Automating the ML process
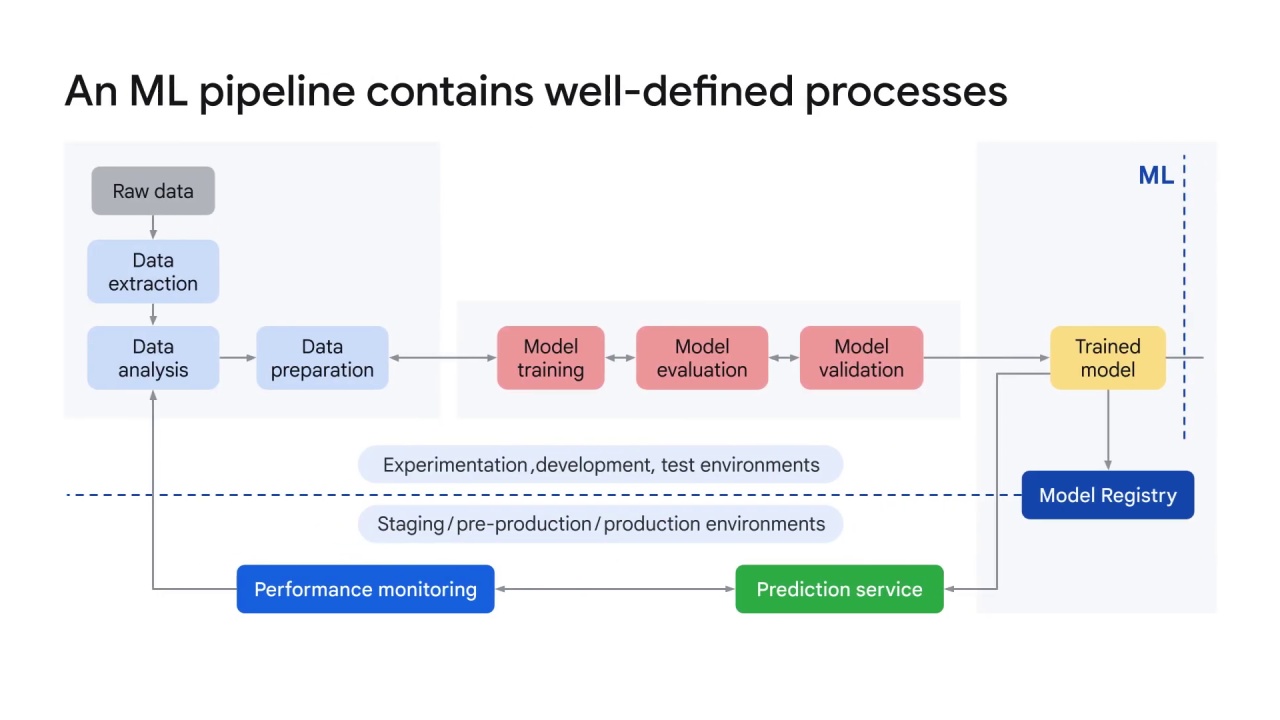
In any ML project, after you define the business use case and establish the success criteria, the process of delivering an ML model to production involves many steps.
These include:
Data extraction,
Data analysis,
Data preparation
Model training
Model evaluation
Model validation
Model serving and
Model monitoring
These steps can be completed manually or by an automatic pipeline.
