NLP history

The history of NLP can be simply divided into two eras: before and after ML(machine learning).
What divides these two eras is the innovation of using ML models to solve NLP problems,
specifically neural networks and deep learning in NLP.
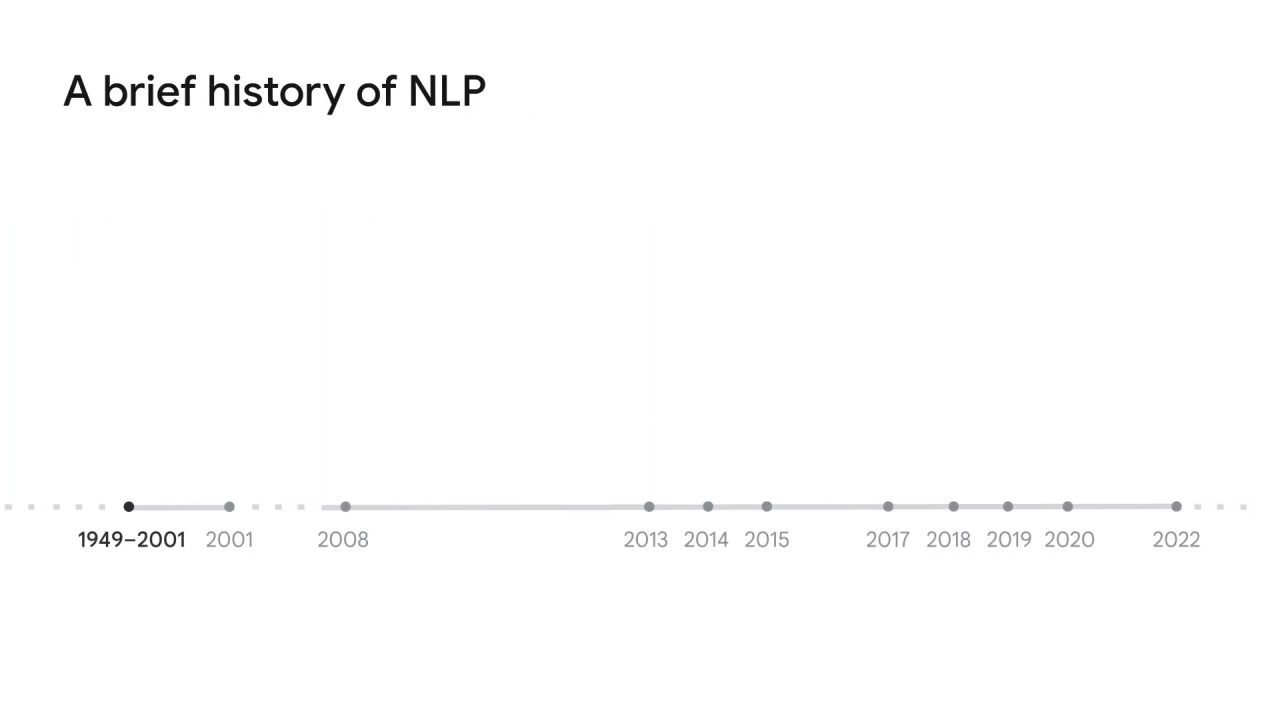
The journey of NLP can be traced back to over 70 years ago in the late 1940s.
