C3W2: Diving deeper into the BBC News archive
Contents
C3W2: Diving deeper into the BBC News archive#
https-deeplearning-ai/tensorflow-1-public/C3/W2/assignment/C3W2_Assignment.ipynb
Commit
1c0f65don May 20, 2022 - Compare
import csv
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import matplotlib.pyplot as plt
with open("./bbc-text.csv", 'r') as csvfile:
print(f"First line (header) looks like this:\n\n{csvfile.readline()}")
print(f"Each data point looks like this:\n\n{csvfile.readline()}")
First line (header) looks like this:
category,text
Each data point looks like this:
tech,tv future in the hands of viewers with home theatre systems plasma high-definition tvs and digital video recorders moving into the living room the way people watch tv will be radically different in five years time. that is according to an expert panel which gathered at the annual consumer electronics show in las vegas to discuss how these new technologies will impact one of our favourite pastimes. with the us leading the trend programmes and other content will be delivered to viewers via home networks through cable satellite telecoms companies and broadband service providers to front rooms and portable devices. one of the most talked-about technologies of ces has been digital and personal video recorders (dvr and pvr). these set-top boxes like the us s tivo and the uk s sky+ system allow people to record store play pause and forward wind tv programmes when they want. essentially the technology allows for much more personalised tv. they are also being built-in to high-definition tv sets which are big business in japan and the us but slower to take off in europe because of the lack of high-definition programming. not only can people forward wind through adverts they can also forget about abiding by network and channel schedules putting together their own a-la-carte entertainment. but some us networks and cable and satellite companies are worried about what it means for them in terms of advertising revenues as well as brand identity and viewer loyalty to channels. although the us leads in this technology at the moment it is also a concern that is being raised in europe particularly with the growing uptake of services like sky+. what happens here today we will see in nine months to a years time in the uk adam hume the bbc broadcast s futurologist told the bbc news website. for the likes of the bbc there are no issues of lost advertising revenue yet. it is a more pressing issue at the moment for commercial uk broadcasters but brand loyalty is important for everyone. we will be talking more about content brands rather than network brands said tim hanlon from brand communications firm starcom mediavest. the reality is that with broadband connections anybody can be the producer of content. he added: the challenge now is that it is hard to promote a programme with so much choice. what this means said stacey jolna senior vice president of tv guide tv group is that the way people find the content they want to watch has to be simplified for tv viewers. it means that networks in us terms or channels could take a leaf out of google s book and be the search engine of the future instead of the scheduler to help people find what they want to watch. this kind of channel model might work for the younger ipod generation which is used to taking control of their gadgets and what they play on them. but it might not suit everyone the panel recognised. older generations are more comfortable with familiar schedules and channel brands because they know what they are getting. they perhaps do not want so much of the choice put into their hands mr hanlon suggested. on the other end you have the kids just out of diapers who are pushing buttons already - everything is possible and available to them said mr hanlon. ultimately the consumer will tell the market they want. of the 50 000 new gadgets and technologies being showcased at ces many of them are about enhancing the tv-watching experience. high-definition tv sets are everywhere and many new models of lcd (liquid crystal display) tvs have been launched with dvr capability built into them instead of being external boxes. one such example launched at the show is humax s 26-inch lcd tv with an 80-hour tivo dvr and dvd recorder. one of the us s biggest satellite tv companies directtv has even launched its own branded dvr at the show with 100-hours of recording capability instant replay and a search function. the set can pause and rewind tv for up to 90 hours. and microsoft chief bill gates announced in his pre-show keynote speech a partnership with tivo called tivotogo which means people can play recorded programmes on windows pcs and mobile devices. all these reflect the increasing trend of freeing up multimedia so that people can watch what they want when they want.
