Training design decisions

One of the key decisions you’ll need to make about your production ML system concerns training.

Here’s a question.
How is physics

unlike fashion?**
If we assume that science is about discovering relationships that already exist in the world, then the answer is that

physics is constant whereas fashion isn’t.

To see some proof, just look at some old pictures of yourself.

Now, you might be asking, why is this relevant?

Well, when making decisions about training, you have to decide whether the phenomenon you’re modelling

is more like physics,

or like fashion.

When training your model, there are two paradigms; static training and dynamic training.

In static training, we gather our data, we partition it, we train our model, and then we deploy it.
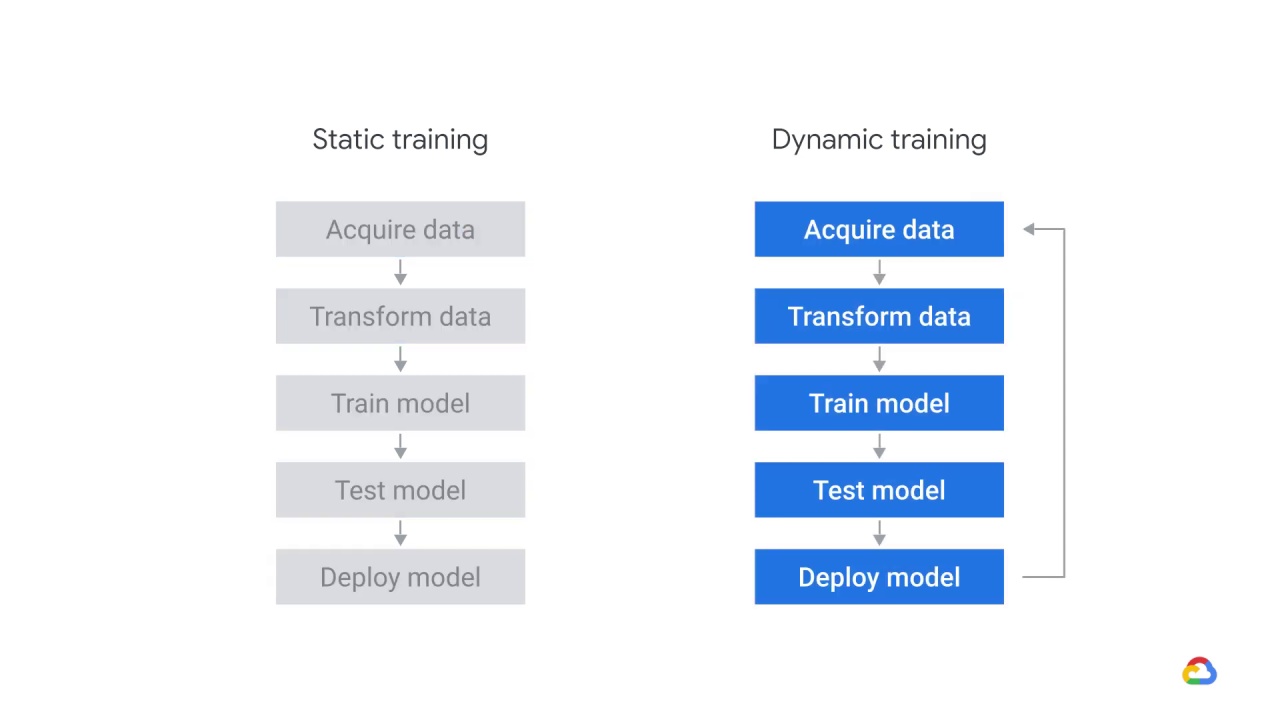
In dynamic training, we do this repeatedly as more data arrives.
This leads to the fundamental trade-off between static and dynamic.

Static is simpler to build and test,

but likely to become stale.

Whereas dynamic is harder to build and test,

but will adapt to changes.
And the tendency to become or not become stale is what was being alluded to earlier when we contrasted physics and fashion.

If the relationship you’re trying to model is one that’s constant, like physics, then a statically trained model may be sufficient.

If the relationship you’re trying to model is one that changes, then the dynamically trained model might be more appropriate.
Part of the reason the dynamic is harder to build and test is that new data may have all sorts of bugs in it.
And that’s something we’ll talk about more deeply in a later module on designing adaptable ML systems.

