Distributed training architectures


Previously we gave an overview of why distributed training is needed.
Let’s now take a look at distributed training architectures.
Before we get into the details of how to achieve this scaling in TensorFlow, let’s step back and explore the high level concepts and architectures in distributed training.

Let’s say you start training on a machine with a multi-core CPU.
TensorFlow automatically handles scaling on multiple cores.
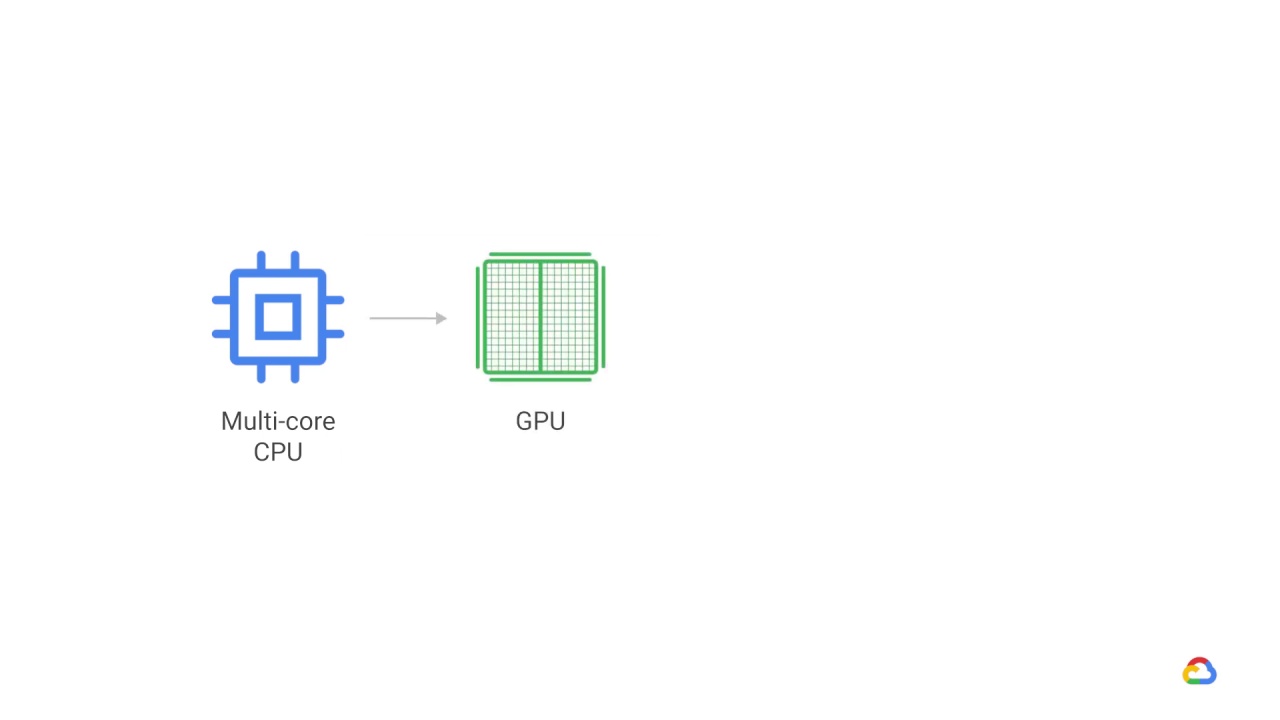
You may speed up your training by adding an accelerator to your machine such as a
GPU.
Again, TensorFlow will use this accelerator to speed up model training with no extra work on your part.
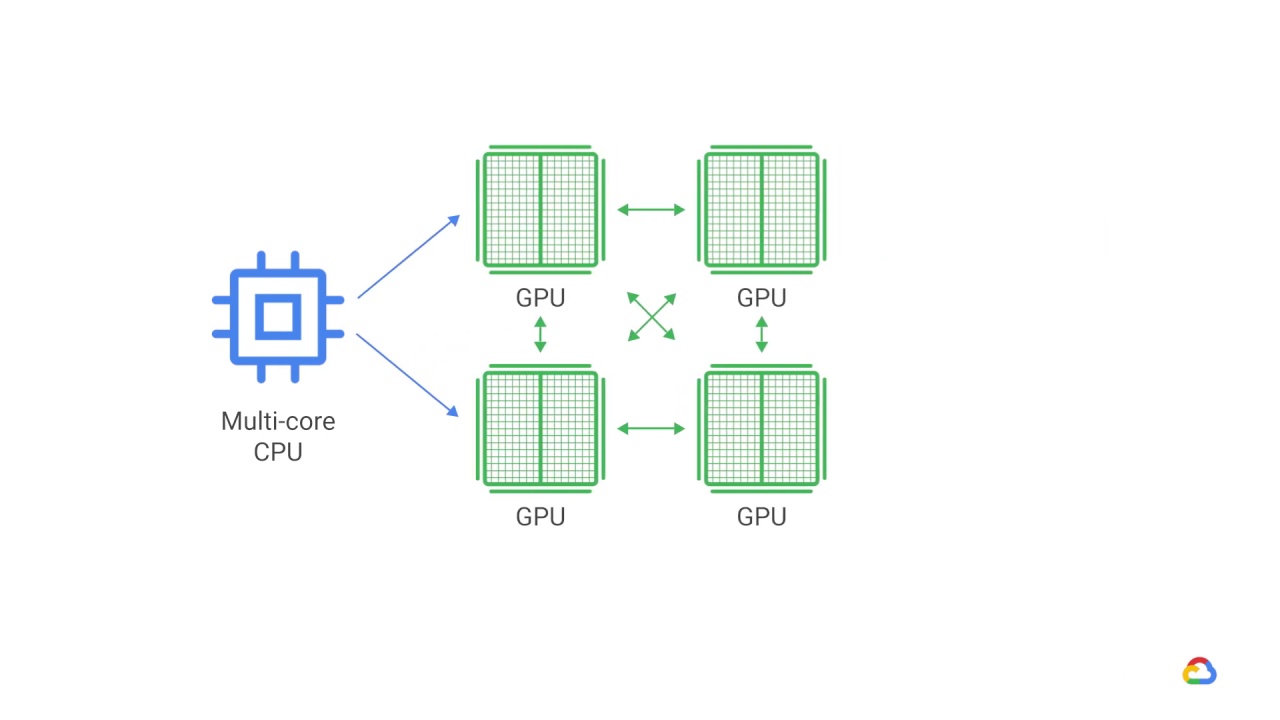
But with distributed training, you can go further.
You can go from using one machine with a single device, to a machine with multiple devices attached to it,
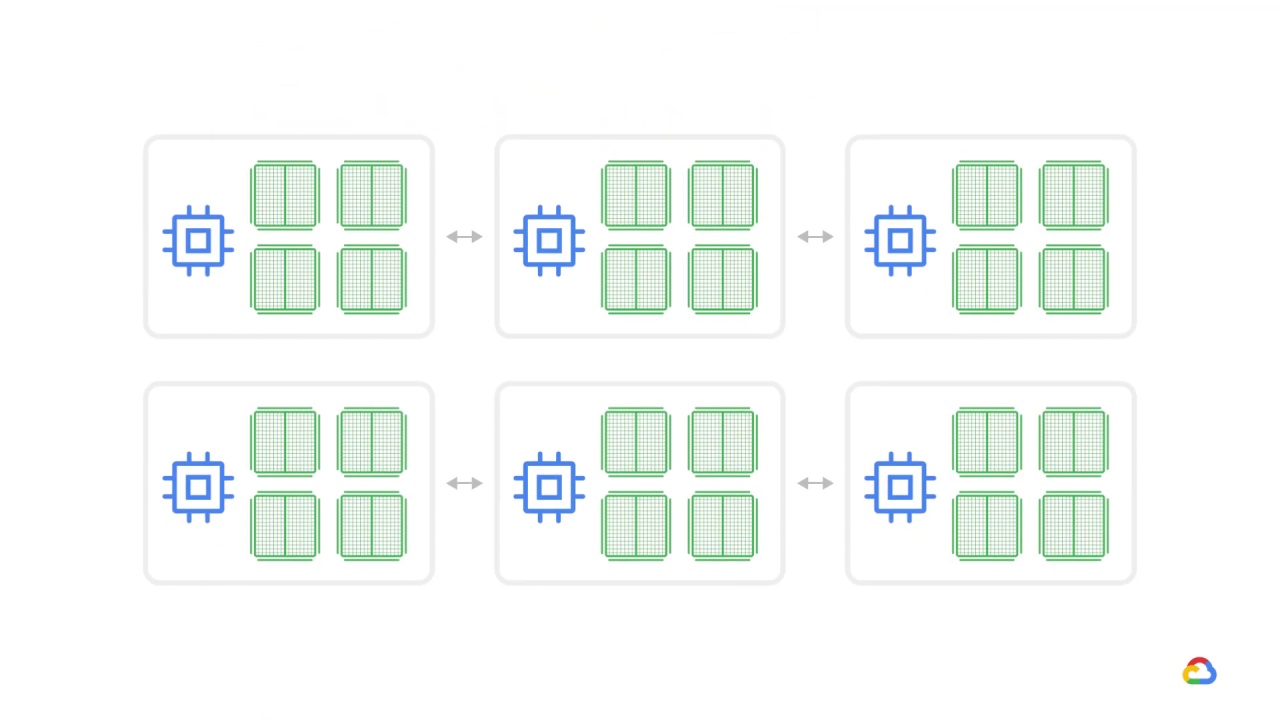
and finally to multiple machines, possibly with multiple devices each, connected over a network.
Eventually, with various approaches, you can scale up to hundreds of devices, and that is in fact what we do in several Google systems.
Simply stated, distributed training distributes training workloads across multiple mini-processors–or worker nodes.
These worker nodes work in parallel to accelerate the training process.

Their parallelism can be achieved via two types of distributed training architecture. Let’s explore both, starting with the most common,
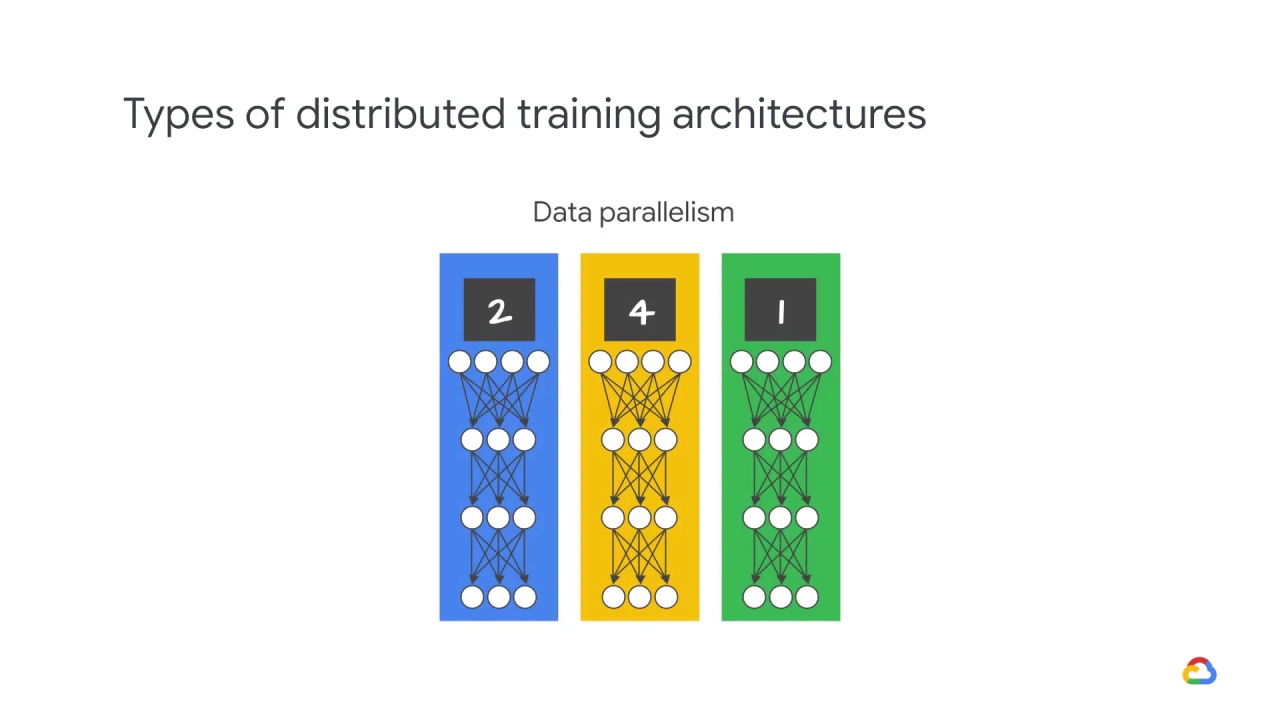
data parallelism.
