Lab: Adapting to data


When leading a team of engineers,

many decisions are informed by

technical debt and other sorts of
cost-benefit analyses.
The best teams get very high rates of return on their investments.
With that in mind,

let’s consider a few scenarios.

Let’s imagine that you’re the leader of a team of engineers
and you are nearing the end of a code sprint.
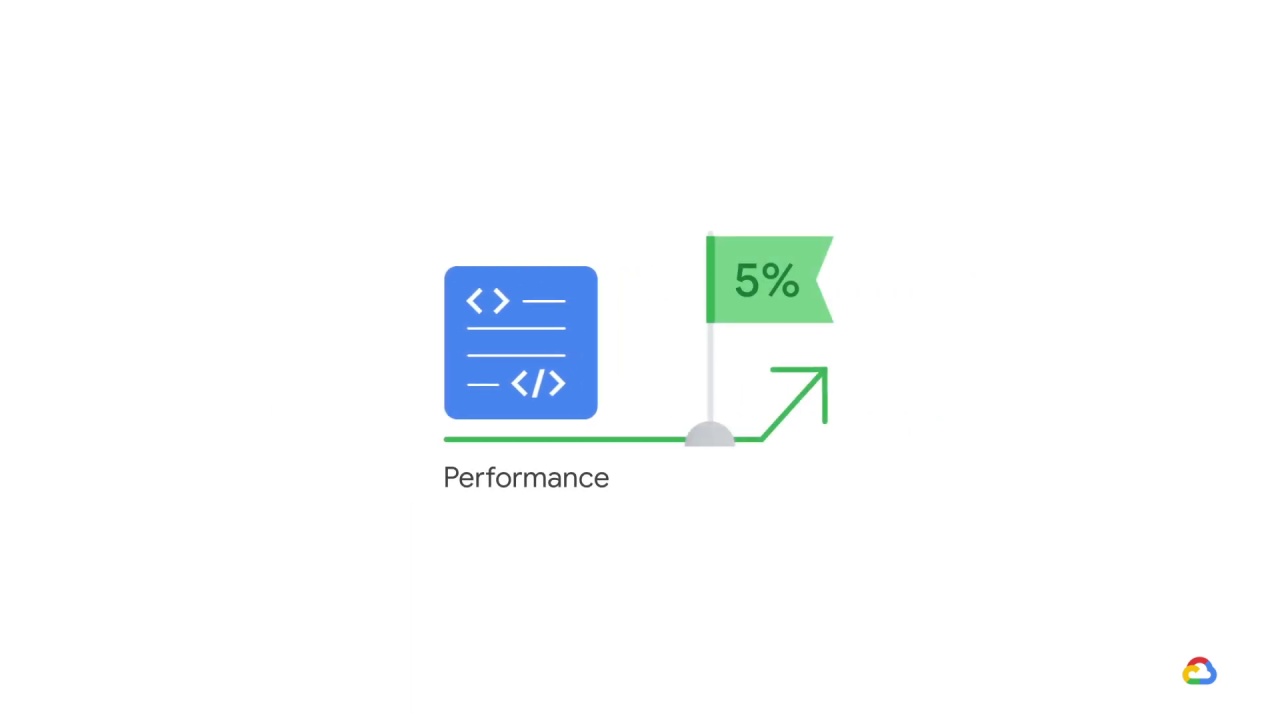
One of the team’s goals for the sprint is to increase performance on the model by 5%.

Currently, however, the best performing model is only marginally better than what was around before.
One of the engineers acknowledges this

but still insists that it’s worth spending time doing an extensive ablation analysis

where the value of an individual feature is computed by comparing it

to a model trained without it.
What might this engineer be concerned about?

The engineer might be concerned about legacy and bundled features.

