C3W3: Exploring Overfitting in NLP
Contents
C3W3: Exploring Overfitting in NLP#
https-deeplearning-ai/tensorflow-1-public/C3/W3/assignment/C3W3_Assignment.ipynb
Commit
69afe3bon Jul 11, 2022 - Compare
Sentiment140 dataset
1.6 million tweets
sentiment (0 for negative and 4 for positive)
import csv
import random
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import matplotlib.pyplot as plt
from scipy.stats import linregress
EMBEDDING_DIM = 100
MAXLEN = 16
TRUNCATING = 'post'
PADDING = 'post'
OOV_TOKEN = "<OOV>"
MAX_EXAMPLES = 160000
TRAINING_SPLIT = 0.9
Explore the dataset#
SENTIMENT_CSV = "./data/training_cleaned.csv"
with open(SENTIMENT_CSV, 'r') as csvfile:
print(f"First data point looks like this:\n\n{csvfile.readline()}")
print(f"Second data point looks like this:\n\n{csvfile.readline()}")
First data point looks like this:
"0","1467810369","Mon Apr 06 22:19:45 PDT 2009","NO_QUERY","_TheSpecialOne_","@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D"
Second data point looks like this:
"0","1467810672","Mon Apr 06 22:19:49 PDT 2009","NO_QUERY","scotthamilton","is upset that he can't update his Facebook by texting it... and might cry as a result School today also. Blah!"
Parsing the raw data#
def parse_data_from_file(filename):
sentences = []
labels = []
with open(filename, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
sentences.append(row[5])
labels.append([0] if int(row[0]) == 0 else [1])
return sentences, labels
sentences, labels = parse_data_from_file(SENTIMENT_CSV)
print(f"dataset contains {len(sentences)} examples\n")
print(f"Text of second example should look like this:\n{sentences[1]}\n")
print(f"Text of fourth example should look like this:\n{sentences[3]}")
print(f"\nLabels of last 5 examples should look like this:\n{labels[-5:]}")
dataset contains 1600000 examples
Text of second example should look like this:
is upset that he can't update his Facebook by texting it... and might cry as a result School today also. Blah!
Text of fourth example should look like this:
my whole body feels itchy and like its on fire
Labels of last 5 examples should look like this:
[[1], [1], [1], [1], [1]]
sentences_and_labels = list(zip(sentences, labels))
# Perform random sampling
random.seed(42)
sentences_and_labels = random.sample(sentences_and_labels, MAX_EXAMPLES)
# Unpack back into separate lists
sentences, labels = zip(*sentences_and_labels)
print(f"There are {len(sentences)} sentences and {len(labels)} labels after random sampling\n")
There are 160000 sentences and 160000 labels after random sampling
Training - Validation Split#
def train_val_split(sentences, labels, training_split):
train_size = int(len(sentences) * training_split)
train_sentences = sentences[:train_size]
train_labels = labels[:train_size]
validation_sentences = sentences[train_size:]
validation_labels = labels[train_size:]
return train_sentences, validation_sentences, train_labels , validation_labels
train_sentences, val_sentences, train_labels, val_labels = train_val_split(sentences, labels, TRAINING_SPLIT)
print(f"There are {len(train_sentences)} sentences for training.\n")
print(f"There are {len(train_labels)} labels for training.\n")
print(f"There are {len(val_sentences)} sentences for validation.\n")
print(f"There are {len(val_labels)} labels for validation.")
There are 144000 sentences for training.
There are 144000 labels for training.
There are 16000 sentences for validation.
There are 16000 labels for validation.
