One-hot encoding and bag-of-words
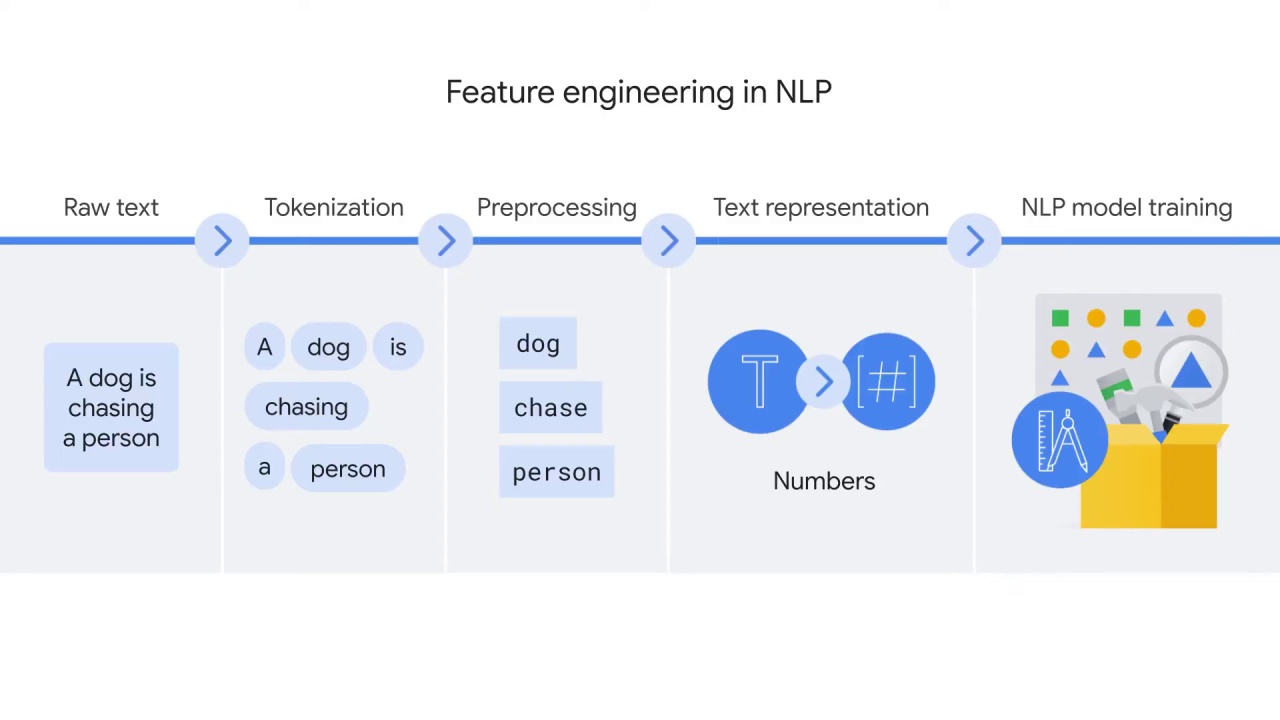
You were introduced to the general steps for preparing text data for model training.
You focused on tokenization, which aims to divide the text into smaller language units such as words.
You also briefly explored the different tasks of preprocessing.
The preprocessing generates a set of cleaned language units, which serve as the input of text representation.
If tokenization is how a computer reads text, the text representation solves the problem of how a computer understands text.


This challenge can be further split into two subproblems:




Morse code and ASCII can be used to turn text into digits, why can’t you use them in modern NLP?