Data parallelism is model agnostic, making it the most widely used paradigm for parallelizing neural network training.
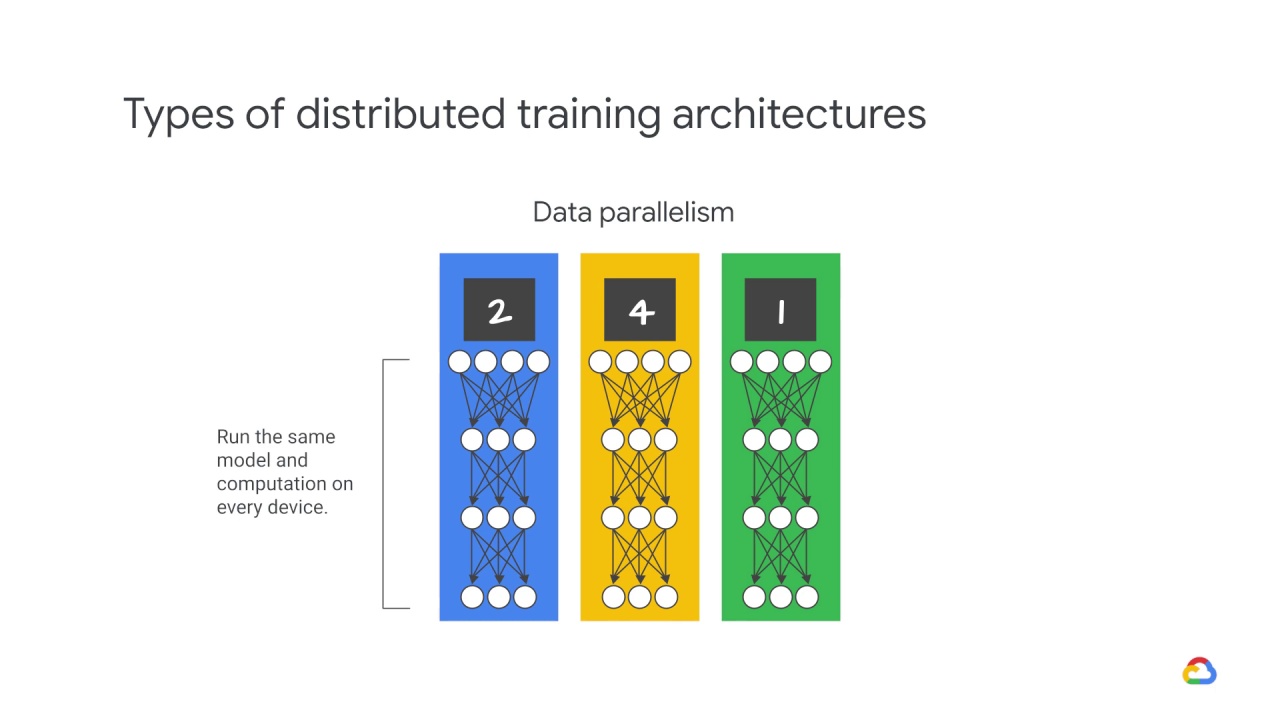
In data parallelism, you run the same model and computation on every device,
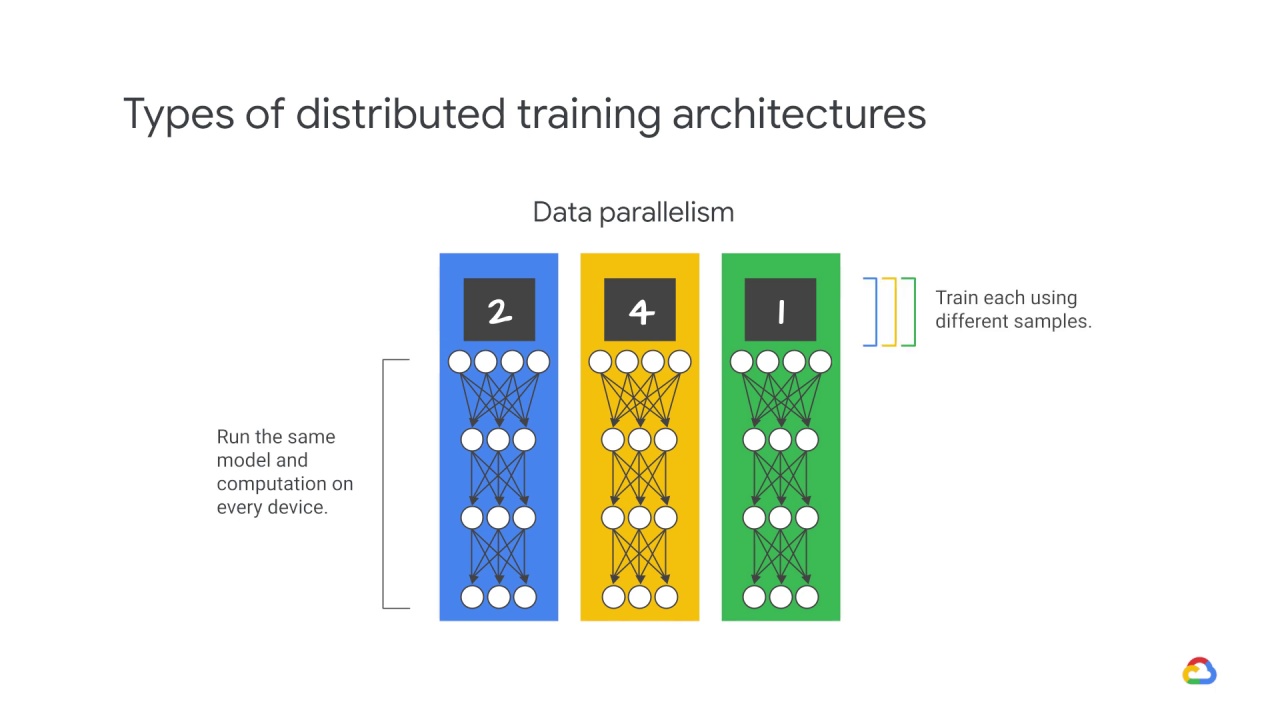
but train each of them using different training samples.
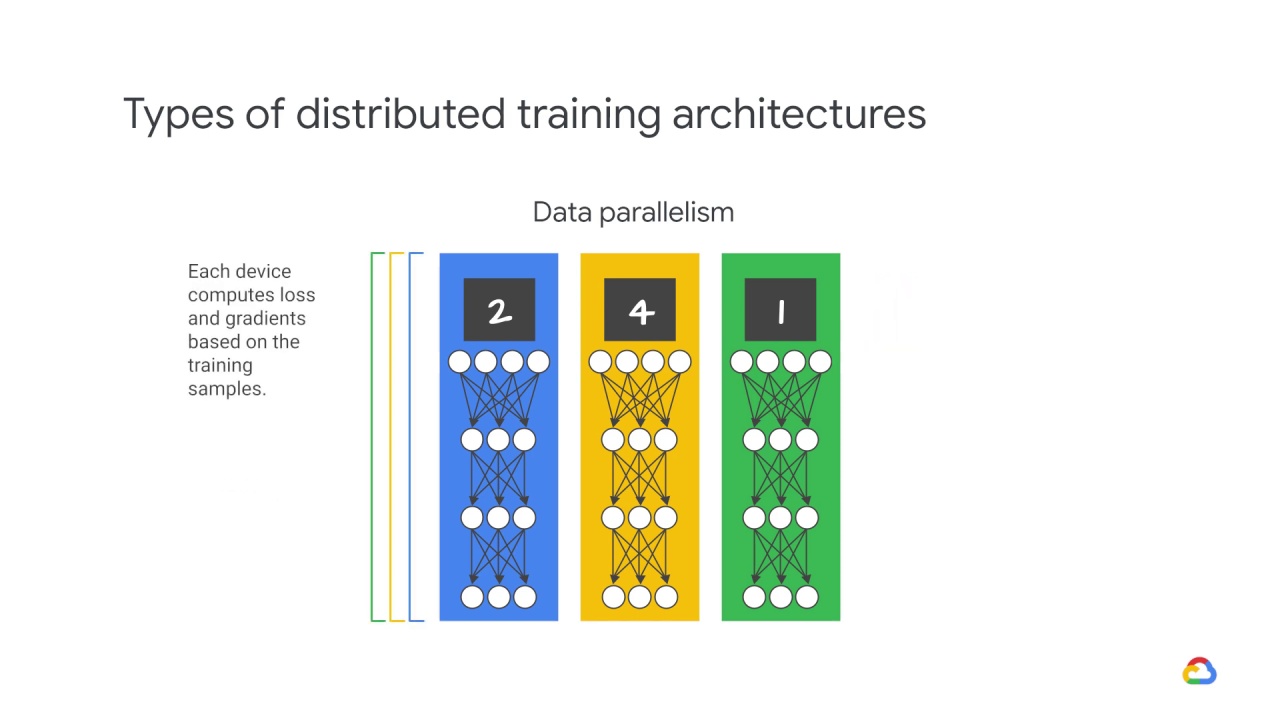
Each device computes loss and gradients based on the training samples it sees.
Then we update the model’s parameters using these gradients.
The updated model is then used in the next round of computation.
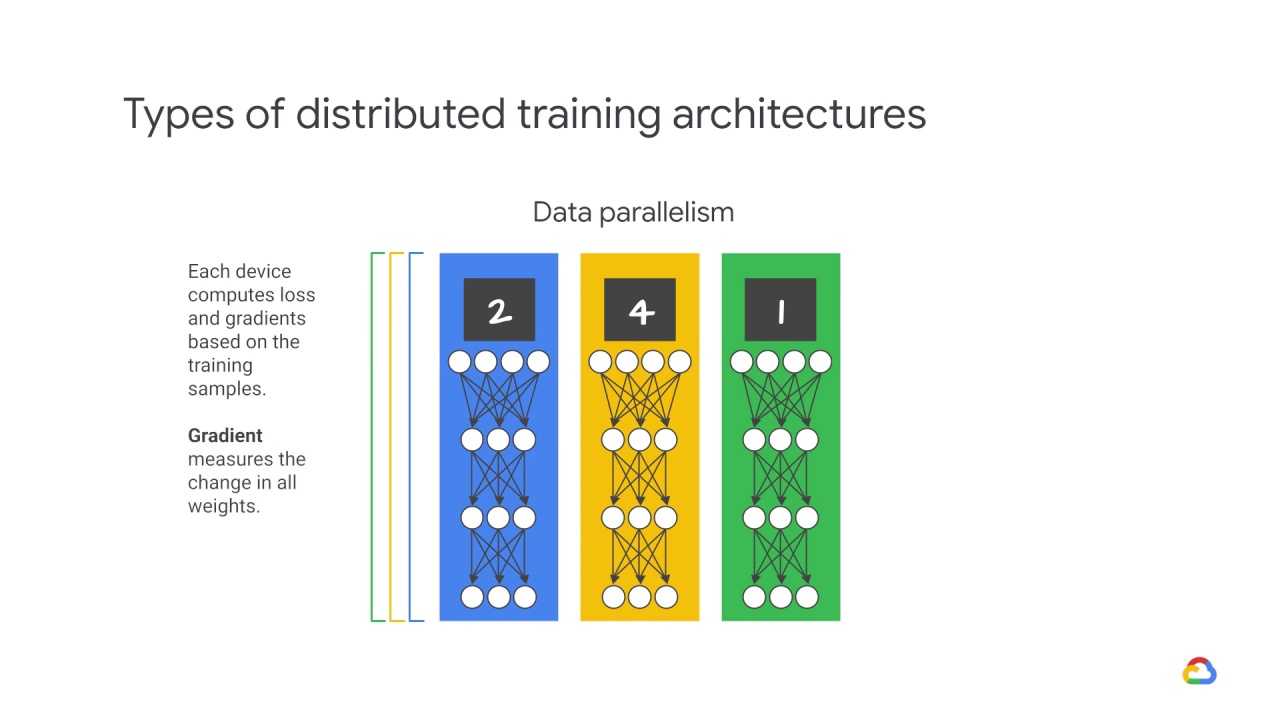
You’ll recall that a gradient simply measures the change in all weights with regard to the change in error.
