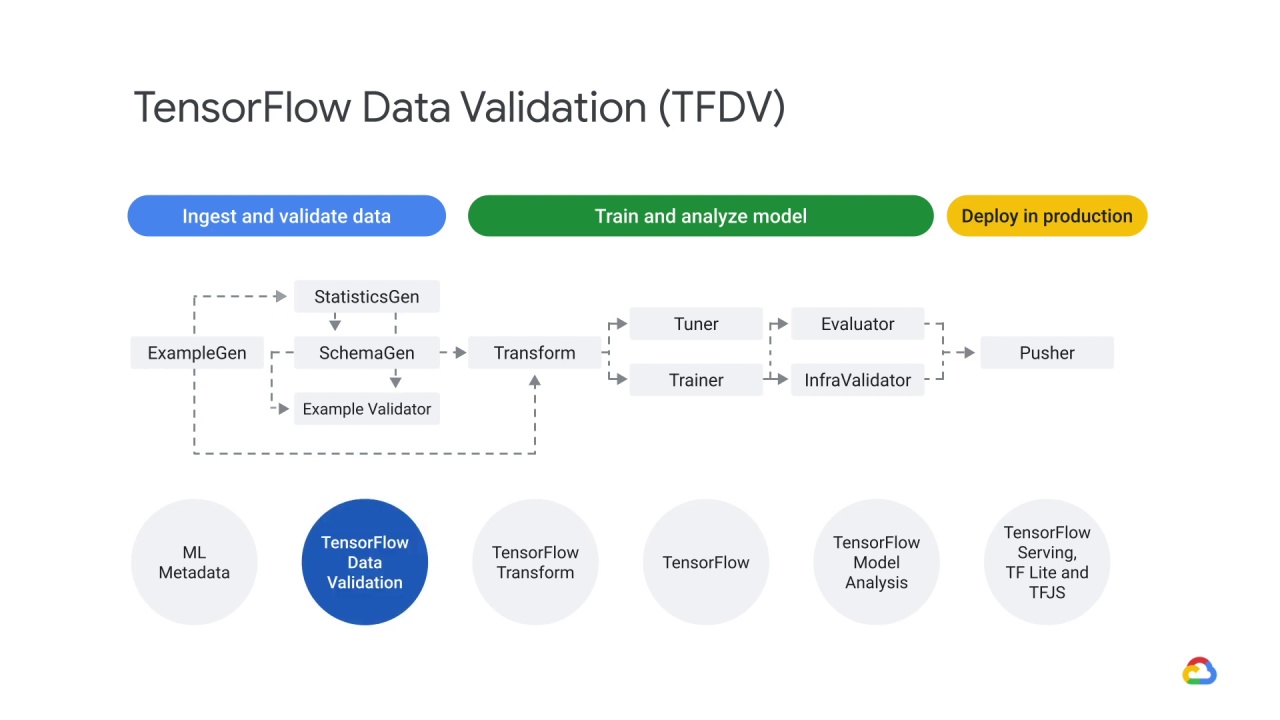
TensorFlow data validation

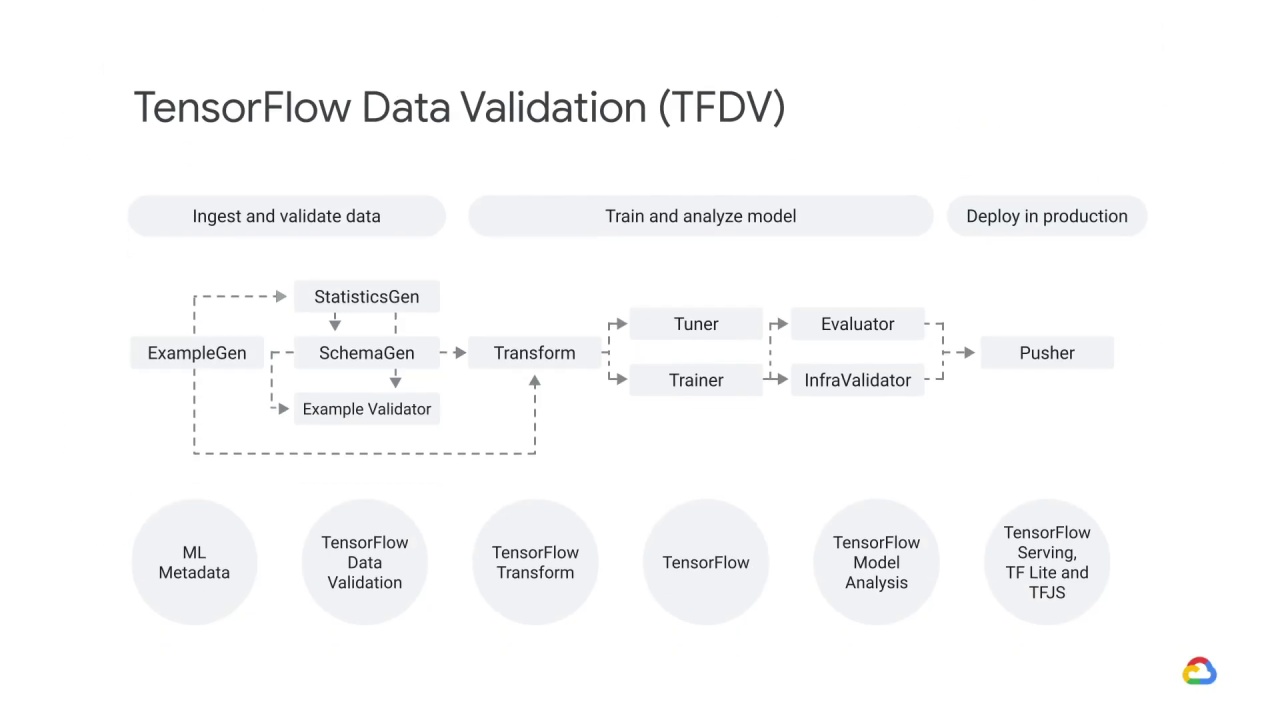
There are three phases in a pipeline:
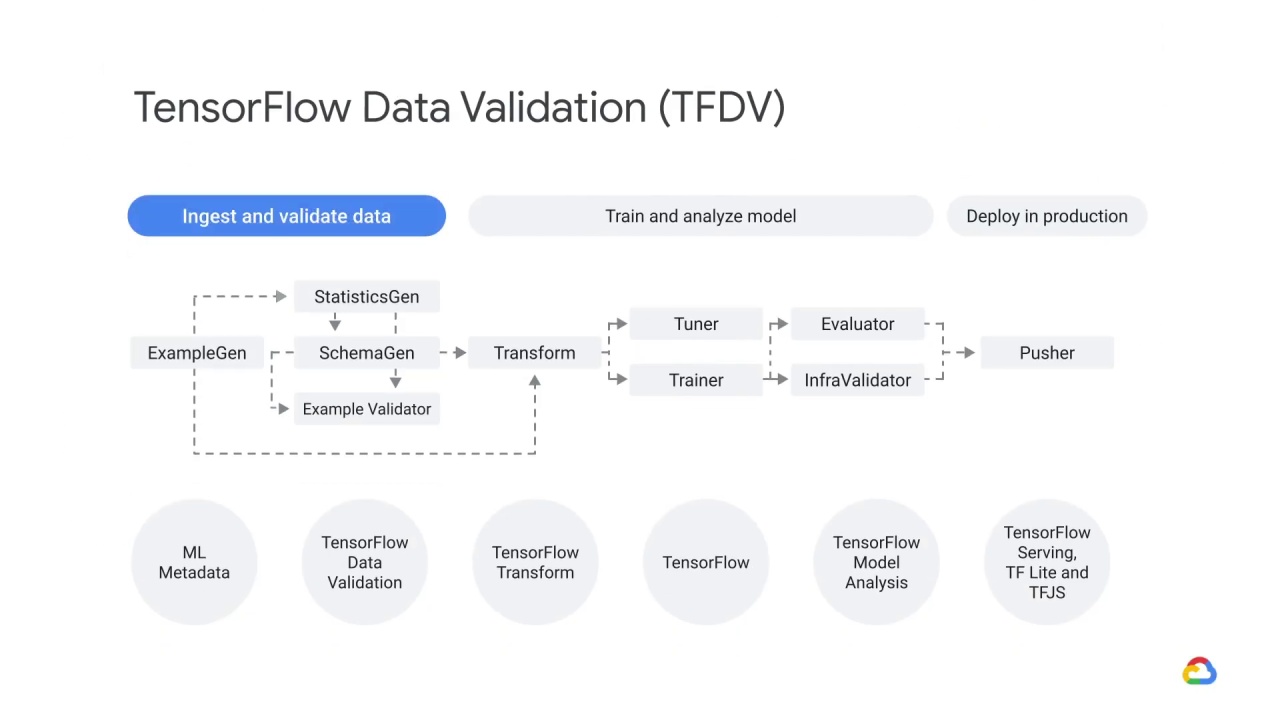
Data is ingested and validated
