TensorFlow distributed training strategies

Distributed training is particularly useful for very large datasets, because it becomes very difficult, and often unrealistic to perform model training on only a single hardware accelerator, such as a GPU.

TensorFlow’s distributed strategies make it easier to seamlessly scale up heavy training workloads across multiple hardware accelerators — be it GPUs or even TPUs.
But in doing so, you may face challenges.
For example:

How will you distribute the model parameters across the different devices?

How will you accumulate the gradients during backpropagation?

And how will the model parameters be updated?

tf.distribute.Strategy can help with these, and other, potential challenges.It’s a
TensorFlow API to distribute training across multiple GPUs, multiple machines or
TPUs.
And there are four TensorFlow distributed training strategies.
The list includes:

The mirrored strategy.

The multi-worker mirrored strategy.

The TPU strategy, and finally
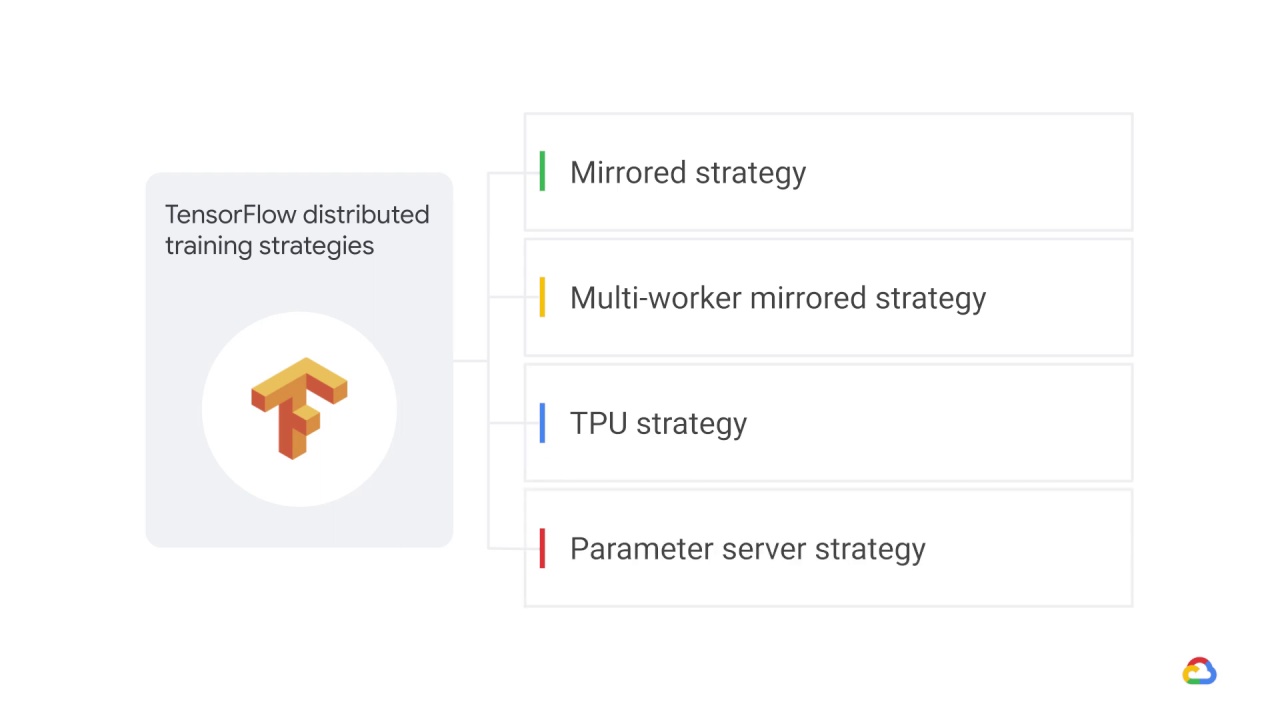
The parameter server strategy.