Multi-worker mirrored strategy

The MultiWorkerMirroredStrategy is very similar to the MirroredStrategy
It implements synchronous distributed training across multiple workers, each with
potentially multiple GPUs. Similar to MirroredStraegy, it creates copies of all variables
in the model on each device across all workers.
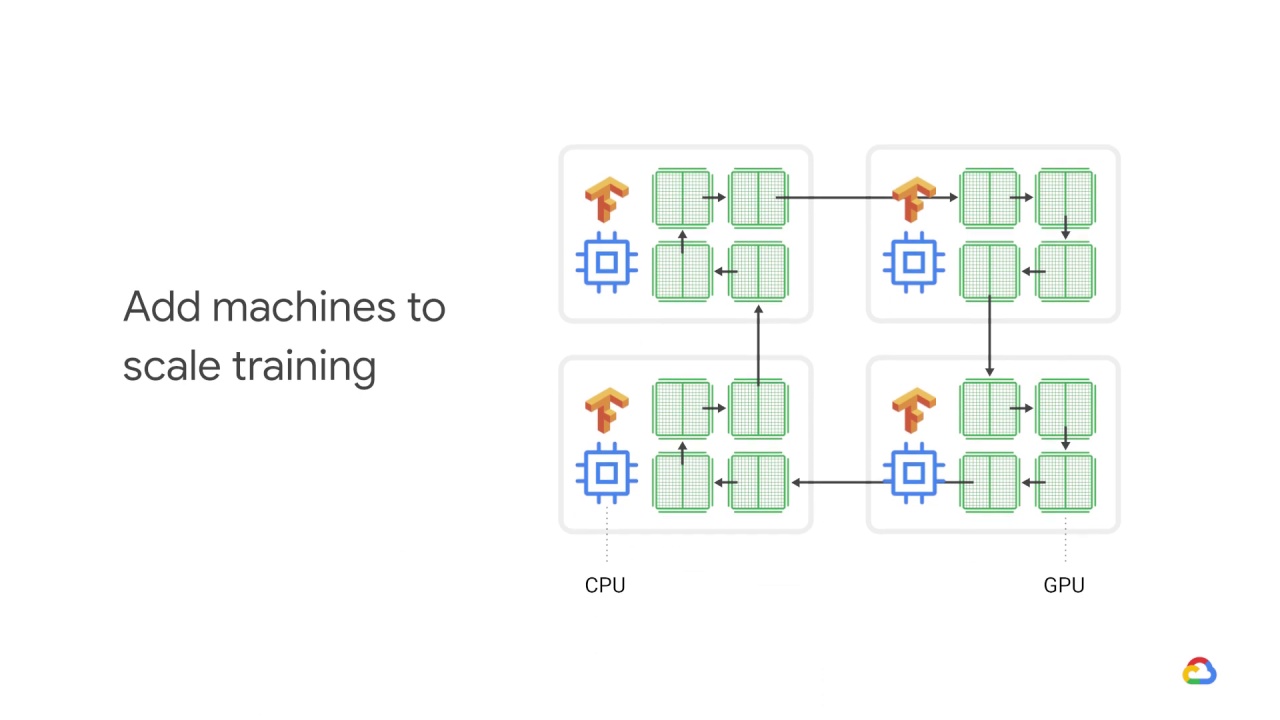
If you’ve mastered single host training and are looking to scale training even further, then adding multiple machines to your cluster can help you get an even greater performance boost.
You can make use of a cluster of machines that are CPU only, or that each have one or more GPUs.

Like its single-worker counterpart, MirroredStrategy, MultiWorkerMirroredStrategy is a
synchronous data parallelism strategy that can be used with only a few code
changes.

However, unlike MirroredStrategy, for a multi-worker setup TensorFlow needs to know
which machines are part of the cluster.
In most cases, this is specified with the
environment variable TF_CONFIG.

In this simple TF_CONFIG example, the “cluster” key contains a dictionary with the
internal IPs and ports of all the machines.