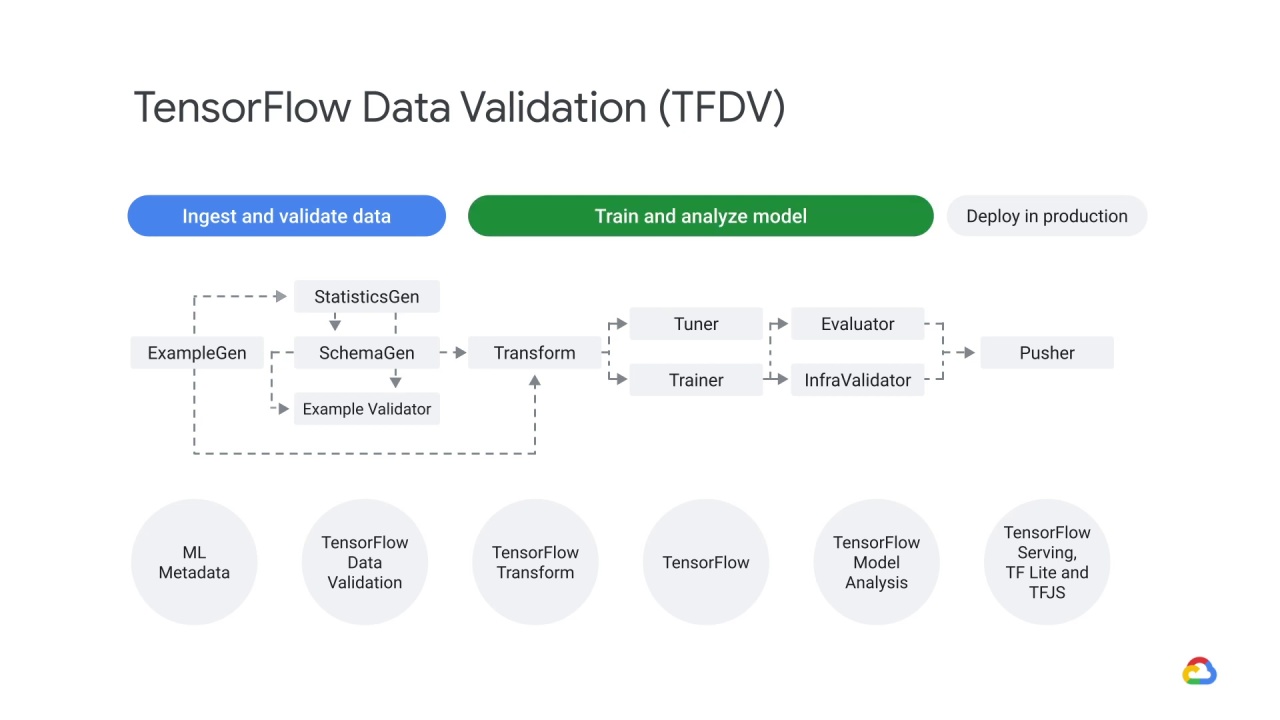
A model is trained and analyzed
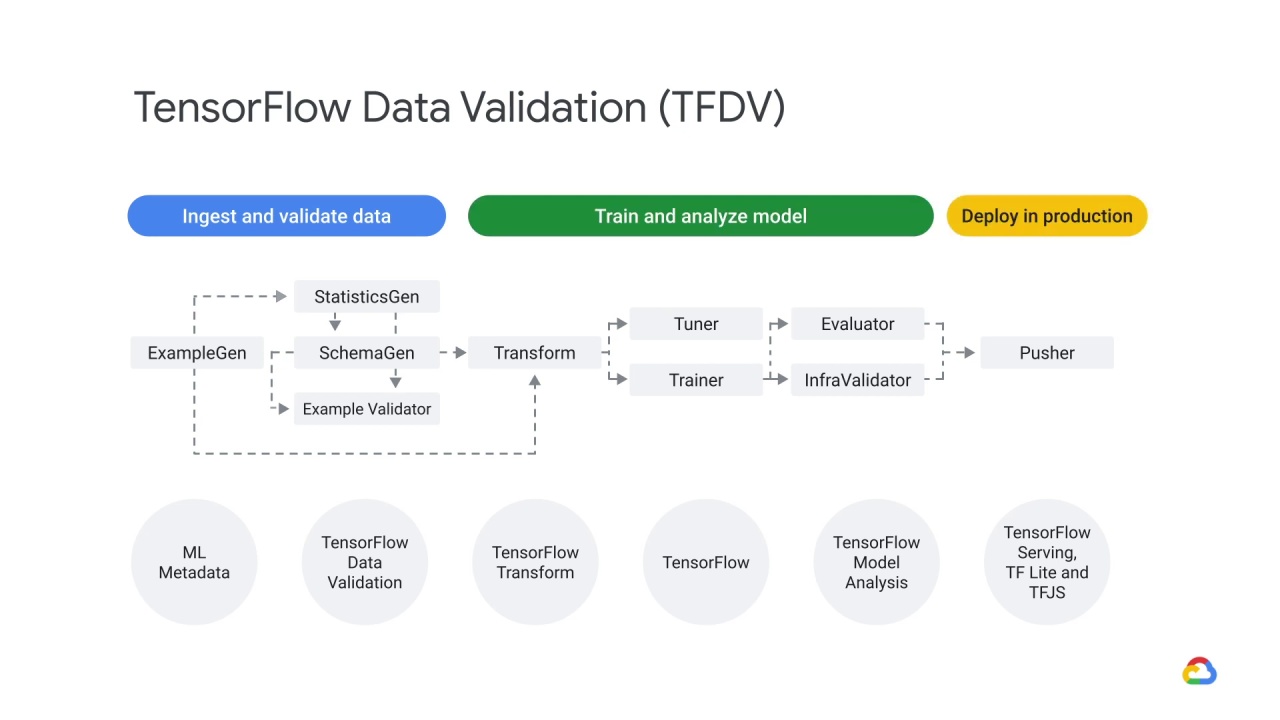
The model is then deployed in production
We’ll provide an overview of TensorFlow Data Validation,