You can also think of a gradient as the slope of a function.
The higher the gradient, the steeper the slope and the faster a model can learn.
But if the slope is zero, the model stops learning.
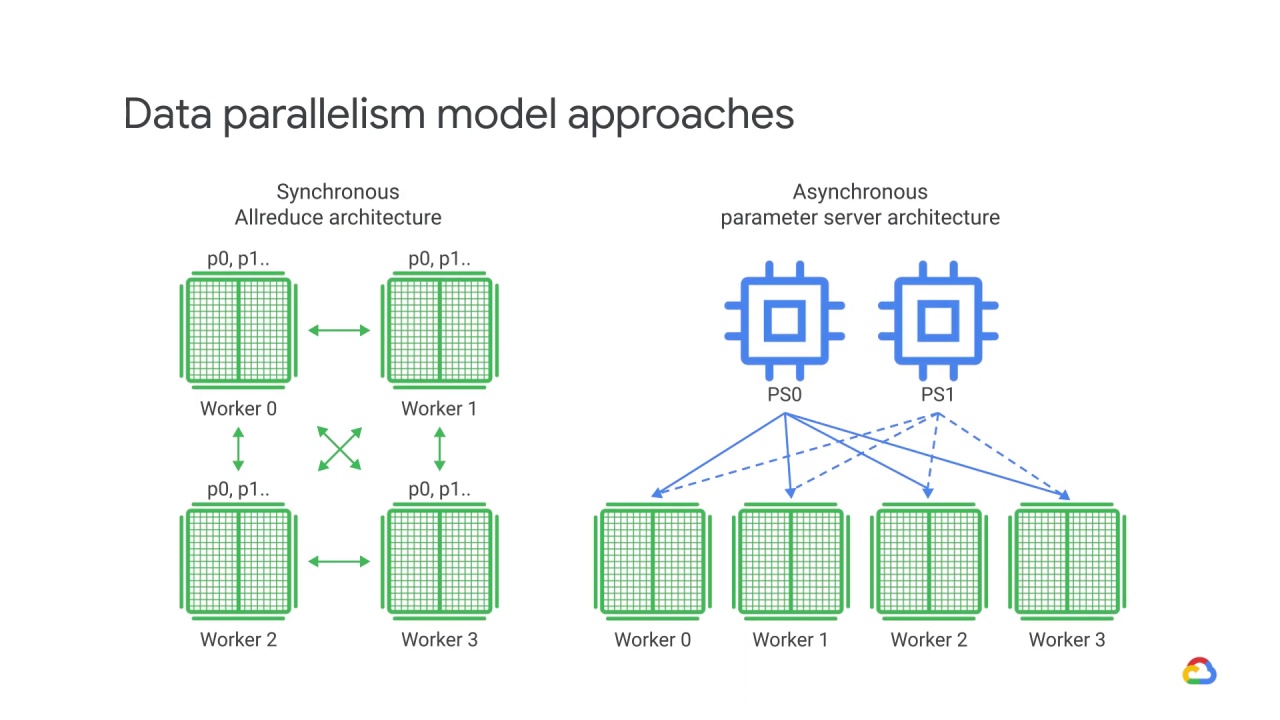
There are currently two approaches used to update the model using gradients from various devices: Synchronous and asynchronous.
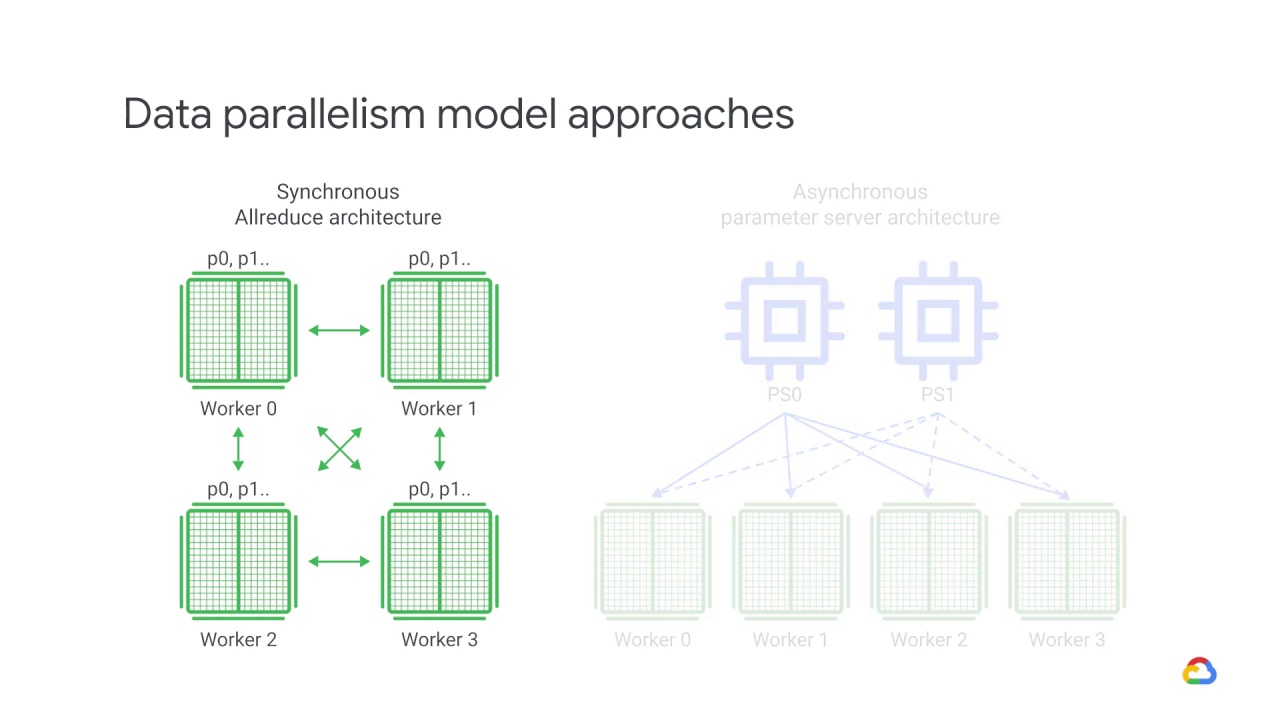
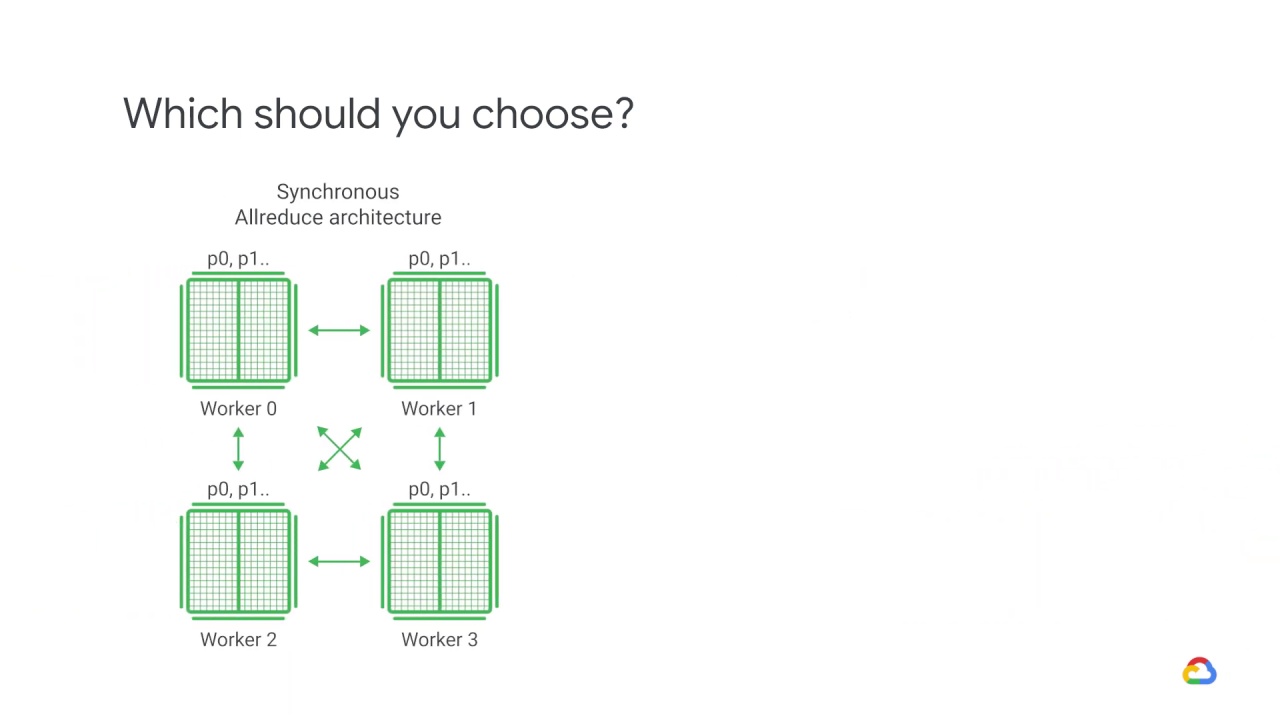
In synchronous training, all of the devices train their local model using different parts of data from a single, large mini-batch.
They then communicate their locally calculated gradients, directly or indirectly, to all devices.
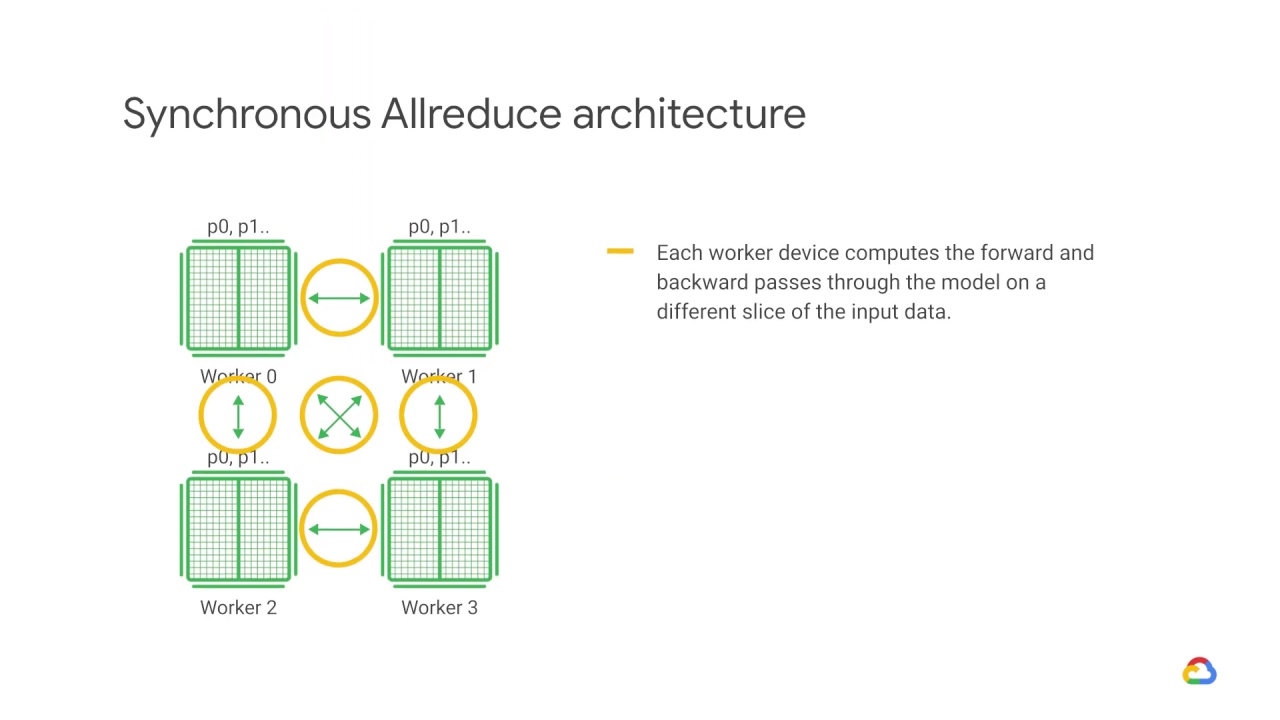
In this approach, each worker device computes the forward and backward passes through the model on a different slice of the input data.