In MultiWorkerMirroredStrategy, all machines are designated as workers, which are
the physical machines on which the replicated computation is executed.

In addition to each machine being a worker, there needs to be one worker that takes on some extra work such as saving checkpoints and writing summary files to TensorBoard.
This machine is known as the chief (or by its deprecated name master).

Conveniently, when using AI Platform Training,

the TF_CONFIG environment variable is set on each machine in your cluster so
there’s no need to worry about this set up!

As with any strategy in the
tf.distributemodule, step one is to create a strategy object.

Step two is to wrap the creation of the model parameters within the scope of the strategy.
This is crucial because it tells MirroredStrategy which variables to
mirror across the GPU devices.

And the third and final step is to scale the batch size by the number of replicas in the cluster. This ensures that each replica processes the same number of examples on each step.
Since we’ve already covered training with MirroredStrategy, the previous steps should be familiar.
The main difference when moving from synchronous data parallelism on one machine to many is that the gradients at the end of each step now need to be synchronized across all GPUs in a machine and across all machines in the cluster.
This additional step of synchronizing across the machines increases the overhead of distribution.
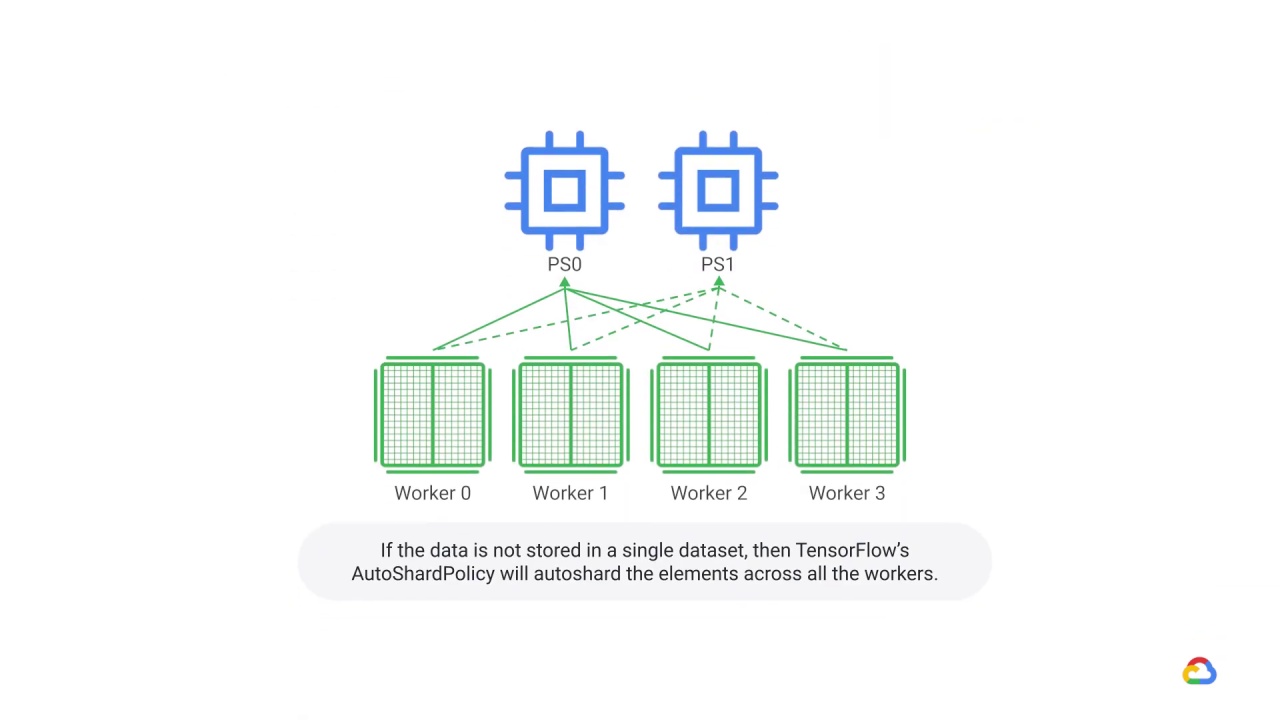
With multi-worker mirrored strategy, the data needs to be sharded, meaning that each worker is assigned a subset of the entire dataset.
