Mitigating training-serving skew through design

We’ve talked about training/serving skew a number, but always at a high level.
Let’s look at it now in a little more detail.
Training/Serving skew refers to

differences in performance that occur as a function of differences in environment.
Specifically, training/serving skew refers to differences caused by one of three things:
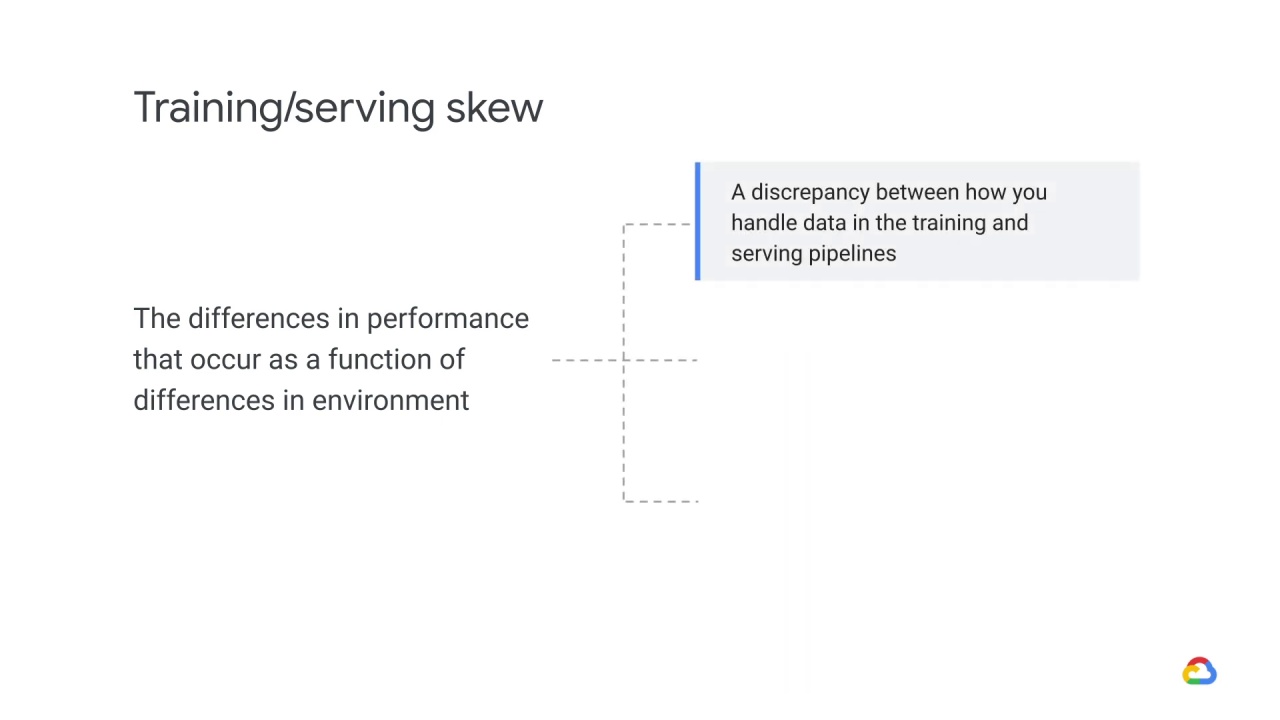