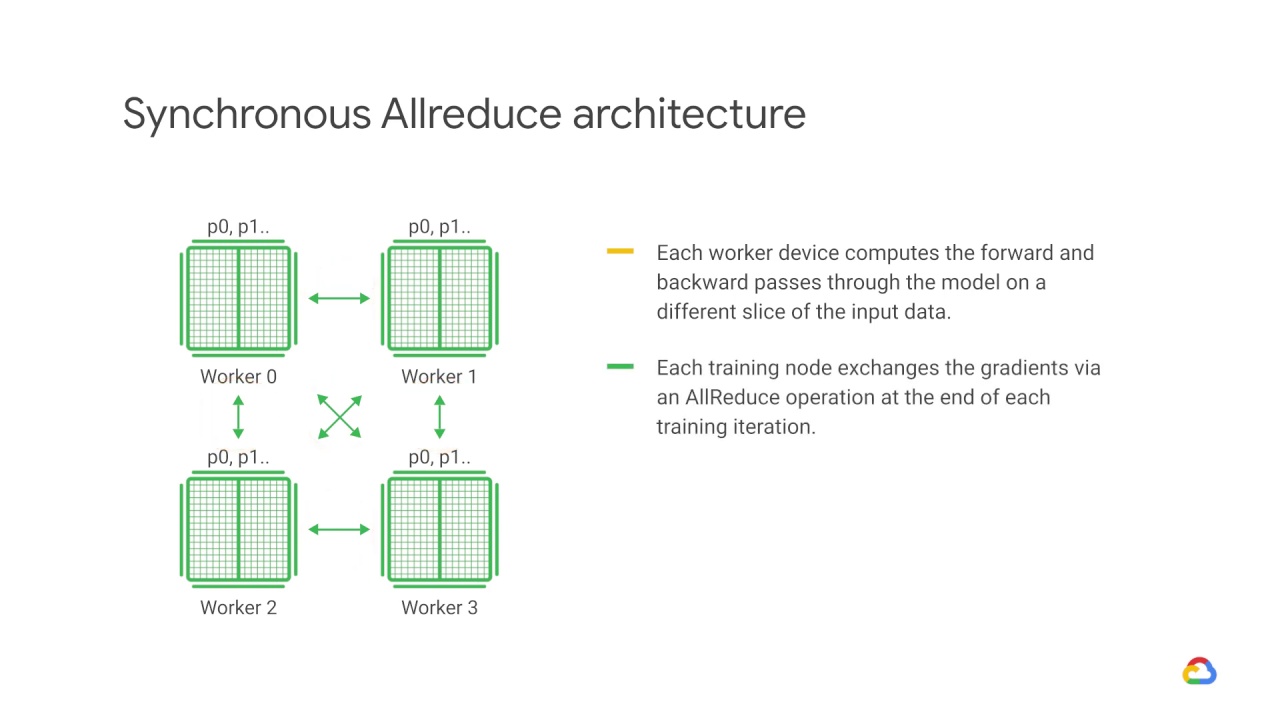
The computed gradients from each of these slices are then aggregated across all of the devices and reduced, usually using an average, in a process known as AllReduce.
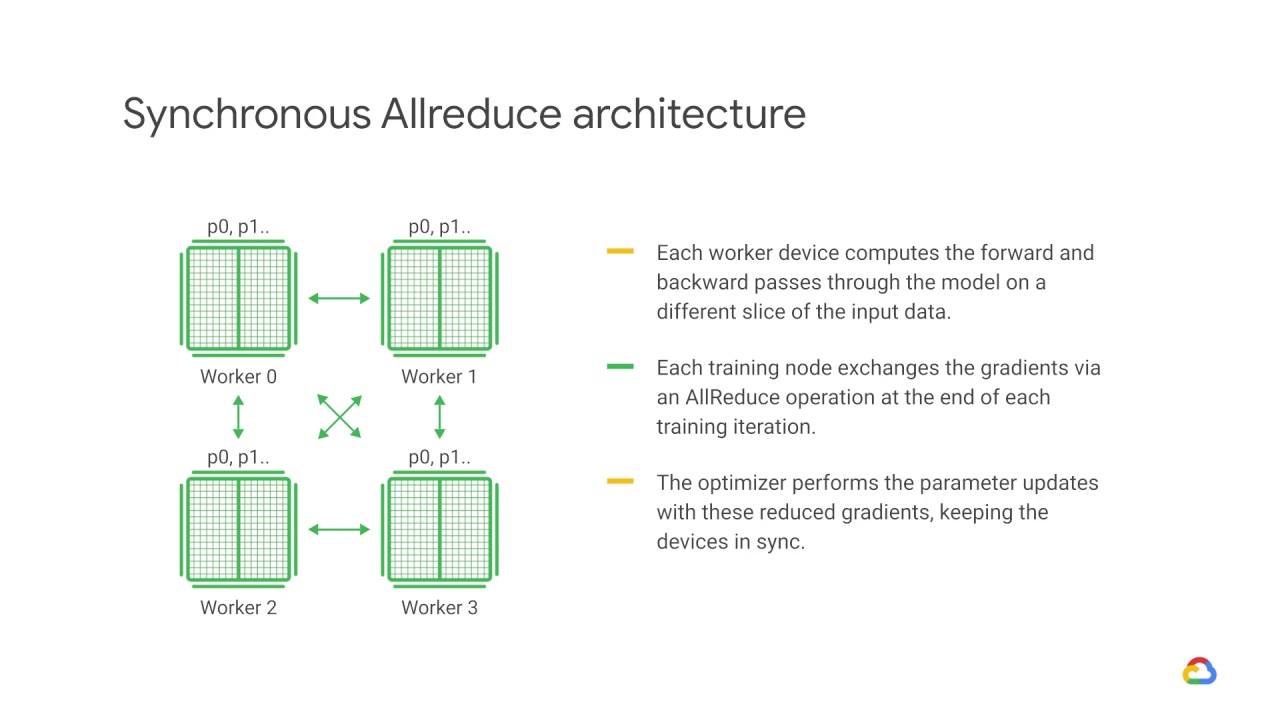
The optimizer then performs the parameter updates with these reduced gradients thereby keeping the devices in sync.
Because each worker cannot proceed to the next training step until all the other workers have finished the current step, this gradient calculation becomes the main overhead in distributed training for synchronous strategies.
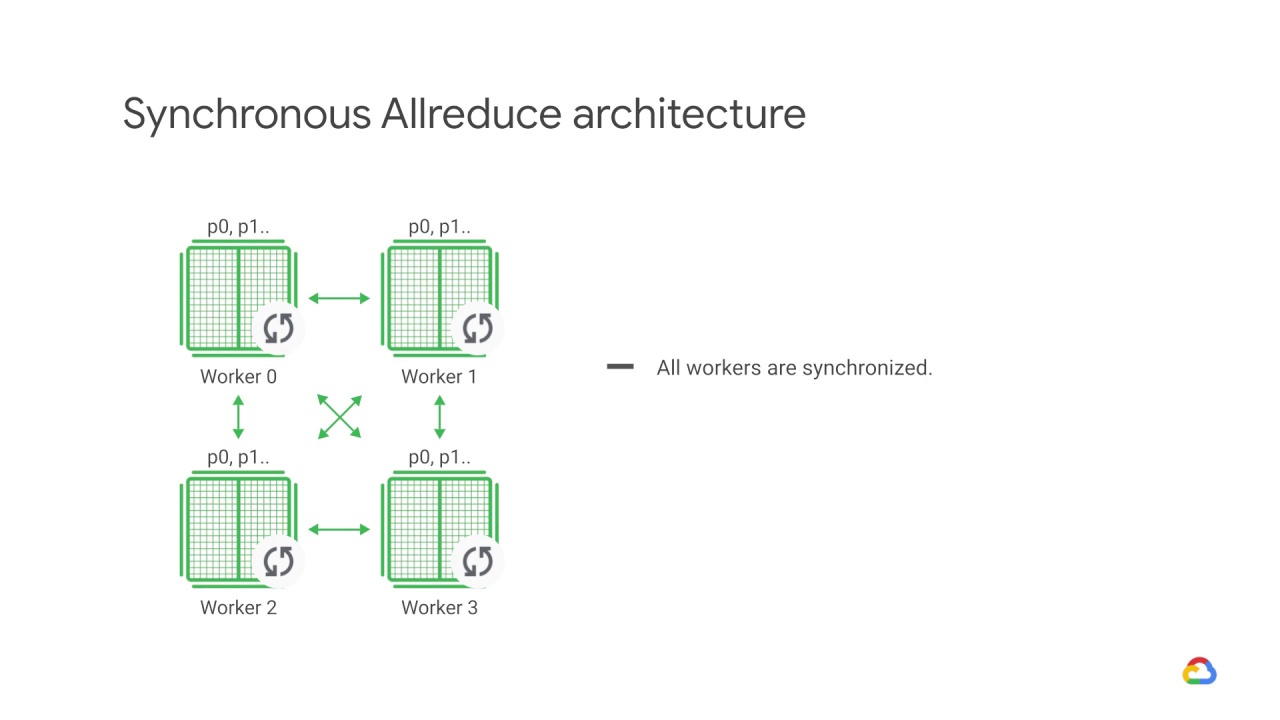
Only after all devices have successfully computed and sent their gradients so that all workers are synchronized, is the model updated.
The updated model is then sent to all nodes along with splits from the next mini-batch.
That is, devices train on non-overlapping splits of the mini-batch.
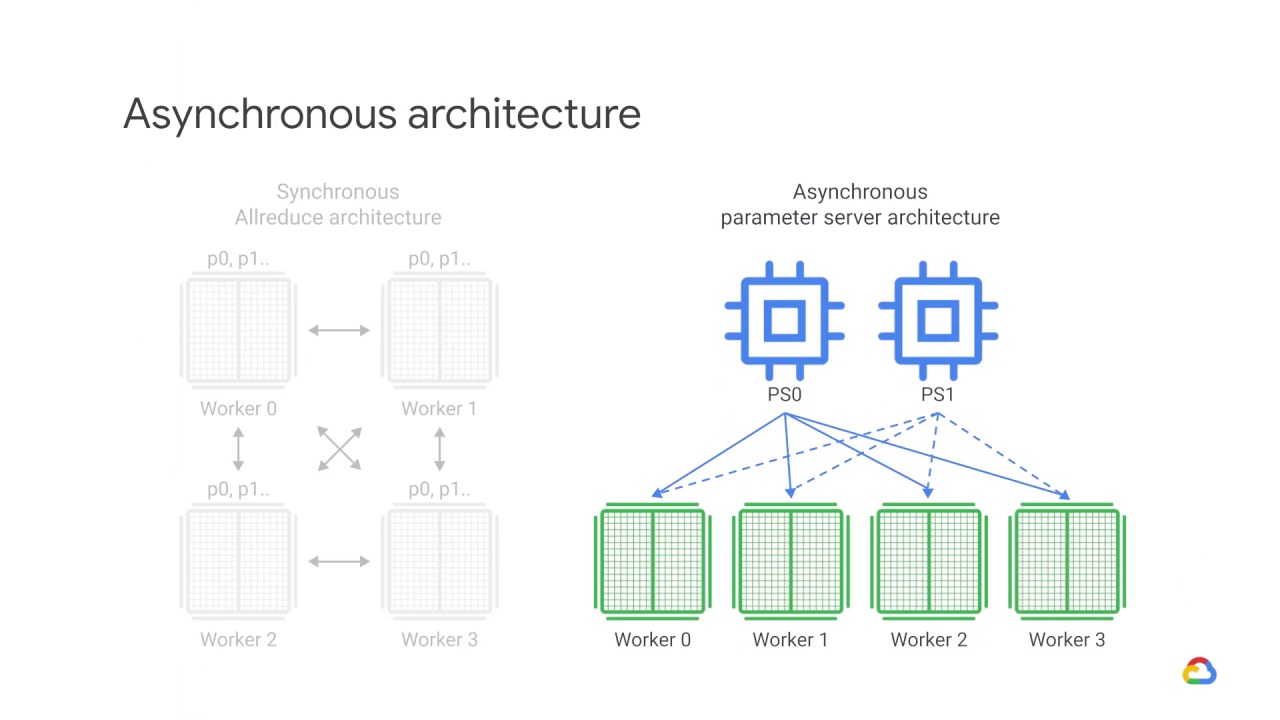
In asynchronous training, no device waits for updates to the model from any other device.