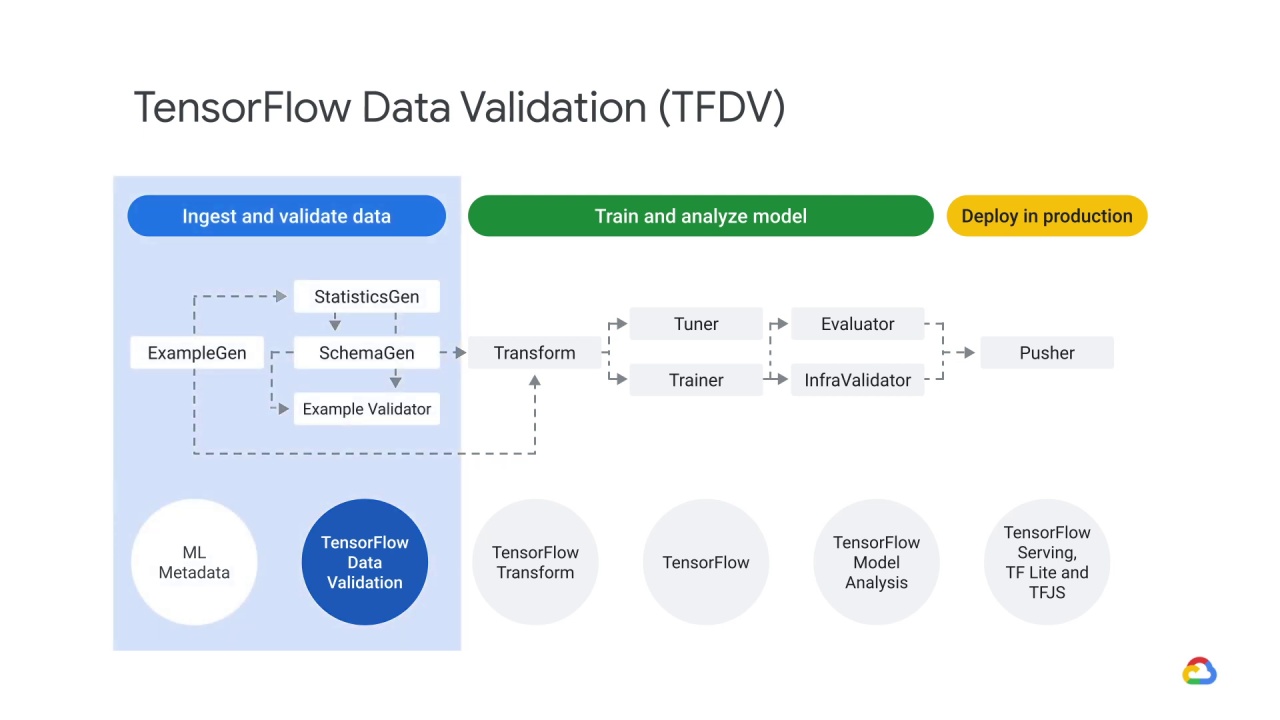
which is part of the ingest and validate data phase.
To learn more about the train and analyze the model phase, or how to deploy a model in production, please check out our MLOps Course.