The first idea is called one-hot encoding.
With this technique, you “one-hot” encode each word in your vocabulary.
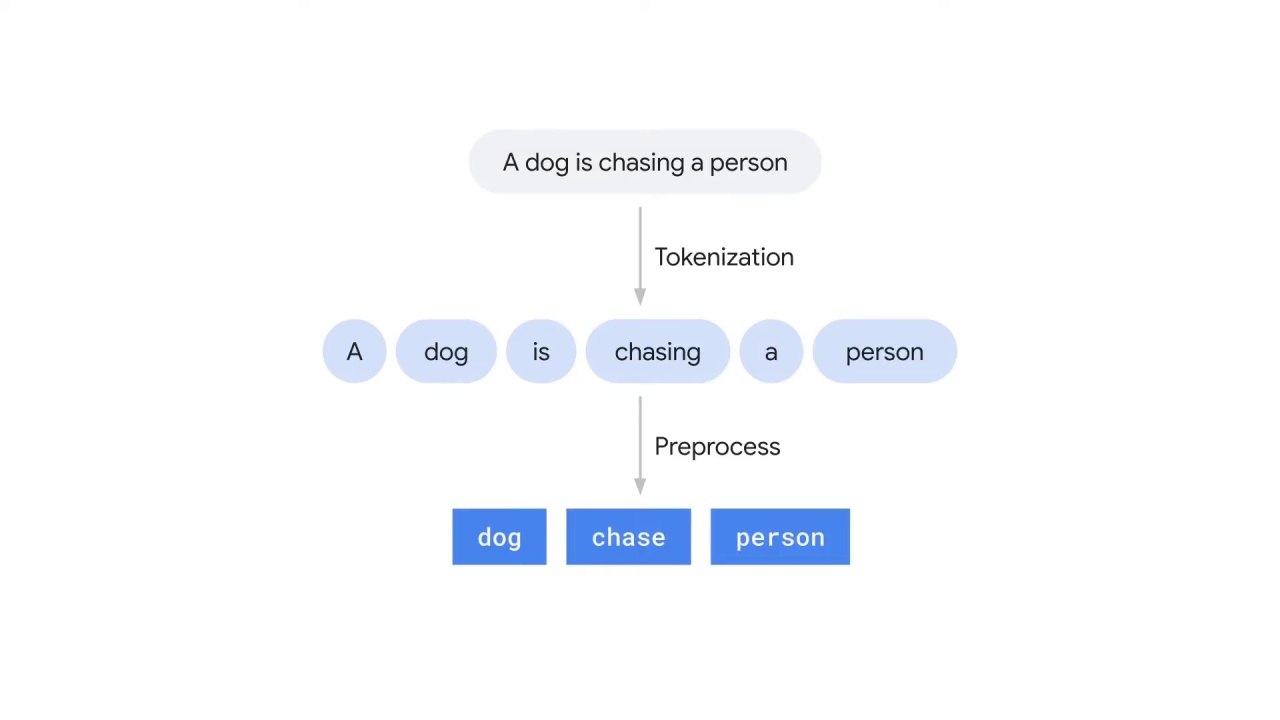
Consider the sentence “A dog is chasing a person.”
After tokenization and preprocessing, the sentence can be represented by three words: dog, chase, person.

To turn each word to a vector, you must first create a vector whose length equals the size of the vocabulary.
Assume you have a vocabulary that includes six words:

dog, chase, person, my, cat, and run.

Then, place a “1” to the position that corresponds to the word and “0”s to the rest of the positions.


In the example, the left represents the words from the sentence and the top represents the vocabulary.
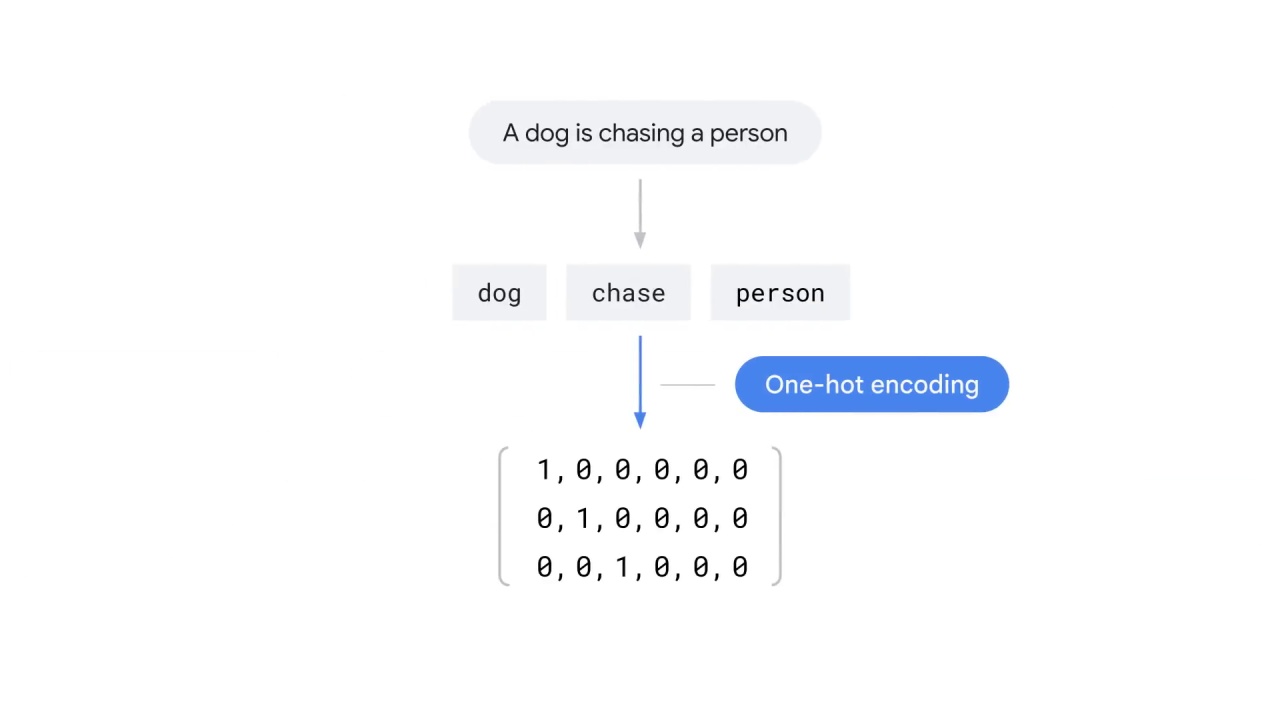
By conducting one-hot encoding, you converted the sentence “A dog is chasing a person” into a matrix that an ML model takes.


