Adapting to data


When it comes to adapting to change, consider which of these four is more likely to change?
An upstream mode,

a data source maintained by another team,

the relationship between features and labels,

, or the distributions of inputs. The answer is

that all of them can, and often do, change.
Let’s see how this happens, and what to do about it with a couple example scenarios.
Let’s say that you’ve created a Let’s say that you’ve created a model
to predict demand for umbrellas
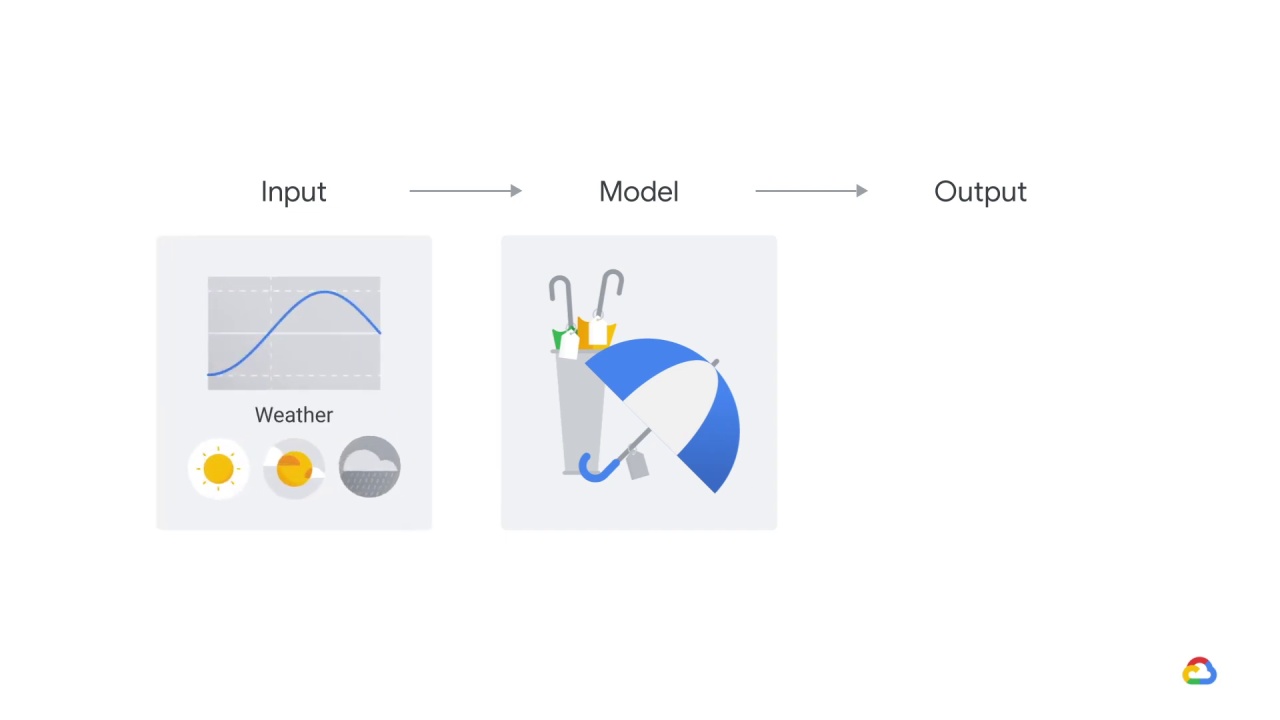
that accepts as input
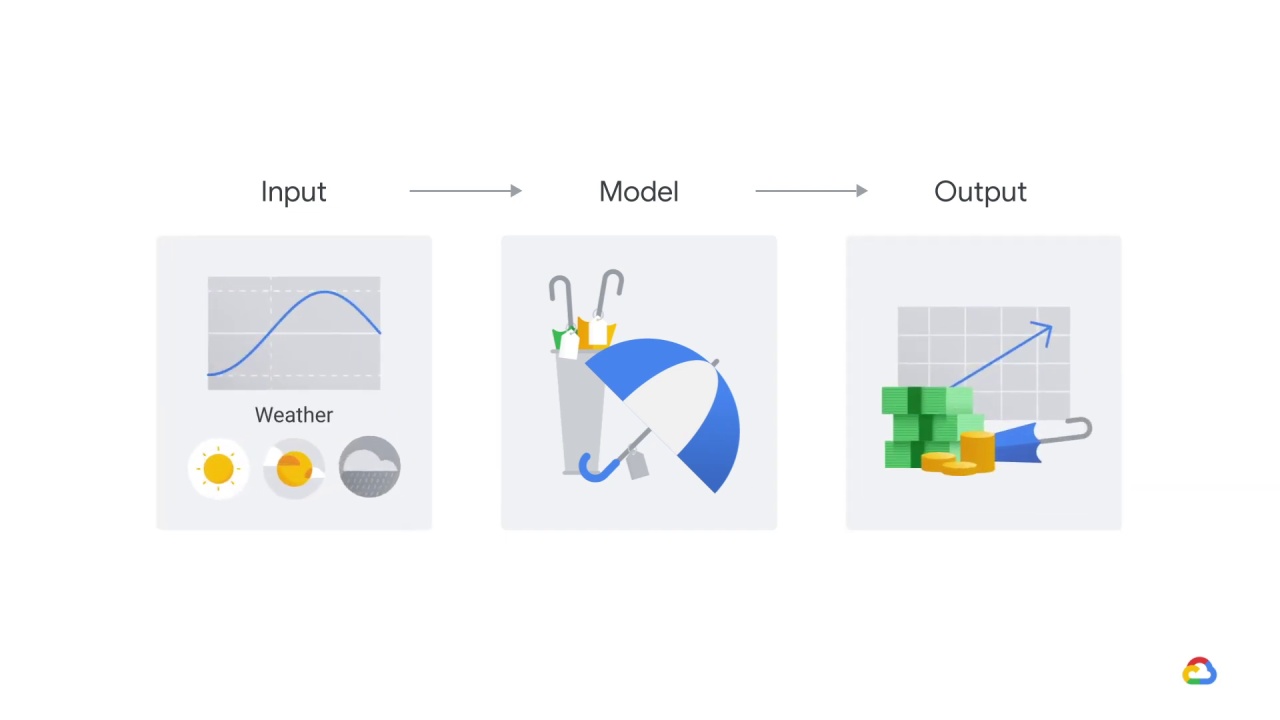
an output from a more specialized weather prediction model.
Unbeknownst to you and the owners, this model has been trained on the wrong years of data.
Your model, however, is fit to the upstream model’s outputs.
What could go wrong?