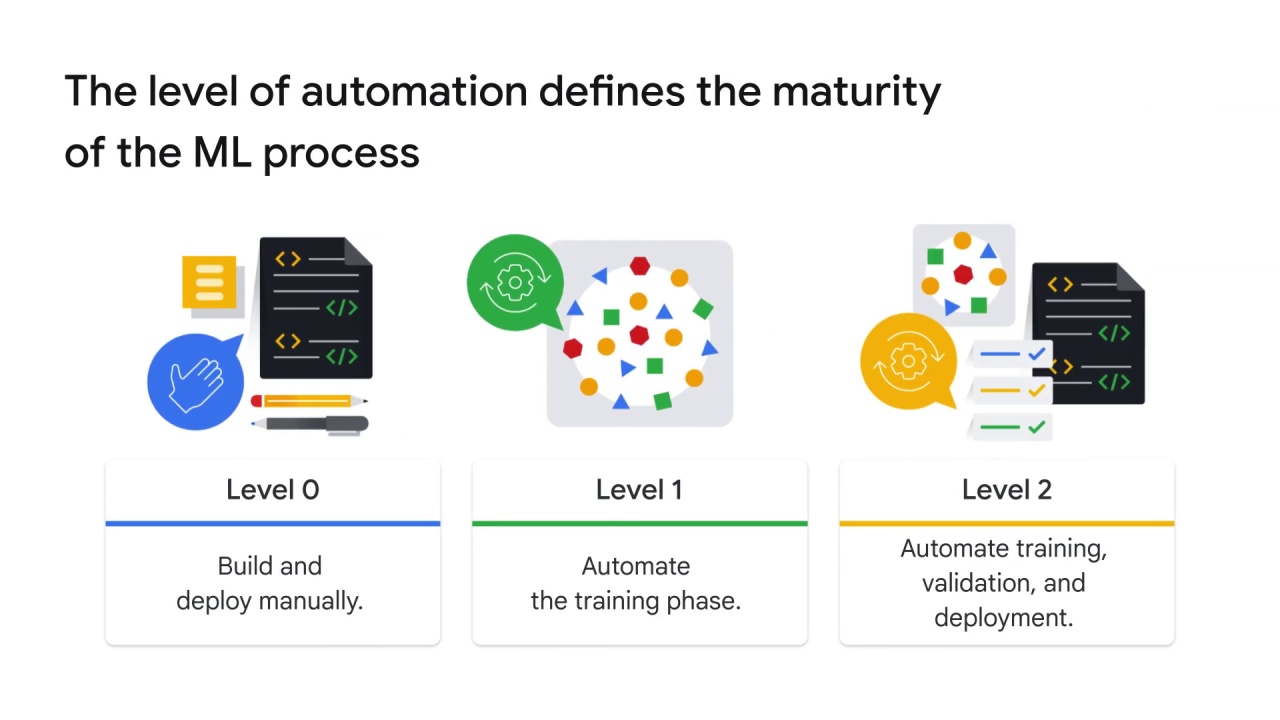
The level of automation of these steps defines the maturity of the ML process.
Many ML professionals build and deploy their models manually. This is called maturity level 0.
Other ML practitioners perform continuous training of their models by automating the ML pipeline. This is maturity level 1.
Finally, the most mature approach completely automates and integrates the ML training, validation, and deployment phases. This is maturity level 2.
Let’s look at each of these levels of automation in a little more detail.
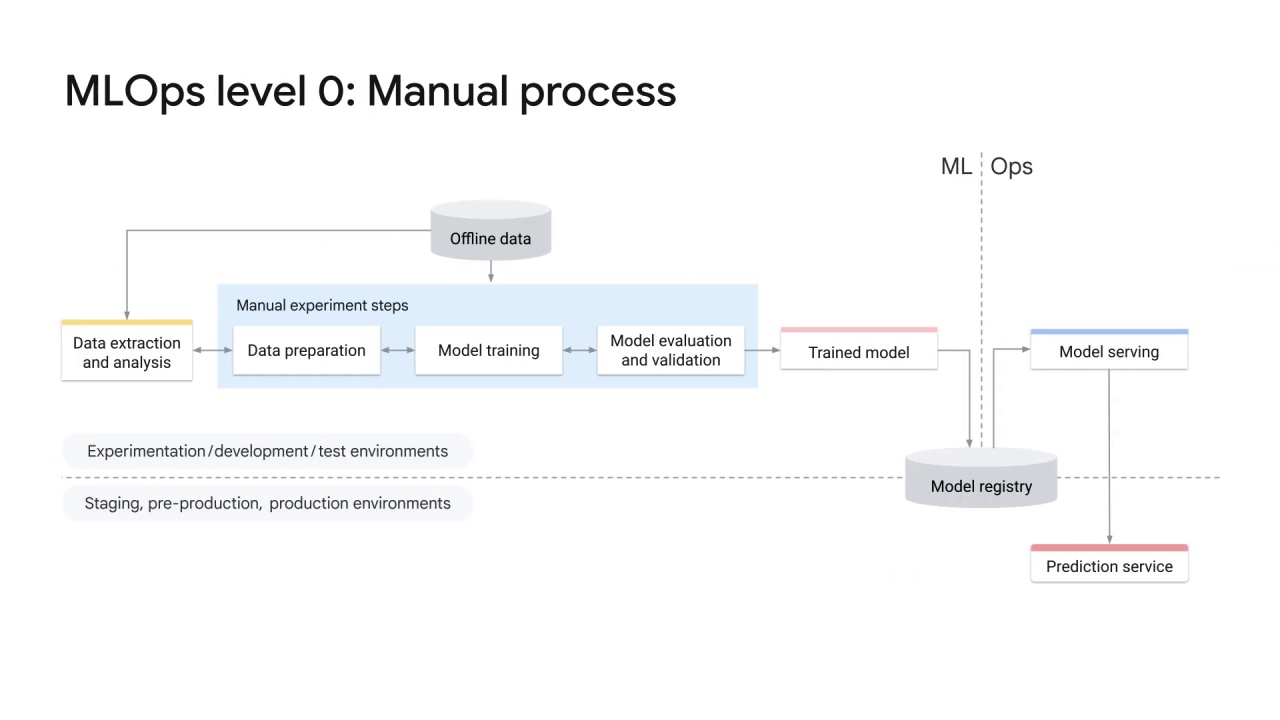