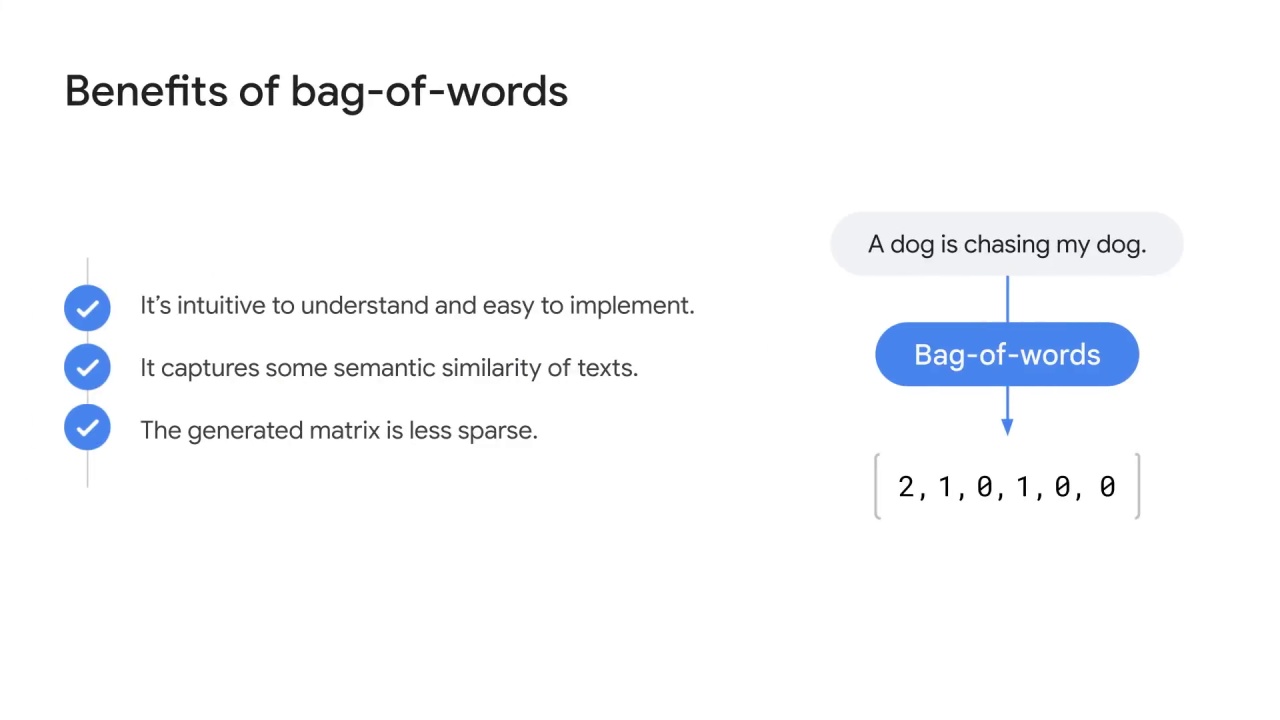
It’s intuitive to understand
and easy to implement.
However, let’s also acknowledge the disadvantages.

Recall the two sub-challenges of text representation, one-hot encoding has two main issues among other.



