Introduction


Welcome to Designing Adaptable ML systems.

In this module, we’ll explore how to:

Recognize the ways that a model is dependent on data

Make cost-conscious engineering decisions

Know when to roll back a model to an earlier version

Debug the causes of observed model behavior

Implement a pipeline that is immune to one type of dependency

In the 16th century, John Donne famously wrote in one of his poems that no man is an island.

He meant that human beings need to be part of a community to thrive.

In software engineering terms

we would say that few software programs adopt a monolithic island-like design.
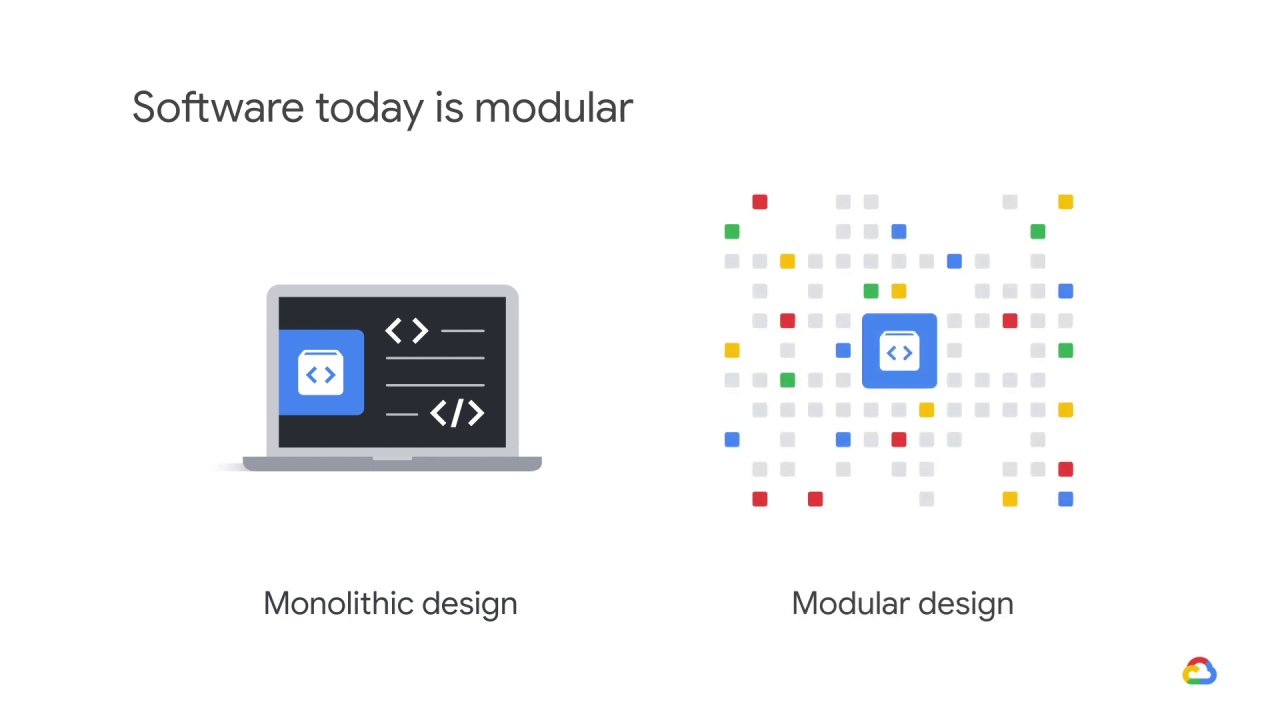
Instead, most software today is modular, and depends on other software