At the basic level of maturity, or level 0, many teams have data scientists and ML researchers who can build state-of-the-art models, but their process for building and deploying ML models is entirely manual.
The characteristics of MLOps level 0 are:
A manual, script-driven, and interactive process.
A disconnection between
MLand operation teams.Infrequent release iterations.
No continuous integration, continuous delivery or continuous deployment. Deployment refers to the prediction service.
And a lack of active performance monitoring.
Check the documentation to learn more about the characteristics and challenges of MLOps level 0.
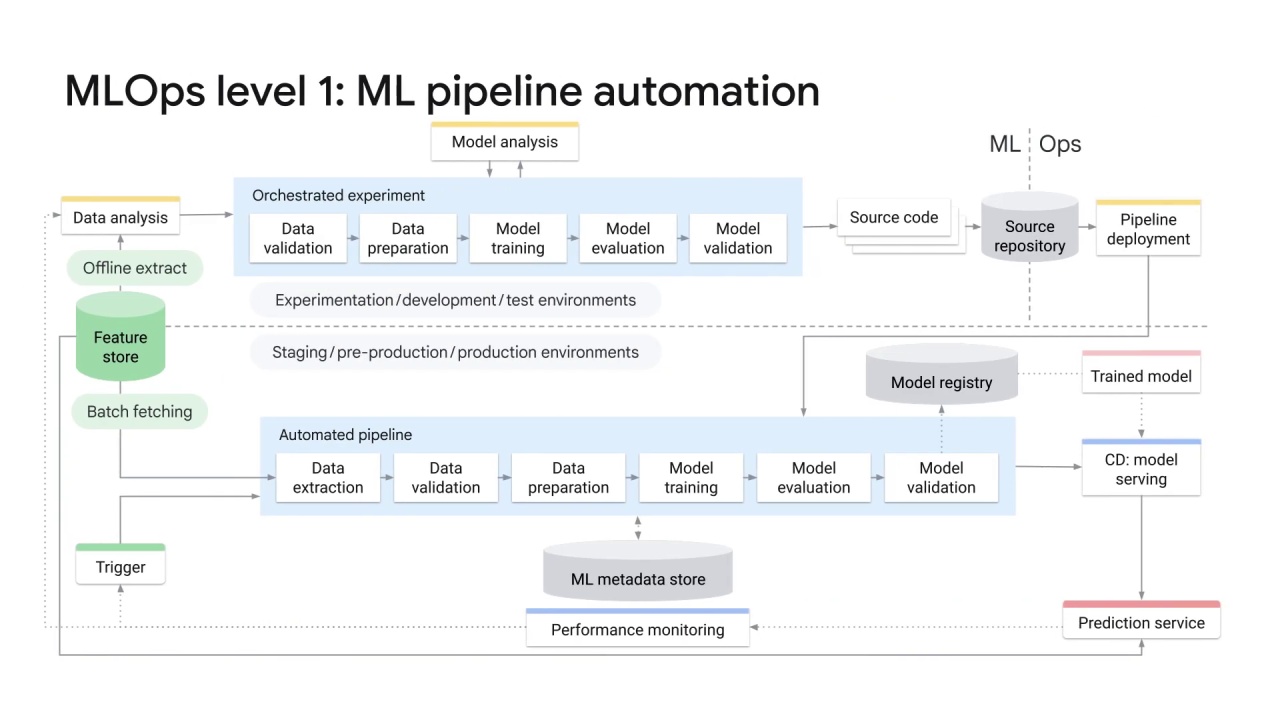
The goal of MLOps level 1 is to perform continuous training of the model by automating the ML pipeline.