TensorFlow Data Validation is a library for analyzing and validating machine learning data.
Two common use-cases of TensorFlow Data Validation within a TensorFlow Extended pipelines are

validation of continuously arriving data

and training/serving skew detection.
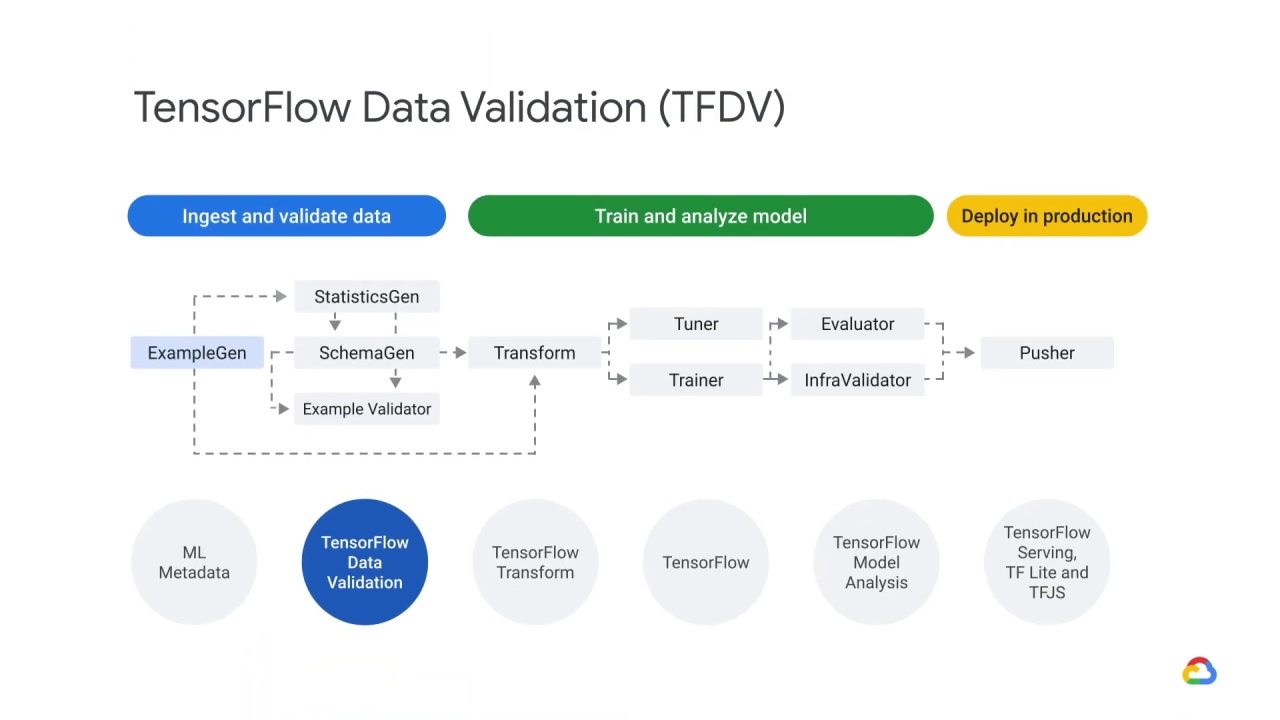
The pipeline begins with the ExampleGen component.
This component takes raw data as input and generates TensorFlow examples, it can take many input formats (e.g. CSV, TF Record).
It also does split the examples for you into Train/Eval.
It then passes the result…
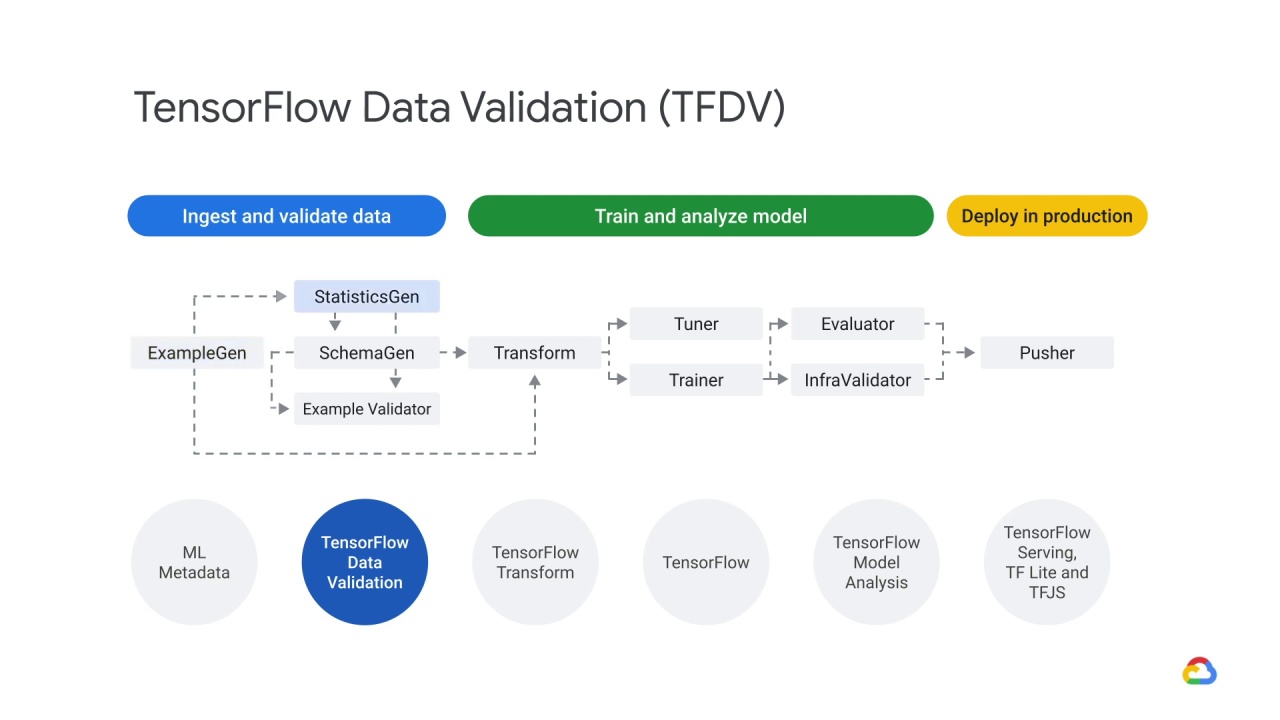