Engineering might also be harder because we need more
monitoring,

model rollback,

and data quarantine capabilities.
Let’s explore some use cases and think about which sort of training style would be most appropriate.
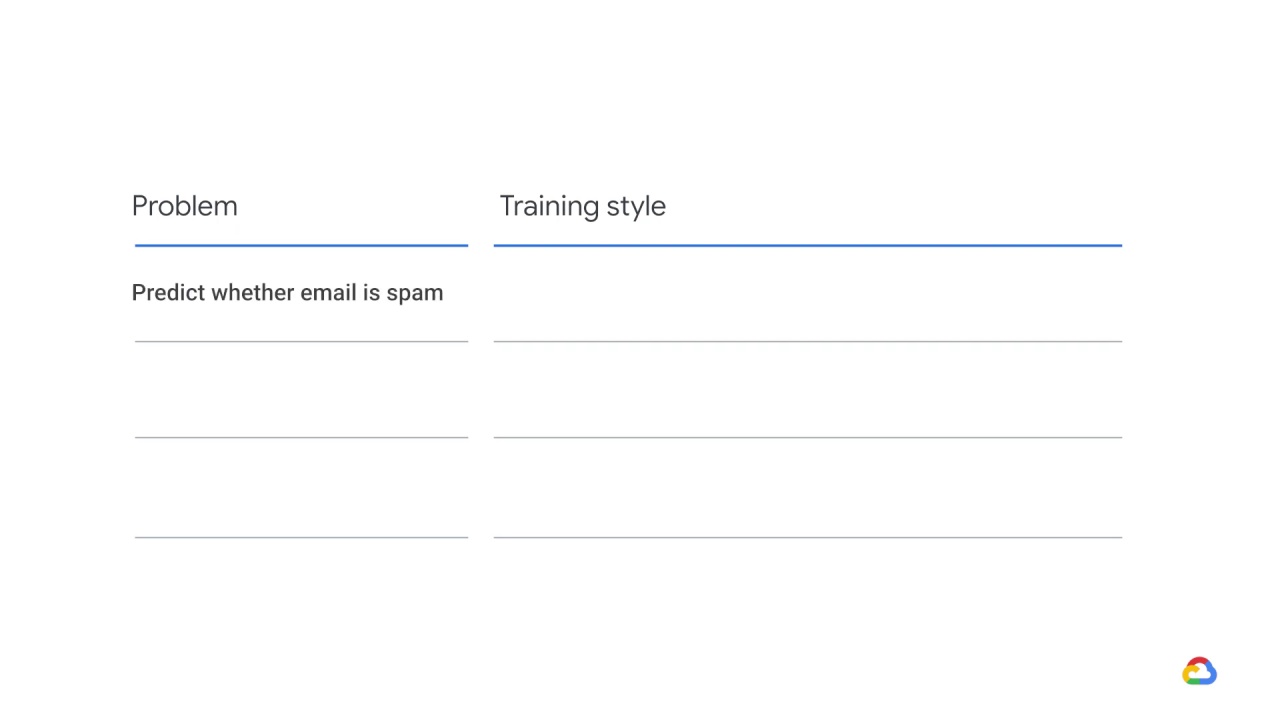
The first use case concerns spam detection, and the question you should ask
yourself is,
“how fresh does spam detection need to be?”
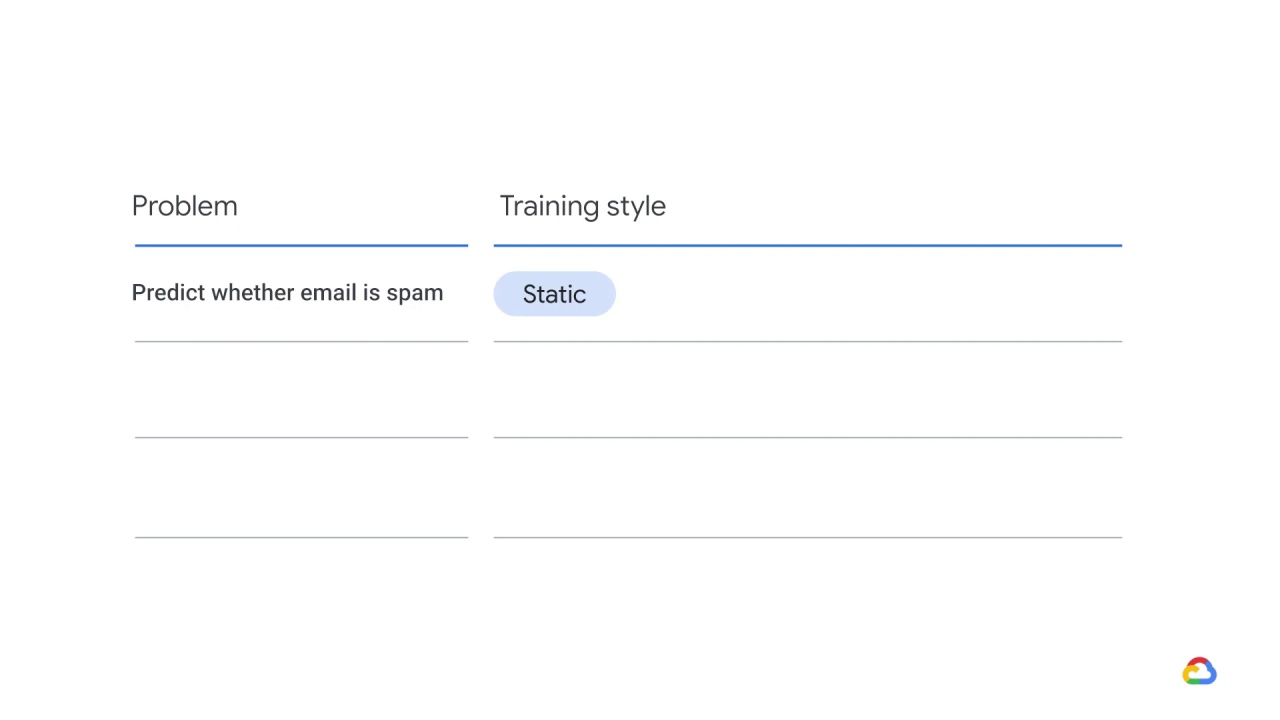
You could do this as static, but spammers are a crafty and determined bunch.
They will probably discover ways of passing whatever filter you impose within a short time.