Tokenization - Sequences, truncating and padding#
def fit_tokenizer(train_sentences, oov_token):
tokenizer = Tokenizer(oov_token=oov_token)
tokenizer.fit_on_texts(train_sentences)
return tokenizer
tokenizer = fit_tokenizer(train_sentences, OOV_TOKEN)
word_index = tokenizer.word_index
VOCAB_SIZE = len(word_index)
print(f"Vocabulary contains {VOCAB_SIZE} words\n")
print("<OOV> token included in vocabulary" if "<OOV>" in word_index else "<OOV> token NOT included in vocabulary")
print(f"\nindex of word 'i' should be {word_index['i']}")
Vocabulary contains 128293 words
<OOV> token included in vocabulary
index of word 'i' should be 2
def seq_pad_and_trunc(sentences, tokenizer, padding, truncating, maxlen):
sequences = tokenizer.texts_to_sequences(sentences)
pad_trunc_sequences = pad_sequences(sequences,
padding=padding, truncating=truncating, maxlen=maxlen)
return pad_trunc_sequences
train_pad_trunc_seq = seq_pad_and_trunc(train_sentences, tokenizer, PADDING, TRUNCATING, MAXLEN)
val_pad_trunc_seq = seq_pad_and_trunc(val_sentences, tokenizer, PADDING, TRUNCATING, MAXLEN)
print(f"Padded and truncated training sequences have shape: {train_pad_trunc_seq.shape}\n")
print(f"Padded and truncated validation sequences have shape: {val_pad_trunc_seq.shape}")
Padded and truncated training sequences have shape: (144000, 16)
Padded and truncated validation sequences have shape: (16000, 16)
train_labels = np.array(train_labels)
val_labels = np.array(val_labels)
Using pre-defined Embeddings#
GLOVE_FILE = './data/glove.6B.100d.txt'
GLOVE_EMBEDDINGS = {}
with open(GLOVE_FILE) as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
GLOVE_EMBEDDINGS[word] = coefs
test_word = 'dog'
test_vector = GLOVE_EMBEDDINGS[test_word]
print(f"Vector representation of word {test_word} looks like this:\n\n{test_vector}")
Vector representation of word dog looks like this:
[ 0.30817 0.30938 0.52803 -0.92543 -0.73671 0.63475
0.44197 0.10262 -0.09142 -0.56607 -0.5327 0.2013
0.7704 -0.13983 0.13727 1.1128 0.89301 -0.17869
-0.0019722 0.57289 0.59479 0.50428 -0.28991 -1.3491
0.42756 1.2748 -1.1613 -0.41084 0.042804 0.54866
0.18897 0.3759 0.58035 0.66975 0.81156 0.93864
-0.51005 -0.070079 0.82819 -0.35346 0.21086 -0.24412
-0.16554 -0.78358 -0.48482 0.38968 -0.86356 -0.016391
0.31984 -0.49246 -0.069363 0.018869 -0.098286 1.3126
-0.12116 -1.2399 -0.091429 0.35294 0.64645 0.089642
0.70294 1.1244 0.38639 0.52084 0.98787 0.79952
-0.34625 0.14095 0.80167 0.20987 -0.86007 -0.15308
0.074523 0.40816 0.019208 0.51587 -0.34428 -0.24525
-0.77984 0.27425 0.22418 0.20164 0.017431 -0.014697
-1.0235 -0.39695 -0.0056188 0.30569 0.31748 0.021404
0.11837 -0.11319 0.42456 0.53405 -0.16717 -0.27185
-0.6255 0.12883 0.62529 -0.52086 ]
print(f"Each word vector has shape: {test_vector.shape}")
Each word vector has shape: (100,)
Represent the words in your vocabulary using the embeddings#
EMBEDDINGS_MATRIX = np.zeros((VOCAB_SIZE+1, EMBEDDING_DIM))
# Iterate all of the words in the vocabulary and if the vector representation for
# each word exists within GloVe's representations, save it in the EMBEDDINGS_MATRIX array
for word, i in word_index.items():
embedding_vector = GLOVE_EMBEDDINGS.get(word)
if embedding_vector is not None:
EMBEDDINGS_MATRIX[i] = embedding_vector
Define a model that does not overfit#
def create_model(vocab_size, embedding_dim, maxlen, embeddings_matrix):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size+1, embedding_dim, input_length=maxlen, weights=[embeddings_matrix], trainable=False),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
model = create_model(VOCAB_SIZE, EMBEDDING_DIM, MAXLEN, EMBEDDINGS_MATRIX)