…to the StatisticsGen component.
This brings us to the three main components of TensorFlow Data Validation.
The Statistics Generation component - which generates statistics for feature analysis,
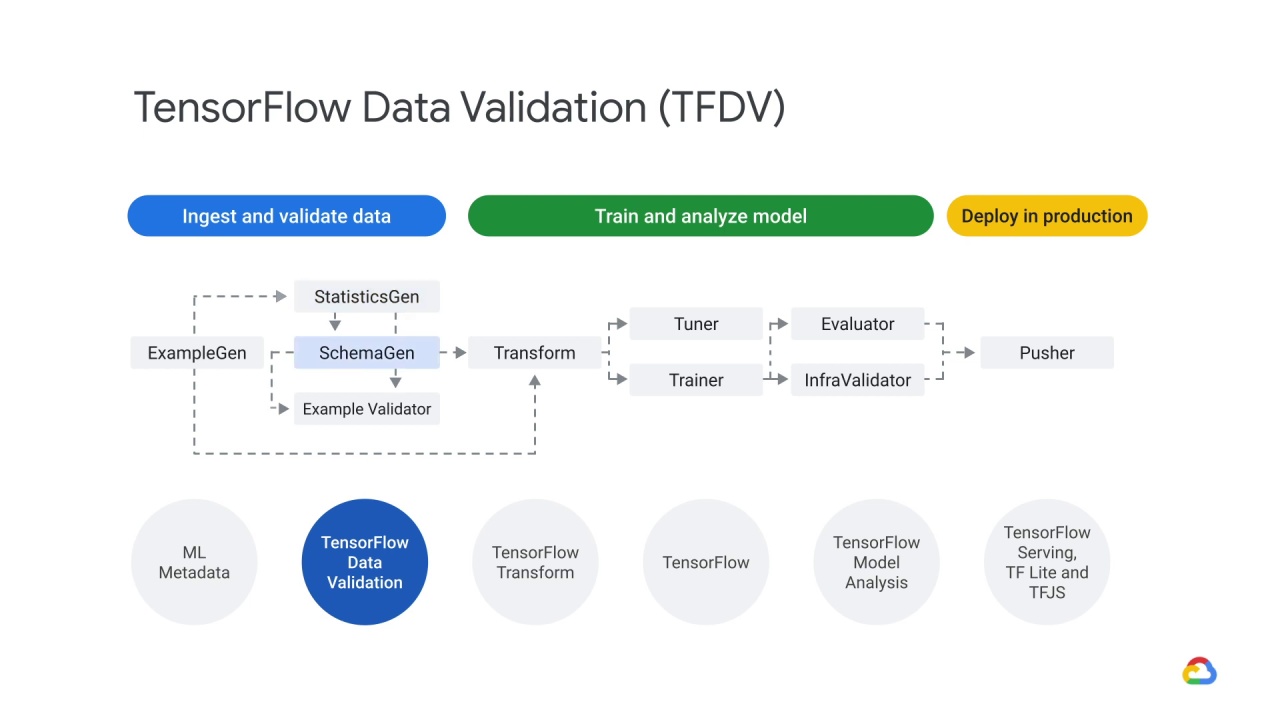
the Schema Generation component - which gives you a description of your data,
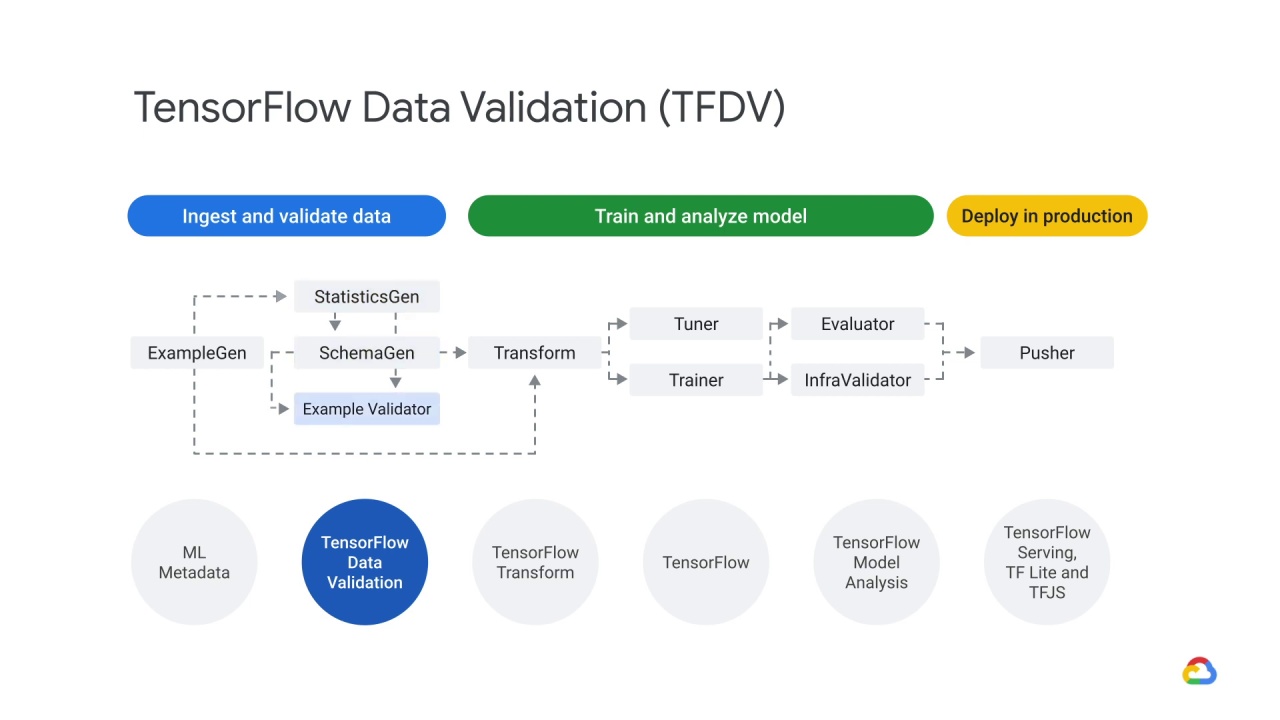
and the Example Validator component - which allows you to check for anomalies.
We’ll explore those three components in more depth, but first let’s look at our use cases for TensorFlow Data Validation so that we can understand how these components work.