The devices can run independently and share results as peers, or communicate through one or more central servers known as “parameter” servers.
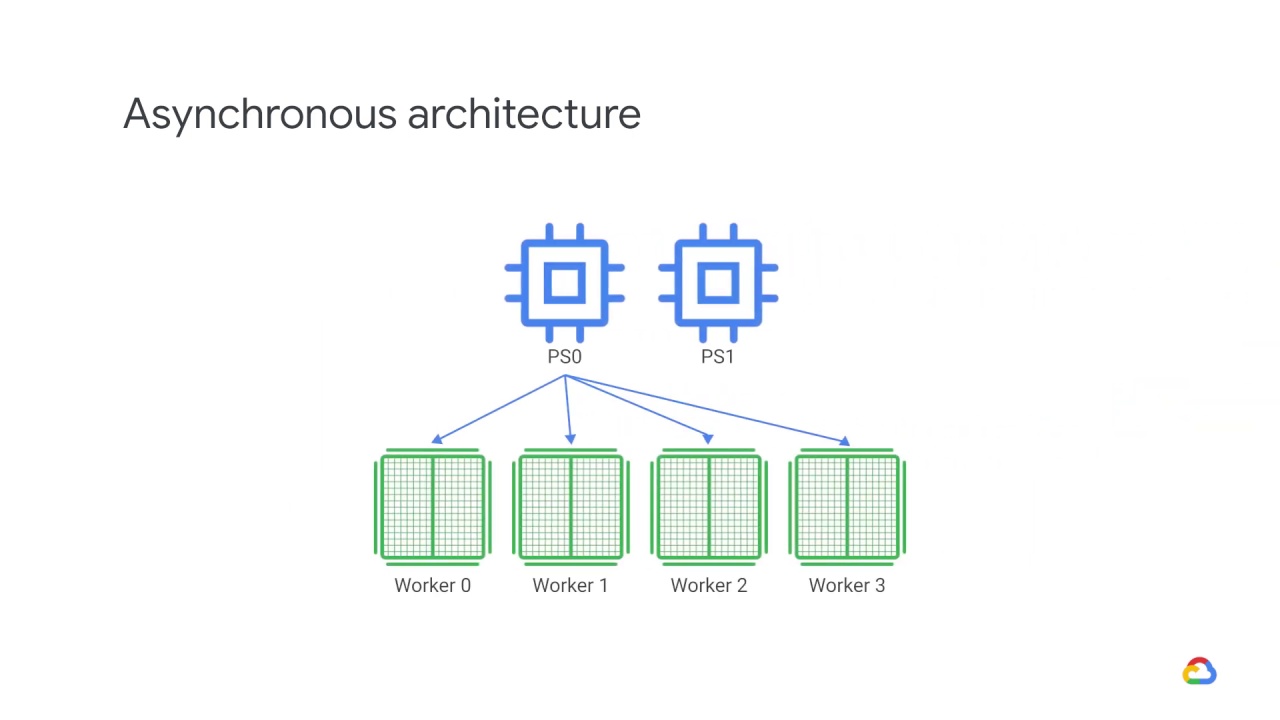
Thus, In an asynchronous parameter server architecture, some devices are designated to be parameter servers, and others as workers.
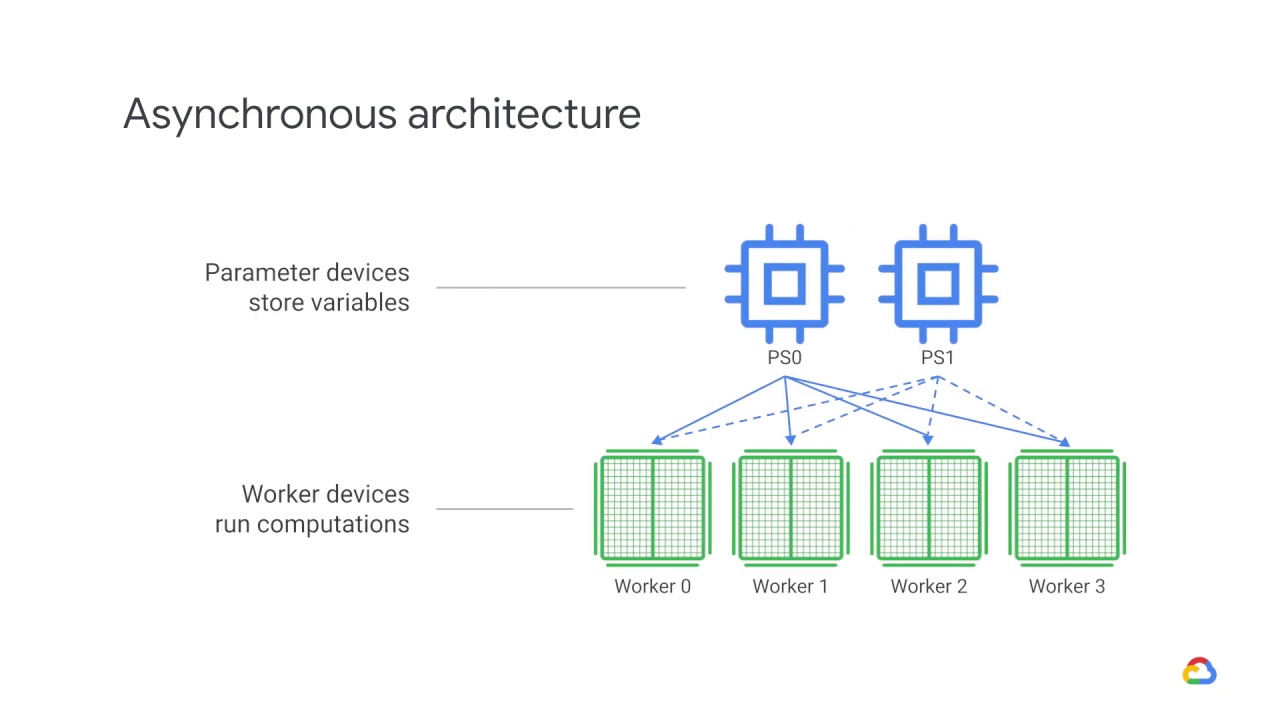
Devices used to store variables are parameter devices, while devices used to run computations are called worker devices.
Each worker independently fetches
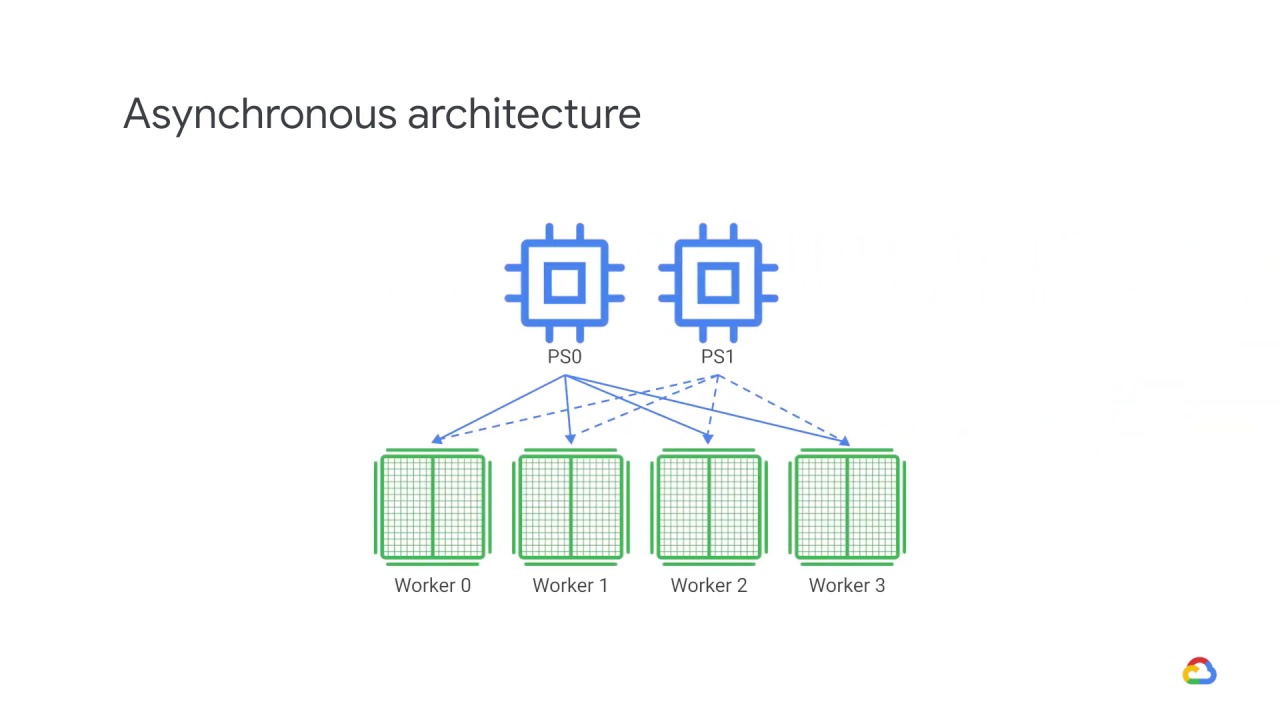
the latest parameters from the parameter servers and computes gradients based on a subset training samples.
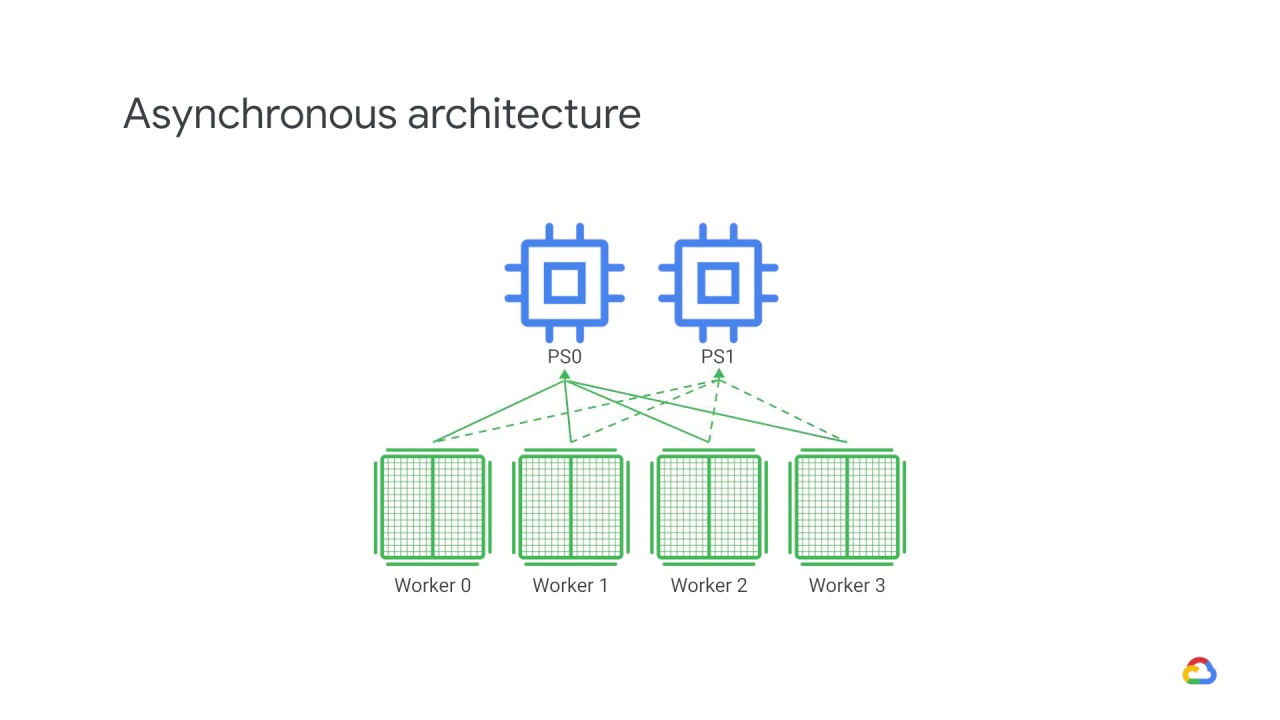
It then sends the gradients back to the PS.
Which then updates its copy of the parameters with those gradients.