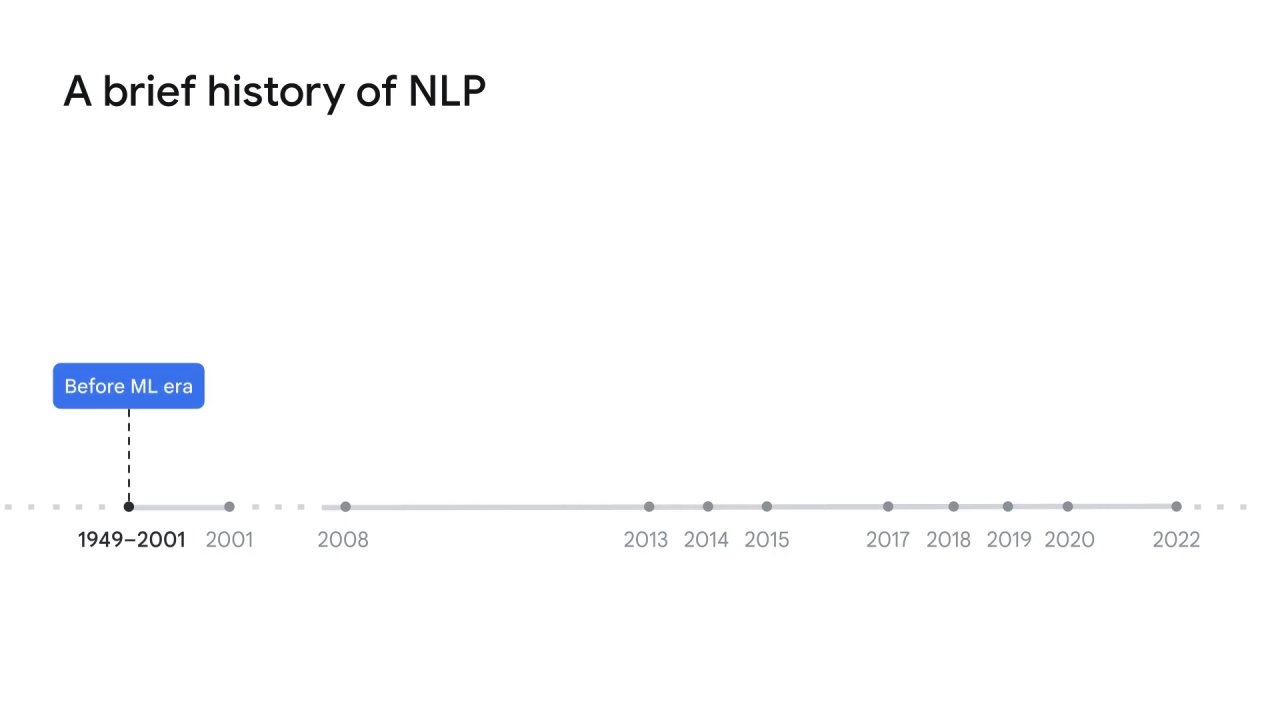
In 1949, people started the idea of using machines to help translation.
The primary methods back then were based on either hand-coded rules or statistical reasoning.
Natural language models marked the innovation of applying machine learning in NLP in 2001.
Natural language models use neural networks to predict the next word, given the previous words.
It also introduces word embedding, a key technique that uses vectors to represent given words.
Motivated by the advances of computer hardware, multi-task learning appeared in 2008.
It allows training models to solve more than one learning task, such as entity recognition and topic classification, based on a set of shared parameters.
2013 and 2014 mark the emergence of multiple new NLP models or architectures enabled by neural networks.
Some models produced remarkable results that are widely used today.
They are:
recurrent neural networks (
RNNs), which were soon replaced by its variantslong-short term memory (
LSTM) networks andGated Recurrent Units (
GRUs);convolutional neural networks (
CNNs); andsequence-to-sequence models.
In 2015, the attention mechanism was introduced to identify only the most relevant section instead of the entire sentence to be processed in the neural network.
It solves the blockage problem of the fixed-length encoding vector that the previous NLP models had.
Additionally, it improves the model performance by focusing on only the most relevant information to accomplish a task.