There are many reasons and use cases where you may need to analyze and transform your data.
For example, when you’re missing data, such as features with empty values,
or when you have labels treated as features, so that your model gets to peek at the right answer during training.
You may also have features with values outside the range you expect

or other data anomalies.

To engineer more effective feature sets, you should identify:

Especially informative features,

redundant features,

features that vary so widely in scale that they may slow learning,

and features with little or no unique predictive information.

One use case for TensorFlow Data Validation is to validate continuously arriving data.

Let’s say on day one you generate statistics based on data from day one
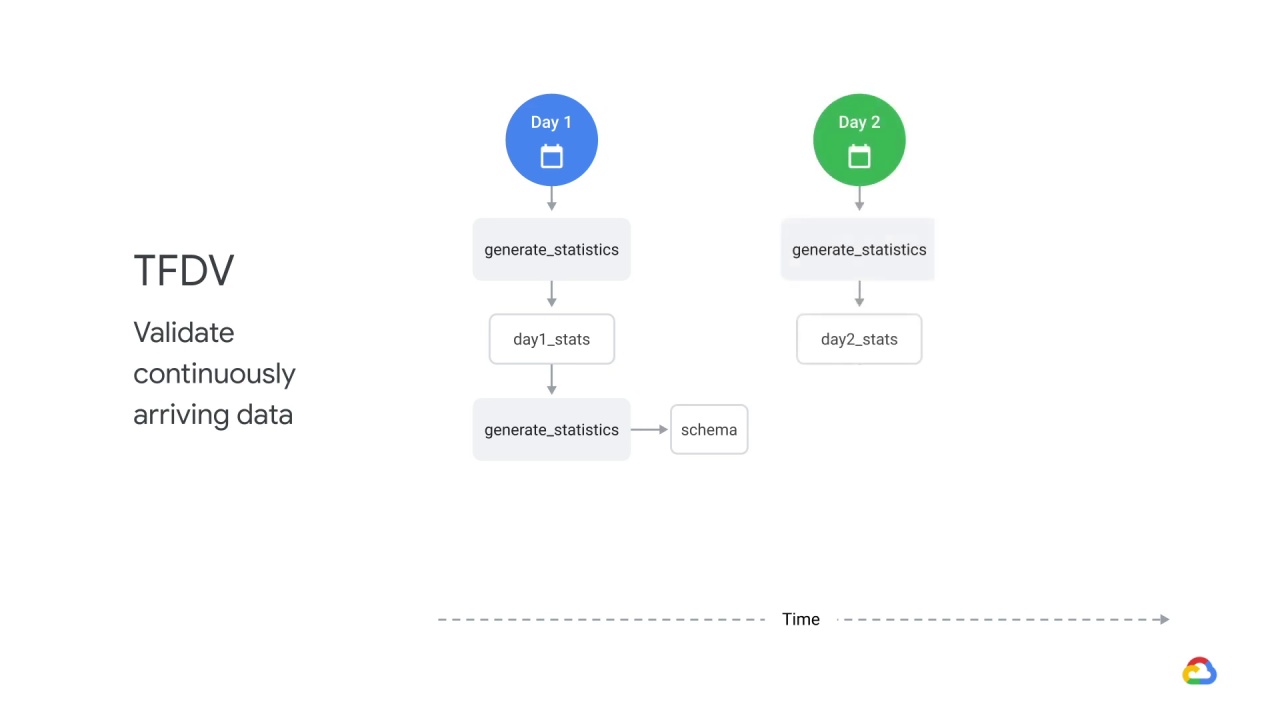
Then, you generate statistics based on day two data.
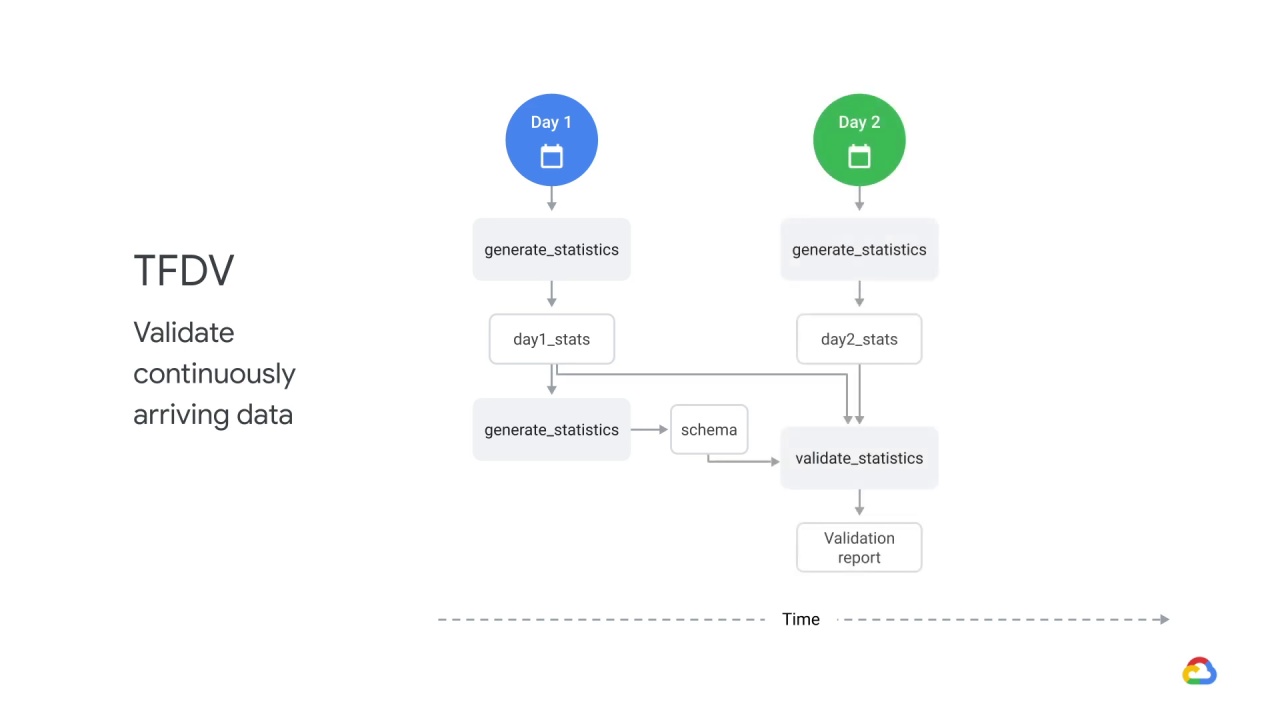
From there, you can validate Day 2 statistics against day one statistics and generate a validation report.
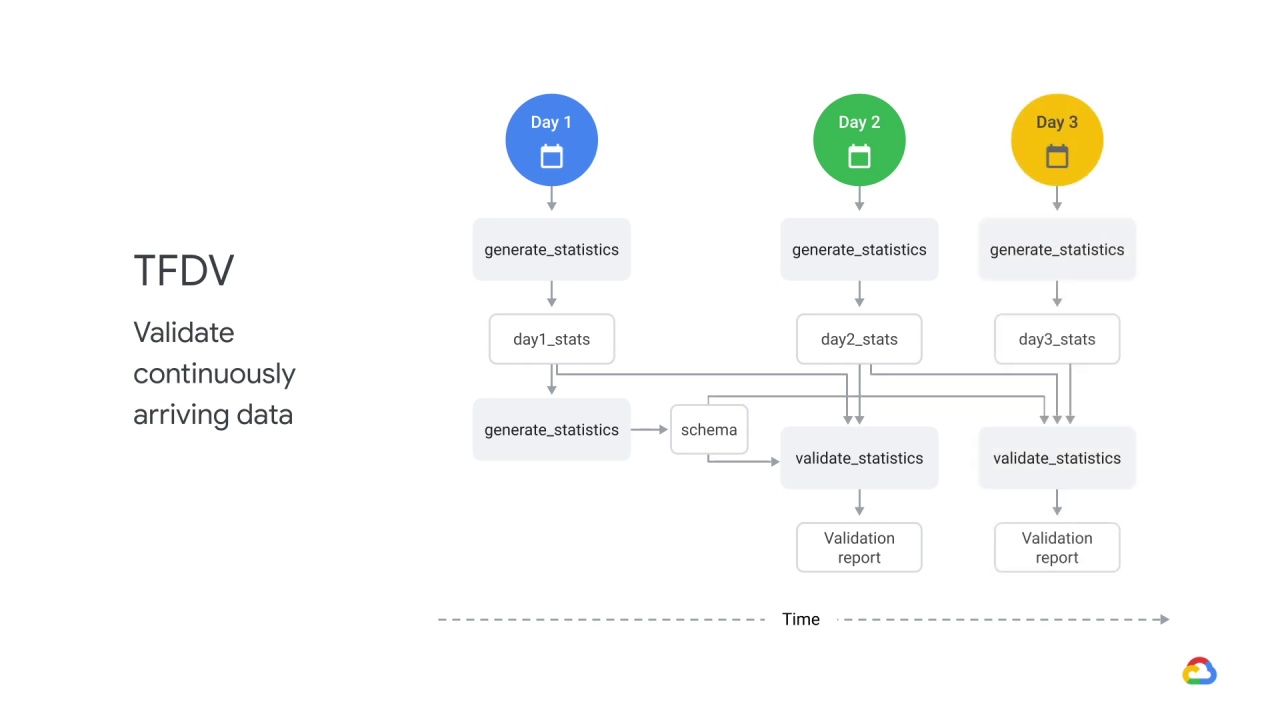
You can do the same for day three, validating day three statistics against statistics from both day two and day one.