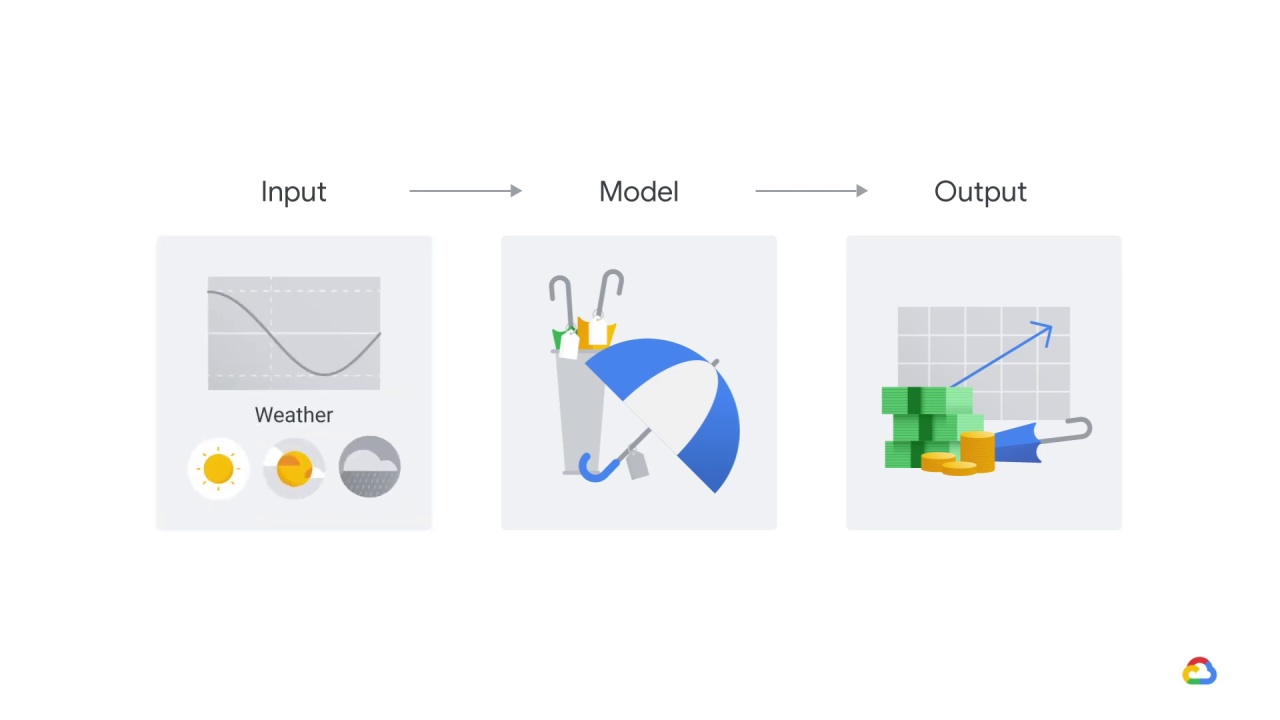
One day, the model owners silently push a fix and the performance of your model, which expected the old model’s distribution of data, drops.
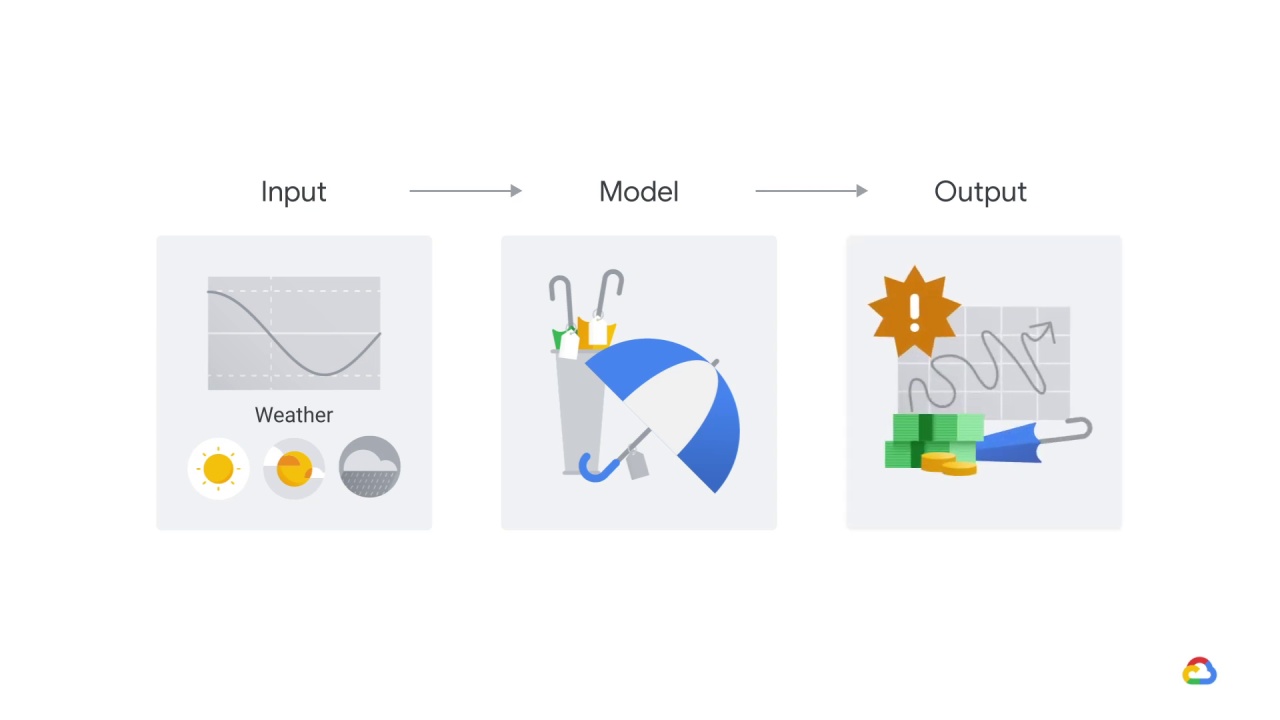
The old data had below-average rainfall and now you’re under-predicting the days when you need an umbrella.