The dimensions of each vector depend on the size of the vocabulary, which can easily be tens of thousands.
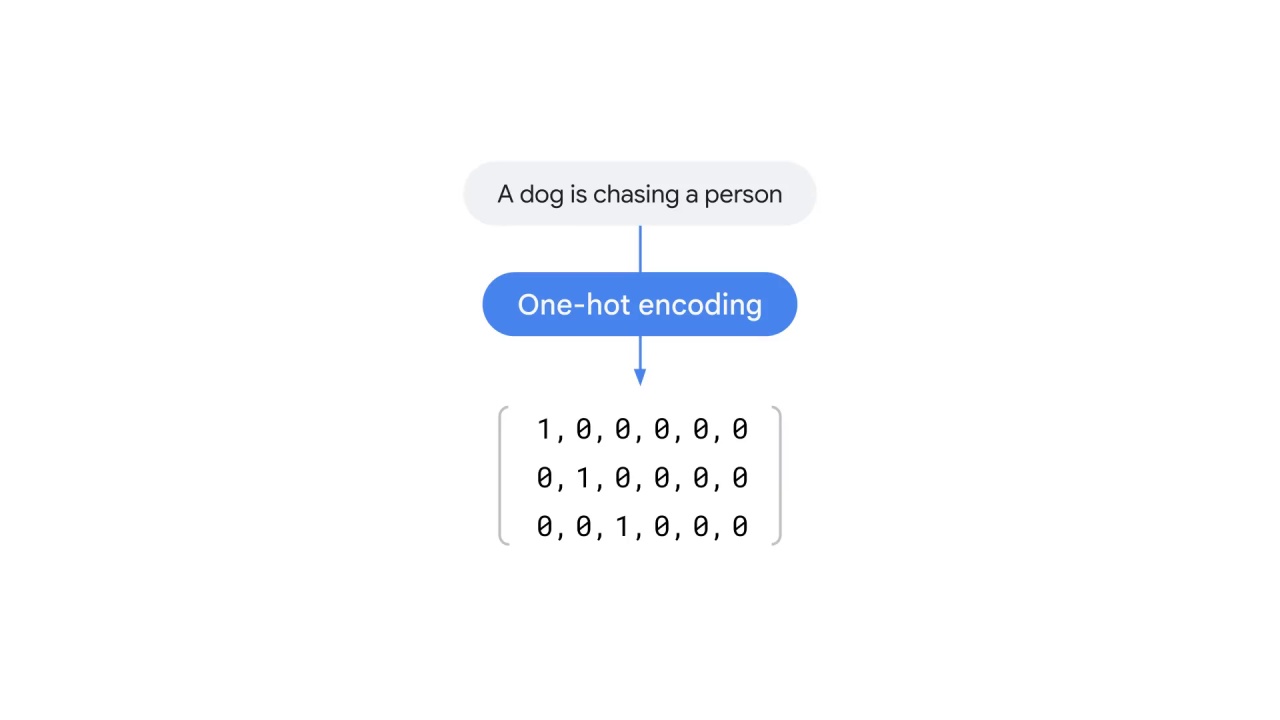
Also, most of the values of each vector are zeros, which means that this is a super sparse representation.

Another method of text representation is called bag-of-words.