A discrepancy between how you handle data in the training and serving pipelines
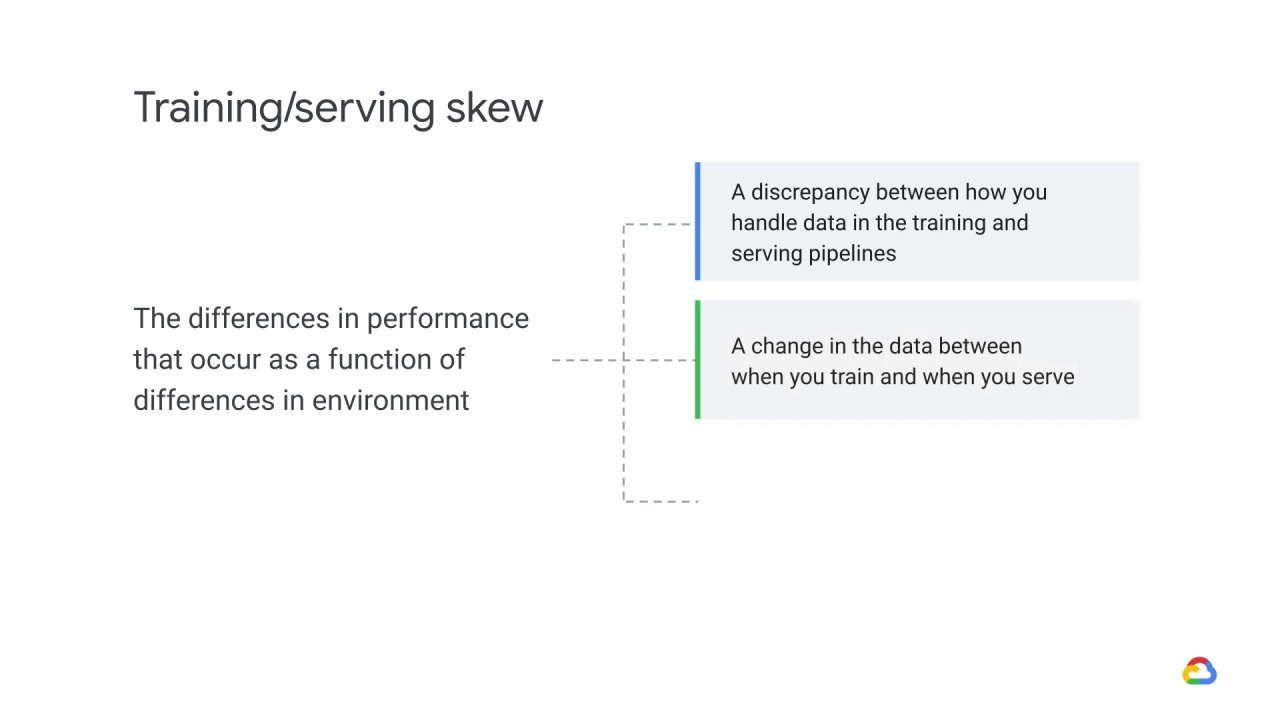
A change in the data between when you train and when you serve, or
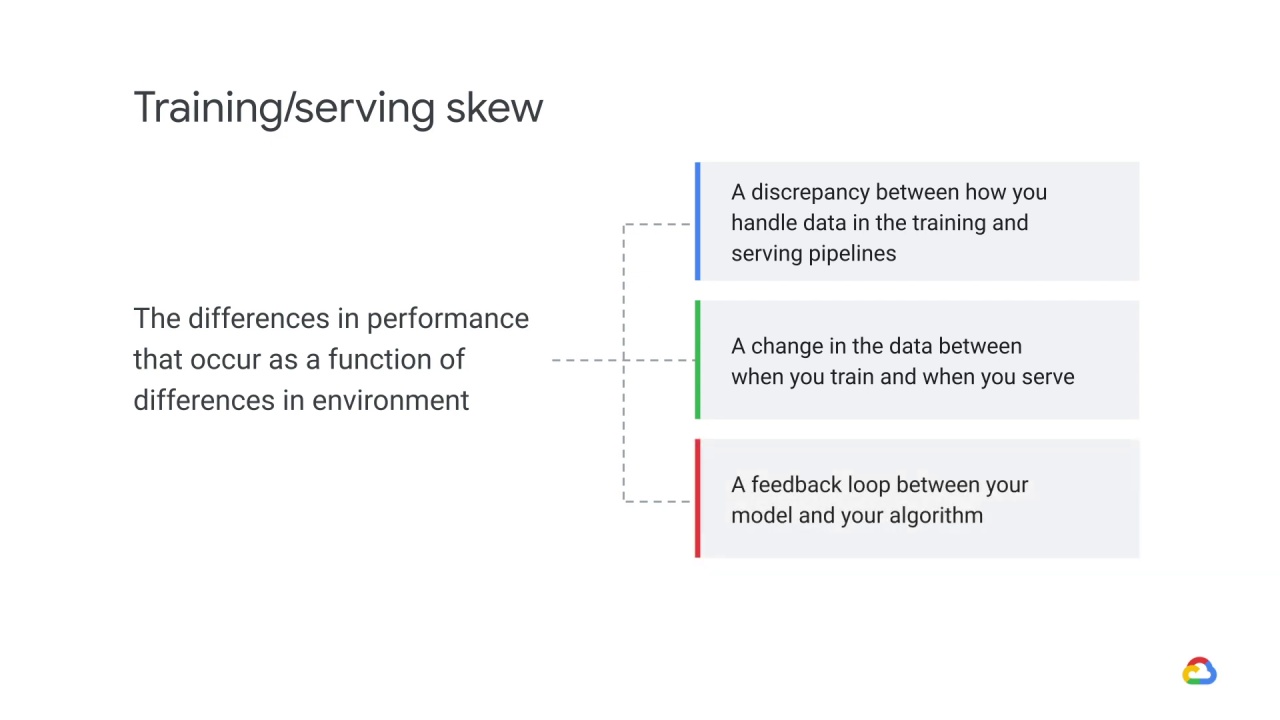
A feedback loop between your model and your algorithm.

Up until now, we’ve focused on the data aspect of training-serving skew,

but it’s also possible to have inconsistencies that arise after the data have been introduced.