Legacy features are older features that were added, because they were valuable at the time.
But since then, better features have been added, which have made them redundant without our knowledge.
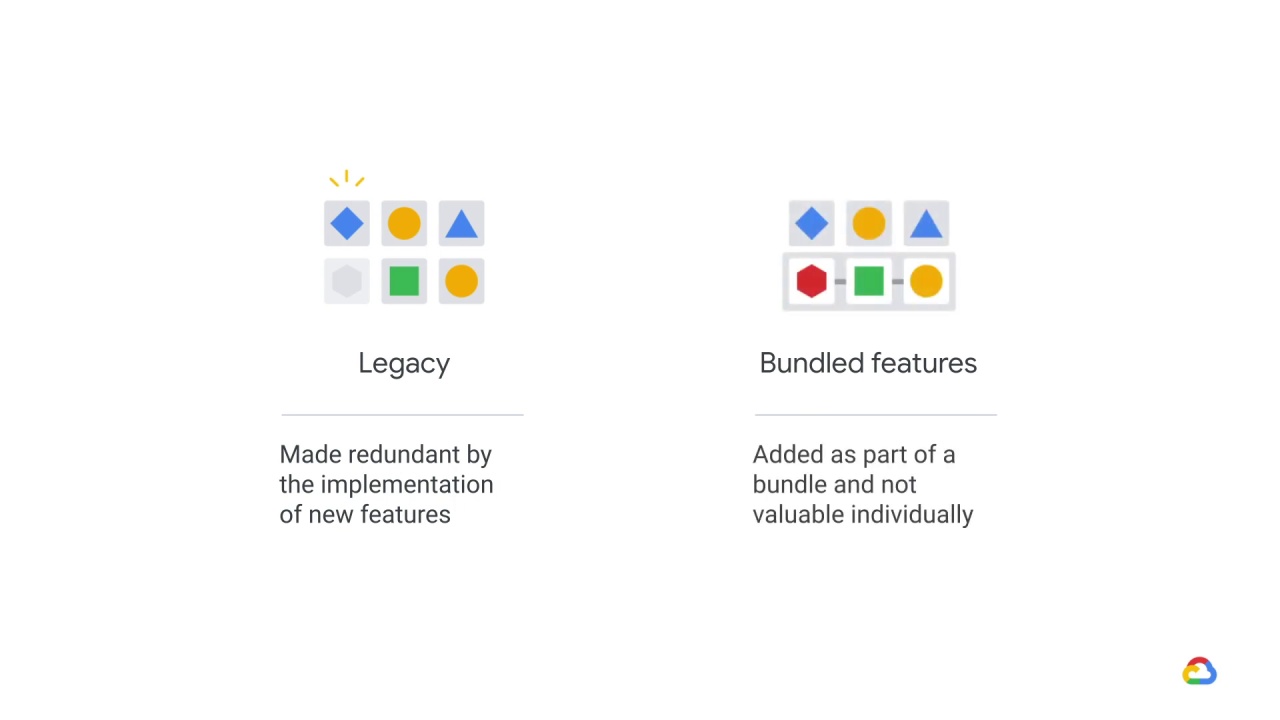
Bundled features on the other hand, are features that were added as part of a bundle, which collectively are valuable but individually may not be.
Both of these features represent additional unnecessary data dependencies.