NUM_WORDS = 1000
EMBEDDING_DIM = 16
MAXLEN = 120
PADDING = 'post'
OOV_TOKEN = "<OOV>"
TRAINING_SPLIT = .8
Loading and pre-processing the data#
def remove_stopwords(sentence):
"""
Removes a list of stopwords
Args:
sentence (string): sentence to remove the stopwords from
Returns:
sentence (string): lowercase sentence without the stopwords
"""
# List of stopwords
stopwords = ["a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as", "at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has", "have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself", "his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself", "let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours", "ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that", "that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll", "they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll", "we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom", "why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
# Sentence converted to lowercase-only
sentence = sentence.lower()
words = sentence.split()
no_words = [w for w in words if w not in stopwords]
sentence = " ".join(no_words)
return sentence
def parse_data_from_file(filename):
"""
Extracts sentences and labels from a CSV file
Args:
filename (string): path to the CSV file
Returns:
sentences, labels (list of string, list of string): tuple containing lists of sentences and labels
"""
sentences = []
labels = []
with open(filename, 'r') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader)
for row in reader:
labels.append(row[0])
sentence = row[1]
sentence = remove_stopwords(sentence)
sentences.append(sentence)
return sentences, labels
sentences, labels = parse_data_from_file("./bbc-text.csv")
print(f"There are {len(sentences)} sentences in the dataset.\n")
print(f"First sentence has {len(sentences[0].split())} words (after removing stopwords).\n")
print(f"There are {len(labels)} labels in the dataset.\n")
print(f"The first 5 labels are {labels[:5]}")
There are 2225 sentences in the dataset.
First sentence has 436 words (after removing stopwords).
There are 2225 labels in the dataset.
The first 5 labels are ['tech', 'business', 'sport', 'sport', 'entertainment']
Training - Validation Split#
def train_val_split(sentences, labels, training_split):
train_size = int(len(sentences) * training_split)
train_sentences = sentences[:train_size]
train_labels = labels[:train_size]
validation_sentences = sentences[train_size:]
validation_labels = labels[train_size:]
return train_sentences, validation_sentences, train_labels, validation_labels
train_sentences, val_sentences, train_labels, val_labels = train_val_split(sentences, labels, TRAINING_SPLIT)
print(f"There are {len(train_sentences)} sentences for training.\n")
print(f"There are {len(train_labels)} labels for training.\n")
print(f"There are {len(val_sentences)} sentences for validation.\n")
print(f"There are {len(val_labels)} labels for validation.")
There are 1780 sentences for training.
There are 1780 labels for training.
There are 445 sentences for validation.
There are 445 labels for validation.
Tokenization - Sequences and padding#
def fit_tokenizer(train_sentences, num_words, oov_token):
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(train_sentences)
return tokenizer
tokenizer = fit_tokenizer(train_sentences, NUM_WORDS, OOV_TOKEN)
word_index = tokenizer.word_index