Here’s another scenario.
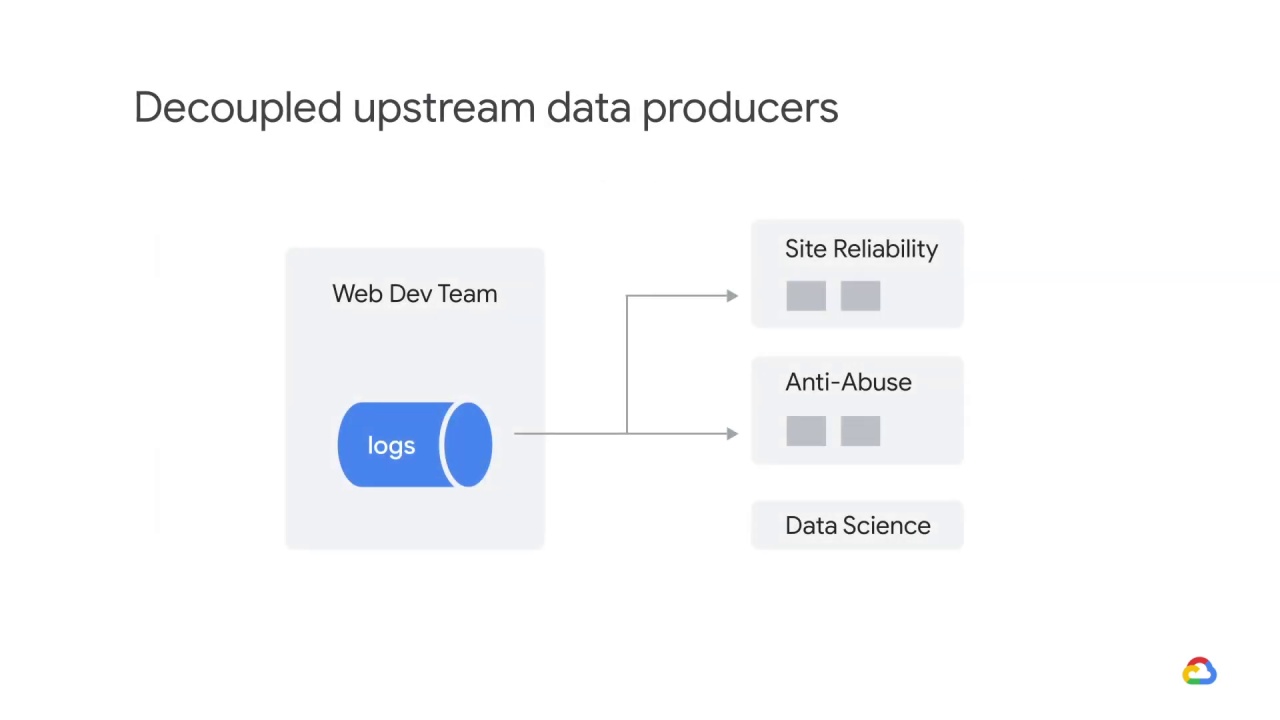
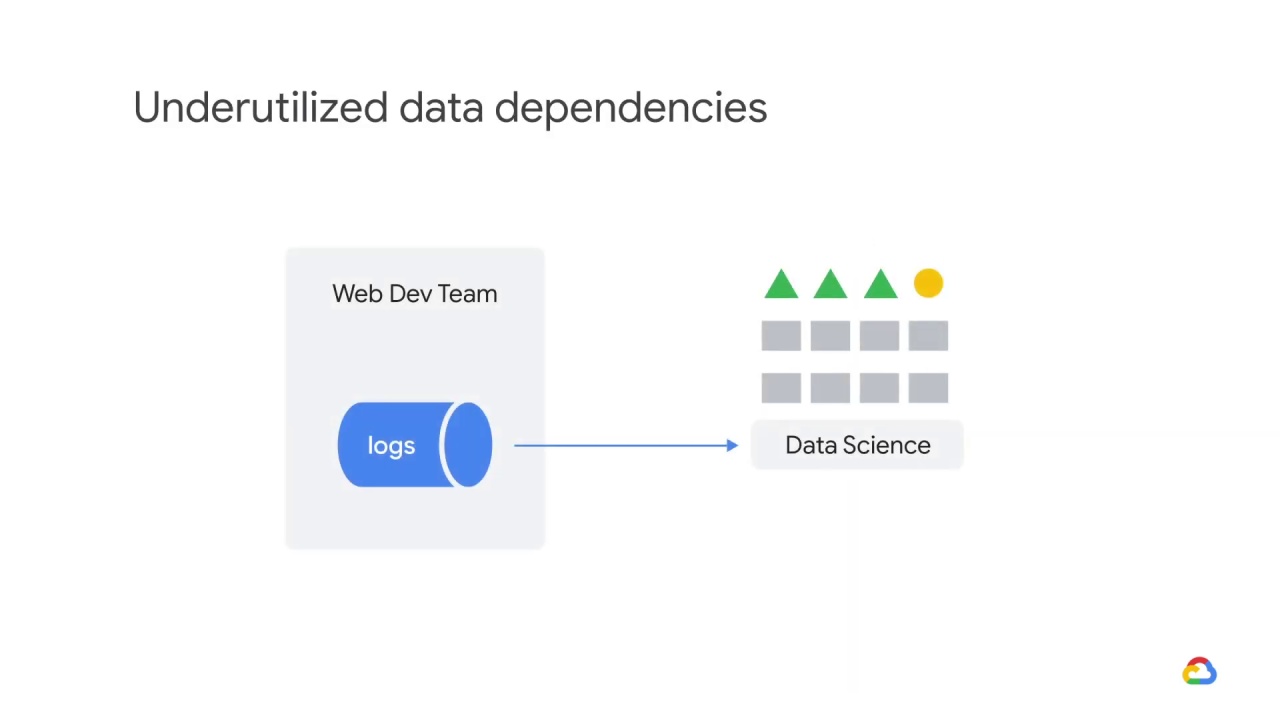
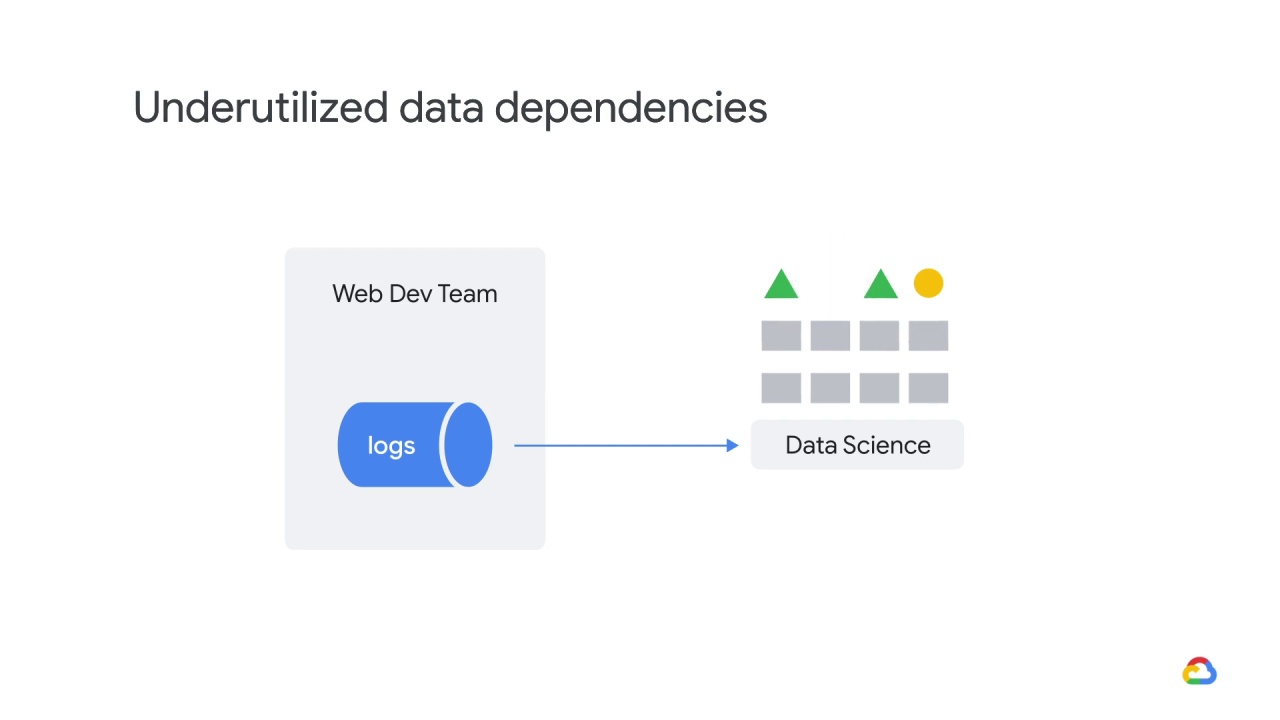
Let’s say your small data science team has convinced the web development team
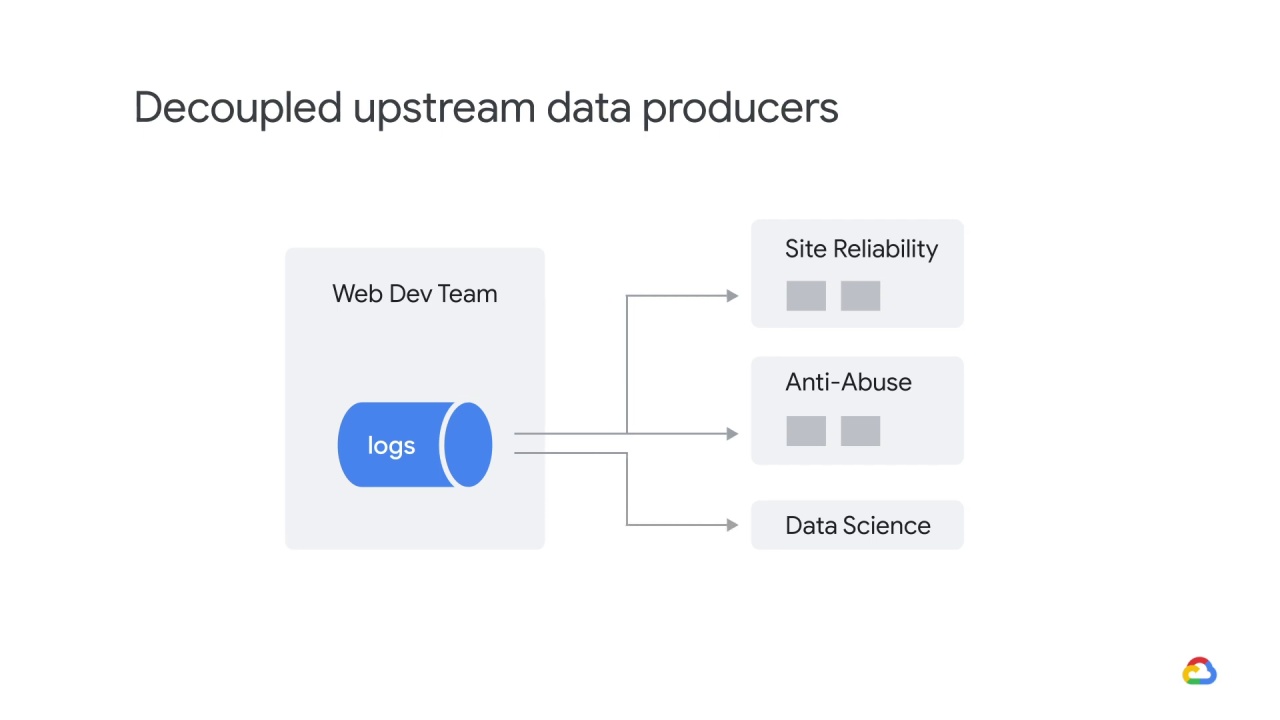
to let you ingest their traffic logs.