In another scenario,

another engineer has found a new data source that is very much related to the label.
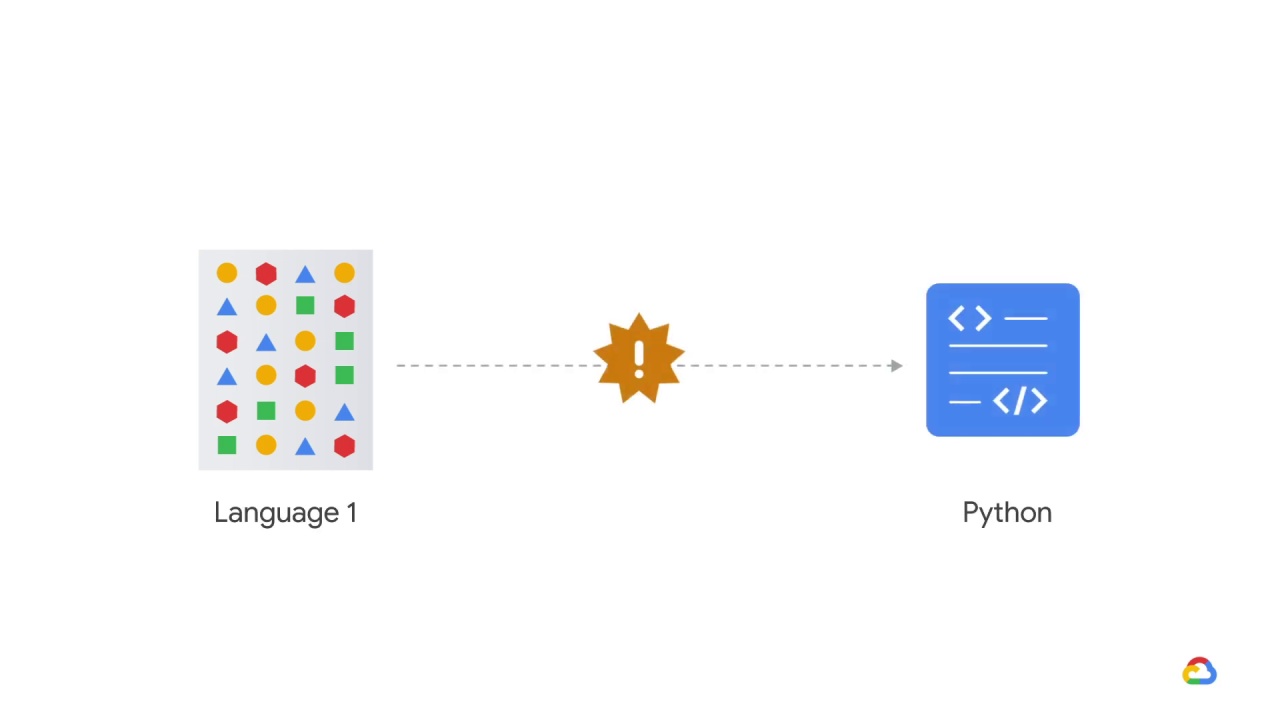
The problem is that it’s in a unique format and there’s no parser written in Python, which