Modular programs are:

more maintainable,

as well as easier to reuse,

test,

and fix because they allow engineers to focus on small pieces of code rather than the entire program.
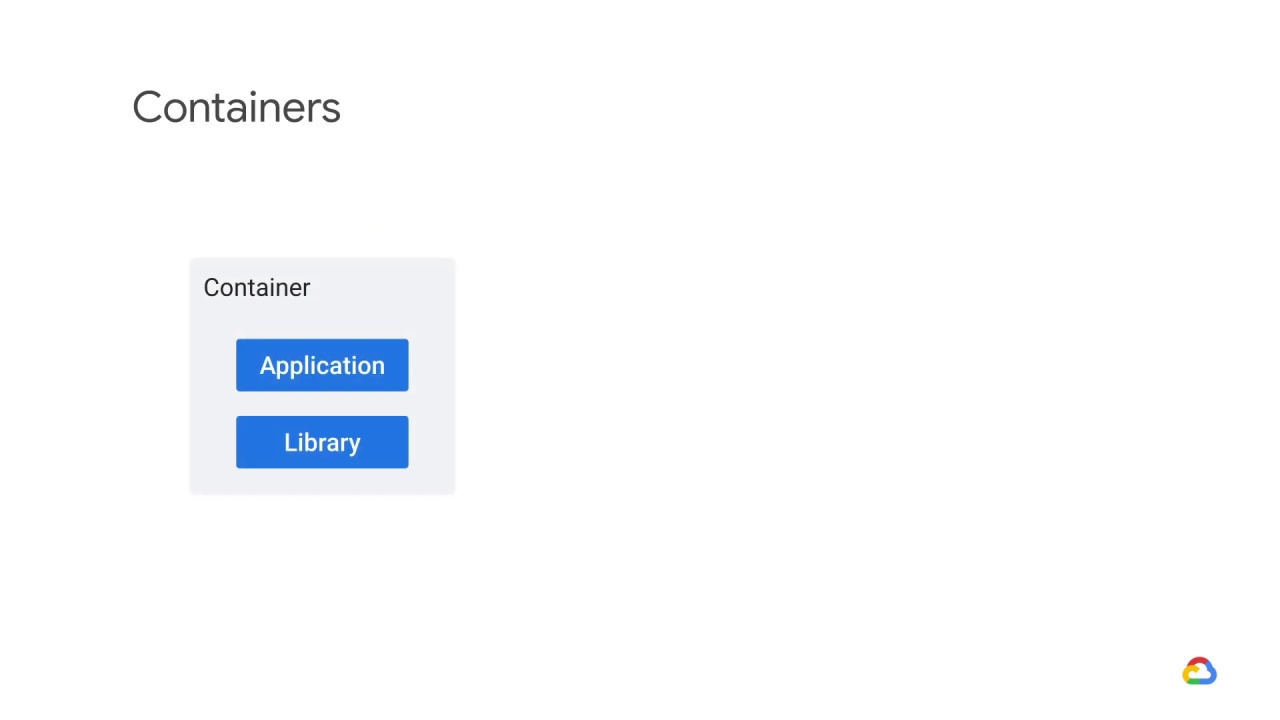
Containers make it easier to manage modular programs.
A container is an abstraction that packages applications and libraries together
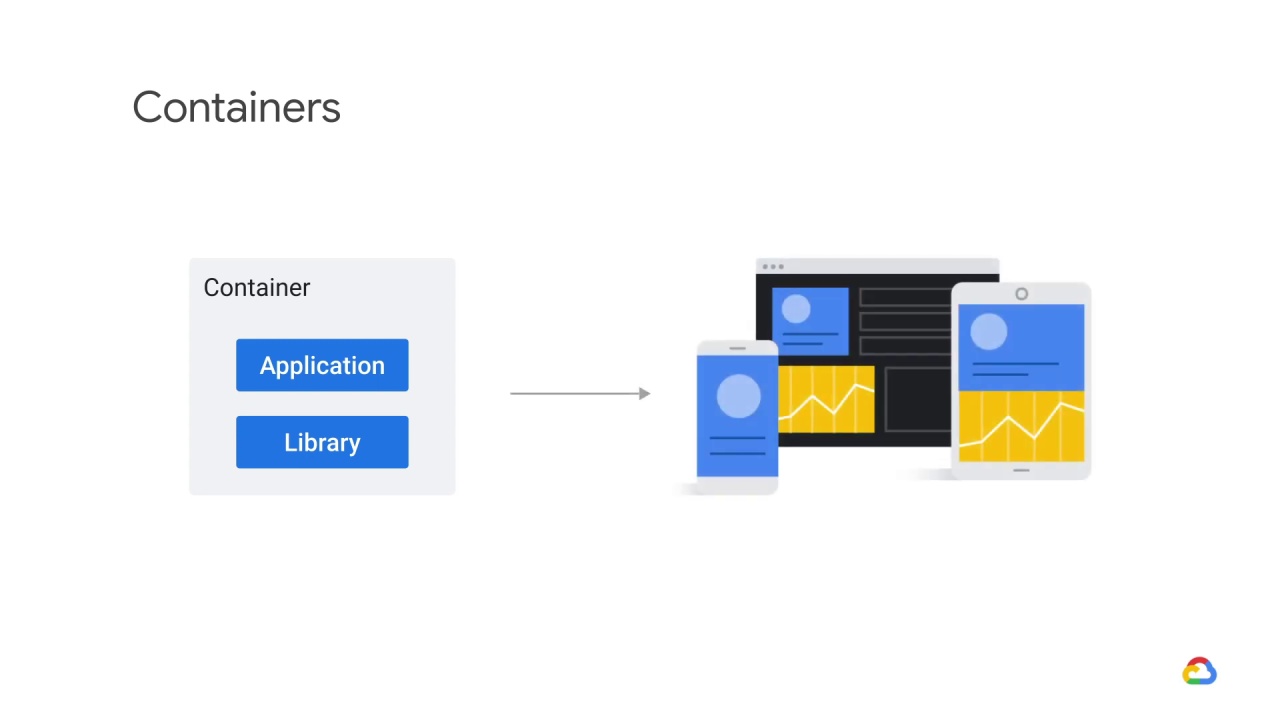
so that the applications can run on a greater variety of hardware and operating systems.
This ultimately makes hosting large applications better.