This lets you achieve the continuous delivery of the model prediction service.
To automate the process of using new data to retrain models in production, you must introduce automated data and model validation steps to the pipeline, as well as pipeline triggers and metadata management.
The characteristics of MLOps level 1 are:
Rapid experiment
Continuous training of the model in production
Experimental-operational symmetry
Modularized code for components and pipelines
Continuous deployment of models, which means continuous delivery of models and automated pipeline deployment.
One important note is that to enable ML continuous training, you must to add a couple of the components, such as data and model validation, feature store, metadata management, and ML pipeline triggers to the architecture.
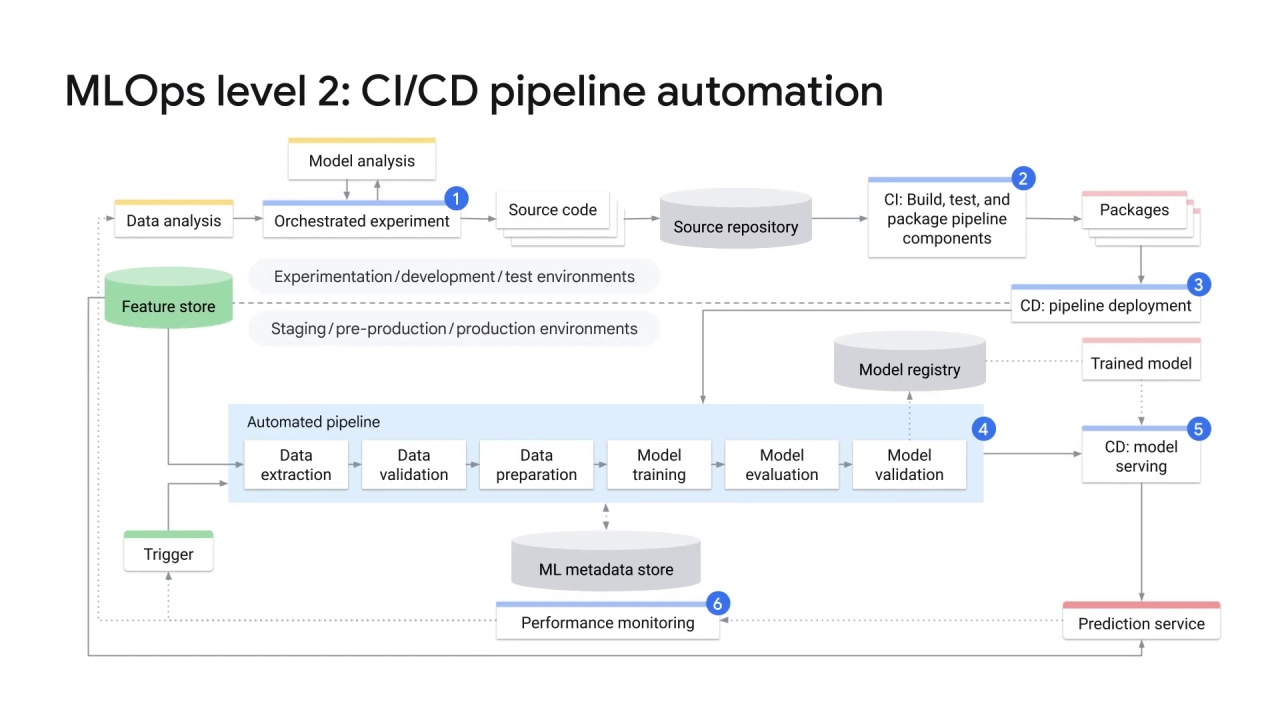
MLOps level 2 can be characterized as Continuous Integration/Continuous Deployment, or CI/CD, pipeline automation, because you need a robust automated CI/CD system for a rapid and reliable update of the pipelines in production.