TensorFlow Data Validation can also be used to detect distribution skew between training and serving data.
Training-serving skew

occurs when training data is generated differently from how the data used to request predictions is generated.
But what causes distribution skew?
Possible causes might come from a change in how data is handled in training vs in production, or even a faulty sampling mechanism that only chooses a subsample of the serving data to train on.
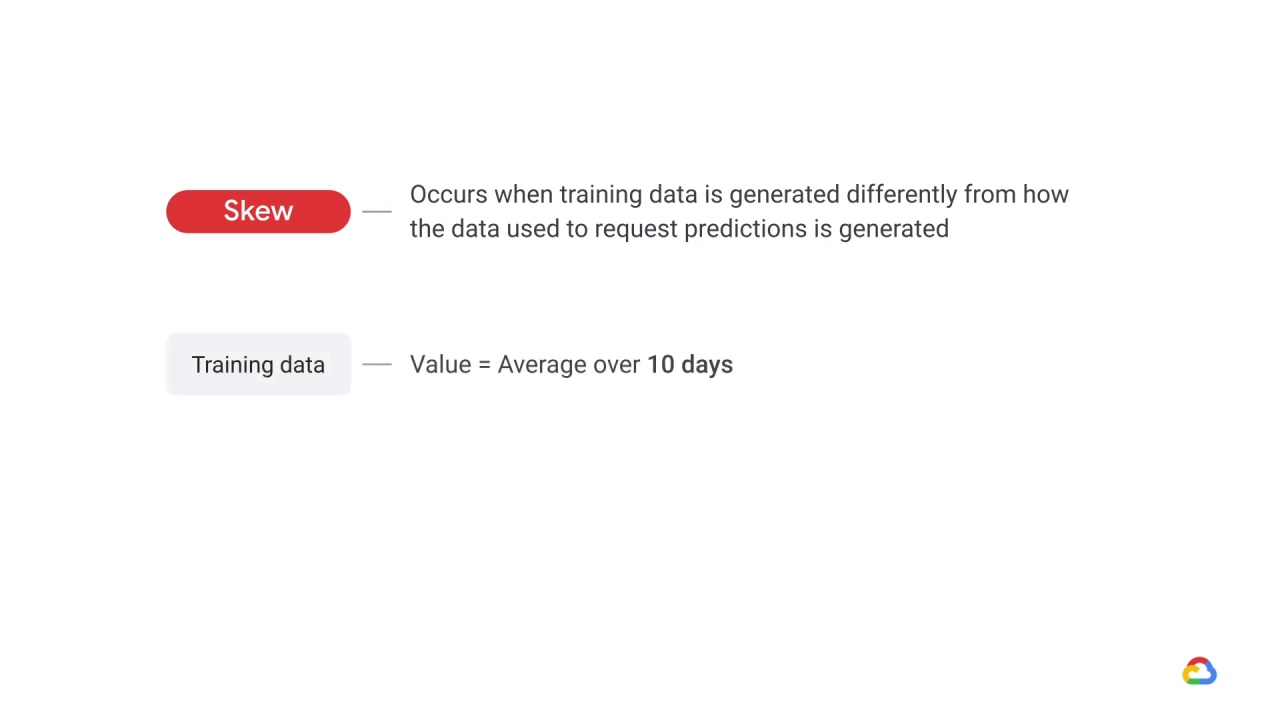
For example, if you use an average value, and for training purposes you average over 10 days,
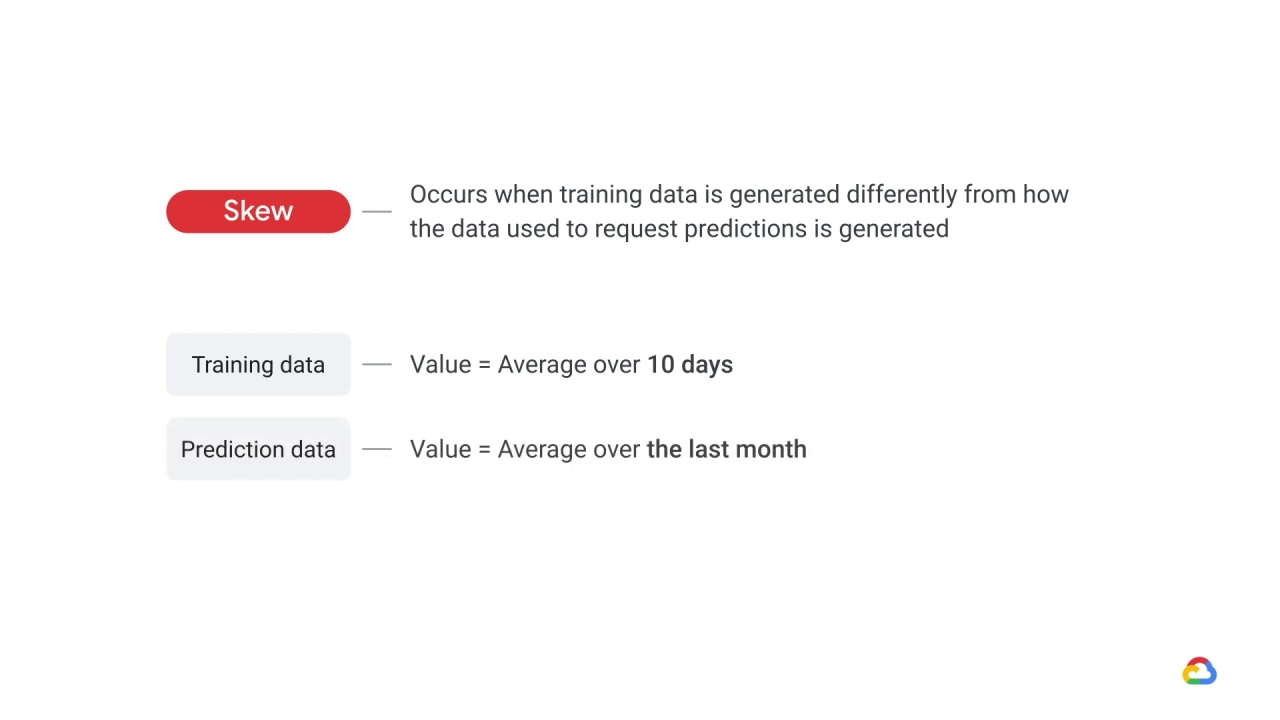
but when you request prediction, you average over the last month.
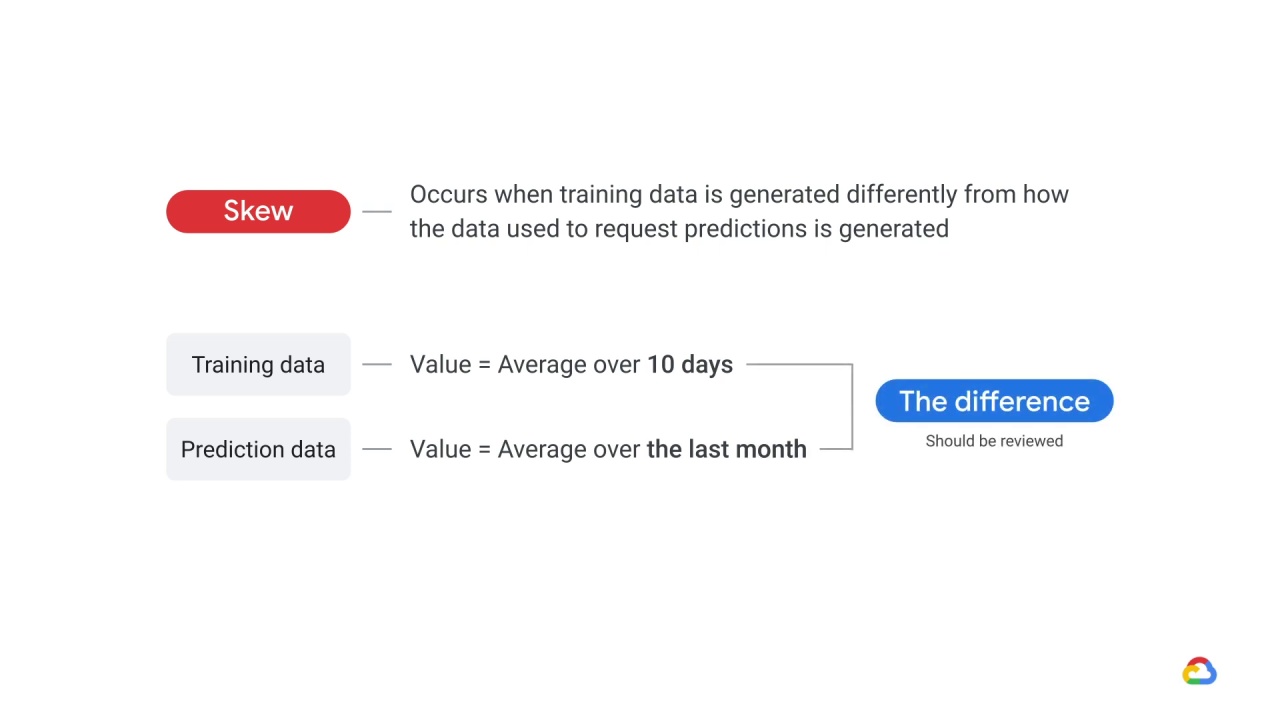
In general, any difference between how you generate your training data and your serving data (the data you use to generate predictions) should be reviewed to prevent training-serving skew.