You first collect a “bag” of words from the text in the NLP project to build your vocabulary (or dictionary).
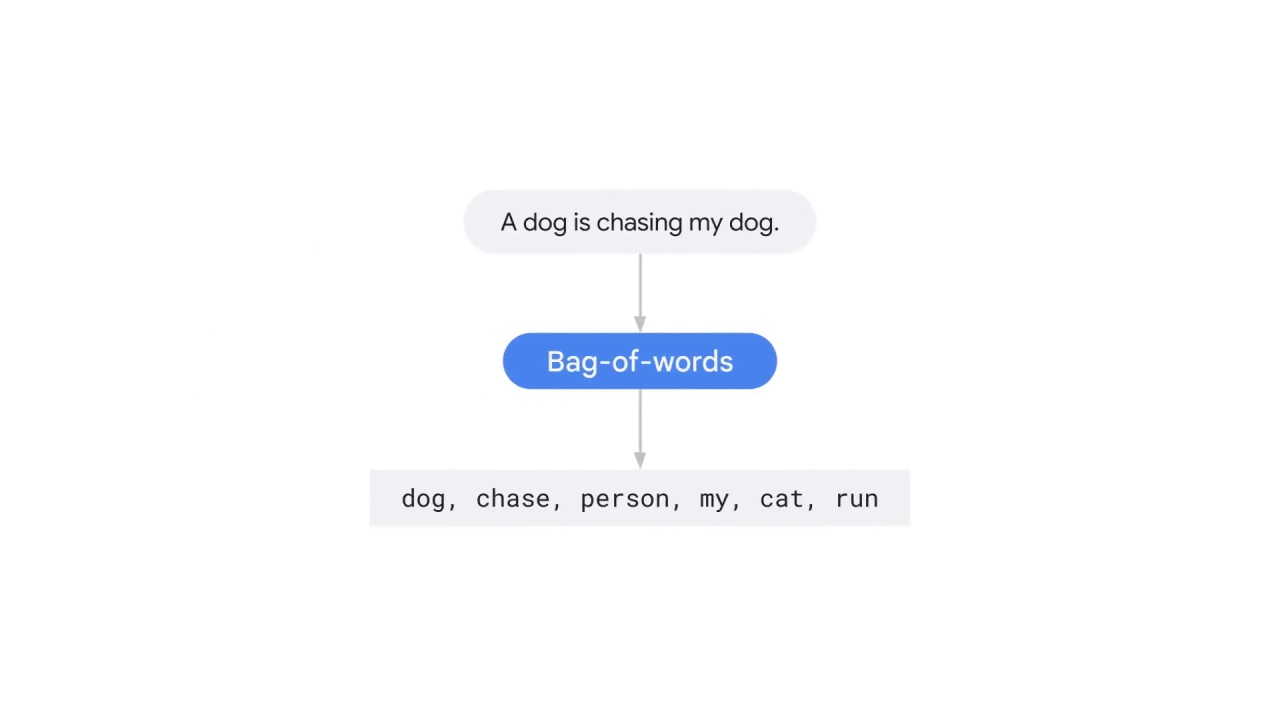
For example, you might have a vocabulary that includes six words: ___
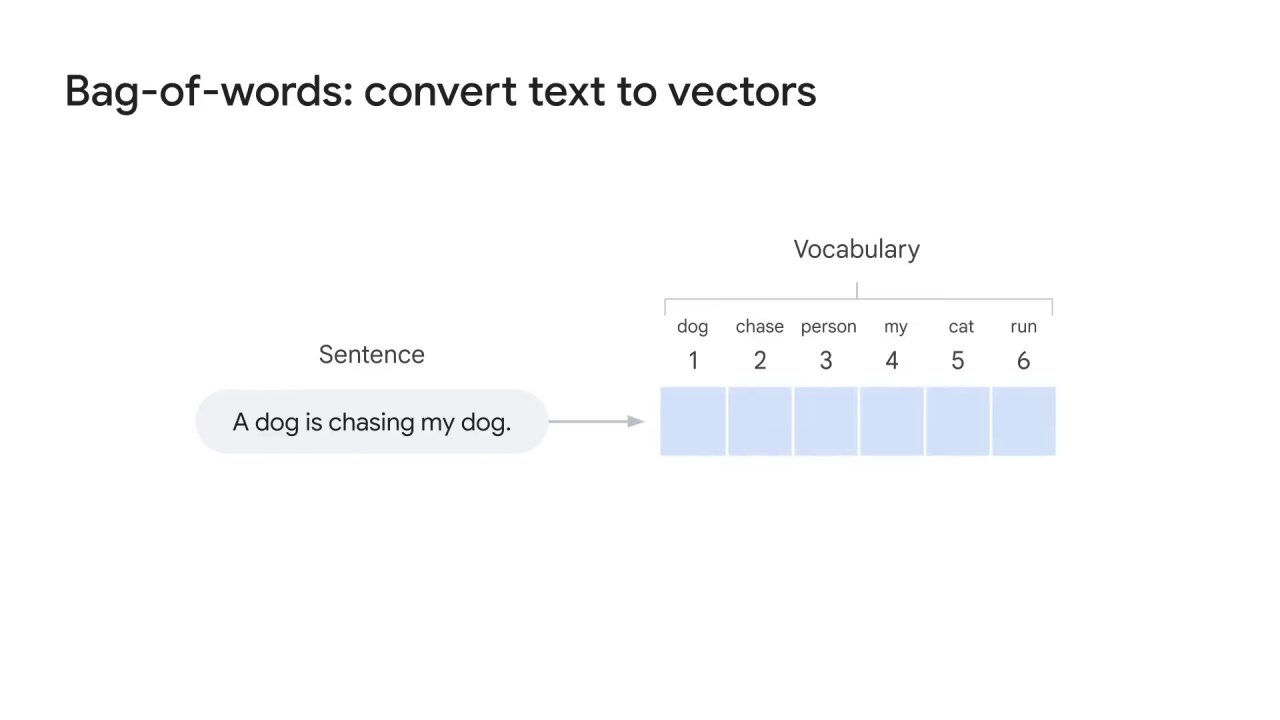
To represent the sentence, you must create a vector whose length is equal to the size of the vocabulary, then