If autosharding is turned off, each replica processes every example in the dataset, which is not recommended.
Therefore, at each step, a global batch size of non-overlapping dataset elements will be processed by each worker.
This sharding happens automatically with tf.data.experimental.AutoShardPolicy.
By default, the policy is set to AUTO, which will shard your data depending on whether it is file-based or not.
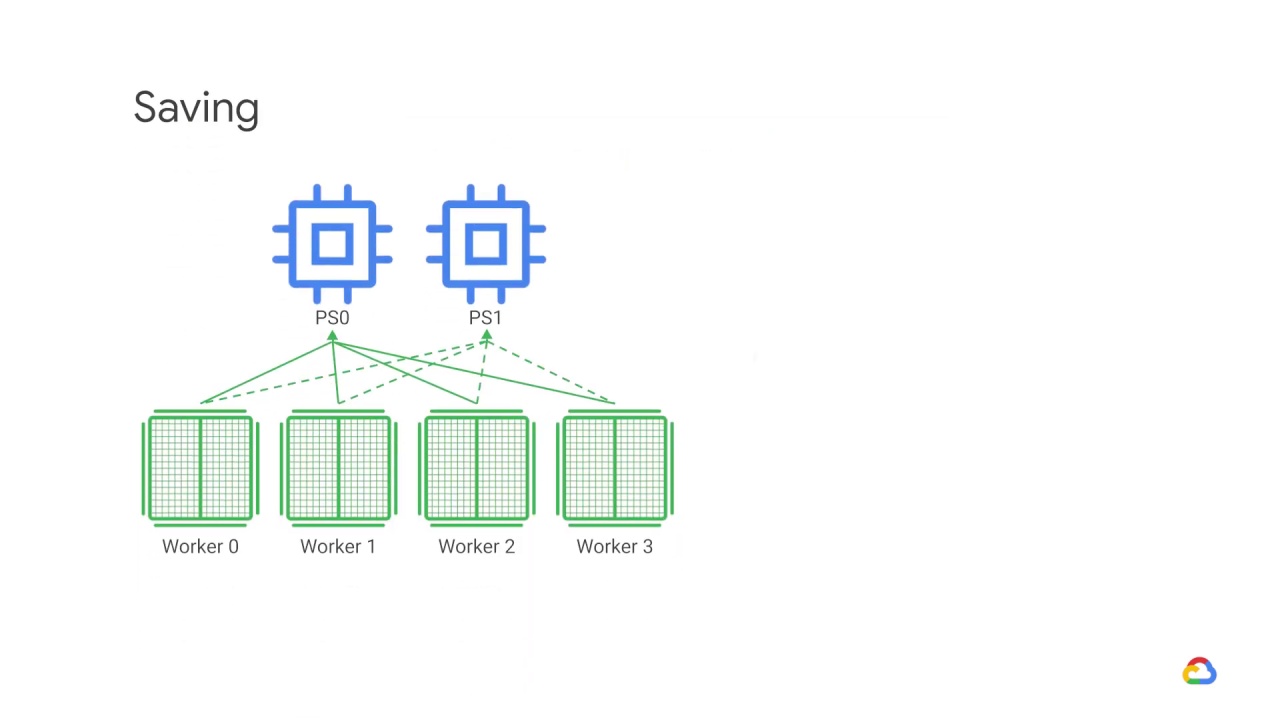
Saving the model is slightly more complicated in the multi-worker case because there needs to be