Training-serving skew can also occur based on your data distribution in your training,
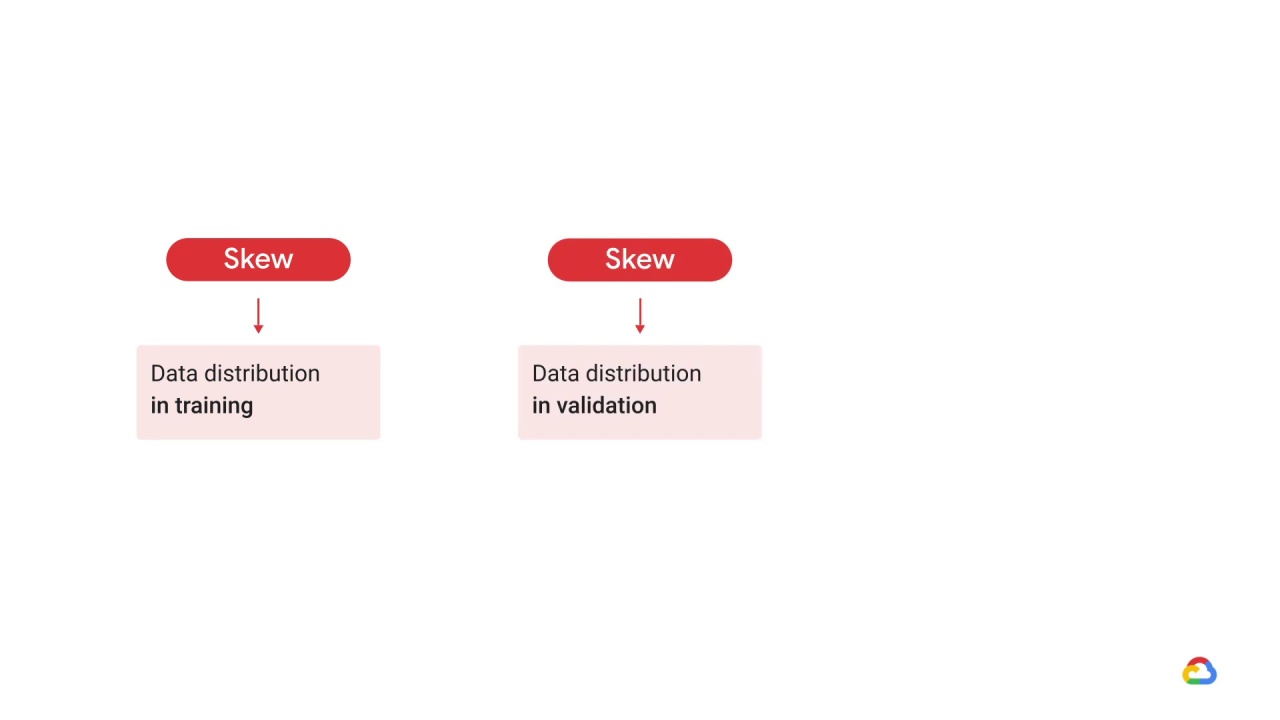
validation,
and testing data splits.

To summarize, distribution skew occurs when the distribution of feature values for training data is significantly different from serving data

and one of the key causes for distribution skew is how data is handled or changed in training vs in production.