place a value to represent the frequency in which the word appears in the given document.
Now you get the outcome vector as [2,1,0,1,0,0].
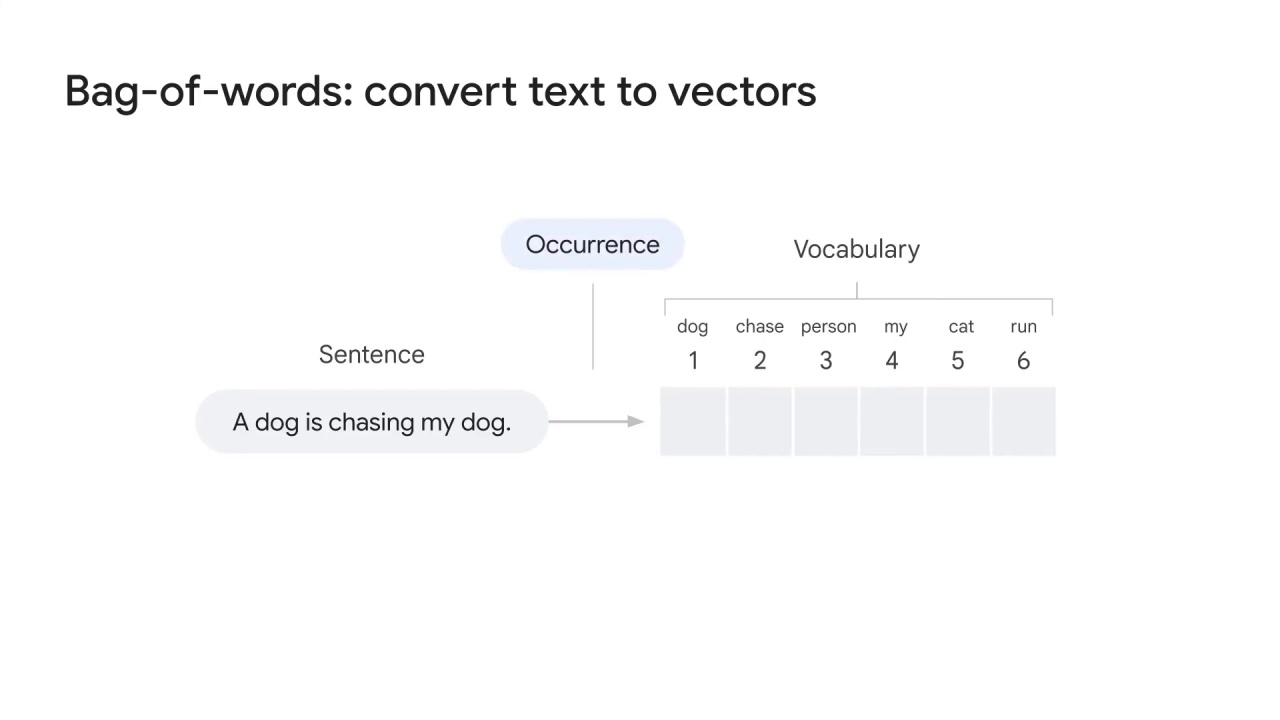
Sometimes you might not care about the frequency, but only the occurrence of the words.

You can simply use 1 and 0 to represent whether this word exists in the text.