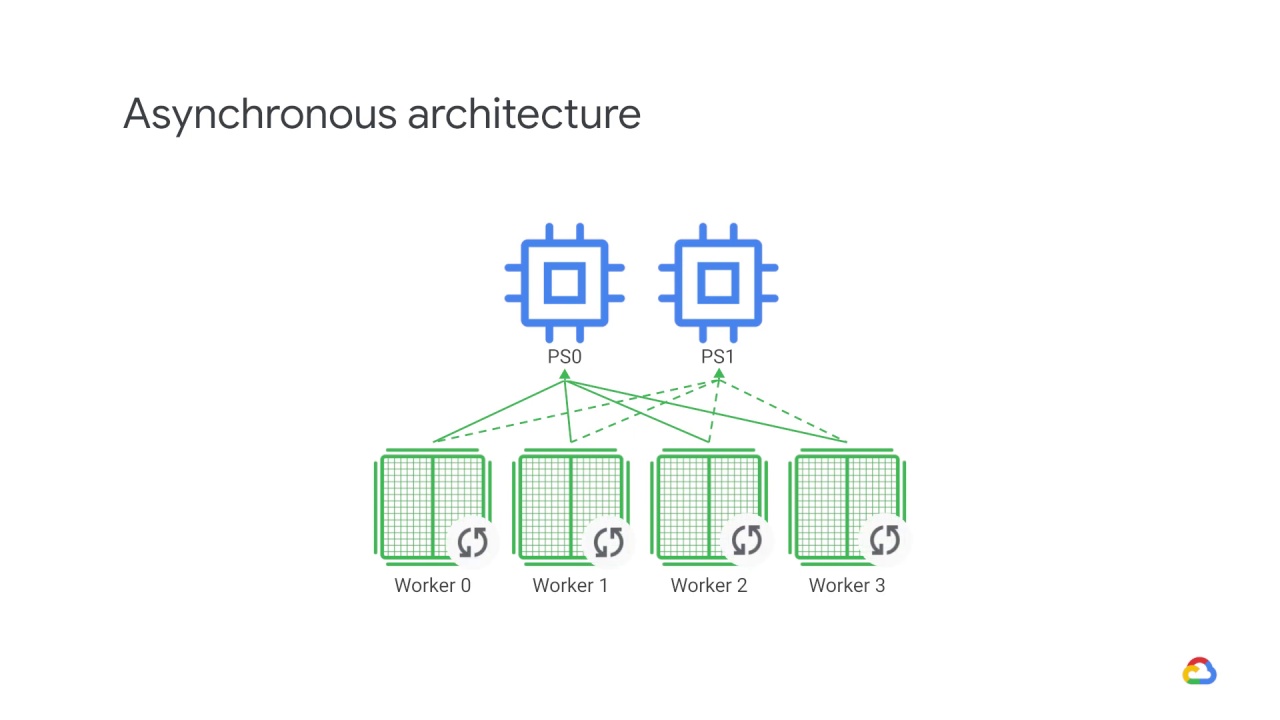
Each worker does this independently.
This allows it to scale well to a large number of workers, where training workers might be preempted by higher priority production jobs, or a machine may go down for maintenance, or where there is asymmetry between the workers.
This does not hurt the scaling because workers are not waiting for each other.
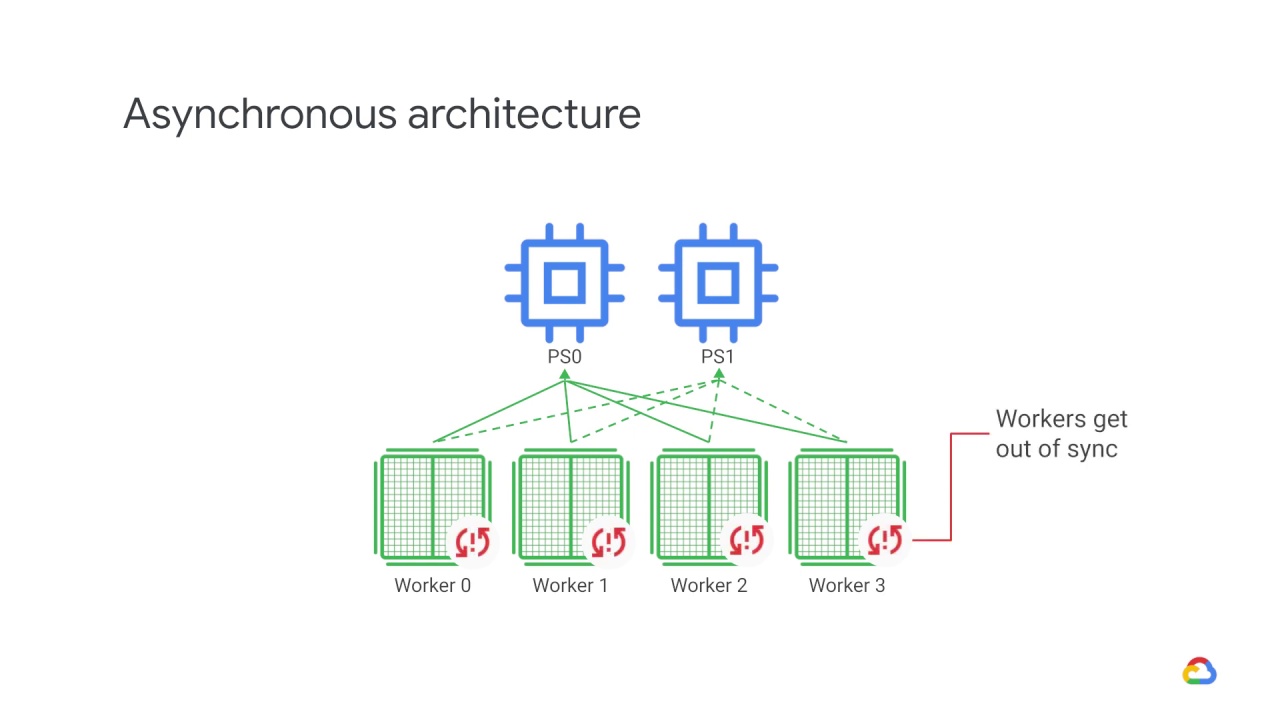
The downside of this approach, however, is that workers can get out of sync.
They compute parameter updates based on stale values and this can delay convergence.
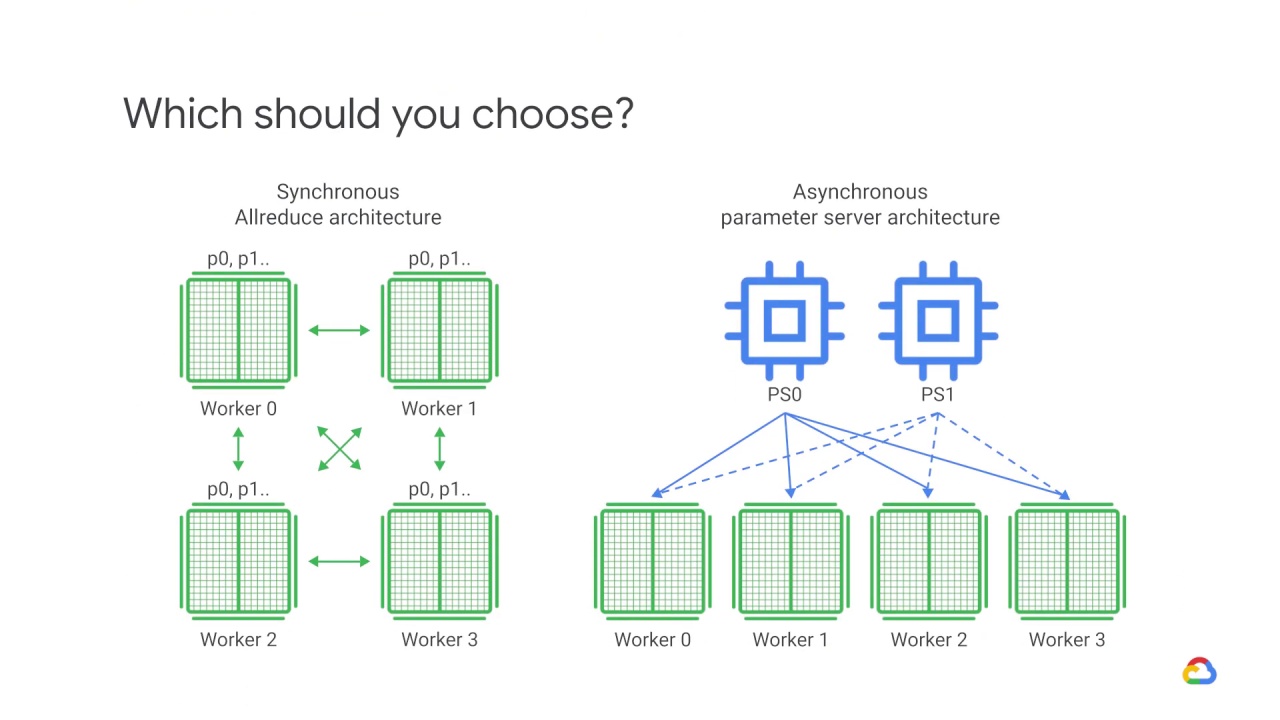
Given these two broad strategies, the asynchronous parameter server approach and the synchronous allreduce approach, which should you choose?
Well, there isn’t one right answer, but here are some considerations.
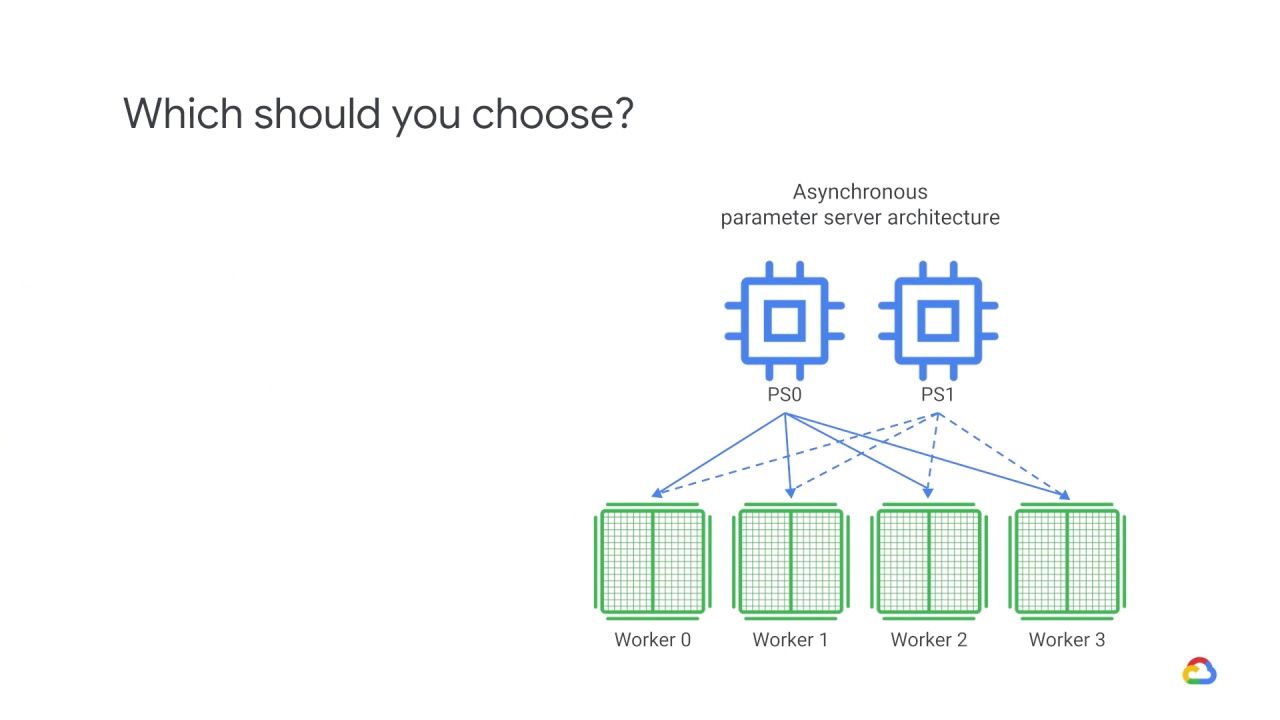
The Asynchronous parameter server approach should be used for models that use sparse data (which contain fewer features, consume less memory, and can run just a cluster of CPUs).