Later, the web development team refactors their code and changes their logging format,
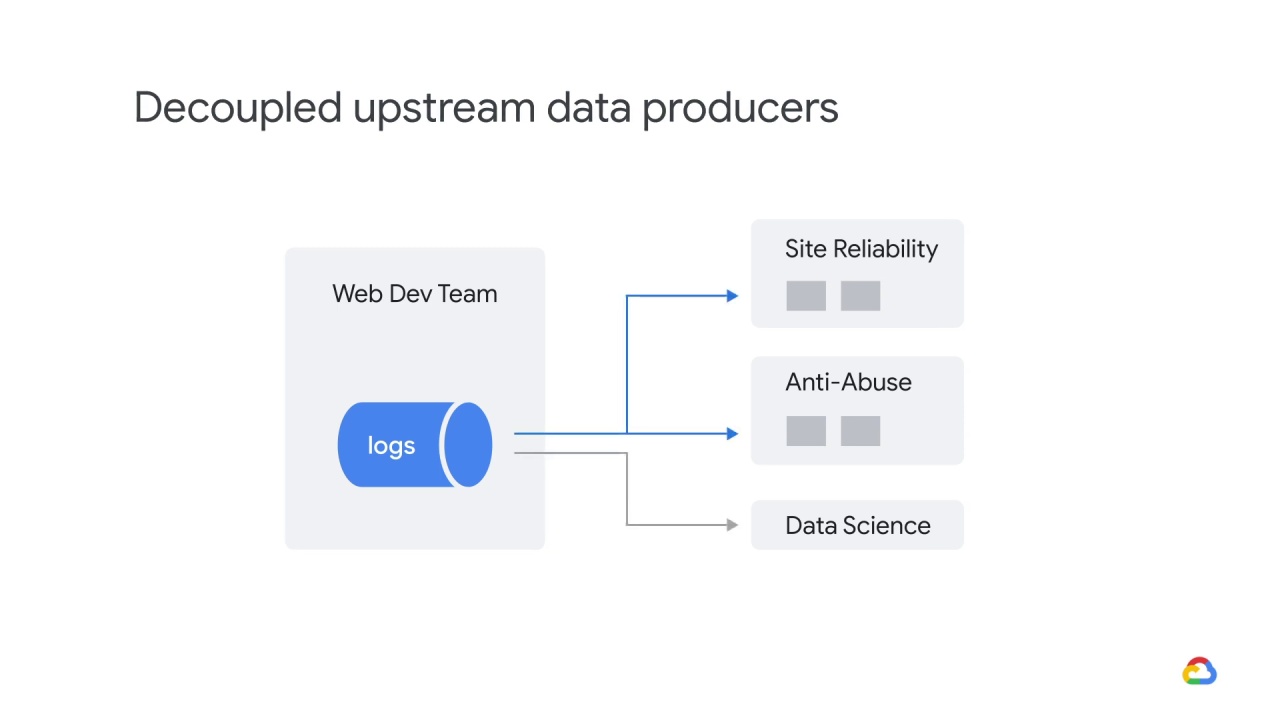
but continues publishing the old format.
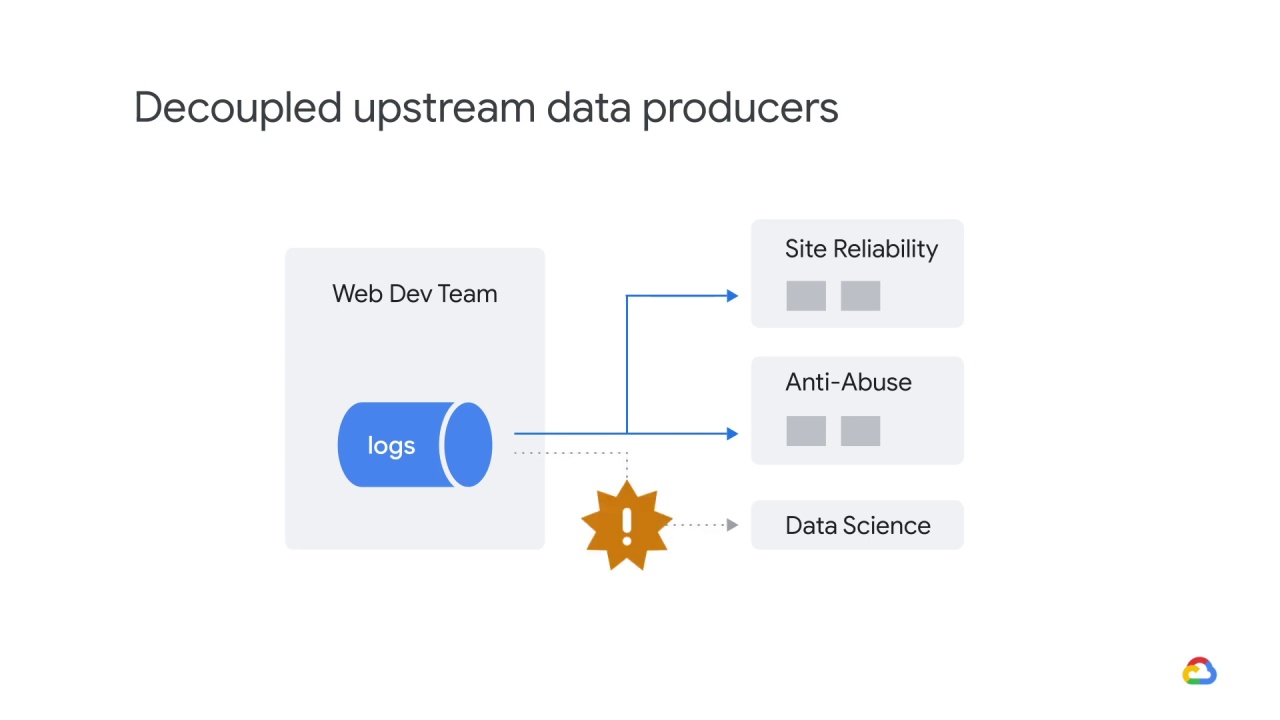
At some point, they stop publishing in the old format but they forget to tell your team.
Your model’s performance degrades after getting an unexpectedly high number of null features.