By conducting bag-of-words, you can convert the sentence “a dog is chasing a person” to a vector that an ML model takes.
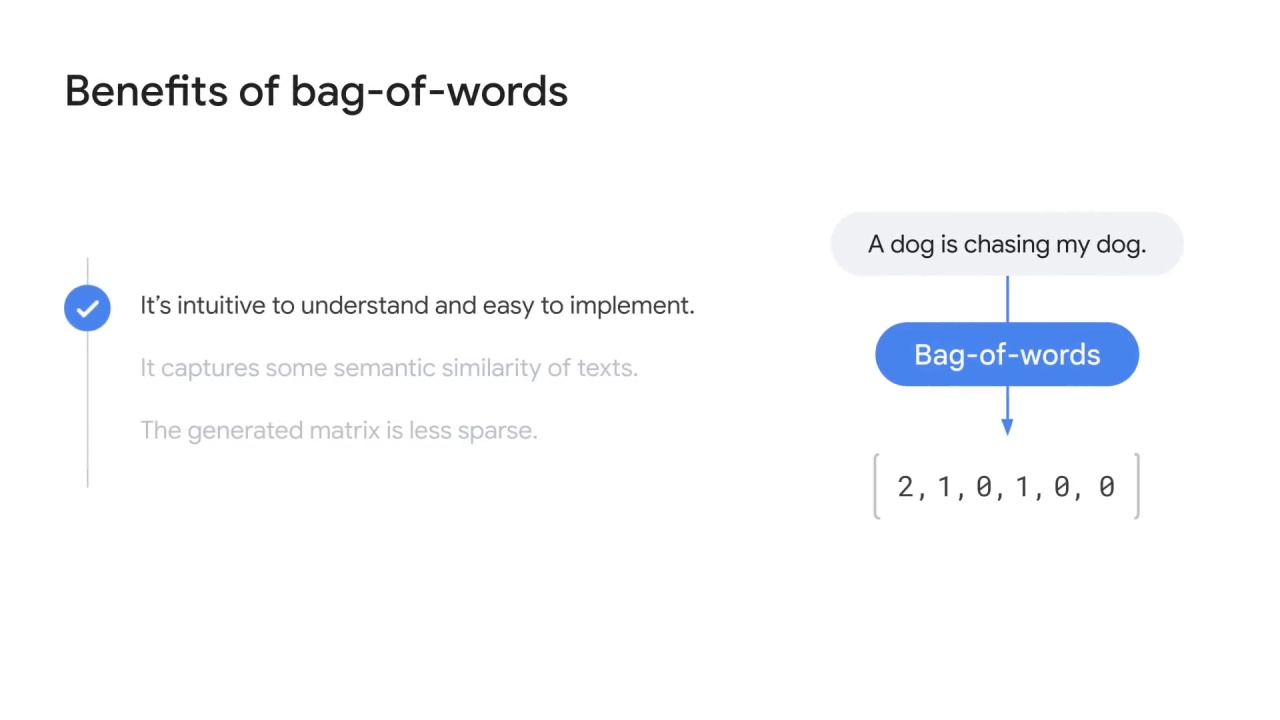
Similar to one-hot encoding, it’s intuitive to understand and easy to implement.
Compared to one-hot encoding, it has two improvements:
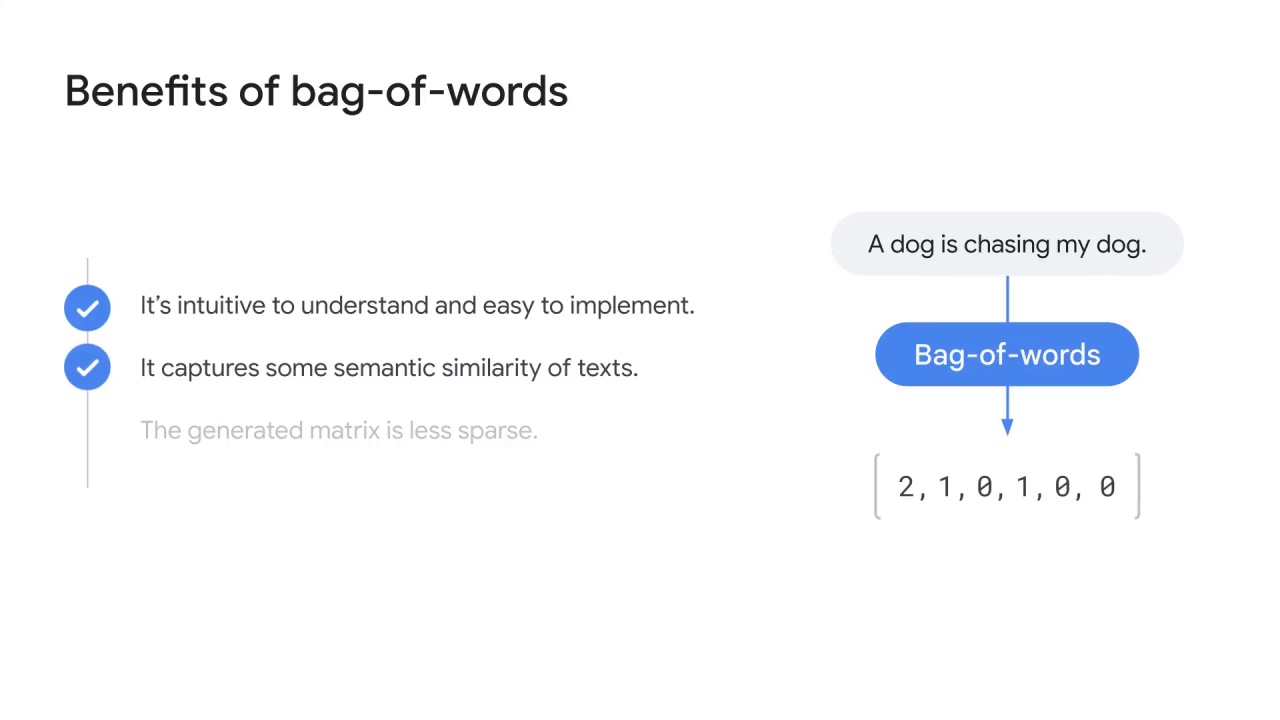