This automated CI/CD system lets ML practitioners rapidly explore new ideas around feature engineering, model architecture, and hyperparameters.
MLOps level 2 achieves this automation thanks to the following components:
Source control
Test and build services
Deployment services
Model registry
Feature store
ML metadata store
ML pipeline orchestrator.
In any ML project, after you define the business use case and establish the success criteria, the process of delivering an ML model to production involves many steps.
These include:
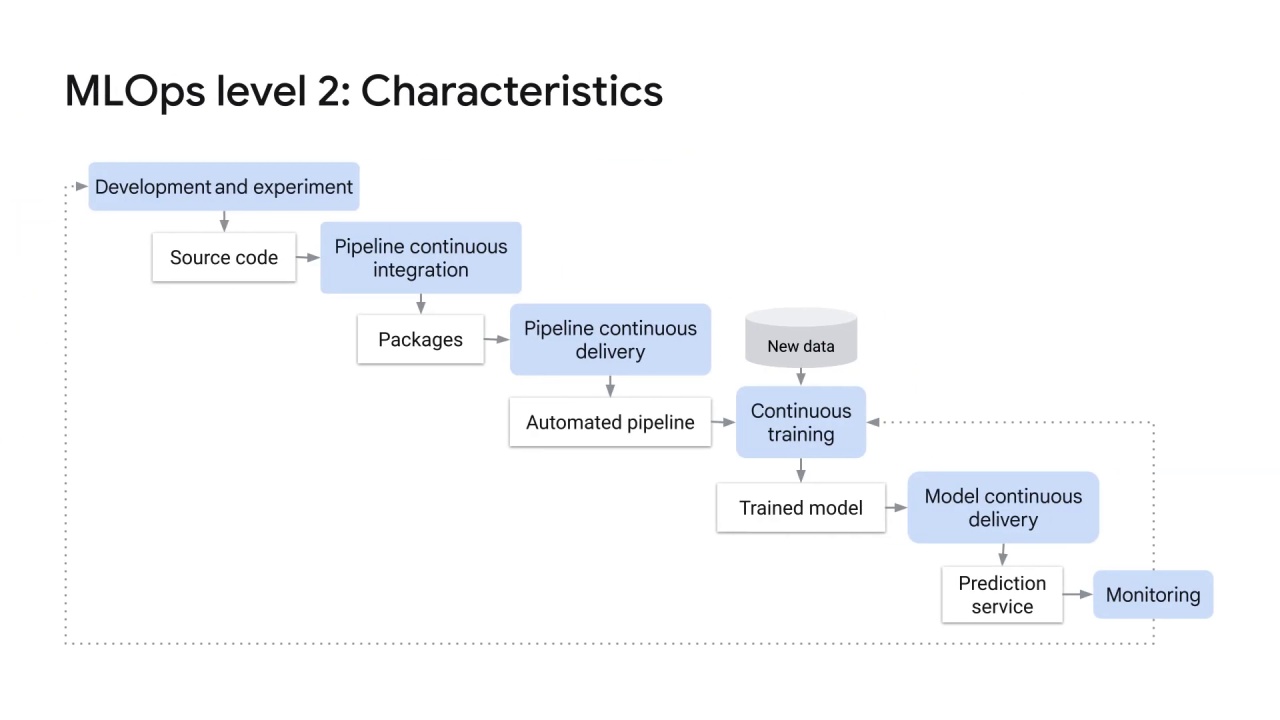
Development and experimentation: you iteratively test new ML algorithms and new modeling where the experiment steps are orchestrated.
The output of this stage is the source code of the ML pipeline steps that are then pushed to a source repository.
Then, pipeline continuous integration: you build source code and run various tests.
The outputs of this stage are pipeline components such as packages, executables, and artifacts that are deployed in a later stage.
Next is pipeline continuous delivery: you deploy the artifacts produced by the CI stage to the target environment.