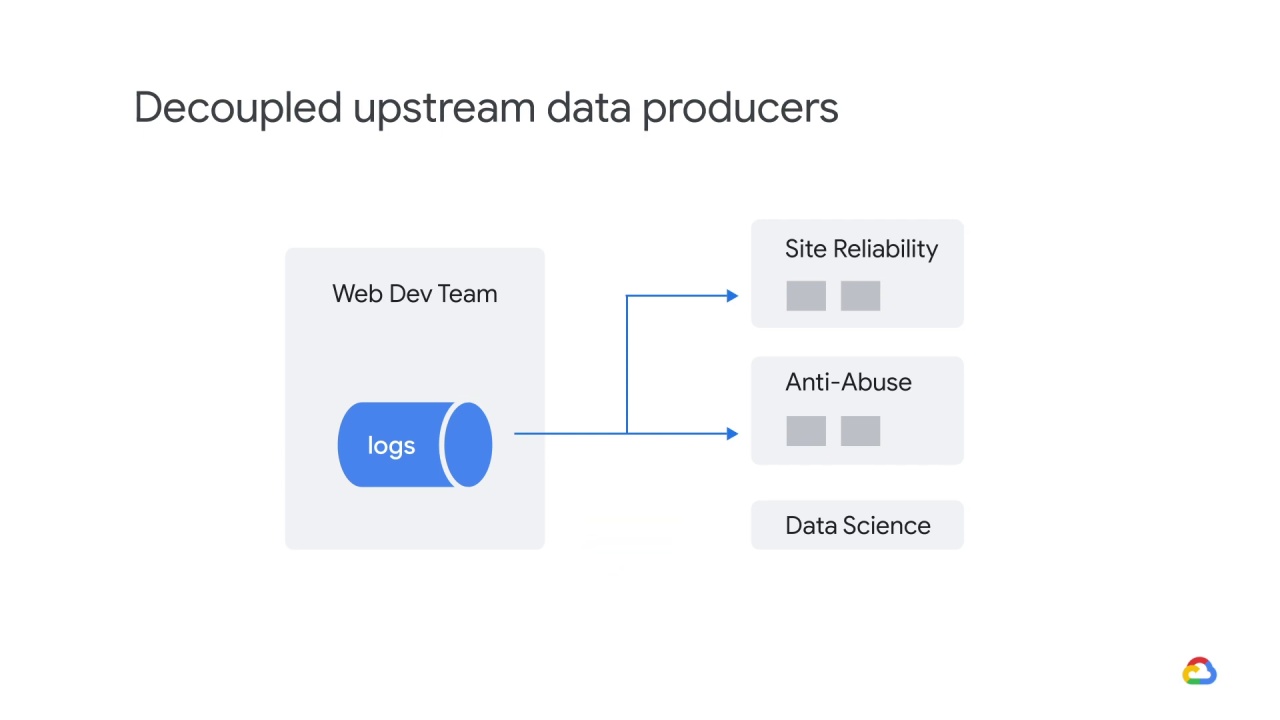
To fix this problem, first, you should stop consuming data from a source that doesn’t notify downstream consumers.
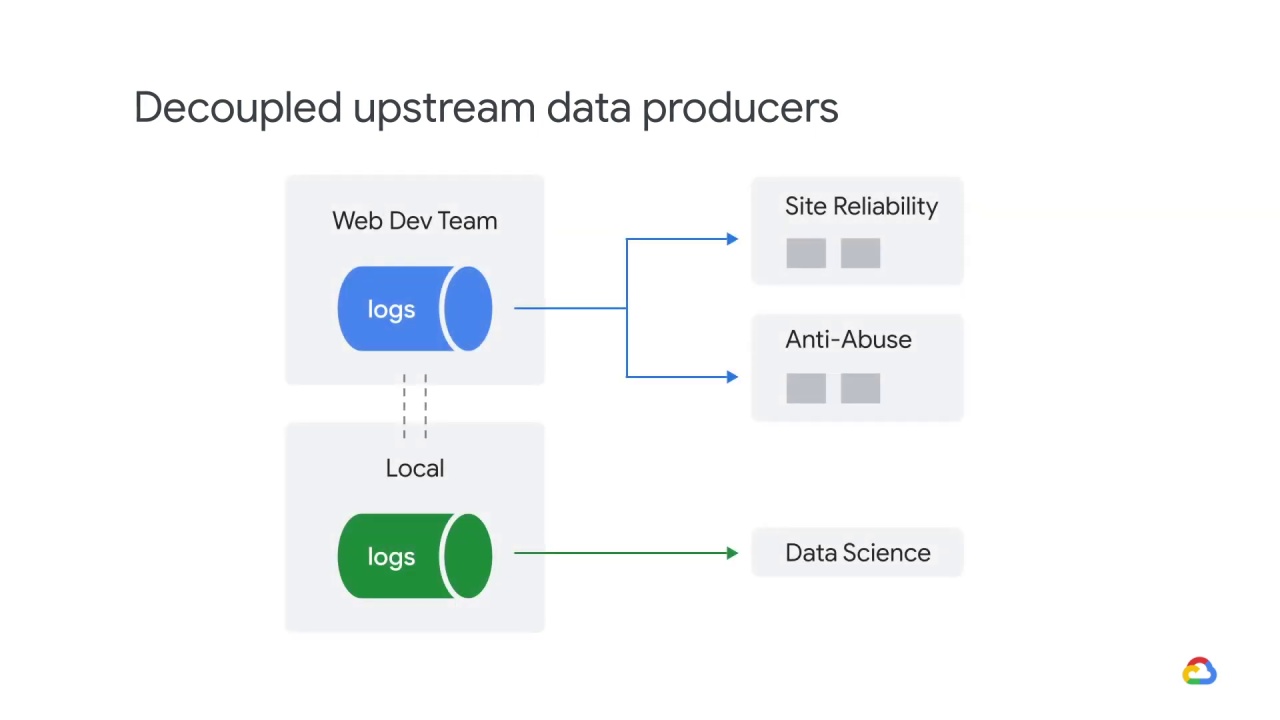
Second, you should consider making a local version of the upstream model and keeping it updated.
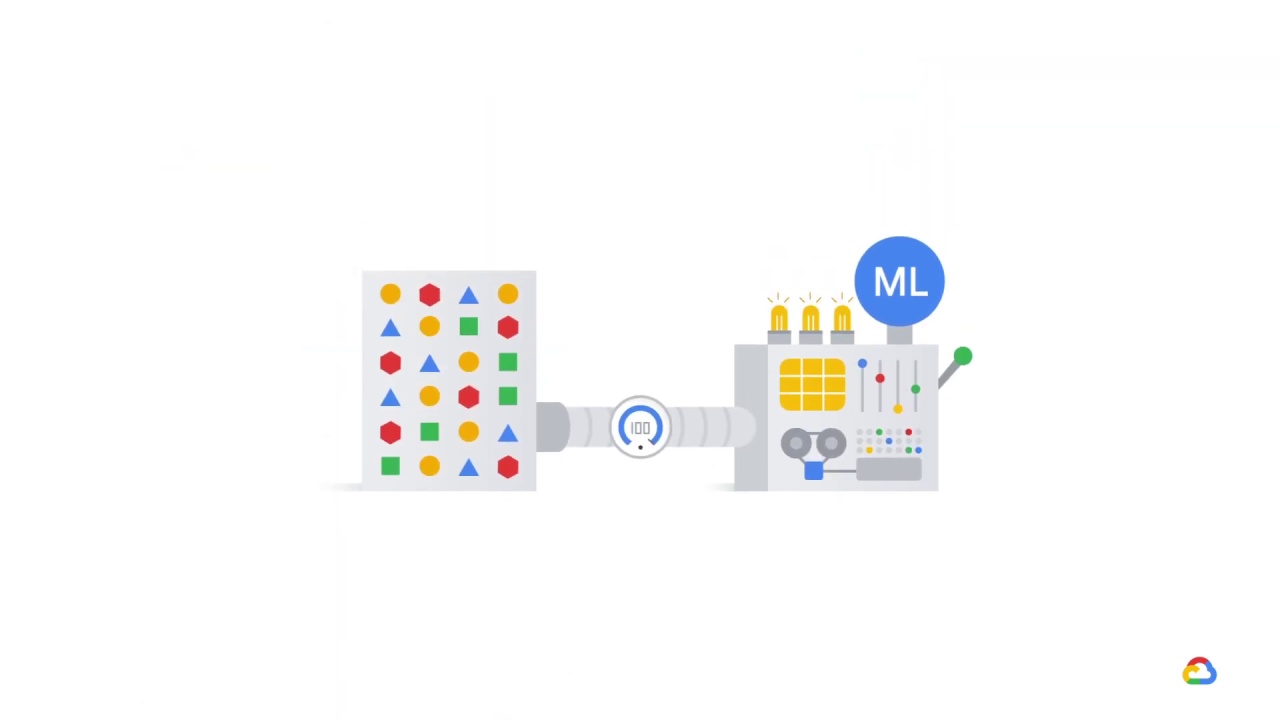
Sometimes, the set of features that the model has been trained on include
many that were added indiscriminately, which may worsen performance at times.