So, dynamic is likely to be more effective over time.
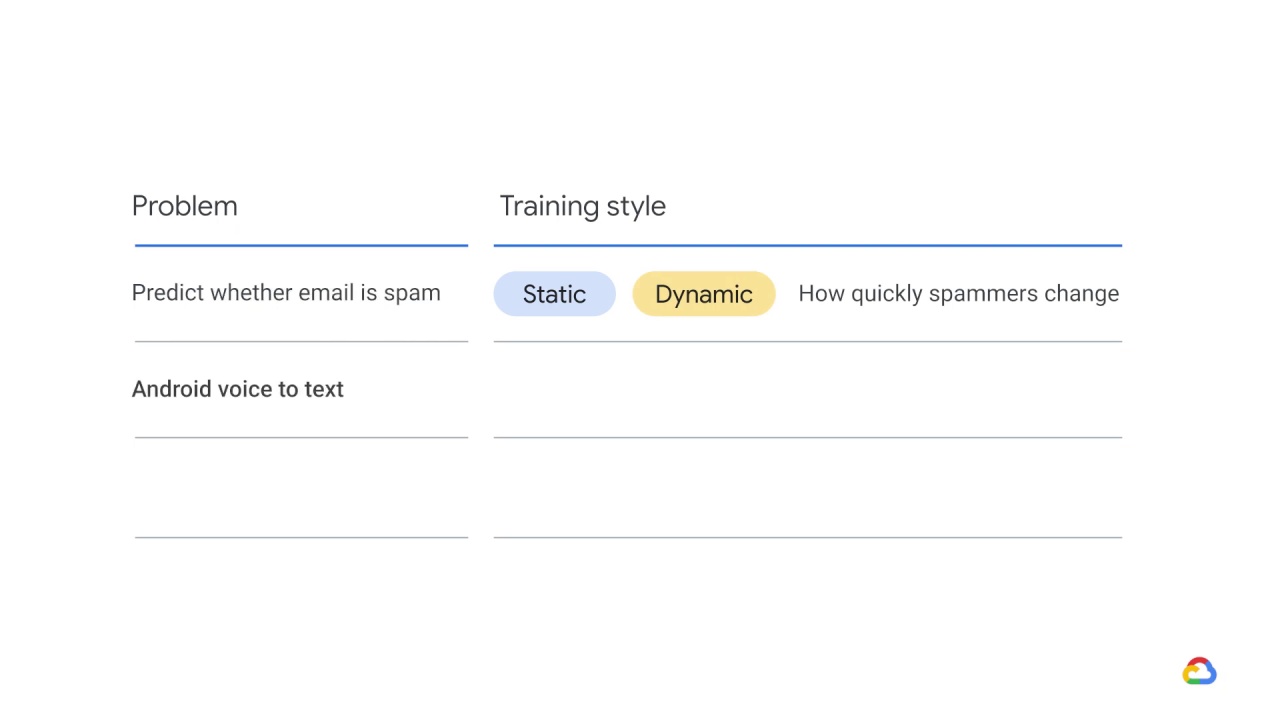
What about Android Voice-to-Text?
Note that this question has some subtlety.

For a global model, training offline is probably fine.

But, if you want to personalize the voice recognition, you may need to do something online, or at least different, on the phone.
So this could be static or dynamic, depending on whether you want global or personalized transcription.

**What about ad conversion rate? **
The interesting subtlety here is that conversions may come in very late.
For example, if I’m shopping for a car online, I’m unlikely to buy for a very long time.

This system could use dynamic training, then regularly going back at different intervals to catch up on new conversion data that has arrived for the past.
So in practice, most of the time, you’ll need to use dynamic,

but you might start with static because it’s simpler.

In a reference architecture for static training, models are trained once and then pushed to AI Platform.

Now, for dynamic training, there are three potential architectures to explore,

Cloud Functions,

App Engine,

or Cloud Dataflow.