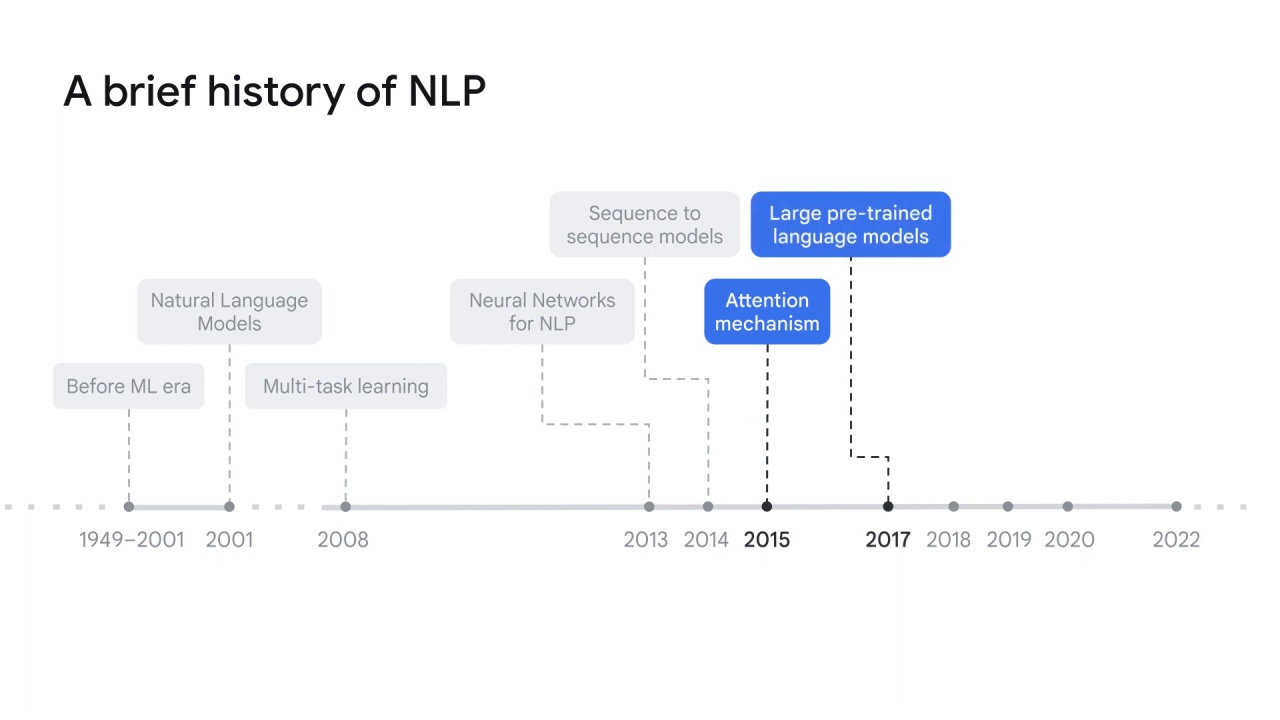
The attention mechanism generated a new state-of-the-art architecture called large language models, or pre-trained language models, in 2017.
Large pre-trained language models are designed