For example, under pressure during a sprint, your team decided to include
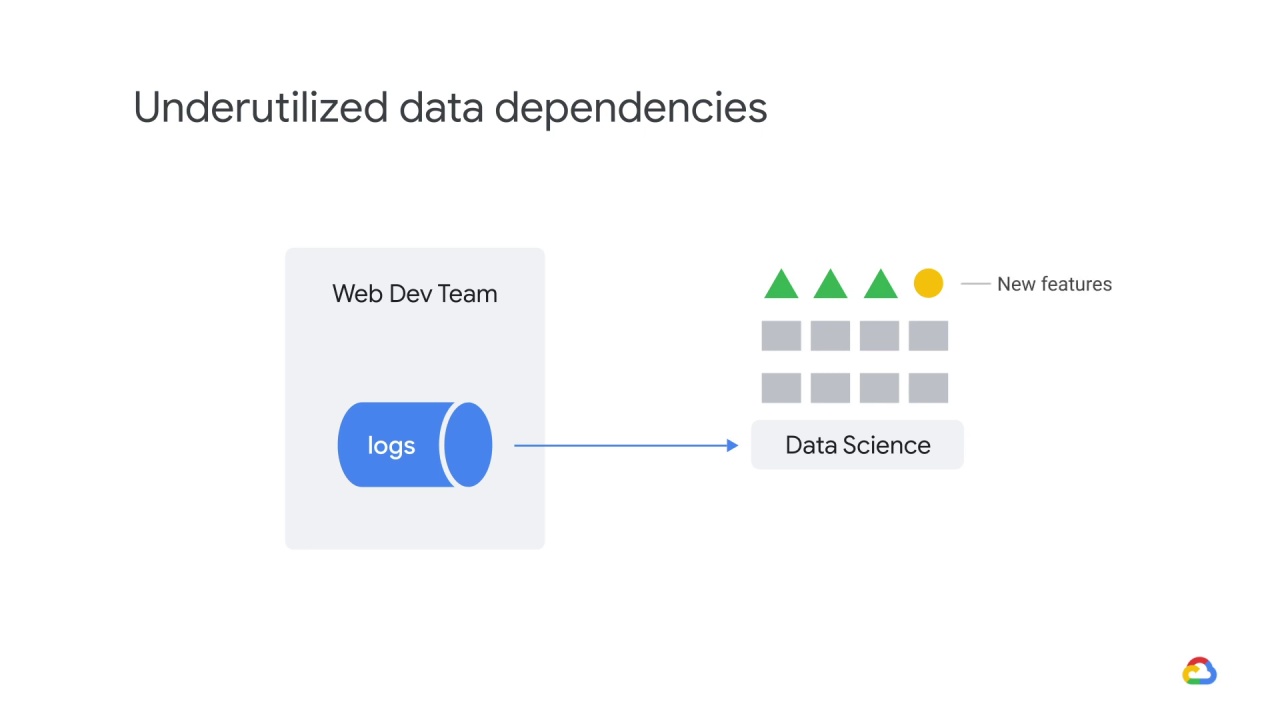
a number of new features without understanding their relationship to the label.
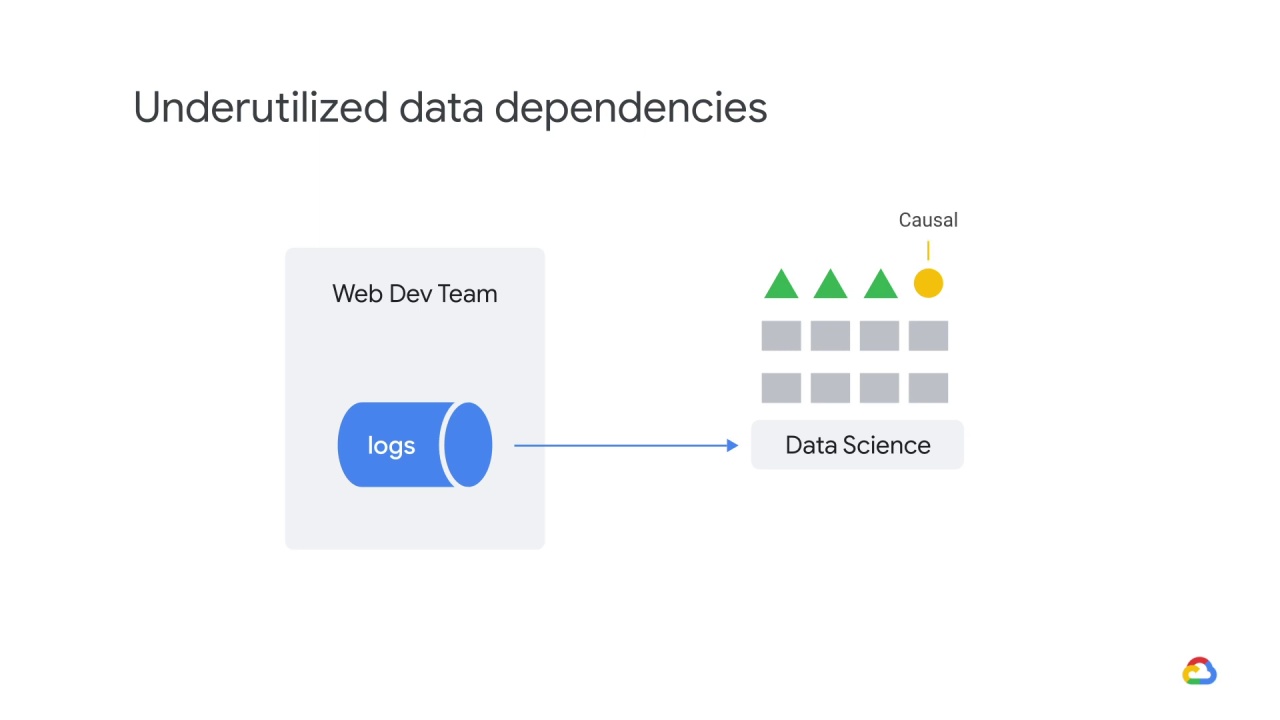
One of them is causal,
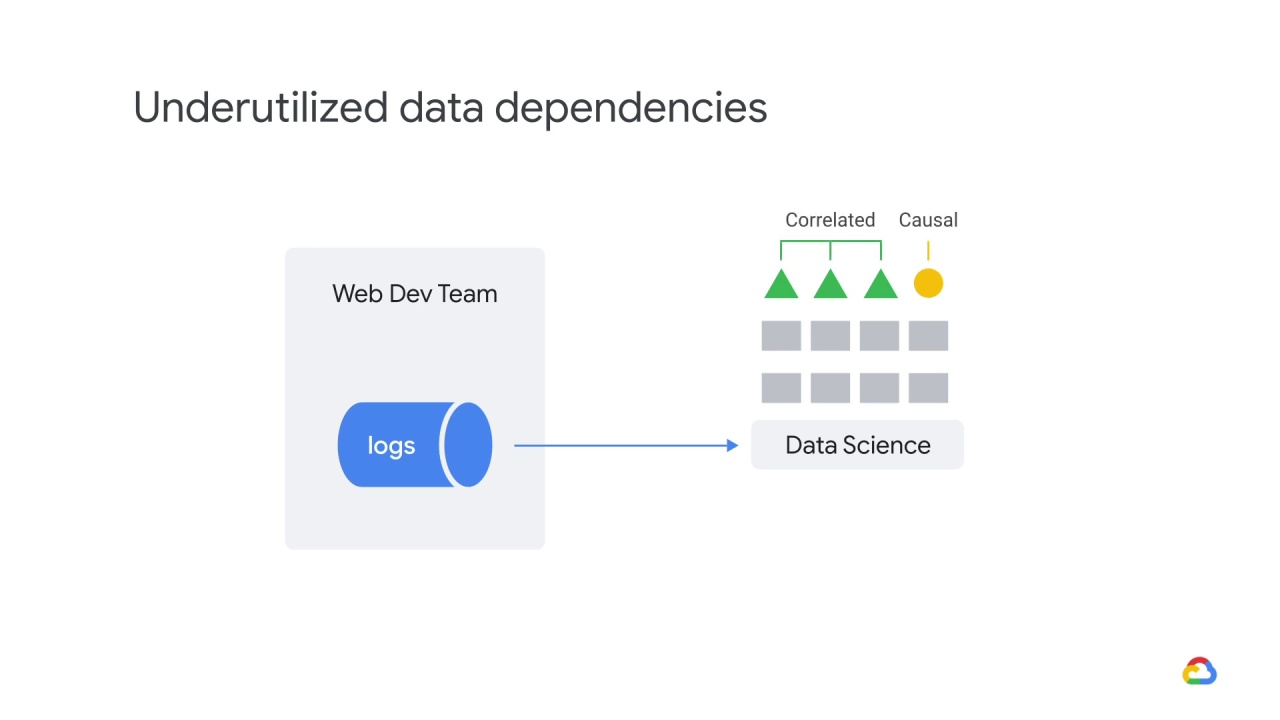
while the others are merely correlated with the causal one.