print(f"Vocabulary contains {len(word_index)} words\n")
print("<OOV> token included in vocabulary" if "<OOV>" in word_index else "<OOV> token NOT included in vocabulary")
Vocabulary contains 27285 words
<OOV> token included in vocabulary
def seq_and_pad(sentences, tokenizer, padding, maxlen):
sequences = tokenizer.texts_to_sequences(sentences)
padded_sequences = pad_sequences(sequences, padding=padding, maxlen=maxlen)
return padded_sequences
train_padded_seq = seq_and_pad(train_sentences, tokenizer, PADDING, MAXLEN)
val_padded_seq = seq_and_pad(val_sentences, tokenizer, PADDING, MAXLEN)
print(f"Padded training sequences have shape: {train_padded_seq.shape}\n")
print(f"Padded validation sequences have shape: {val_padded_seq.shape}")
Padded training sequences have shape: (1780, 120)
Padded validation sequences have shape: (445, 120)
def tokenize_labels(all_labels, split_labels):
label_tokenizer = Tokenizer()
label_tokenizer.fit_on_texts(all_labels)
label_seq = label_tokenizer.texts_to_sequences(split_labels)
label_seq_np = np.array(label_seq) - 1
return label_seq_np
train_label_seq = tokenize_labels(labels, train_labels)
val_label_seq = tokenize_labels(labels, val_labels)
print(f"First 5 labels of the training set should look like this:\n{train_label_seq[:5]}\n")
print(f"First 5 labels of the validation set should look like this:\n{val_label_seq[:5]}\n")
print(f"Tokenized labels of the training set have shape: {train_label_seq.shape}\n")
print(f"Tokenized labels of the validation set have shape: {val_label_seq.shape}\n")
First 5 labels of the training set should look like this:
[[3]
[1]
[0]
[0]
[4]]
First 5 labels of the validation set should look like this:
[[4]
[3]
[2]
[0]
[0]]
Tokenized labels of the training set have shape: (1780, 1)
Tokenized labels of the validation set have shape: (445, 1)
Selecting the model for text classification#
def create_model(num_words, embedding_dim, maxlen):
tf.random.set_seed(123)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(num_words, embedding_dim, input_length=maxlen),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model = create_model(NUM_WORDS, EMBEDDING_DIM, MAXLEN)
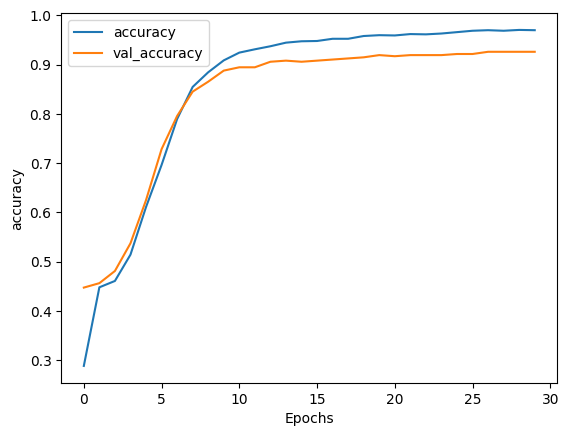
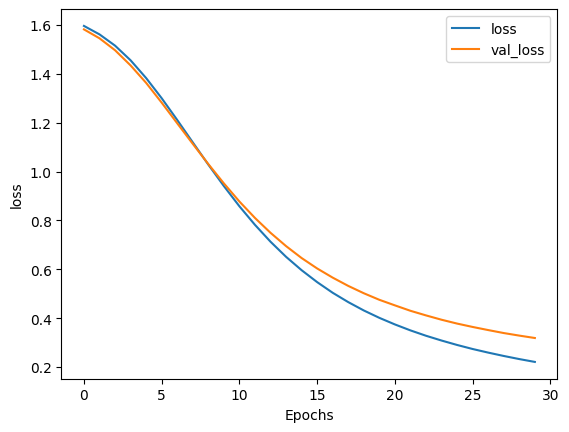
history = model.fit(train_padded_seq, train_label_seq, epochs=30, validation_data=(val_padded_seq, val_label_seq))
Epoch 1/30
56/56 [==============================] - 2s 16ms/step - loss: 1.5959 - accuracy: 0.2882 - val_loss: 1.5818 - val_accuracy: 0.4472
Epoch 2/30
56/56 [==============================] - 1s 11ms/step - loss: 1.5613 - accuracy: 0.4478 - val_loss: 1.5453 - val_accuracy: 0.4562
Epoch 3/30
56/56 [==============================] - 1s 10ms/step - loss: 1.5152 - accuracy: 0.4607 - val_loss: 1.4965 - val_accuracy: 0.4809
Epoch 4/30
56/56 [==============================] - 1s 10ms/step - loss: 1.4552 - accuracy: 0.5140 - val_loss: 1.4343 - val_accuracy: 0.5371
Epoch 5/30
56/56 [==============================] - 1s 10ms/step - loss: 1.3825 - accuracy: 0.6107 - val_loss: 1.3628 - val_accuracy: 0.6247
Epoch 6/30
56/56 [==============================] - 1s 11ms/step - loss: 1.3001 - accuracy: 0.6961 - val_loss: 1.2819 - val_accuracy: 0.7281
Epoch 7/30
56/56 [==============================] - 1s 10ms/step - loss: 1.2110 - accuracy: 0.7893 - val_loss: 1.1974 - val_accuracy: 0.7955
Epoch 8/30