to pre-train general language models with large amounts of data and parameters, which can be fine-tuned later for more specific tasks.
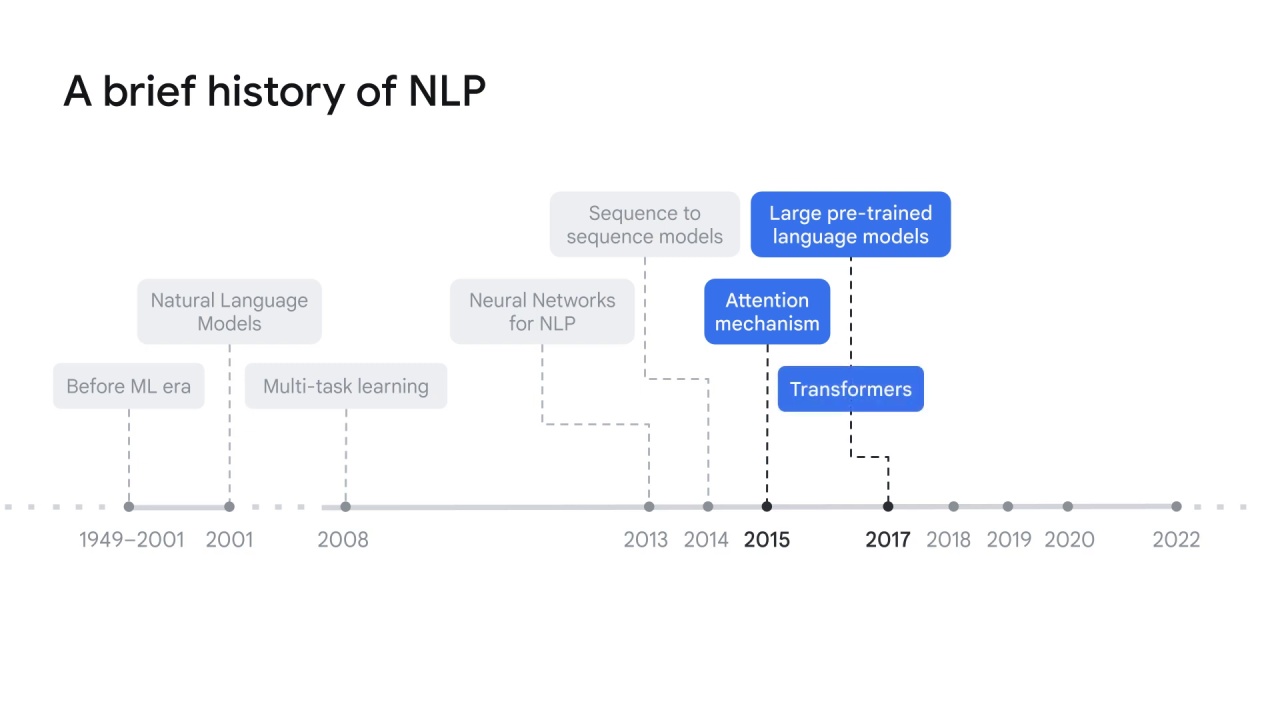
This trend triggered a series of modules or libraries