In a general architecture for dynamic training using Cloud functions, a new data file appears in Cloud storage and then
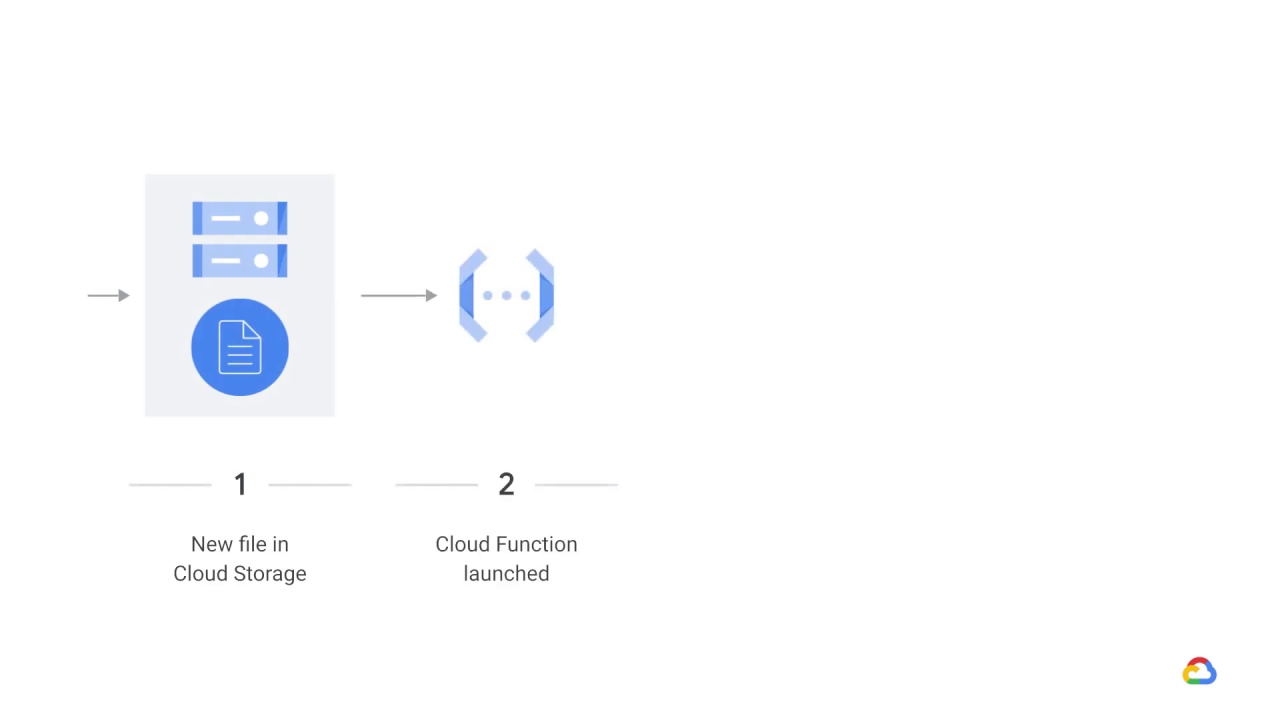
the Cloud function is launched.
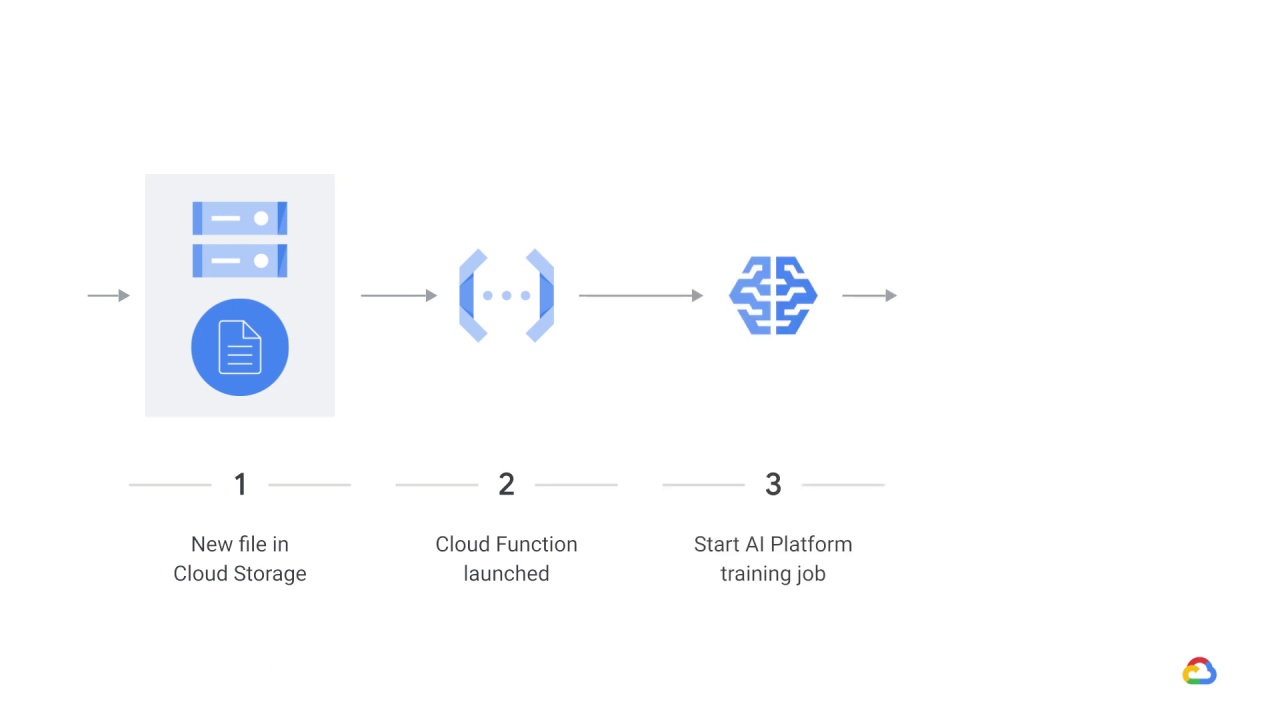
After that, the Cloud function starts the AI Platform training job, and then
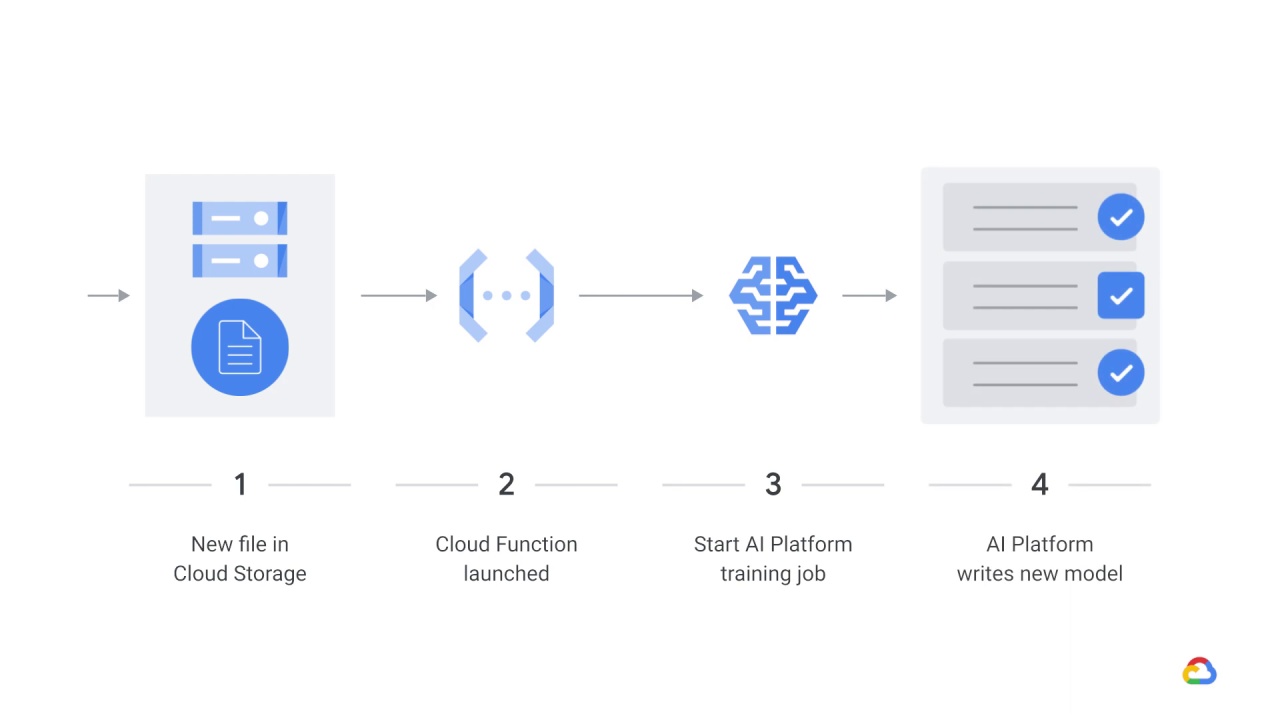
the AI Platform writes out a new model.

