TPU strategy

Similar to mirrored strategy, TPU strategy uses a single machine

where the same model is replicated on each core, with its variable synchronized mirrored across each replica of the model.
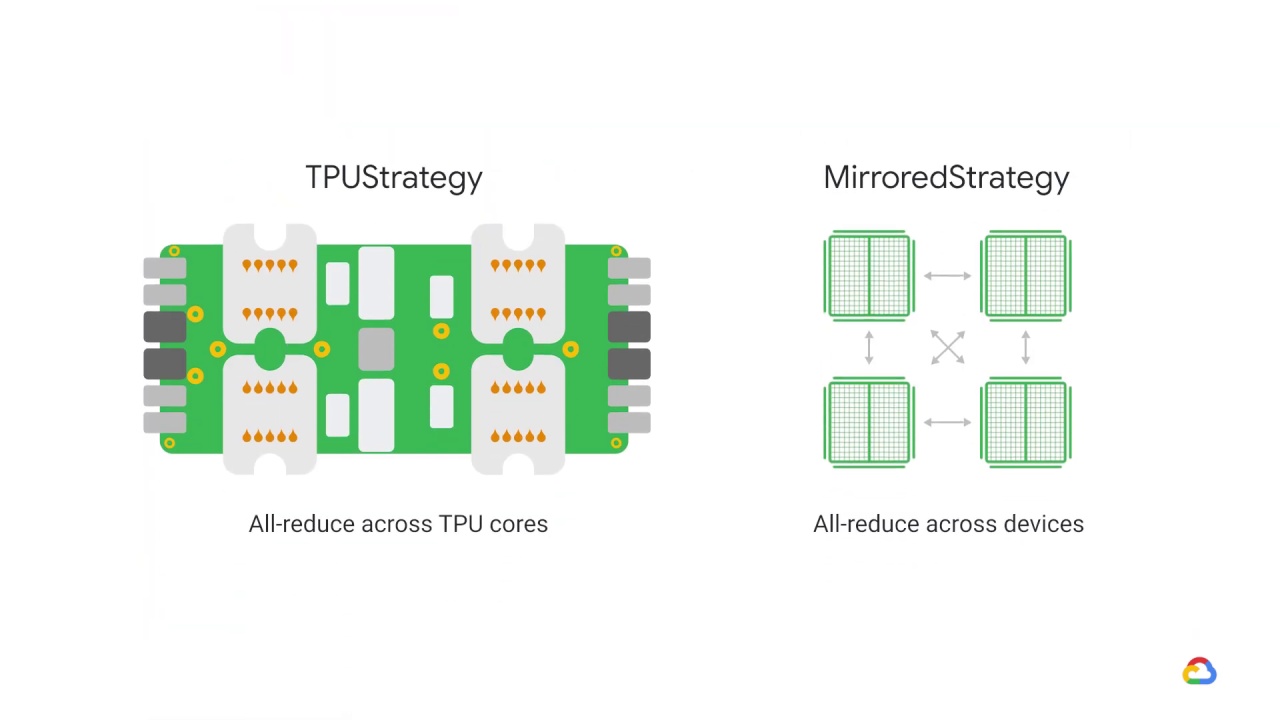
The main difference, however, is that the TPU strategy will all-reduce across TPU cores, whereas the Mirrored Strategy will all-reduce across devices.
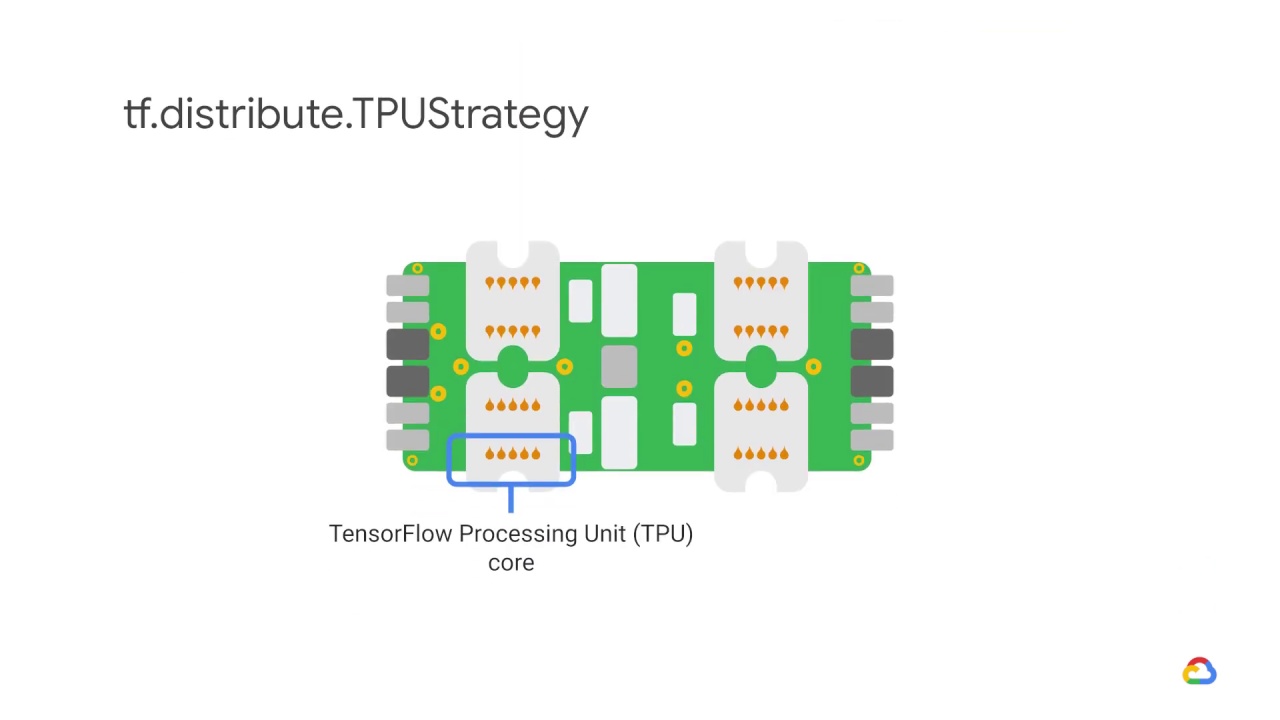
tf.distribute.TPUStrategy lets you run your TensorFlow training on Tensor Processing Units (TPUs).
TPUs are Google’s specialized ASICs designed to dramatically accelerate machine learning workloads.
TPUs provide their own implementation of efficient all-reduce and other collective operations across multiple TPU cores, which are used in TPUStrategy.

You’ll also need a variable called strategy but this time you will choose the
tf.distribute.TPUStrategy method
Because TPUs are very fast, many models ported to the TPU end up with a data bottleneck.
The TPU is sitting idle, waiting for data for the most part of each training epoch.

TPUs read training data exclusively from Google Cloud Storage (GCS).
And GCS can sustain a pretty large throughput if it is continuously streaming from multiple files in parallel.
Following best practices will optimize the throughput.
With too few files, GCS will not have enough streams to get max throughput.
With too many files, time will be wasted accessing each individual file.

Let’s summarize the distribution strategies using code.
Our base scope is a Keras sequential model.

Now, to improve training, we can use the mirrored strategy.

Or for faster training, the multi-worker mirrored strategy.

And for really fast training, the TPU strategy.