such as Transformers by Google Brain in 2017,
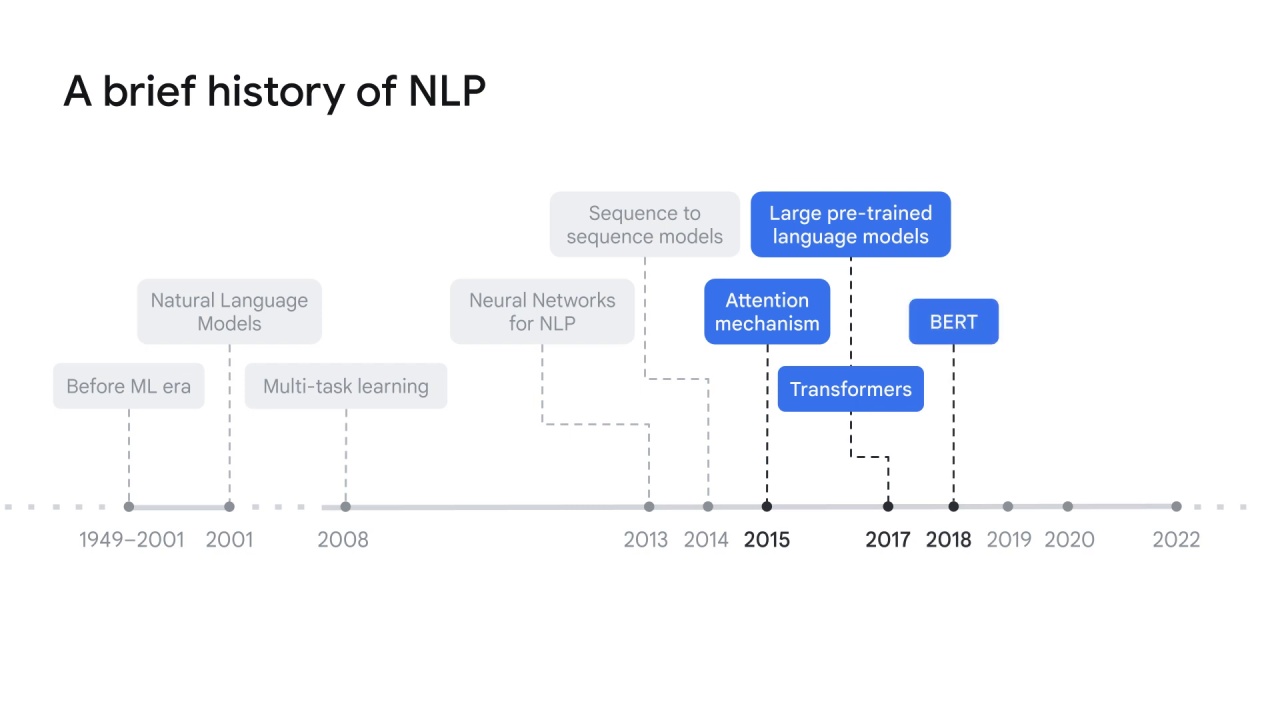
Google also created BERT (or Bidirectional Encoder Representations from Transformers) in 2018,
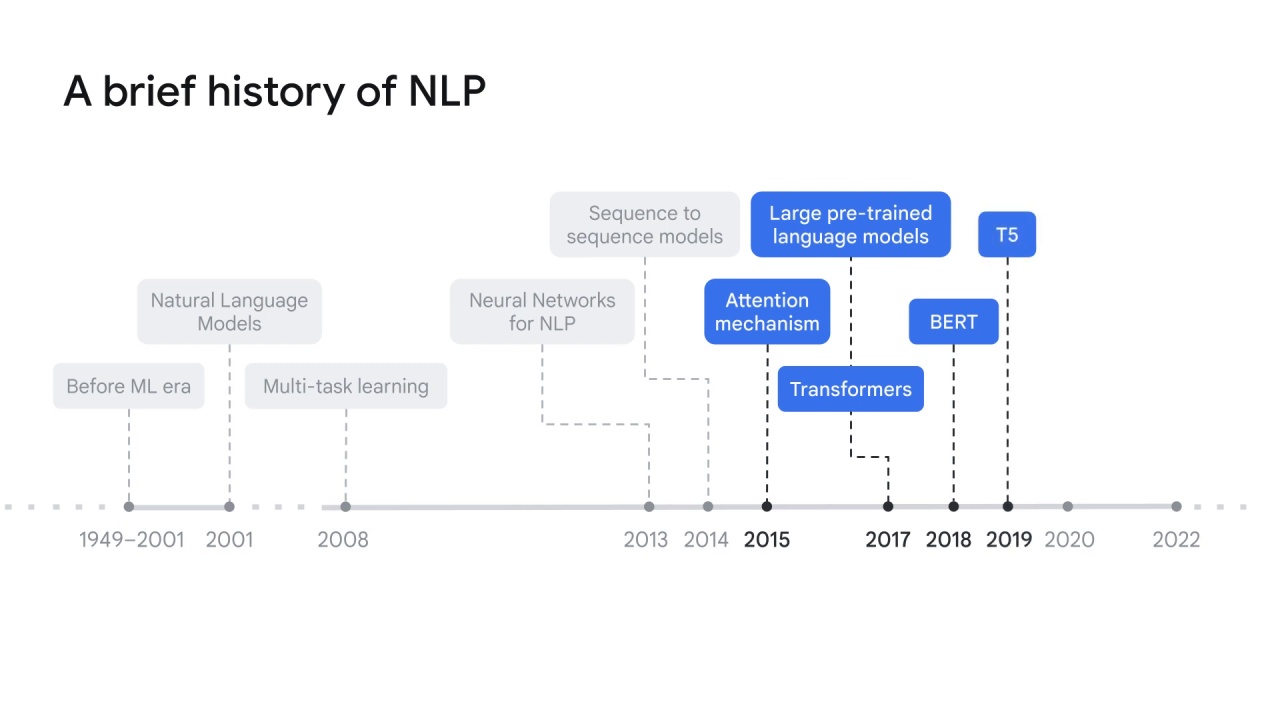