Bag-of-words still has high-dimensional and sparse vectors.
The dimension of the vector increases with the size of the vocabulary.
Thus sparsity remains a problem.

Although it captures some semantic similarities between sentences, it still far from captures the relationship between words.
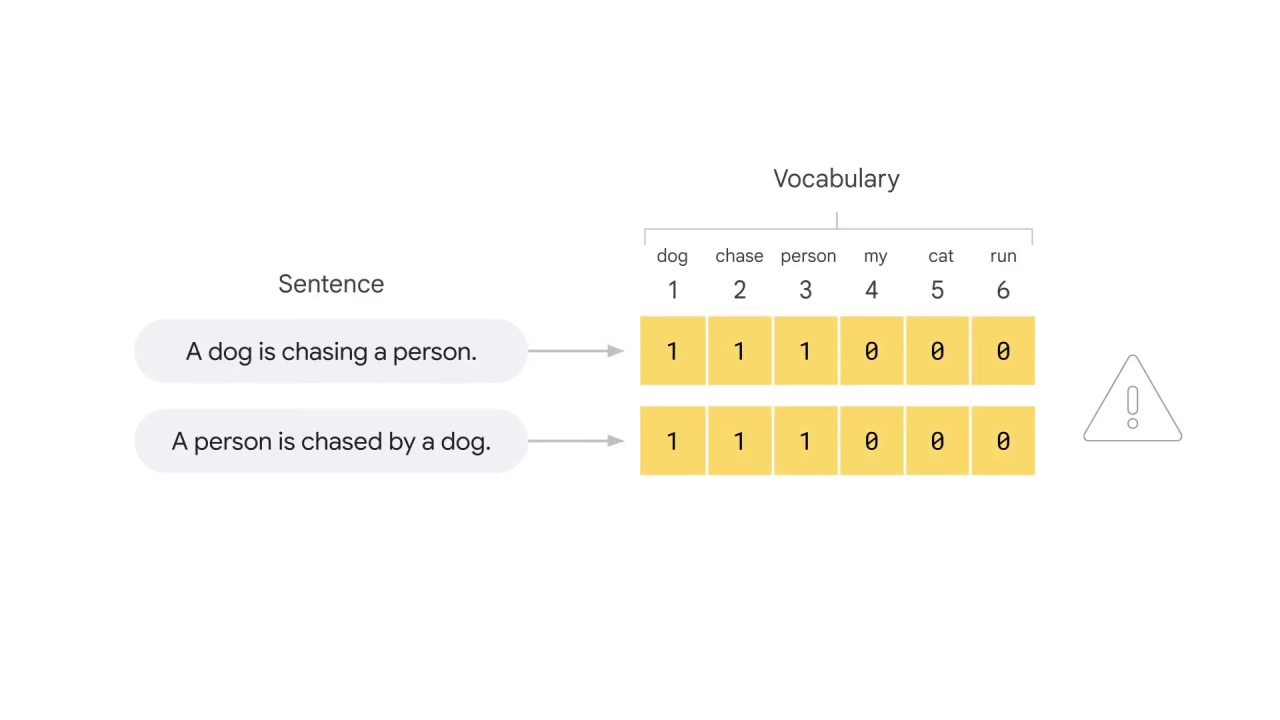
Bag-of-words does not consider the order of the words and that is why it’s called a “bag” of words.

The basic vectorization methods such as one-hot encoding and bag-of-words are not ideal.
Two major problems that have not been solved include:
the high-dimensional and sparse vectors;
the lack of relationship between words.