In a general architecture for dynamic training using App Engine, when a user makes a web request, perhaps from a dashboard to App Engine,
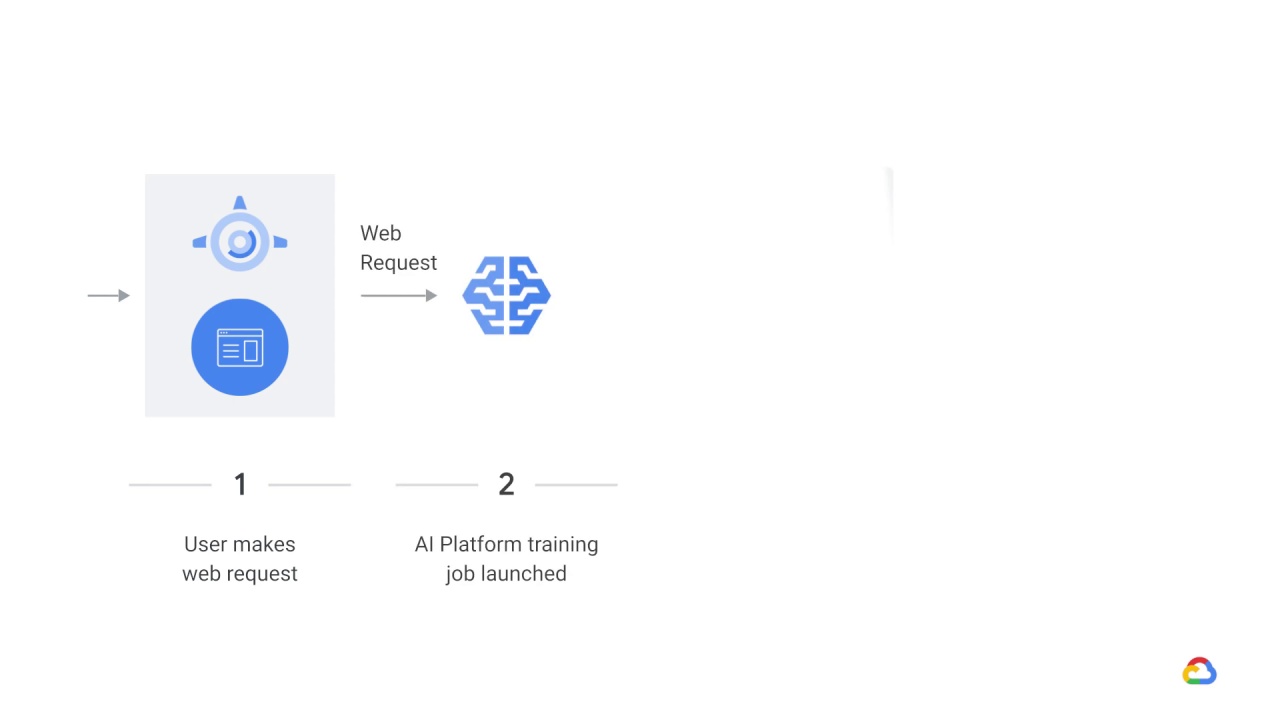
an AI Platform training job is launched,
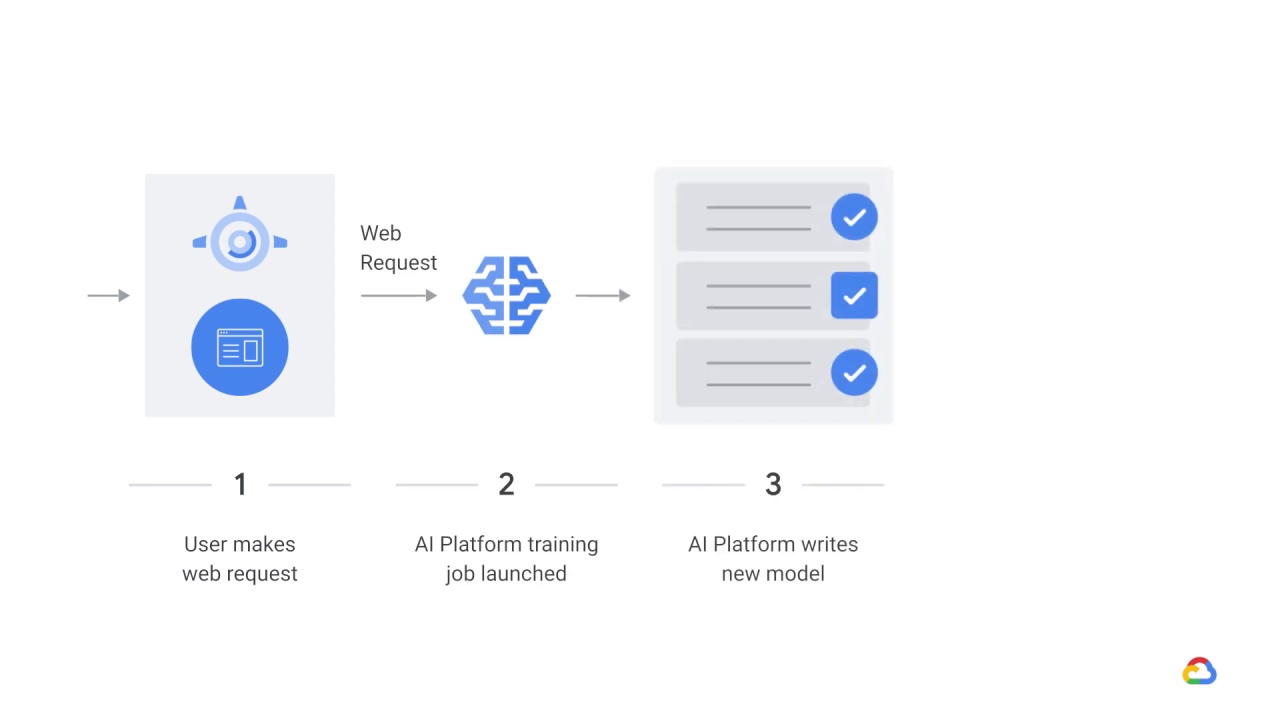