T5 in 2019,
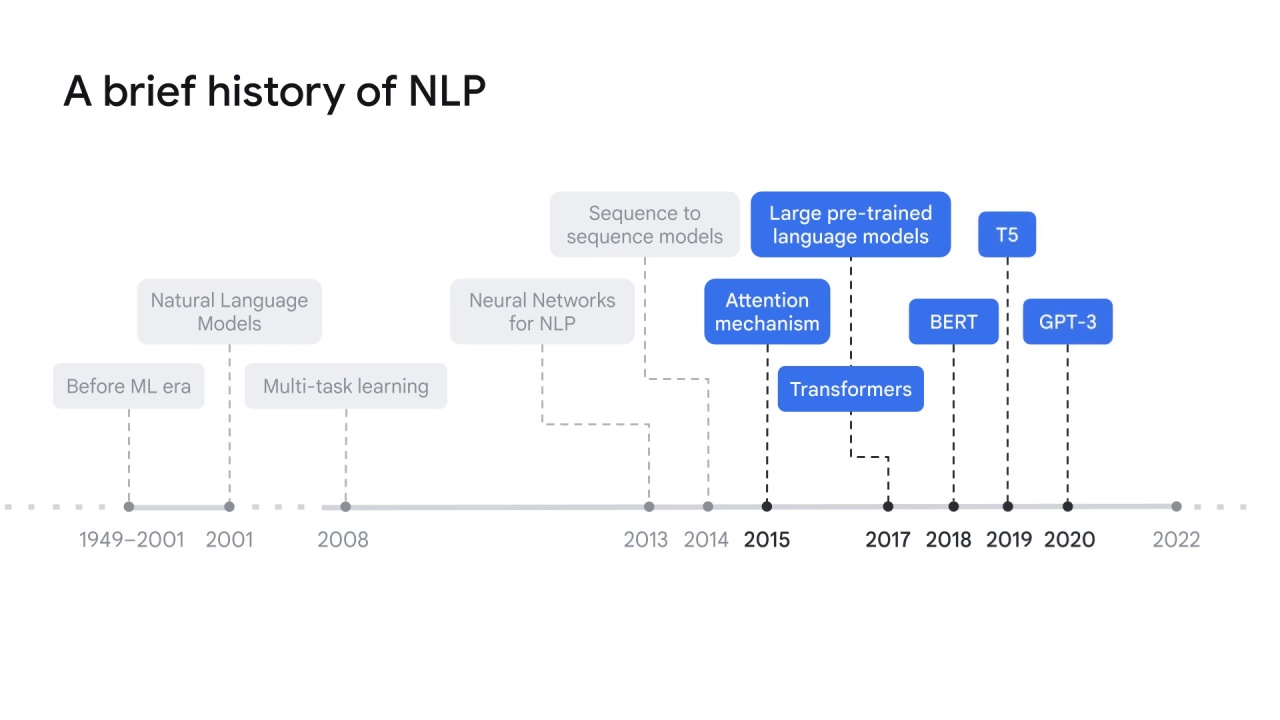
GPT-3 (or the third-generation Generative Pre-trained Transformer) by Open AI in 2020,
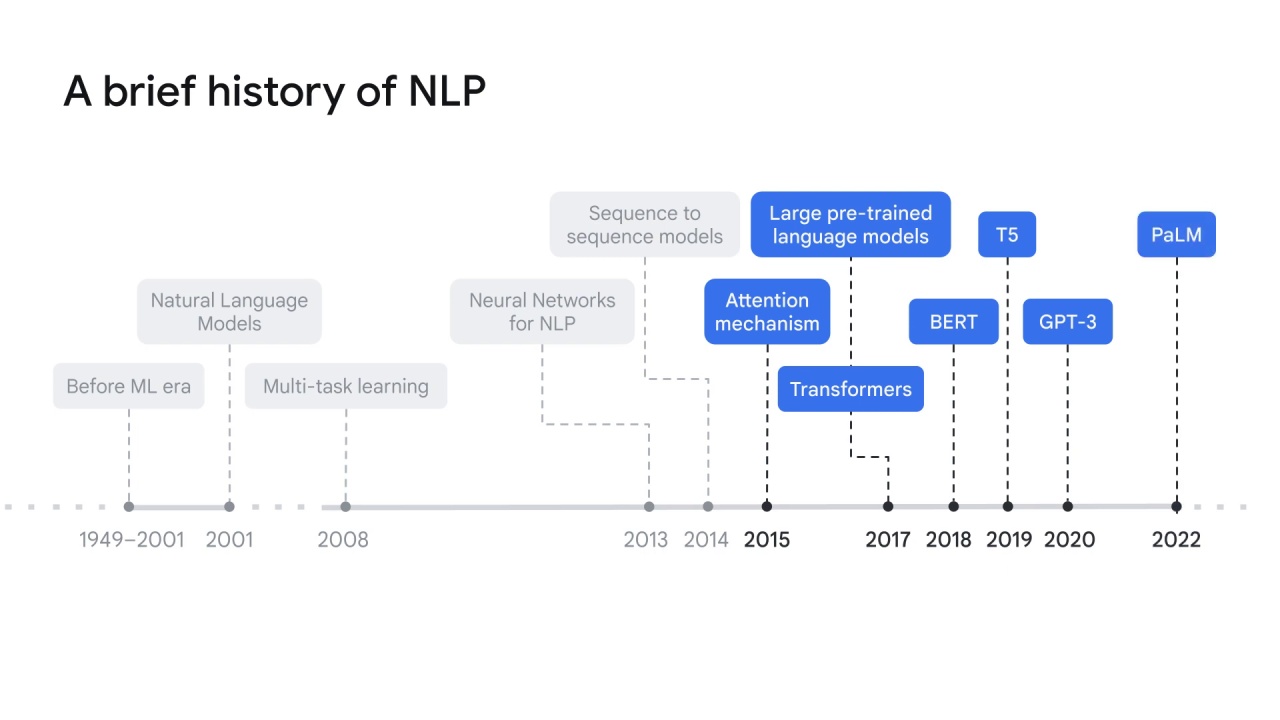
and PaLM (or Pathways Language Models) by Google.