To learn more about Kubernetes, Google’s open source container orchestration software, check out the getting started with Google Kubernetes engine course.

But what if there was no way to identify a specific version of a library
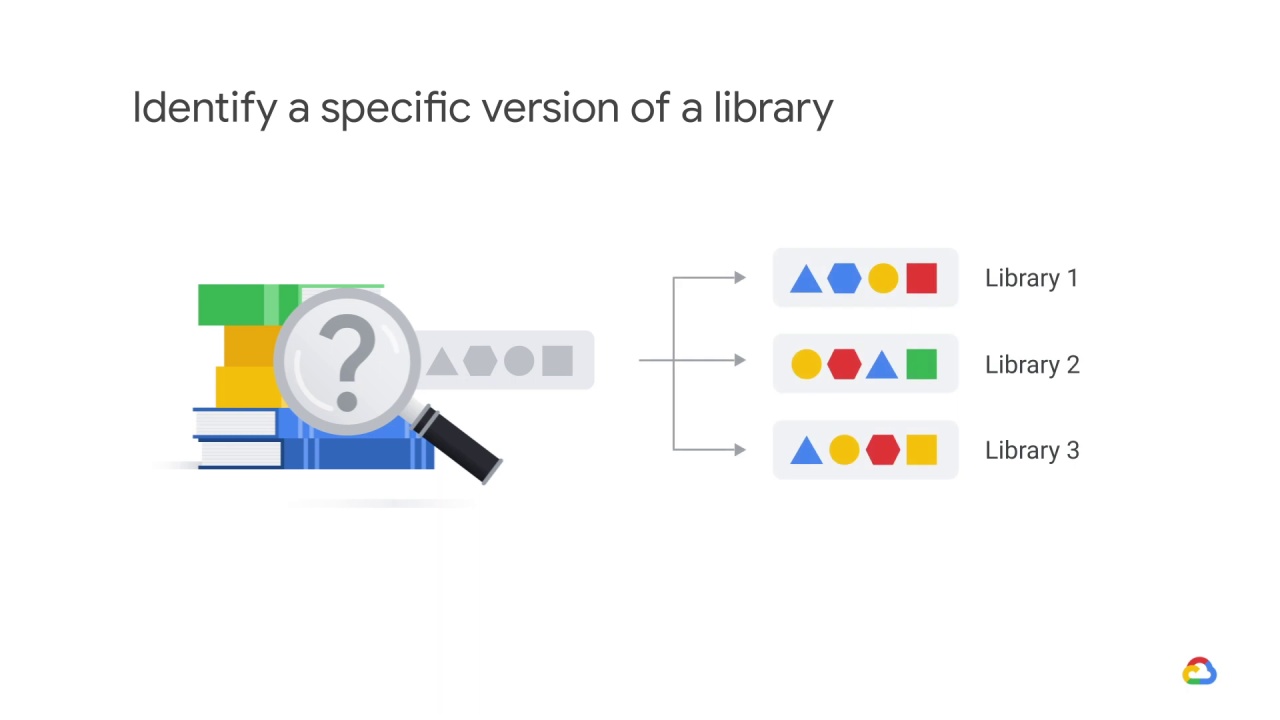