and the AI Platform job writes a new model to Cloud storage.
From there,
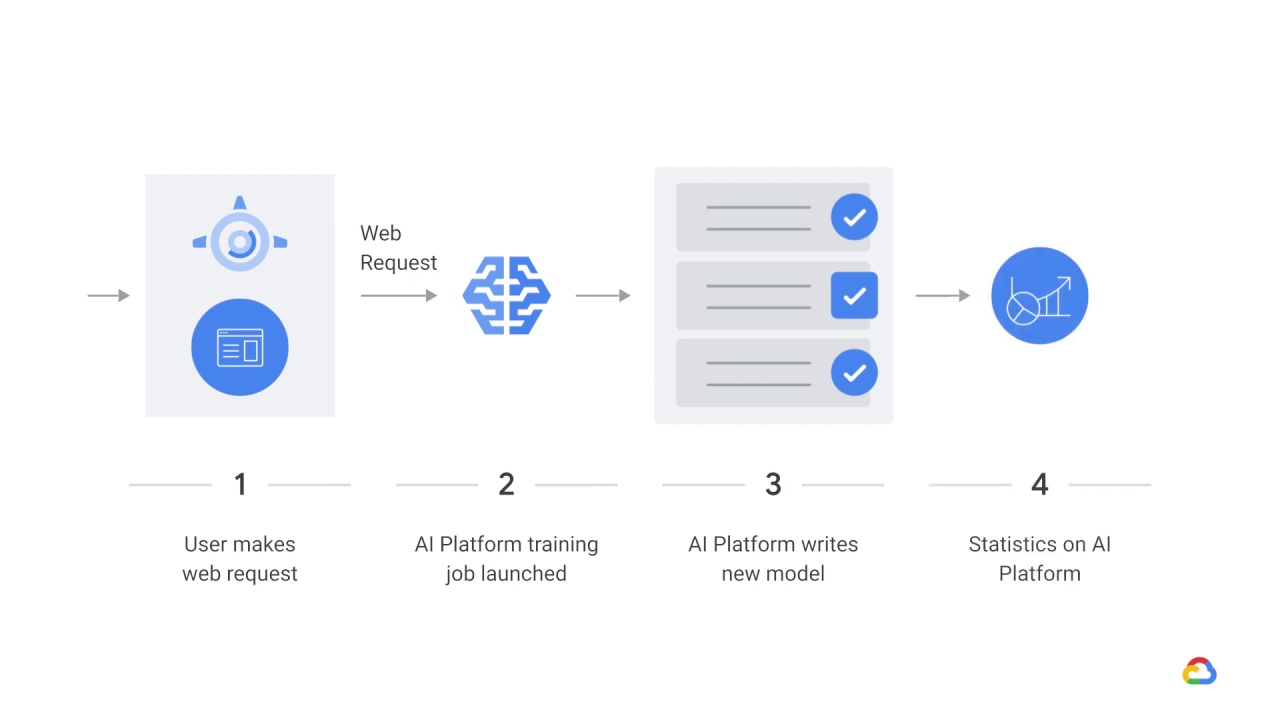
the statistics of the training job are displayed to the user when the job is complete.
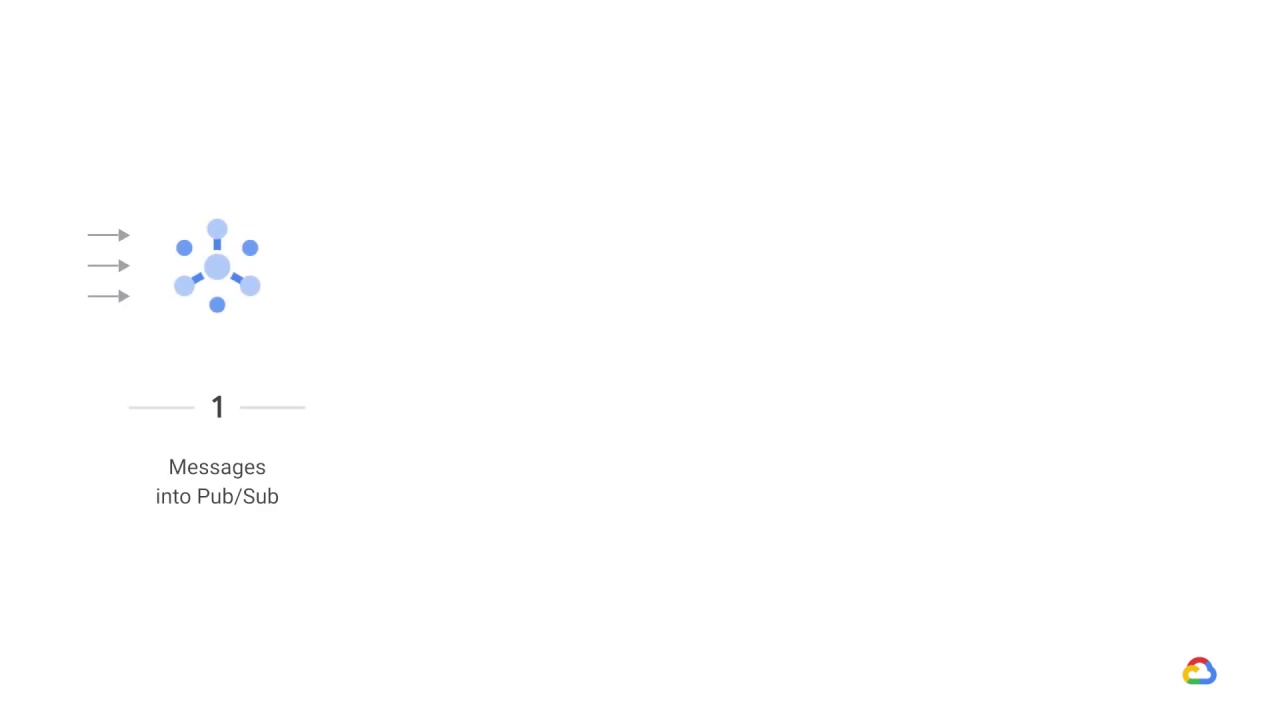