The output of this stage is a deployed pipeline with the new implementation of the model.
Then there is automated triggering: the pipeline is automatically executed in production based on a schedule or in response to a trigger.
The output of this stage is a trained model that is pushed to the model registry.
The next is model continuous delivery: you serve the trained model as a prediction service for the predictions.
The output of this stage is a deployed model prediction service.
And finally, monitoring: you collect statistics on the model performance based on live data.
The output of this stage is a trigger to execute the pipeline or to execute a new experiment cycle.
These steps can be completed manually or by an automatic pipeline.
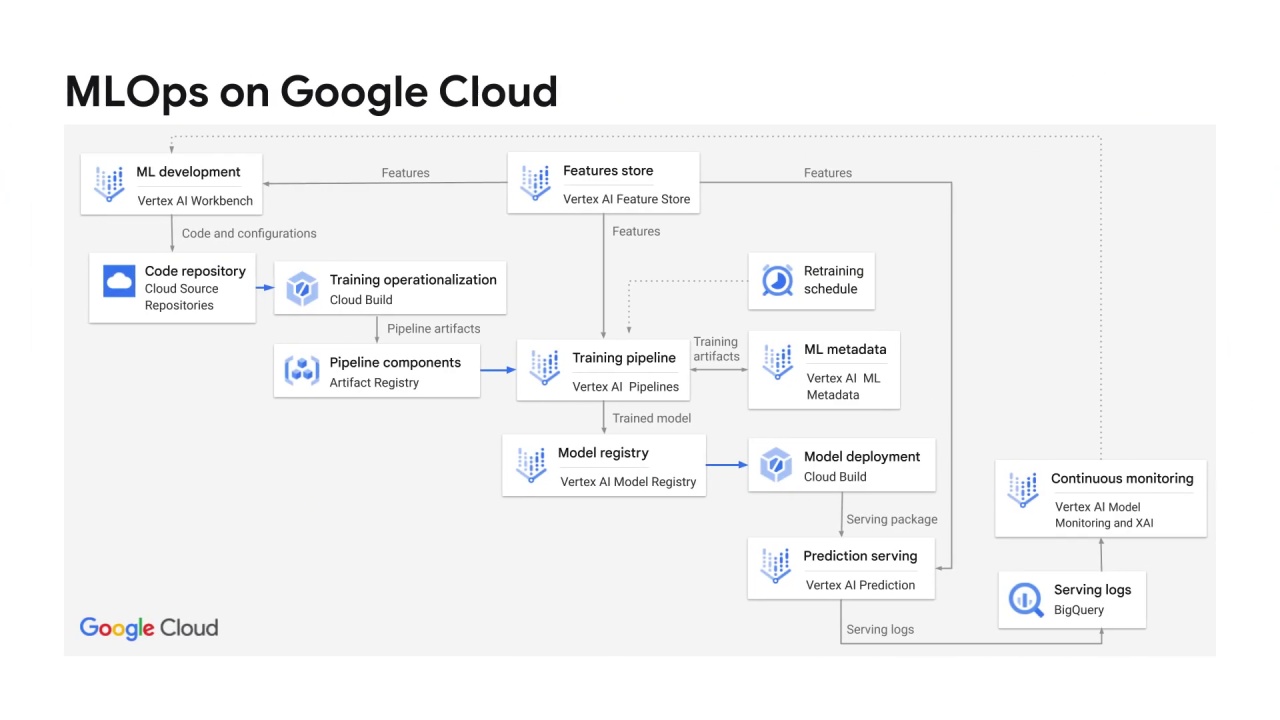
In the full stack for a machine learning system with Vertex AI, you can use:
Vertex AI Feature Store for feature store
Vertex AI Workbench for model development
Cloud Source Repositories as your code repository
Cloud Build for training operationalization
Artifact Registry for your pipeline components
Vertex AI Pipelines for your training pipeline
Vertex AI Model Registry as your model registry
Vertex AI ML Metadata for your ML metadata
Cloud Build for model deployment
Vertex AI Prediction for prediction serving
BigQuery for serving logs
Vertex AI Model Monitoring and
Vertex Explainable AI, or XAI in short, for continuous monitoring.