and you had to rely on finding similar libraries at run-time?
Furthermore, what if someone else got to choose which version got run
and they didn’t know or really care about your program?
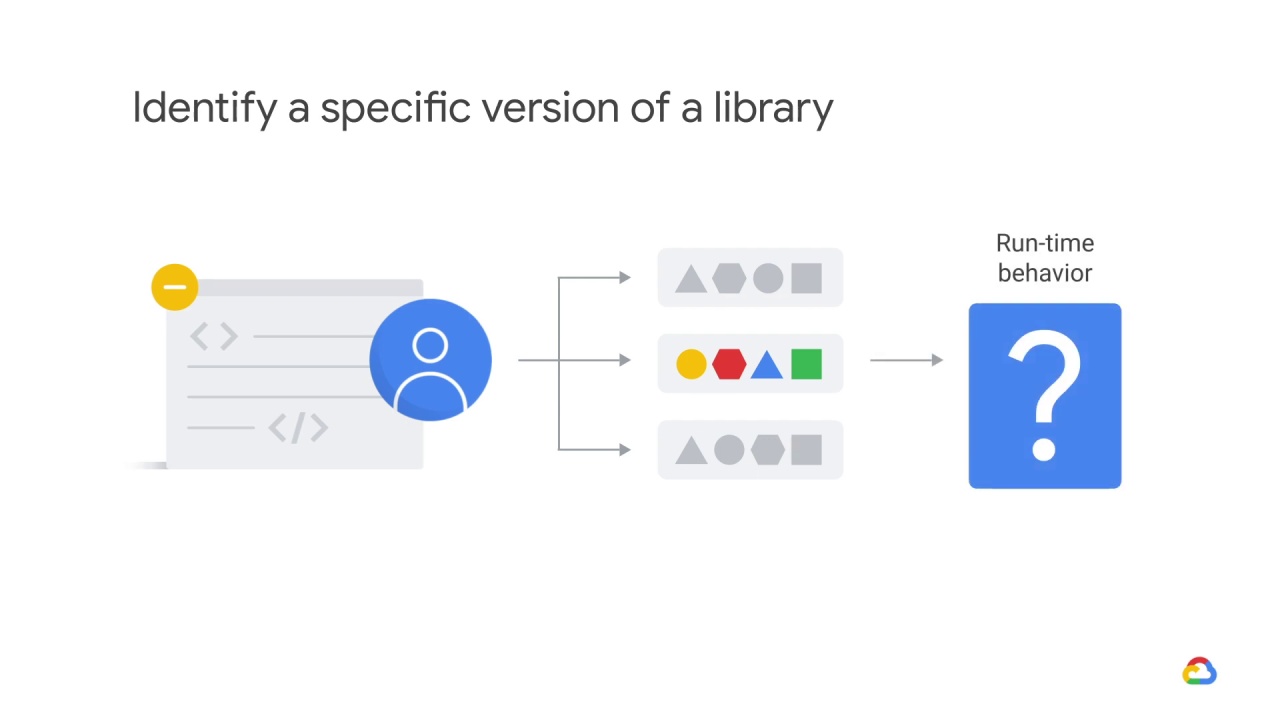
There would be no way of knowing what the run-time behavior would look like.