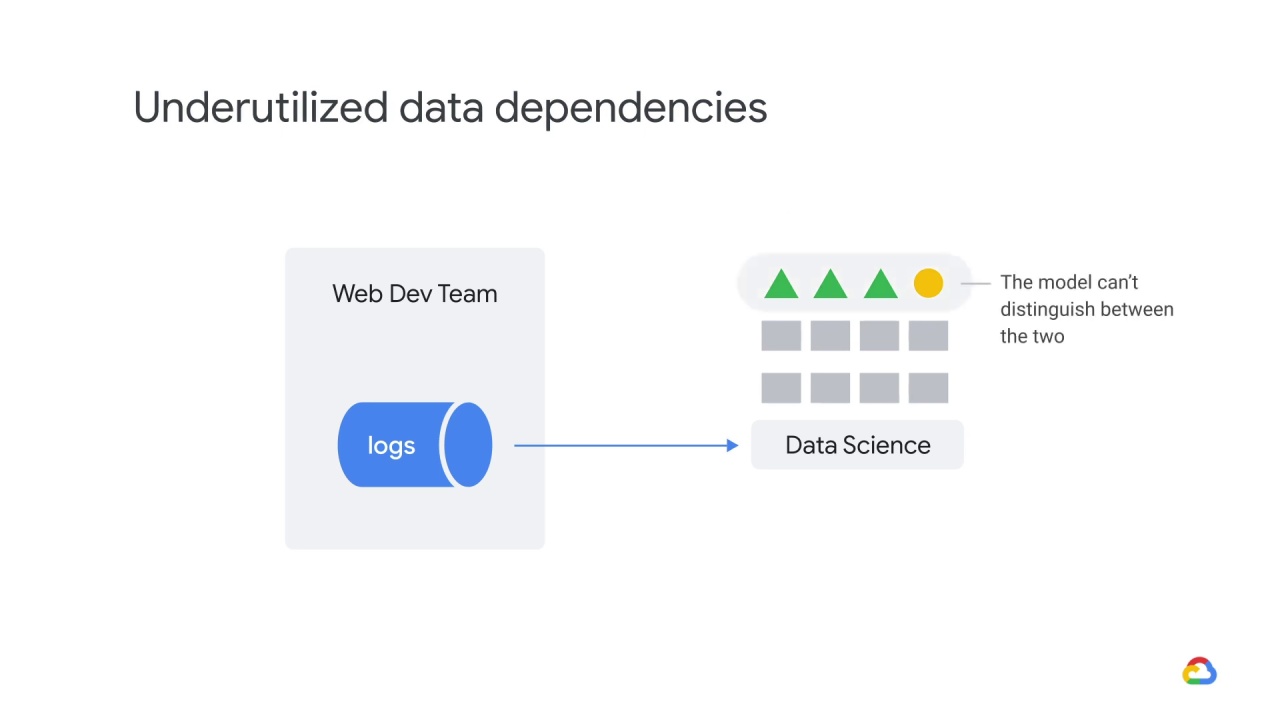
The model can’t distinguish between the two types,
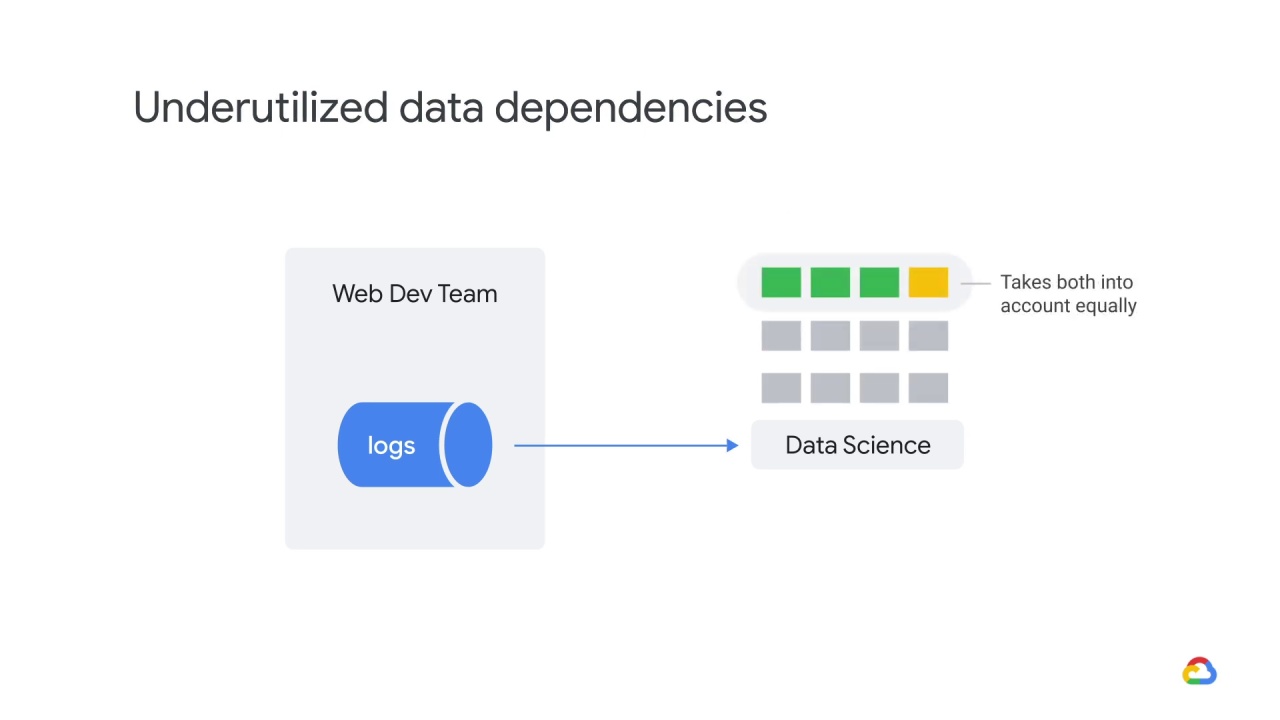
and takes all features into account equally
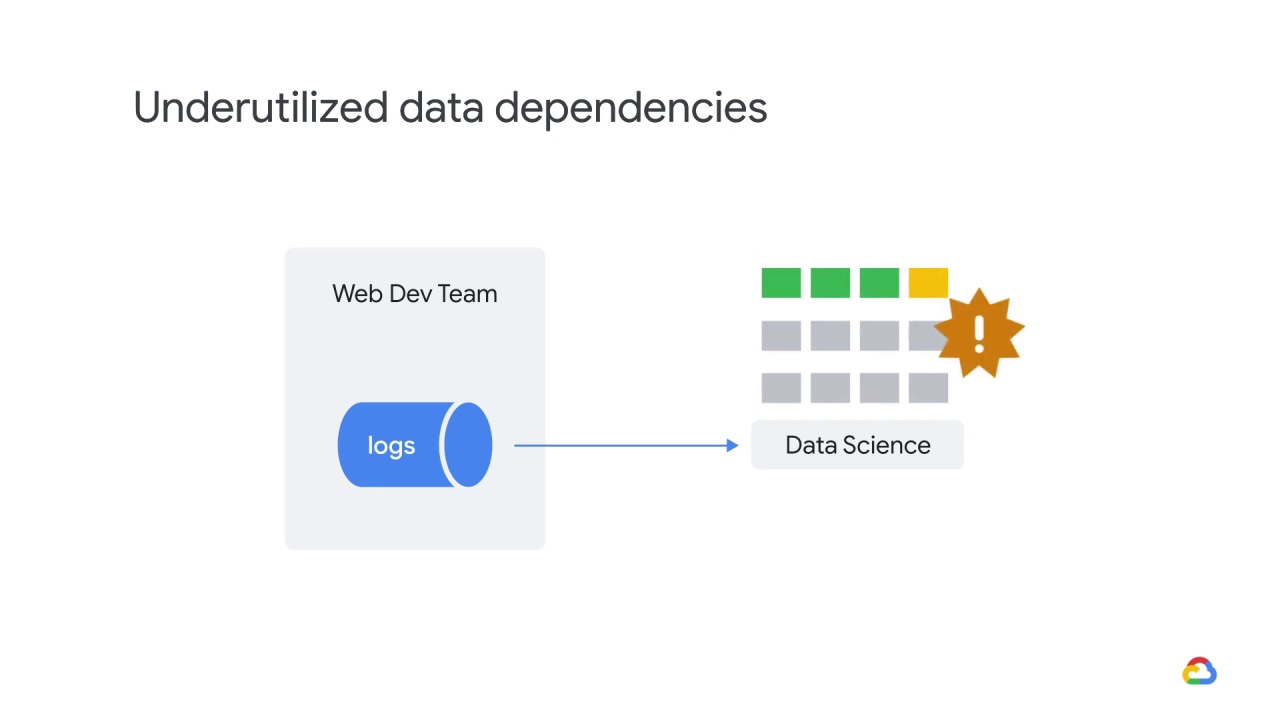
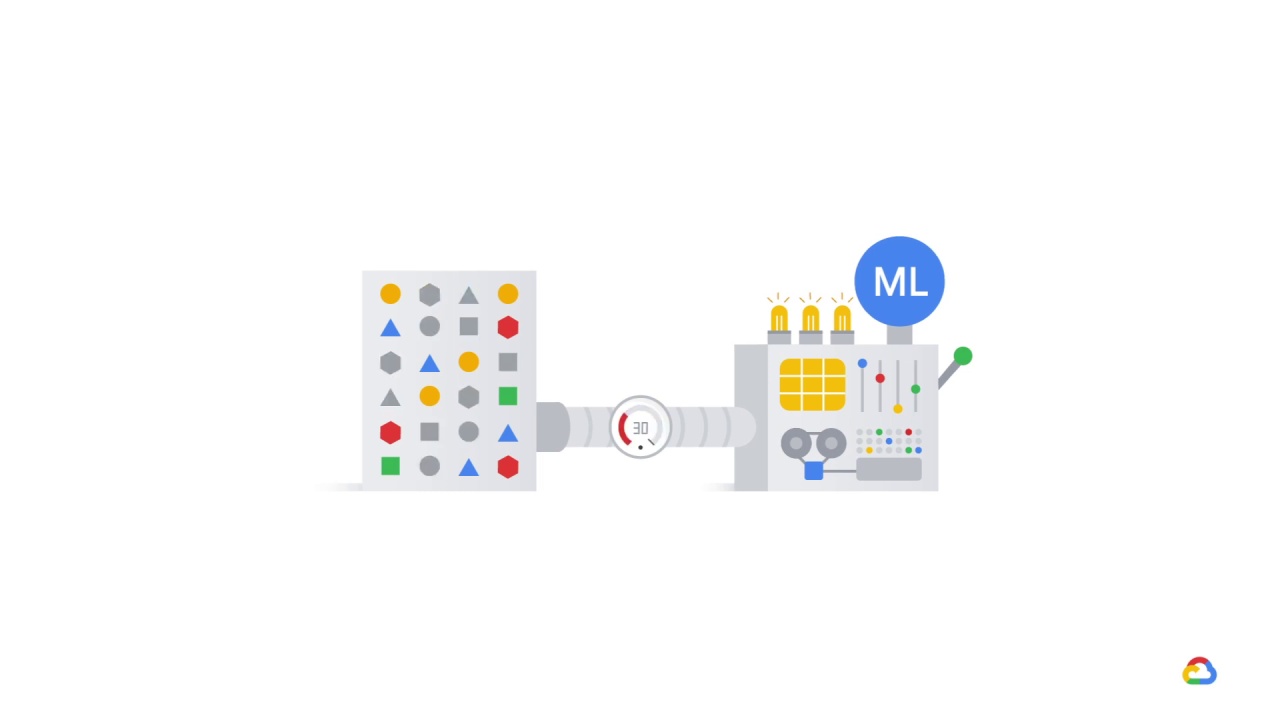