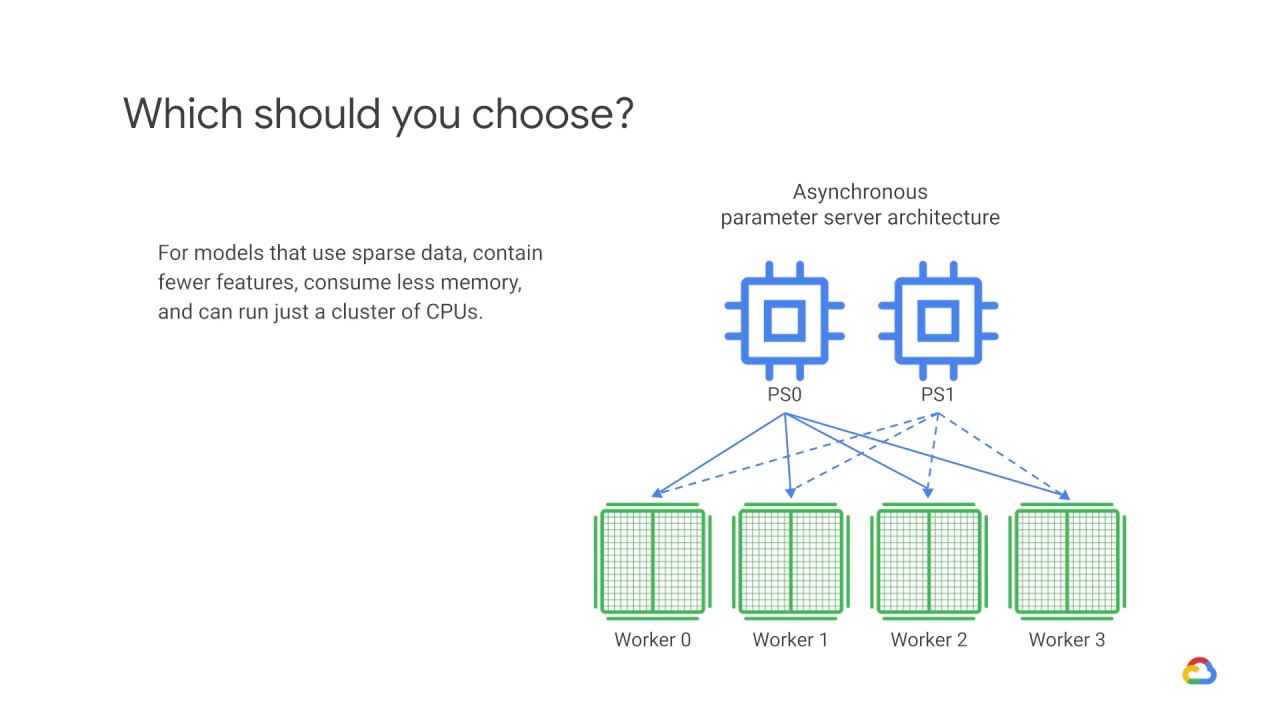
is great for sparse models, as it shards the model across parameter servers, and workers only need to fetch the part they need for each step.
For dense models, the parameter server transfers the whole model each step, and this can create a lot of network pressure.
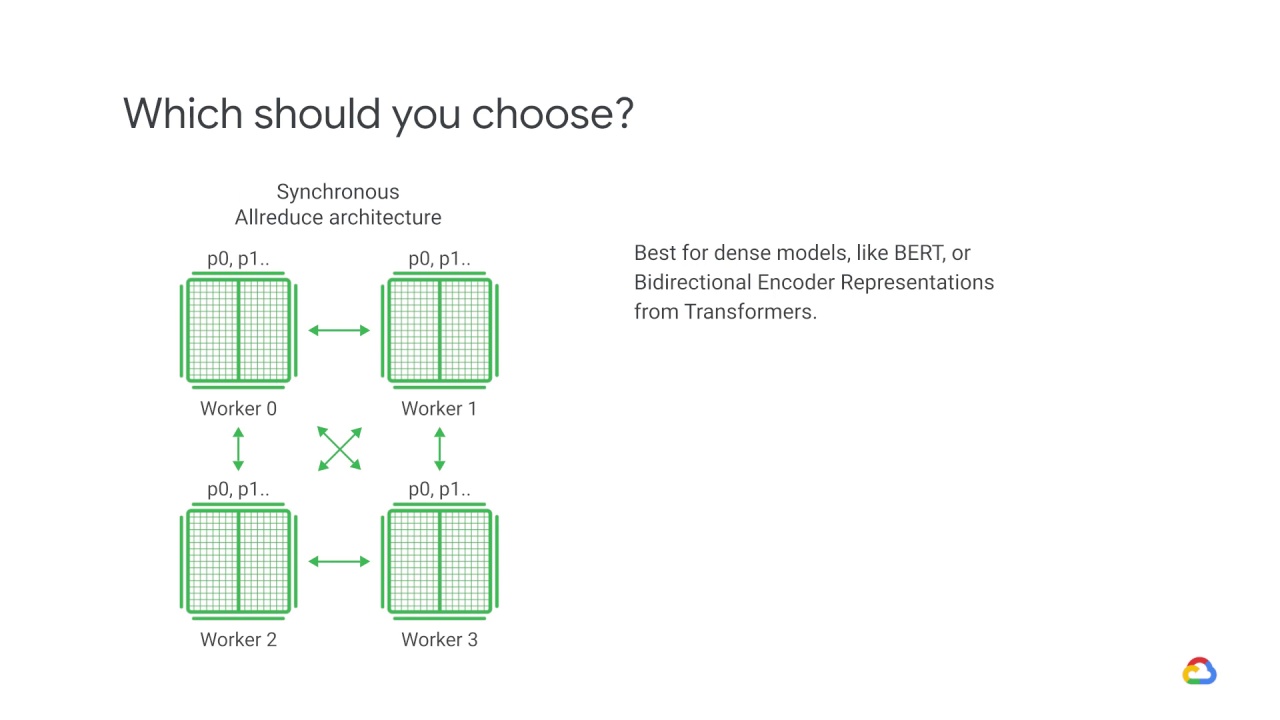
The Sync AllReduce approach should be considered for dense models which contain many features and thus consume more memory.
In this approach, all machines share the load of storing and maintaining the global parameters.
This makes it the best option for dense models, like BERT (or
Bidirectional Encoder Representations from Transformers).
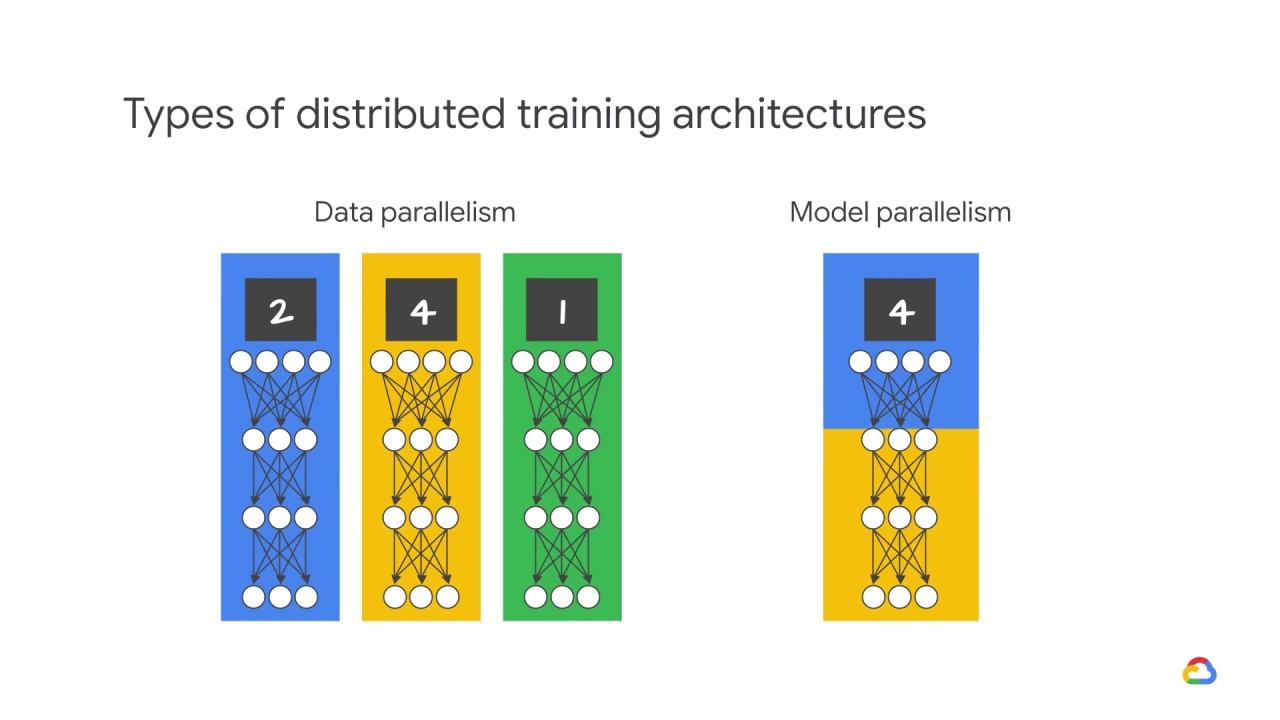
When a model is too big to fit on one device’s memory, you divide it into smaller parts on multiple devices and then compute over the same training samples
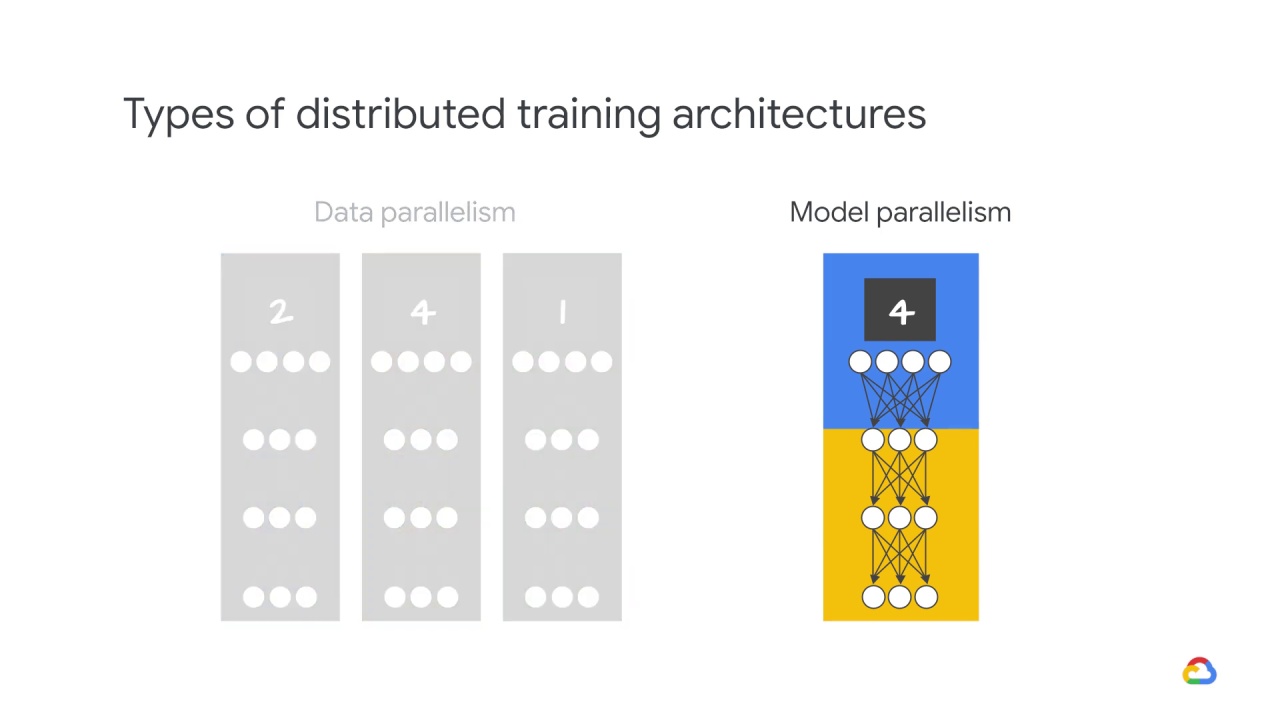
This is called model parallelism.