56/56 [==============================] - 1s 10ms/step - loss: 1.1194 - accuracy: 0.8545 - val_loss: 1.1134 - val_accuracy: 0.8449
Epoch 9/30
56/56 [==============================] - 1s 10ms/step - loss: 1.0283 - accuracy: 0.8843 - val_loss: 1.0306 - val_accuracy: 0.8652
Epoch 10/30
56/56 [==============================] - 1s 9ms/step - loss: 0.9407 - accuracy: 0.9084 - val_loss: 0.9516 - val_accuracy: 0.8876
Epoch 11/30
56/56 [==============================] - 1s 11ms/step - loss: 0.8579 - accuracy: 0.9242 - val_loss: 0.8774 - val_accuracy: 0.8944
Epoch 12/30
56/56 [==============================] - 1s 10ms/step - loss: 0.7820 - accuracy: 0.9309 - val_loss: 0.8102 - val_accuracy: 0.8944
Epoch 13/30
56/56 [==============================] - 1s 10ms/step - loss: 0.7130 - accuracy: 0.9371 - val_loss: 0.7494 - val_accuracy: 0.9056
Epoch 14/30
56/56 [==============================] - 1s 13ms/step - loss: 0.6512 - accuracy: 0.9444 - val_loss: 0.6950 - val_accuracy: 0.9079
Epoch 15/30
56/56 [==============================] - 1s 10ms/step - loss: 0.5965 - accuracy: 0.9472 - val_loss: 0.6462 - val_accuracy: 0.9056
Epoch 16/30
56/56 [==============================] - 1s 10ms/step - loss: 0.5476 - accuracy: 0.9478 - val_loss: 0.6035 - val_accuracy: 0.9079
Epoch 17/30
56/56 [==============================] - 1s 10ms/step - loss: 0.5040 - accuracy: 0.9522 - val_loss: 0.5660 - val_accuracy: 0.9101
Epoch 18/30
56/56 [==============================] - 1s 11ms/step - loss: 0.4659 - accuracy: 0.9522 - val_loss: 0.5322 - val_accuracy: 0.9124
Epoch 19/30
56/56 [==============================] - 1s 11ms/step - loss: 0.4317 - accuracy: 0.9579 - val_loss: 0.5022 - val_accuracy: 0.9146
Epoch 20/30
56/56 [==============================] - 1s 9ms/step - loss: 0.4015 - accuracy: 0.9596 - val_loss: 0.4753 - val_accuracy: 0.9191
Epoch 21/30
56/56 [==============================] - 1s 11ms/step - loss: 0.3746 - accuracy: 0.9590 - val_loss: 0.4526 - val_accuracy: 0.9169
Epoch 22/30
56/56 [==============================] - 1s 11ms/step - loss: 0.3502 - accuracy: 0.9618 - val_loss: 0.4304 - val_accuracy: 0.9191
Epoch 23/30
56/56 [==============================] - 1s 12ms/step - loss: 0.3282 - accuracy: 0.9612 - val_loss: 0.4115 - val_accuracy: 0.9191
Epoch 24/30
56/56 [==============================] - 1s 12ms/step - loss: 0.3087 - accuracy: 0.9629 - val_loss: 0.3938 - val_accuracy: 0.9191
Epoch 25/30
56/56 [==============================] - 1s 9ms/step - loss: 0.2906 - accuracy: 0.9657 - val_loss: 0.3781 - val_accuracy: 0.9213
Epoch 26/30
56/56 [==============================] - 1s 12ms/step - loss: 0.2741 - accuracy: 0.9685 - val_loss: 0.3643 - val_accuracy: 0.9213
Epoch 27/30
56/56 [==============================] - 1s 11ms/step - loss: 0.2593 - accuracy: 0.9697 - val_loss: 0.3515 - val_accuracy: 0.9258
Epoch 28/30
56/56 [==============================] - 1s 10ms/step - loss: 0.2456 - accuracy: 0.9685 - val_loss: 0.3394 - val_accuracy: 0.9258
Epoch 29/30
56/56 [==============================] - 1s 10ms/step - loss: 0.2329 - accuracy: 0.9702 - val_loss: 0.3289 - val_accuracy: 0.9258
Epoch 30/30
56/56 [==============================] - 1s 10ms/step - loss: 0.2212 - accuracy: 0.9697 - val_loss: 0.3191 - val_accuracy: 0.9258
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history[f'val_{metric}'])
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, f'val_{metric}'])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")