is what the codebase is composed of.
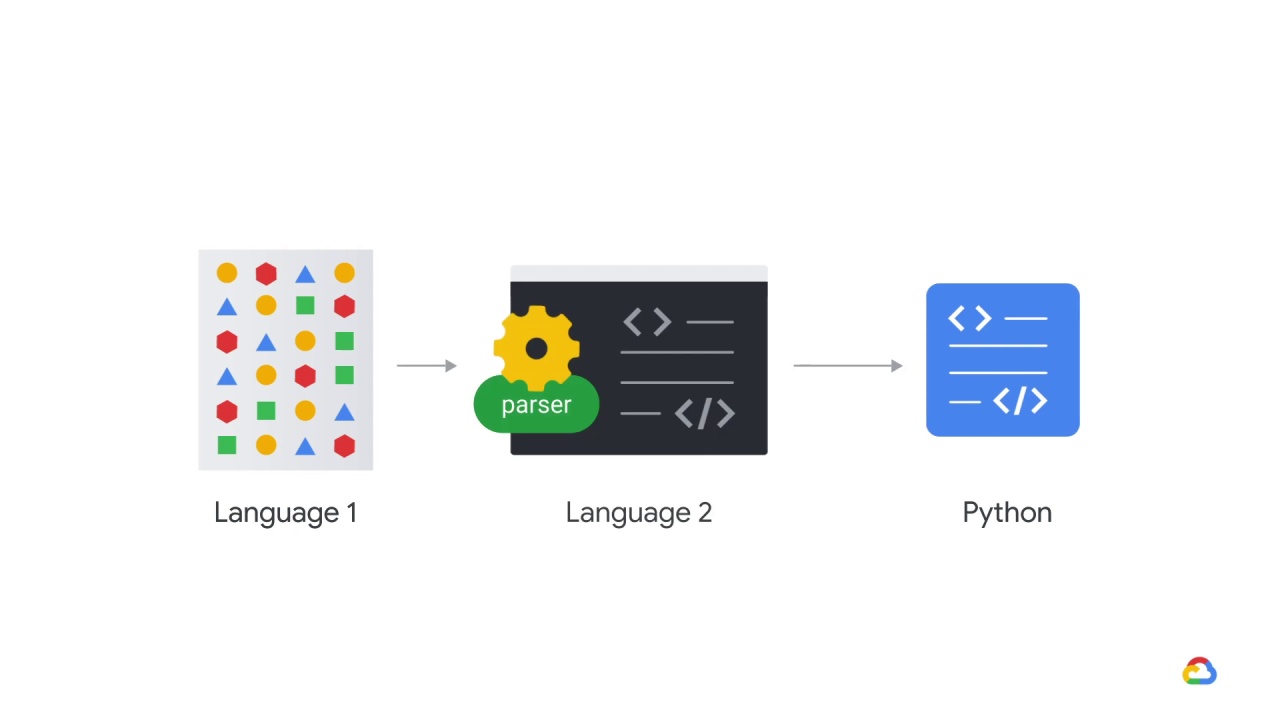
Thankfully, there is a parser on the web but it’s closed source and written in a different language.
The engineer is thinking about the model performance.