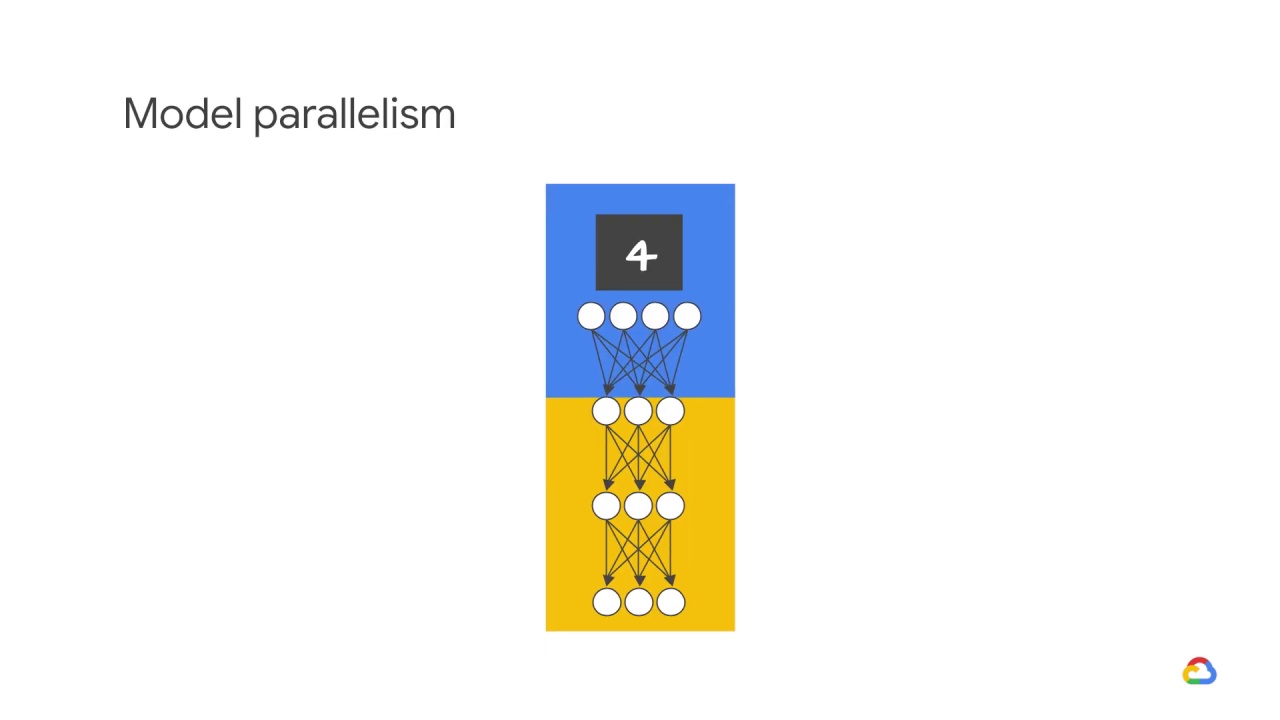
Model parallelism feeds or gives every processor the same data, but applies a different model to it.
Think of model parallelism as simply multiple program, same data.
Model parallelism splits the weights of the net equally among the threads.
And all threads work on a single mini-batch.
Here, the generated output after each layer needs to be synchronized, i.e. stacked, to provide the input to the next layer.
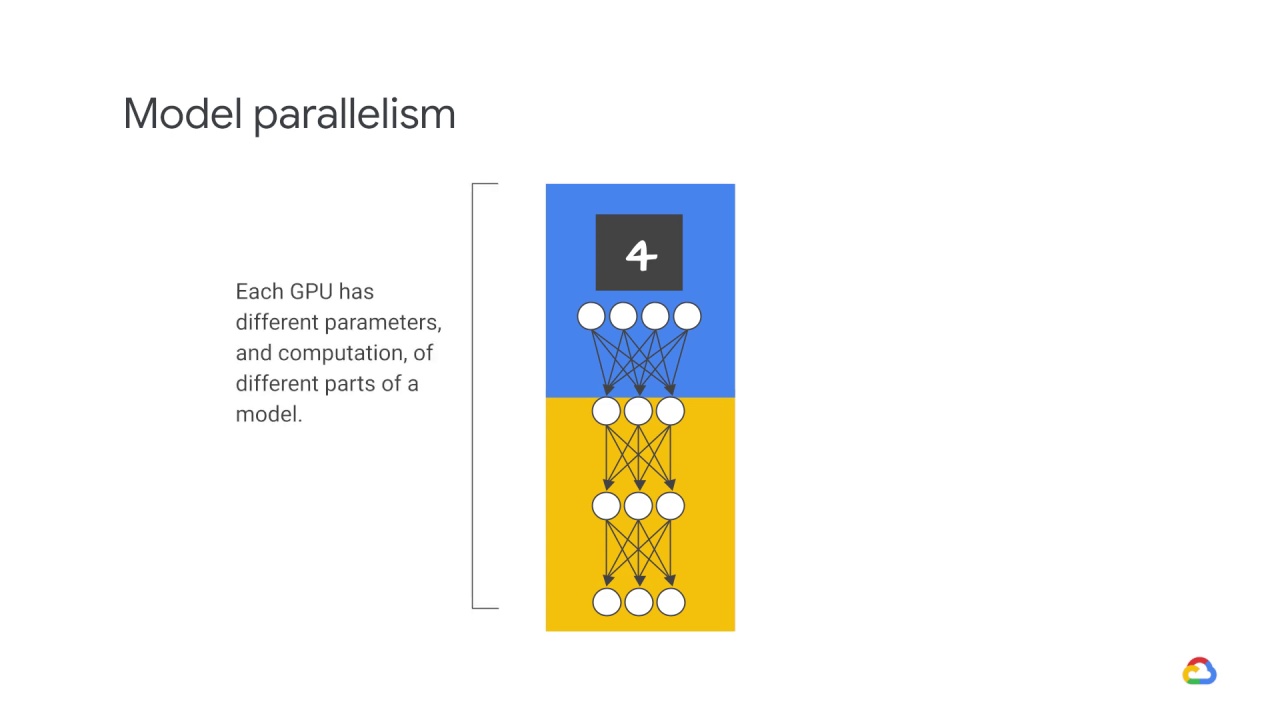
In this approach, each GPU has different parameters, and computation, of different parts of a model.
In other words, multiple GPUs do not need to synchronize the values of the parameters.
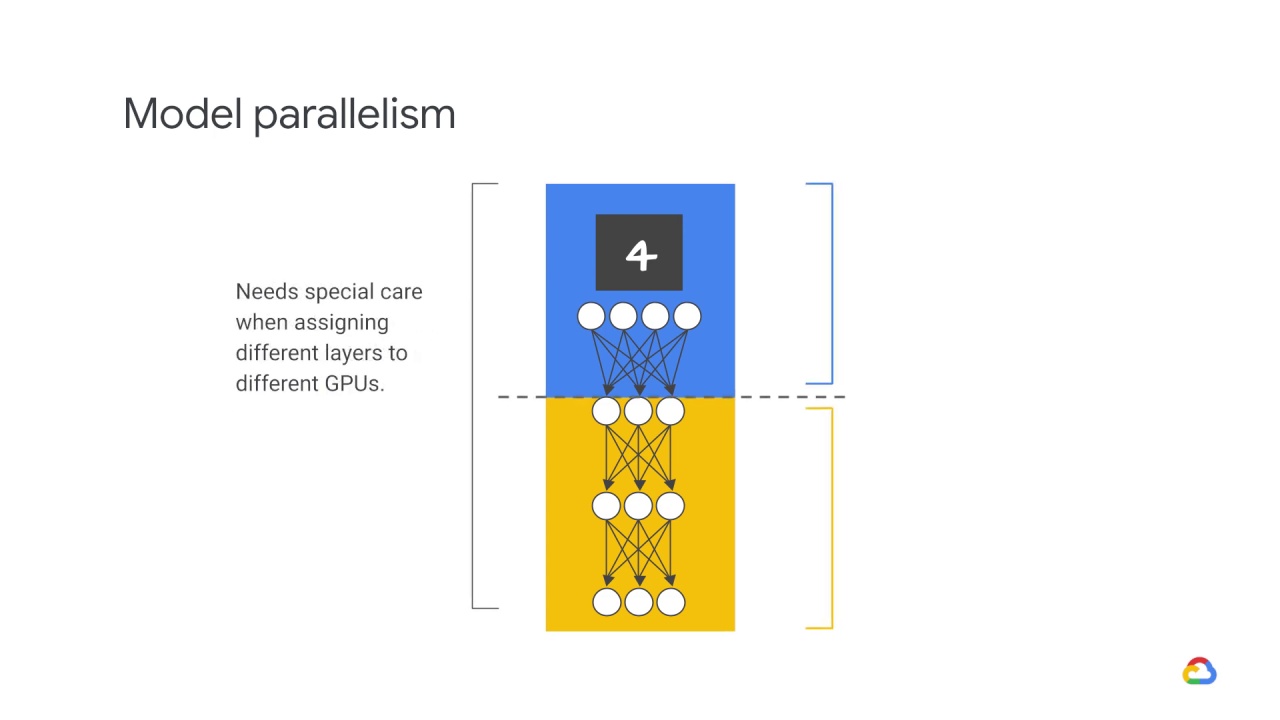
Model parallelism needs special care when assigning different layers to different GPUs, which is more complicated than data parallelism.
The gradients obtained from each model on each GPU are accumulated after a backward process, and the parameters are synchronized and updated.
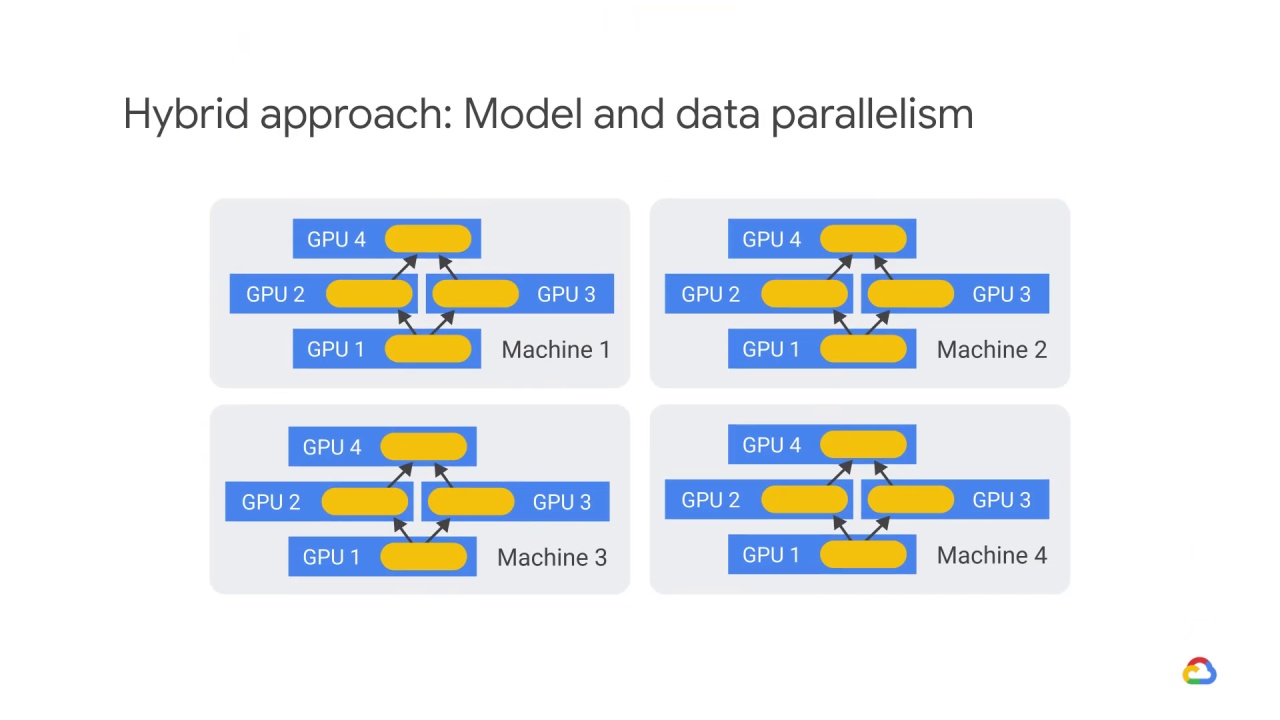
However, a hybrid of the data and model parallelism approaches is sometimes used together in the same architecture.
Now that you’ve been introduced to some of the different distributed training architectures,
we’ll take a look at four TensorFlow distributed training strategies.