It’s possible that the Dataflow pipeline is also invoking the model for predictions.
Here, a streaming topic is ingested into Pub/Sub from subscribers.
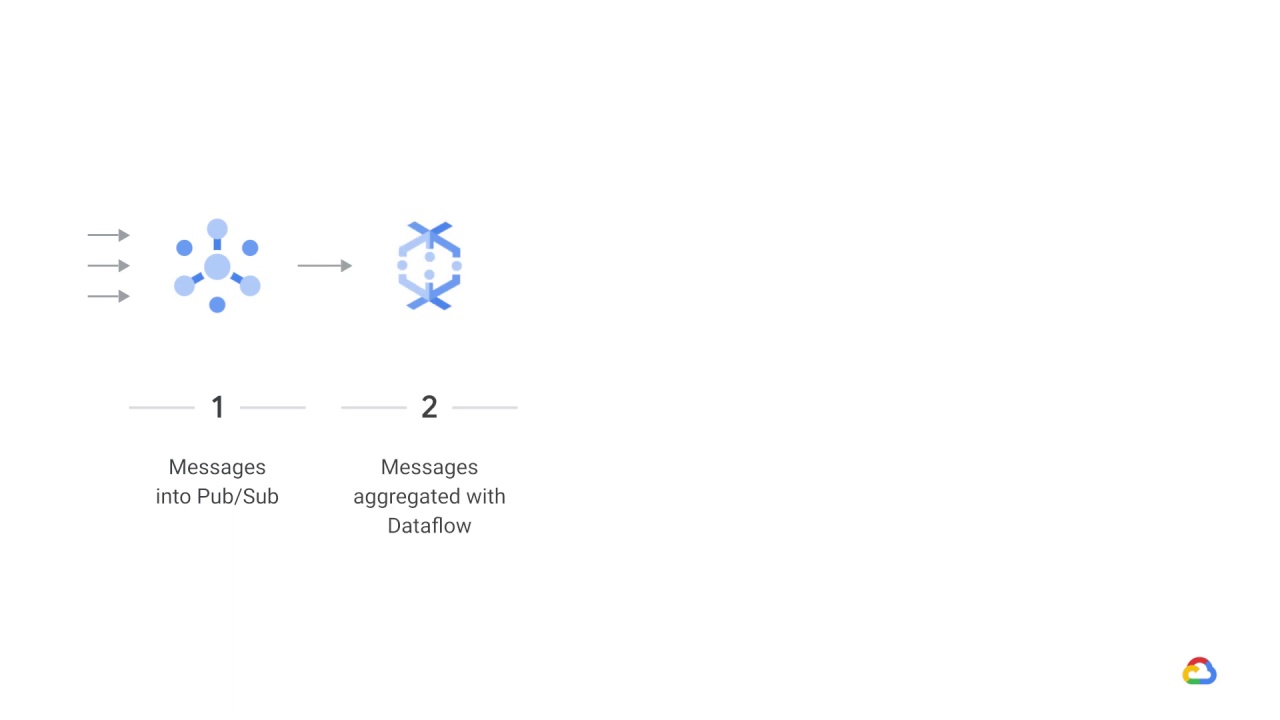
Messages are then aggregated with Dataflow