Something in the back of your mind seems wrong.
What is it? It’s the smell.
No, really! There’s a concept called
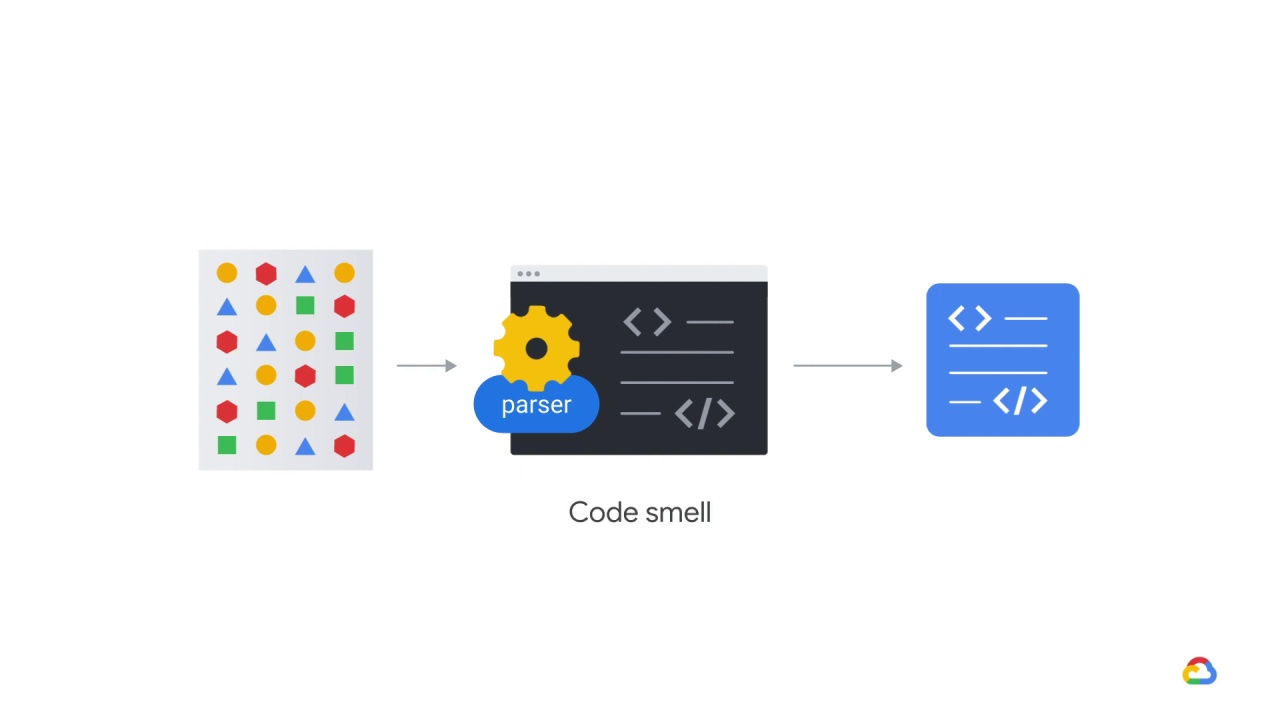
code smell and it applies in ML as well.
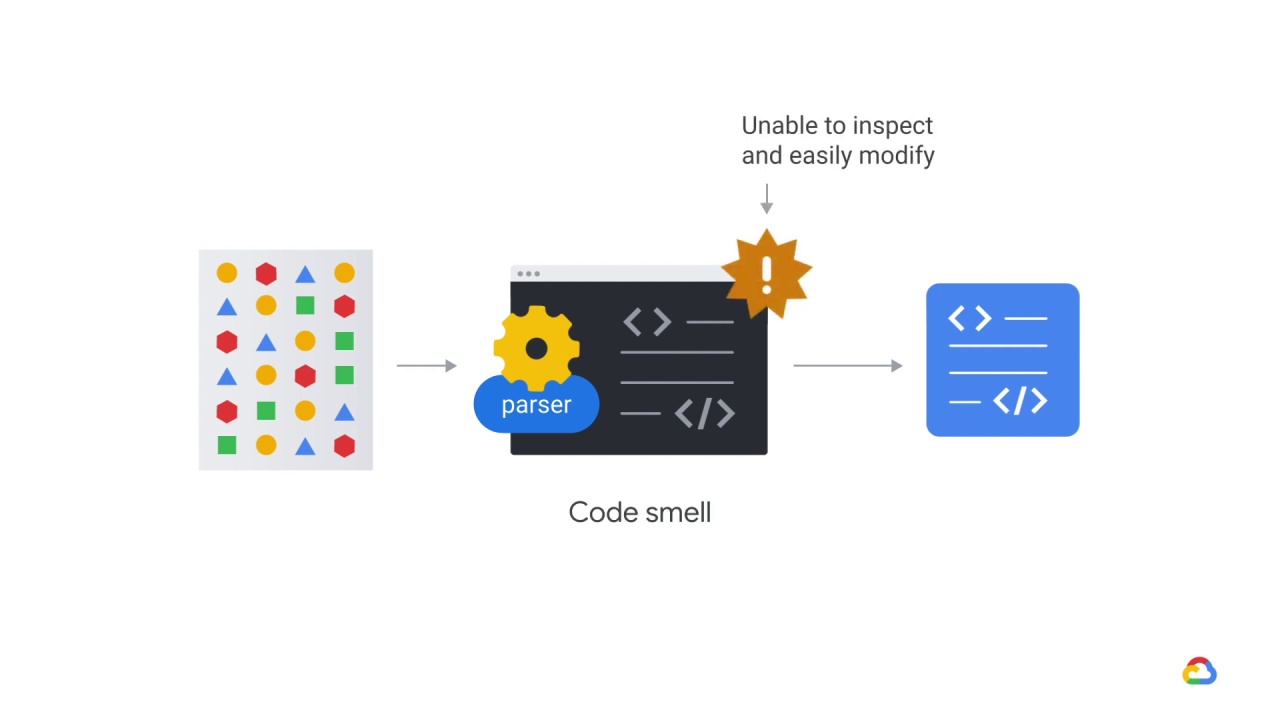
In this case, you might be thinking, “I wonder what introducing code that we can’t inspect and are unable to easily modify into our testing in production frameworks will do.”