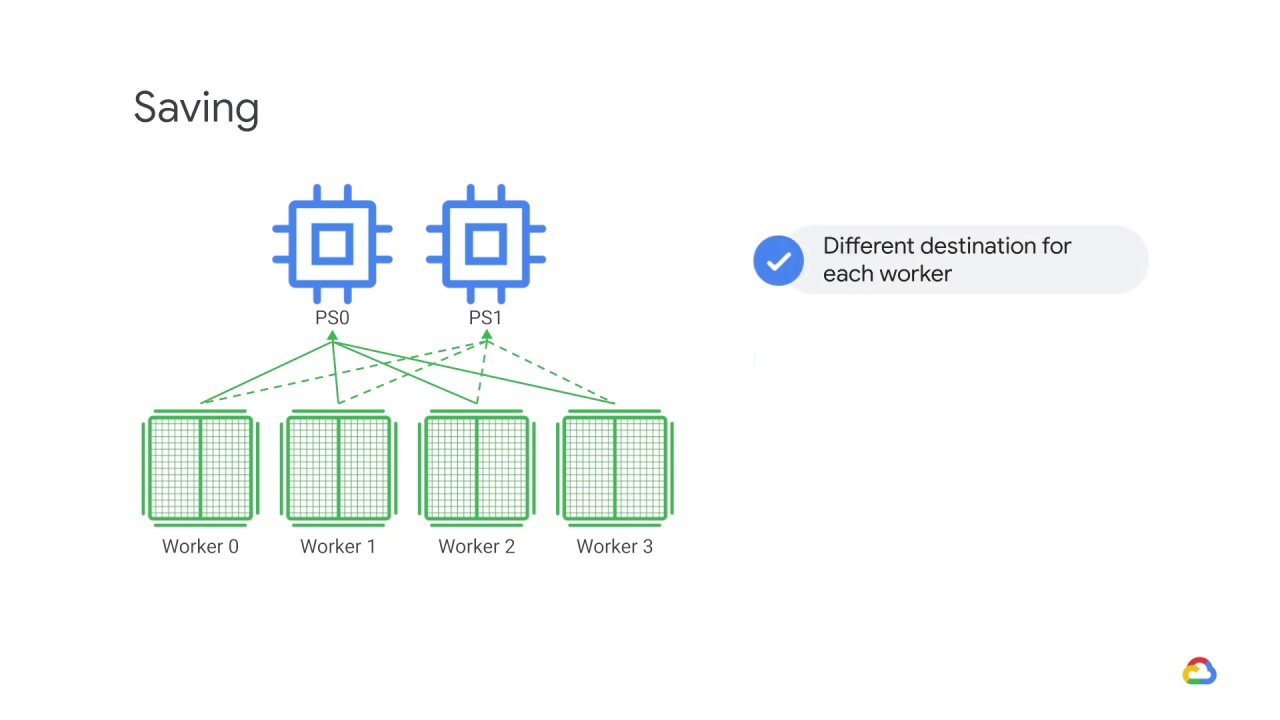
different destinations for each worker.
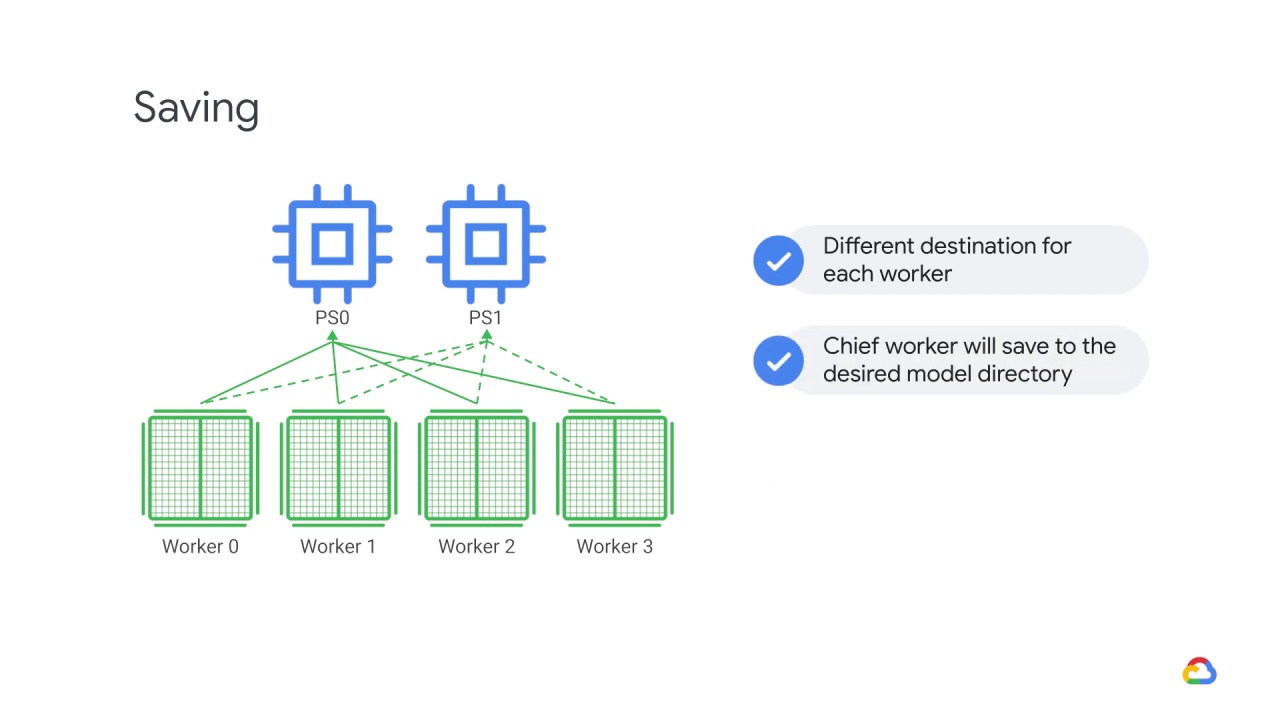
The chief worker will save to the desired model directory,
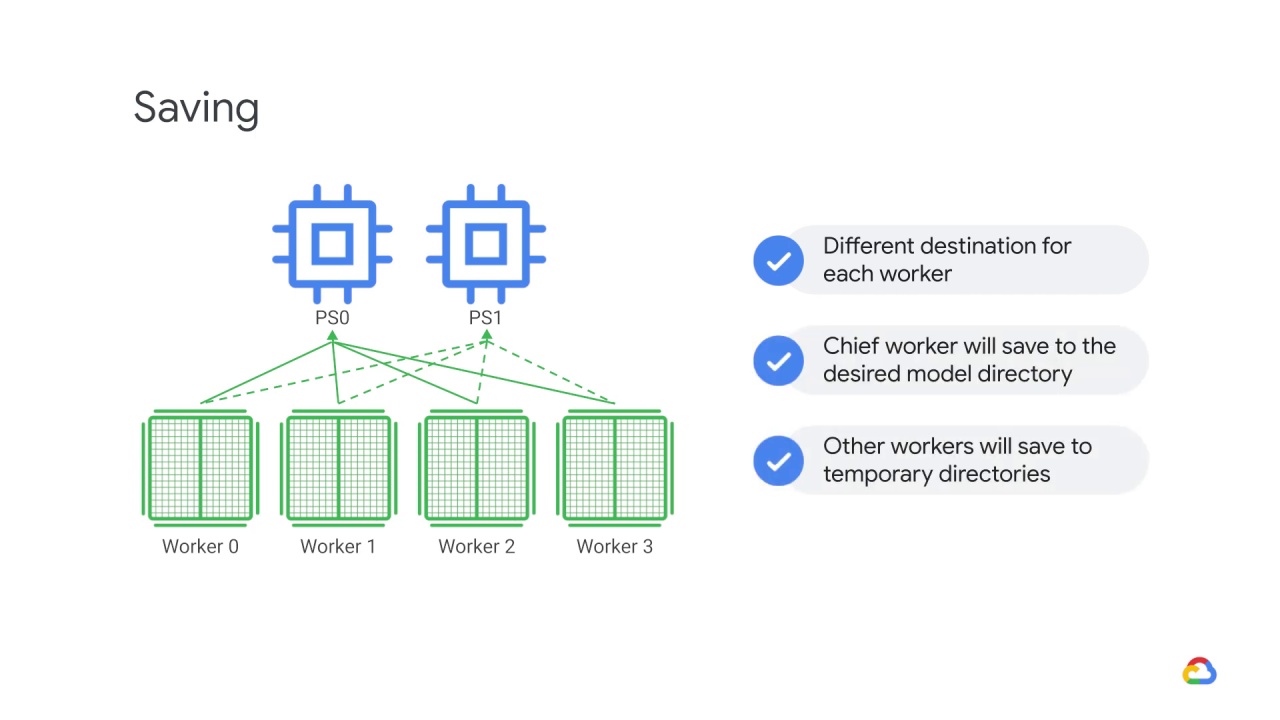
while the other workers will save the model to temporary directories.
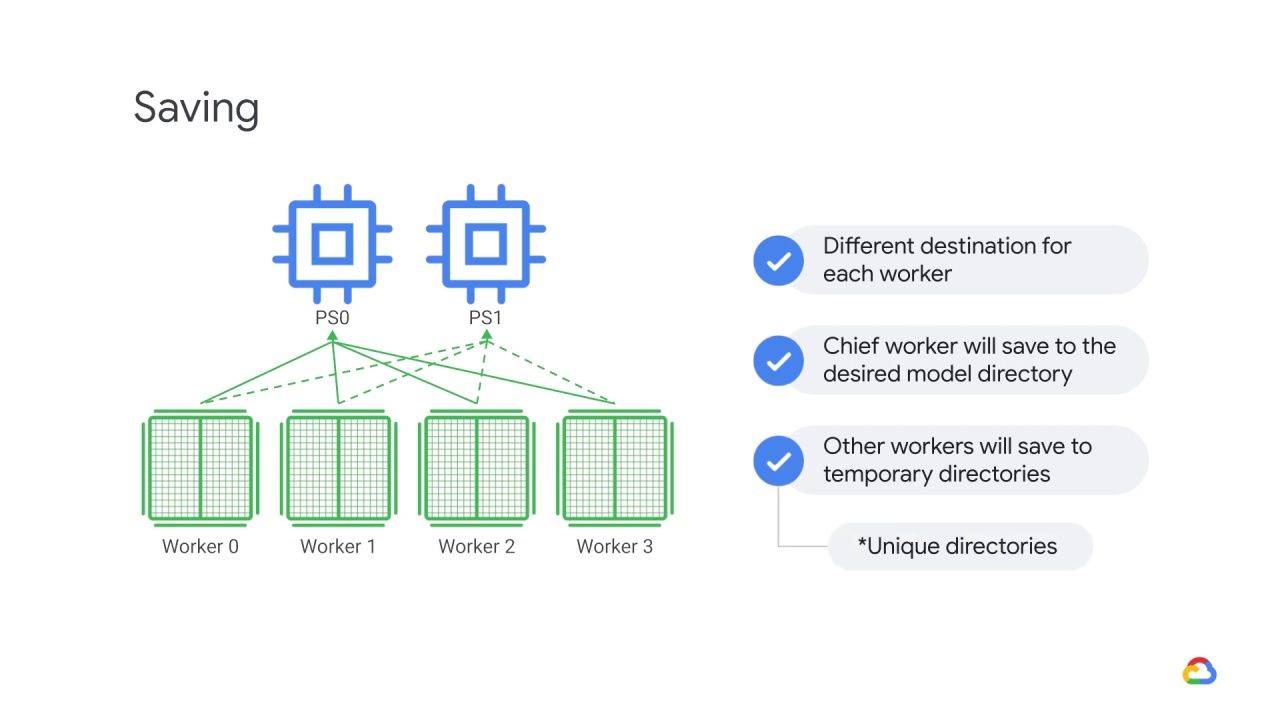
It’s important that these temporary directories are unique in order to prevent multiple workers from writing to the same location.
Saving can contain collective ops, so all workers must save and not just the chief.