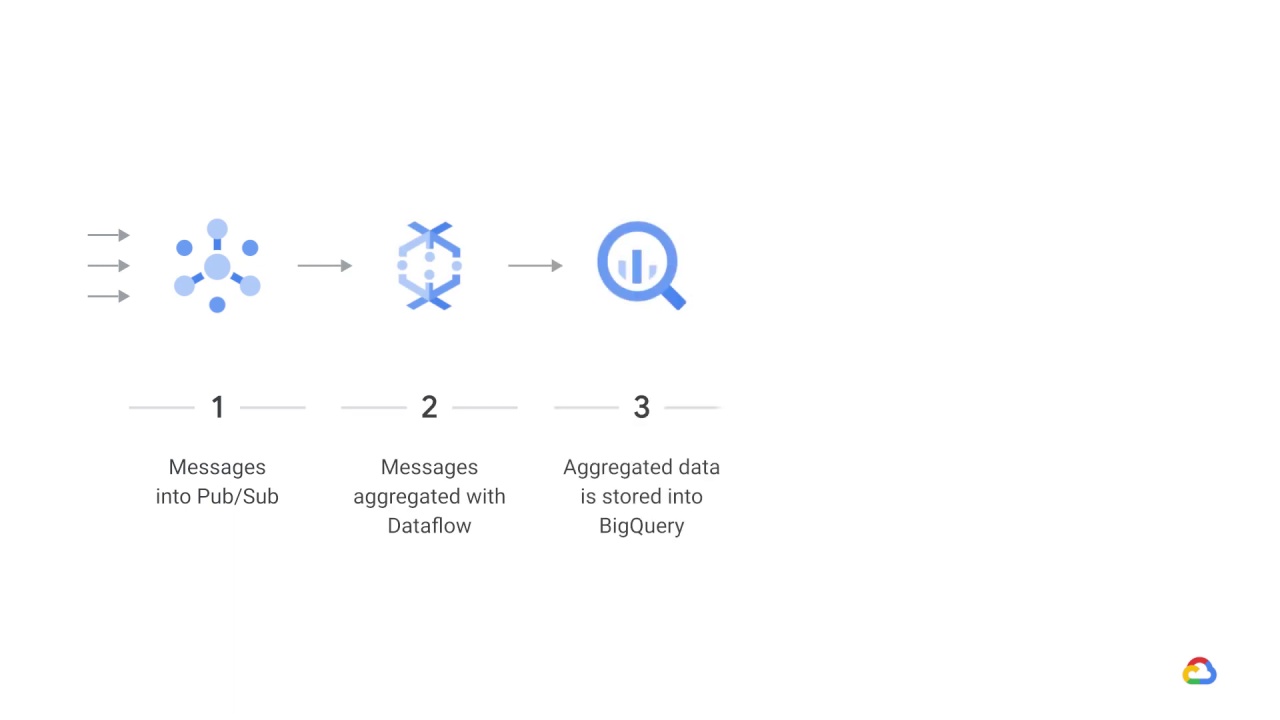
and aggregated data is stored into BigQuery.
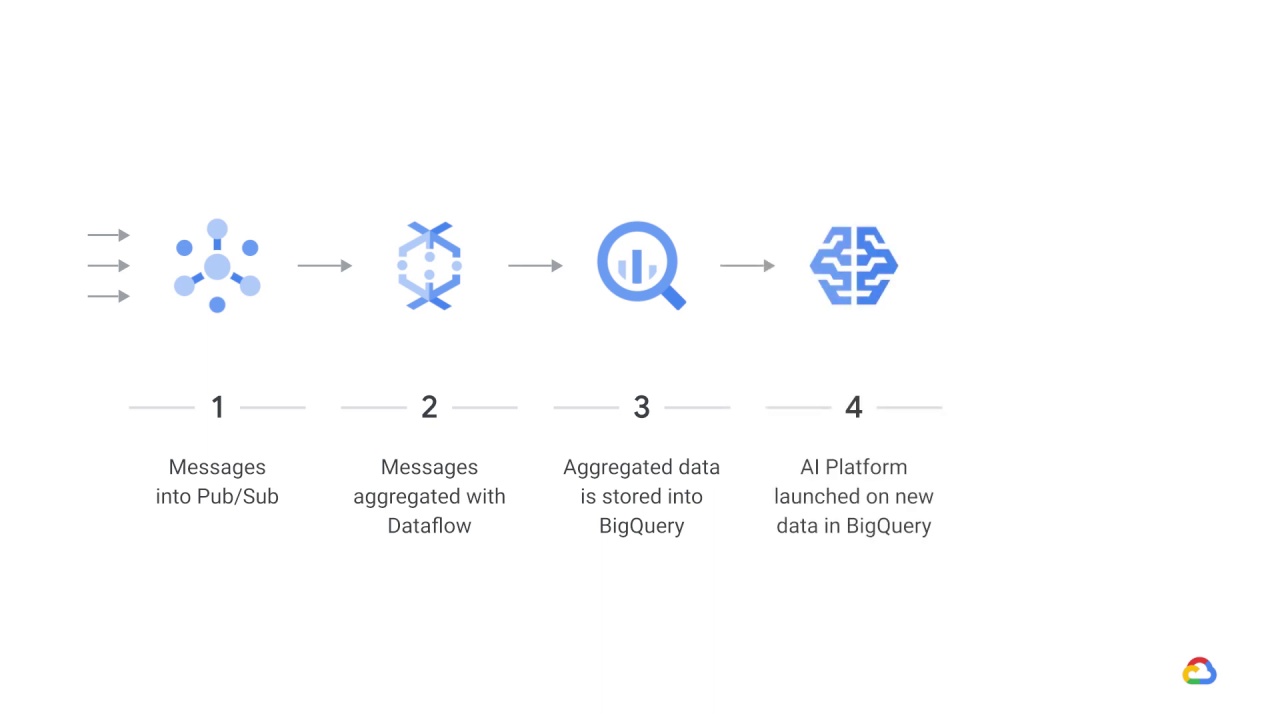
AI Platform is launched on the arrival of new data in BigQuery
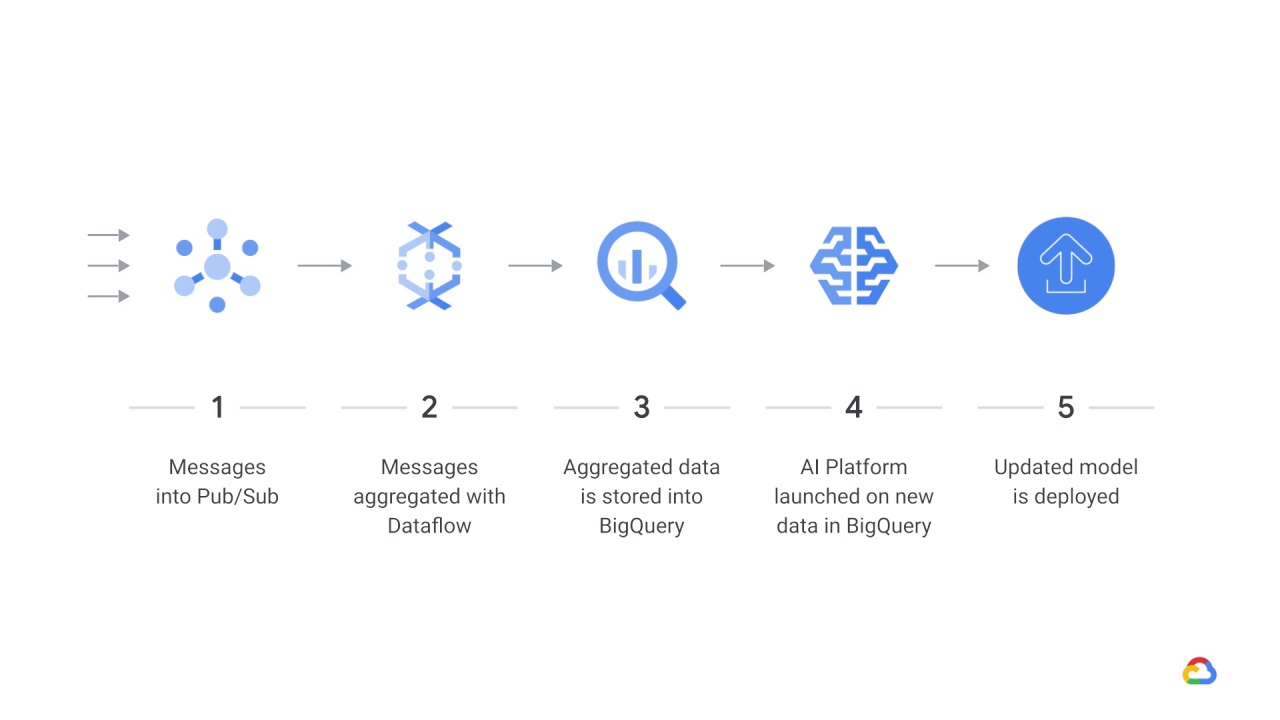
and then an updated model is deployed.