Months later, the correlated feature becomes decorrelated with the label and is thus no longer predictive.
The model’s performance suffers.
To address this,
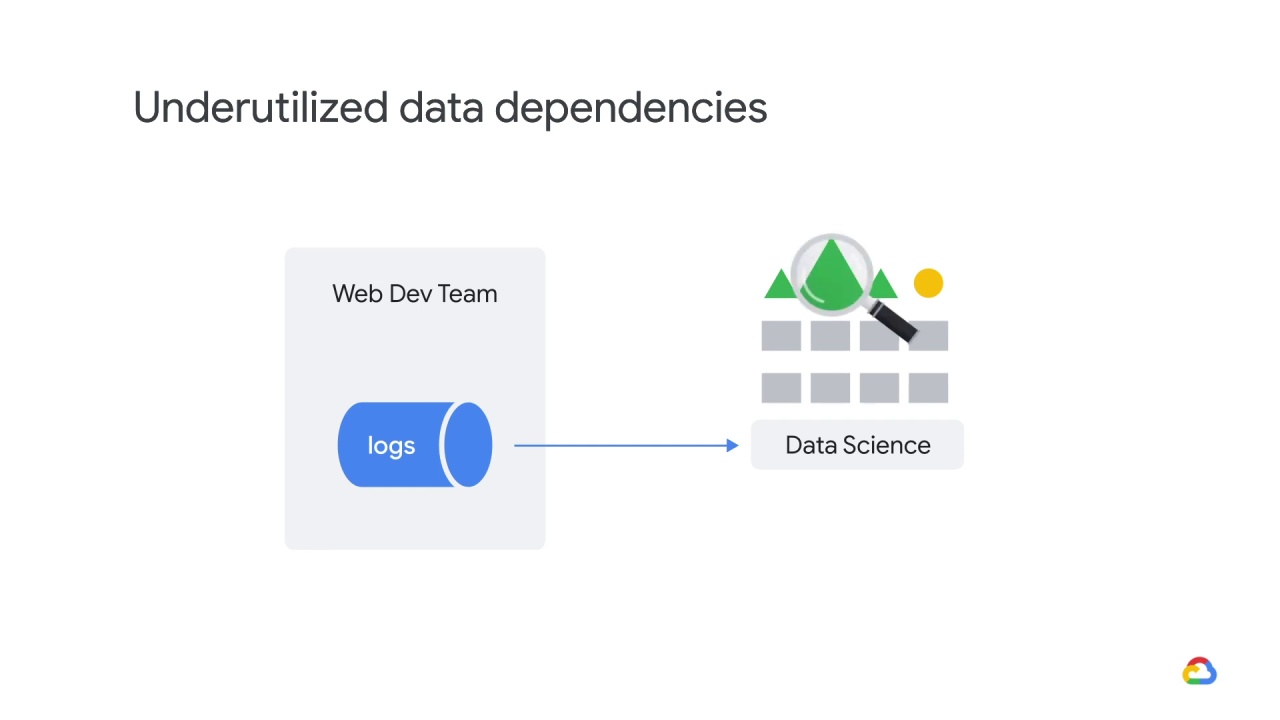
features should always be scrutinized before being added,
and all features should be subjected to leave-one-out evaluations, to assess their importance.