softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model = create_model(total_words, max_sequence_len)
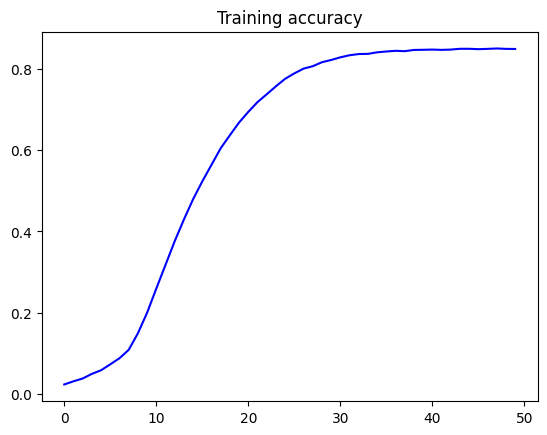
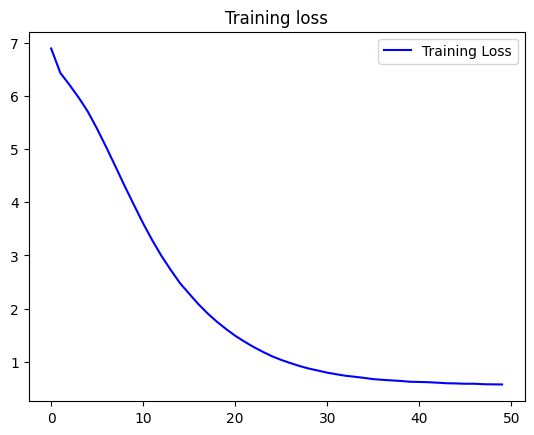
history = model.fit(features, labels, epochs=50, verbose=1)
acc = history.history['accuracy']
loss = history.history['loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.title('Training accuracy')
plt.figure()
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.title('Training loss')
plt.legend()
plt.show()
seed_text = "Help me Obi Wan Kenobi, you're my only hope"
next_words = 100
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict(token_list, verbose=0)
predicted = np.argmax(predicted, axis=-1).item()
output_word = tokenizer.index_word[predicted]
seed_text += " " + output_word
print(seed_text)
Help me Obi Wan Kenobi, you're my only hope the day to night right wrong night of heart in thee behold thine eye i lose or wet thy time more much lies in weeds eyes rage doth one can seen black imprison'd drop once have hell dye when their sun staineth date pen discloses had alone of more lovely past dispraise rare bond to misuse ages to be alone of thee thy bring eyes care truth is deem'd so foul a time was than behind behind behind a dye leaves have master now used more short my thought right alack from thee i live lies in my friend my