history = model.fit(train_pad_trunc_seq, train_labels, epochs=20, validation_data=(val_pad_trunc_seq, val_labels))
Epoch 1/20
4500/4500 [==============================] - 75s 15ms/step - loss: 0.5630 - accuracy: 0.7046 - val_loss: 0.5141 - val_accuracy: 0.7458
Epoch 2/20
4500/4500 [==============================] - 69s 15ms/step - loss: 0.5179 - accuracy: 0.7397 - val_loss: 0.4933 - val_accuracy: 0.7566
Epoch 3/20
4500/4500 [==============================] - 70s 16ms/step - loss: 0.5013 - accuracy: 0.7521 - val_loss: 0.4831 - val_accuracy: 0.7650
Epoch 4/20
4500/4500 [==============================] - 71s 16ms/step - loss: 0.4907 - accuracy: 0.7592 - val_loss: 0.4759 - val_accuracy: 0.7707
Epoch 5/20
4500/4500 [==============================] - 70s 16ms/step - loss: 0.4831 - accuracy: 0.7639 - val_loss: 0.4785 - val_accuracy: 0.7664
Epoch 6/20
4500/4500 [==============================] - 71s 16ms/step - loss: 0.4759 - accuracy: 0.7680 - val_loss: 0.4728 - val_accuracy: 0.7729
Epoch 7/20
4500/4500 [==============================] - 68s 15ms/step - loss: 0.4714 - accuracy: 0.7726 - val_loss: 0.4749 - val_accuracy: 0.7729
Epoch 8/20
4500/4500 [==============================] - 69s 15ms/step - loss: 0.4669 - accuracy: 0.7750 - val_loss: 0.4679 - val_accuracy: 0.7759
Epoch 9/20
4500/4500 [==============================] - 69s 15ms/step - loss: 0.4614 - accuracy: 0.7782 - val_loss: 0.4697 - val_accuracy: 0.7721
Epoch 10/20
4500/4500 [==============================] - 68s 15ms/step - loss: 0.4583 - accuracy: 0.7808 - val_loss: 0.4850 - val_accuracy: 0.7658
Epoch 11/20
4500/4500 [==============================] - 75s 17ms/step - loss: 0.4567 - accuracy: 0.7812 - val_loss: 0.4697 - val_accuracy: 0.7765
Epoch 12/20
4500/4500 [==============================] - 74s 17ms/step - loss: 0.4540 - accuracy: 0.7830 - val_loss: 0.4659 - val_accuracy: 0.7766
Epoch 13/20
4500/4500 [==============================] - 76s 17ms/step - loss: 0.4524 - accuracy: 0.7845 - val_loss: 0.4688 - val_accuracy: 0.7786
Epoch 14/20
4500/4500 [==============================] - 70s 15ms/step - loss: 0.4501 - accuracy: 0.7850 - val_loss: 0.4694 - val_accuracy: 0.7779
Epoch 15/20
4500/4500 [==============================] - 71s 16ms/step - loss: 0.4494 - accuracy: 0.7858 - val_loss: 0.4668 - val_accuracy: 0.7762
Epoch 16/20
4500/4500 [==============================] - 67s 15ms/step - loss: 0.4474 - accuracy: 0.7860 - val_loss: 0.4721 - val_accuracy: 0.7770
Epoch 17/20
4500/4500 [==============================] - 70s 15ms/step - loss: 0.4448 - accuracy: 0.7895 - val_loss: 0.4684 - val_accuracy: 0.7785
Epoch 18/20
4500/4500 [==============================] - 69s 15ms/step - loss: 0.4440 - accuracy: 0.7892 - val_loss: 0.4659 - val_accuracy: 0.7786
Epoch 19/20
4500/4500 [==============================] - 69s 15ms/step - loss: 0.4432 - accuracy: 0.7899 - val_loss: 0.4661 - val_accuracy: 0.7797
Epoch 20/20
4500/4500 [==============================] - 70s 16ms/step - loss: 0.4423 - accuracy: 0.7908 - val_loss: 0.4651 - val_accuracy: 0.7775
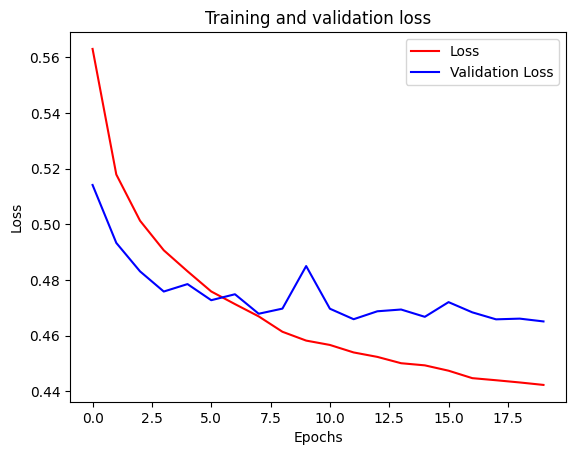
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = [*range(20)]
plt.plot(epochs, loss, 'r')
plt.plot(epochs, val_loss, 'b')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss", "Validation Loss"])
plt.show()
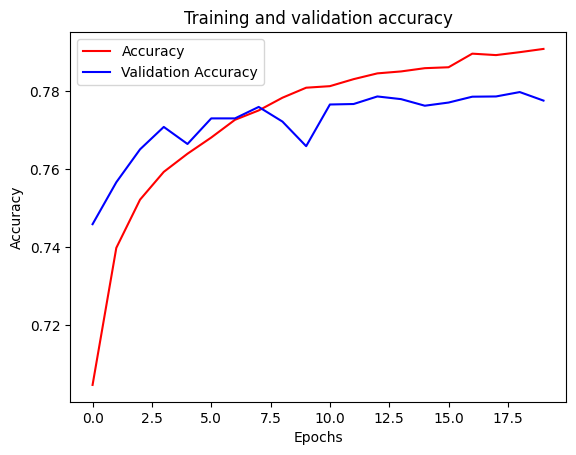
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs, acc, 'r')
plt.plot(epochs, val_acc, 'b')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["Accuracy", "Validation Accuracy"])
plt.show()
slope, *_ = linregress(epochs, val_loss)
print(f"The slope of your validation loss curve is {slope:.5f}")
The slope of your validation loss curve is -0.00145