Say, for example, that in your development environment, you have version 2 of a library, but in production you have version 1.
The libraries may be functionally equivalent but version 2 is
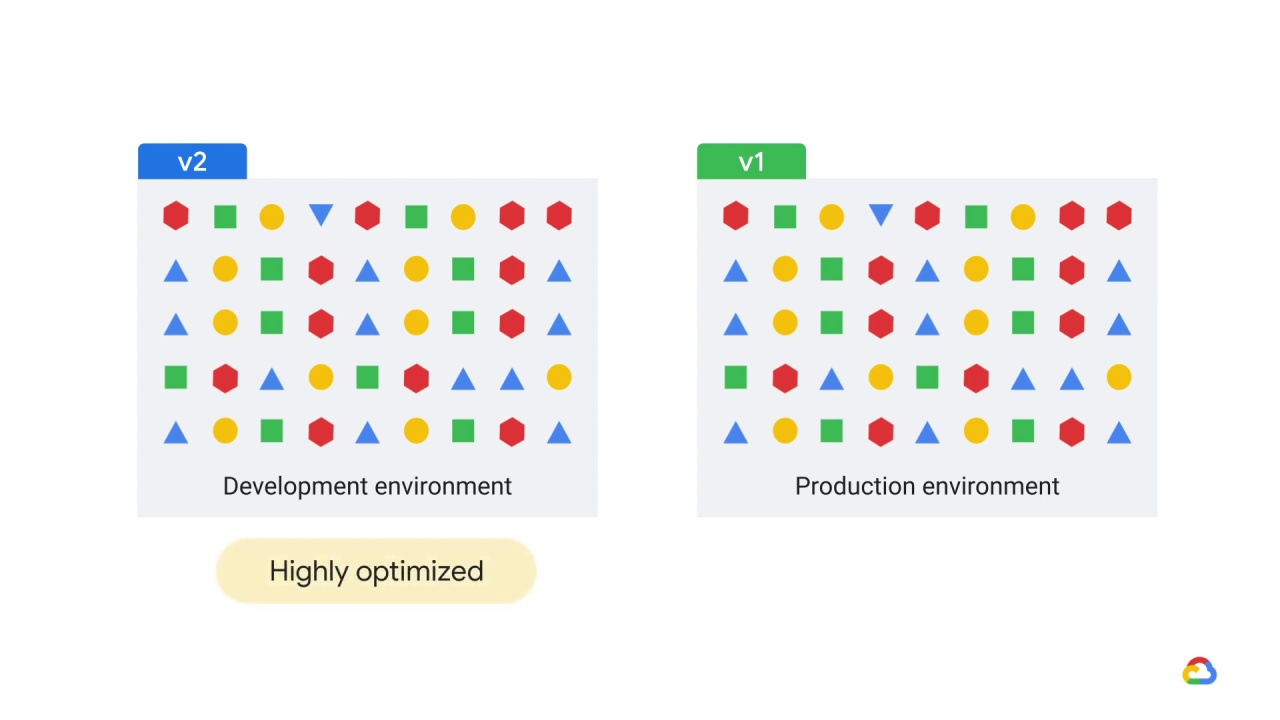
highly optimized and version 1 isn’t.
Consequently, predictions might be significantly slower or consume more memory in production than they did in development.