Unfortunately, this is precisely the case for machine learning,

because the run-time instructions, for example, the model weights,
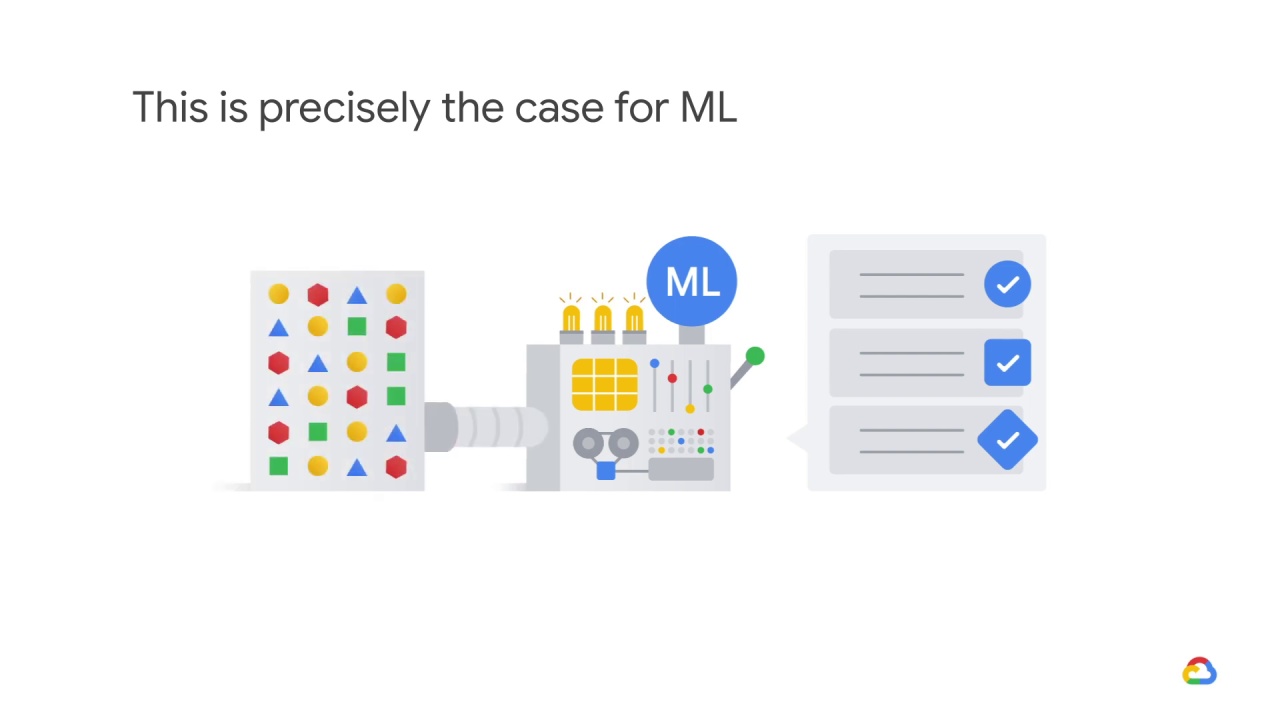
depend on the data that the model was trained on.

Additionally, similar data will yield similar instructions.

And finally other people including other teams and our users create our data.

Just like in traditional software engineering, mismanaged dependencies say,
code that assumes one set of instructions, will be called
when another end up being called instead
can be expensive.

Your models’ accuracy might go down or become unstable.

Sometimes, the errors are subtle and your team may end up spending a large proportion of its time debugging.