Alternately, it’s possible that version 1 and version 2 are functionally different, perhaps because of
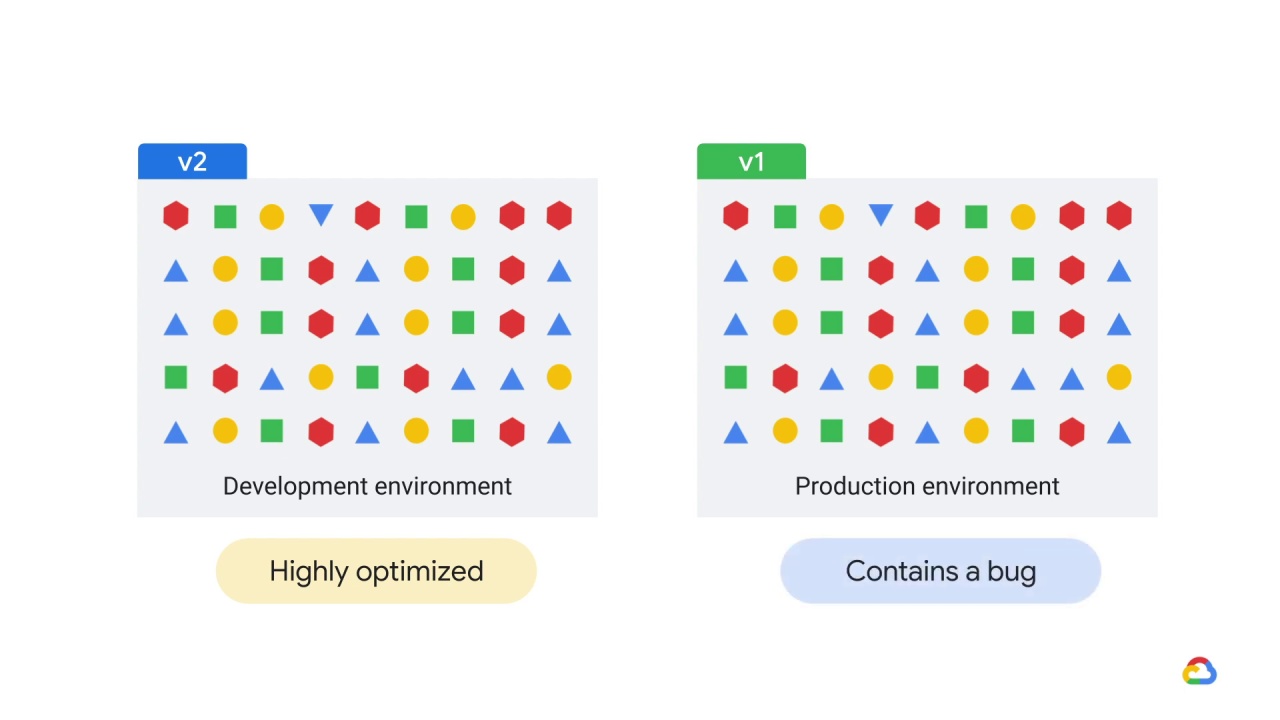
a bug.
Finally, it’s also possible that
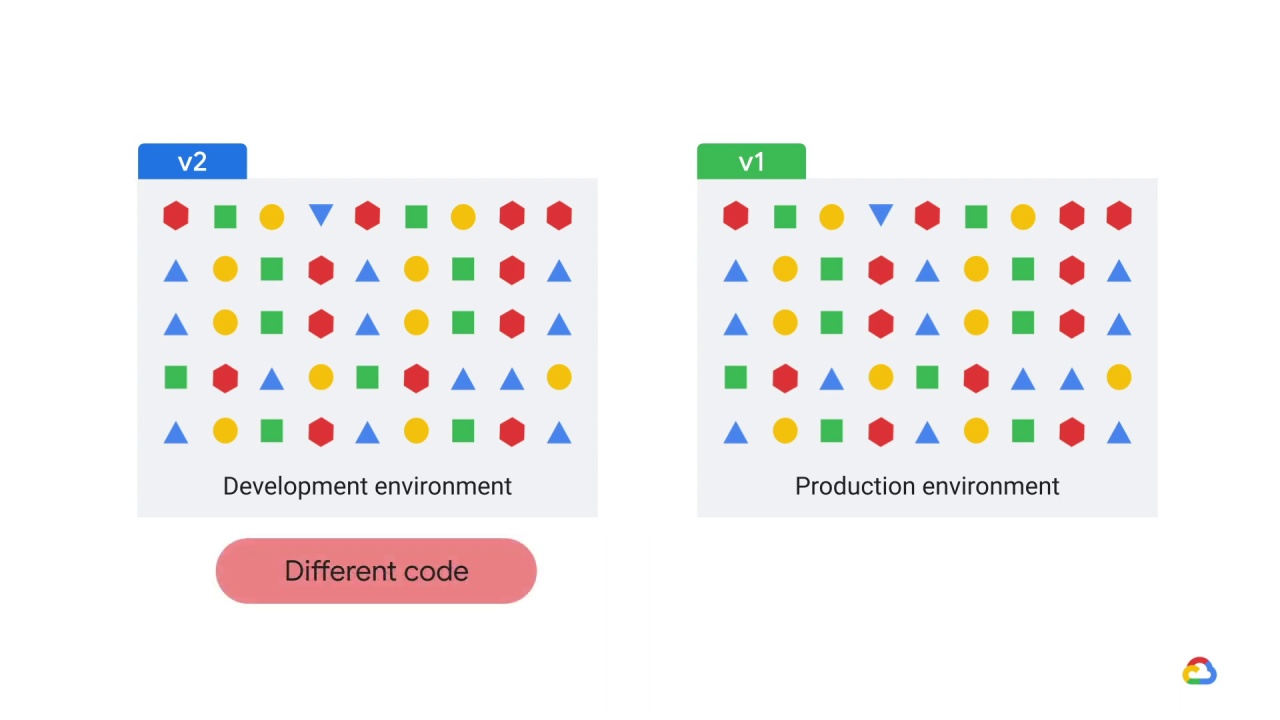
different code is used in production vs. development, perhaps because of recognition of one of the other issues, but though the intent was to create equivalent code, the results were imperfect.