C4W4: Using real world data
Contents
C4W4: Using real world data#
import csv
import pickle
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from dataclasses import dataclass
TEMPERATURES_CSV = './data/daily-min-temperatures.csv'
with open(TEMPERATURES_CSV, 'r') as csvfile:
print(f"Header looks like this:\n\n{csvfile.readline()}")
print(f"First data point looks like this:\n\n{csvfile.readline()}")
print(f"Second data point looks like this:\n\n{csvfile.readline()}")
Header looks like this:
"Date","Temp"
First data point looks like this:
"1981-01-01",20.7
Second data point looks like this:
"1981-01-02",17.9
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
Parsing the raw data#
def parse_data_from_file(filename):
times = []
temperatures = []
with open(filename) as csvfile:
reader = csv.reader(csvfile)
next(reader)
for row in reader:
times.append(row[0])
temperatures.append(float(row[1]))
return times, temperatures
@dataclass
class G:
TEMPERATURES_CSV = './data/daily-min-temperatures.csv'
times, temperatures = parse_data_from_file(TEMPERATURES_CSV)
TIME = np.array(times)
SERIES = np.array(temperatures)
SPLIT_TIME = 2500
WINDOW_SIZE = 64
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
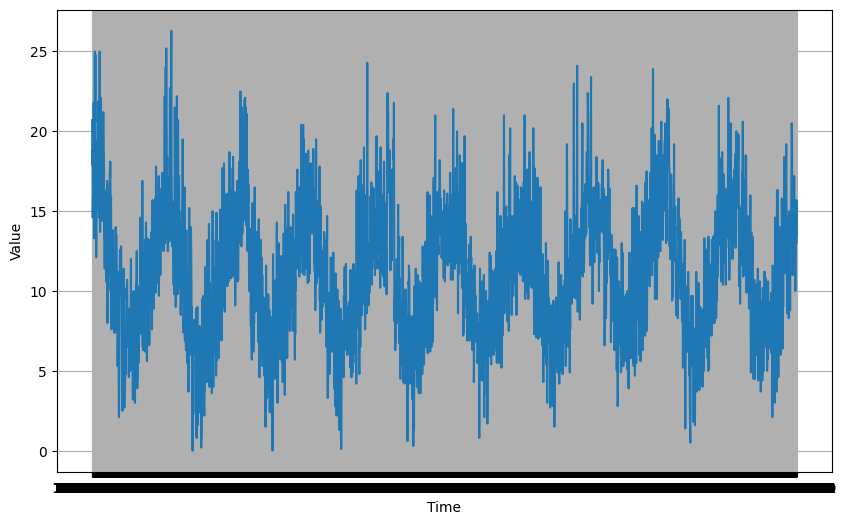
plt.figure(figsize=(10, 6))
plot_series(G.TIME, G.SERIES)
plt.show()
Processing the data#
def train_val_split(time, series, time_step=G.SPLIT_TIME):
time_train = time[:time_step]
series_train = series[:time_step]
time_valid = time[time_step:]
series_valid = series[time_step:]
return time_train, series_train, time_valid, series_valid
time_train, series_train, time_valid, series_valid = train_val_split(G.TIME, G.SERIES)
def windowed_dataset(series, window_size=G.WINDOW_SIZE, batch_size=G.BATCH_SIZE, shuffle_buffer=G.SHUFFLE_BUFFER_SIZE):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
ds = ds.map(lambda w: (w[:-1], w[-1]))
ds = ds.batch(batch_size).prefetch(1)
return ds
train_set = windowed_dataset(series_train, window_size=G.WINDOW_SIZE, batch_size=G.BATCH_SIZE, shuffle_buffer=G.SHUFFLE_BUFFER_SIZE)
Defining the model architecture#
def create_uncompiled_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(64, 3, padding='causal', activation='relu', input_shape=[G.WINDOW_SIZE, 1]),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(32),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1)
])
return model
uncompiled_model = create_uncompiled_model()
try:
uncompiled_model.predict(train_set)
except:
print("Your current architecture is incompatible with the windowed dataset, try adjusting it.")
else:
print("Your current architecture is compatible with the windowed dataset! :)")
77/77 [==============================] - 3s 10ms/step
Your current architecture is compatible with the windowed dataset! :)
Compiling the model#
def create_model():
model = create_uncompiled_model()
model.compile(optimizer='adam',
loss='huber',
metrics=["mae"])
return model
model = create_model()
history = model.fit(train_set, epochs=50)
Evaluating the forecast#
def compute_metrics(true_series, forecast):
mse = tf.keras.metrics.mean_squared_error(true_series, forecast).numpy()
mae = tf.keras.metrics.mean_absolute_error(true_series, forecast).numpy()
return mse, mae
Faster model forecasts#
def model_forecast(model, series, window_size):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecast
rnn_forecast = model_forecast(model, G.SERIES, G.WINDOW_SIZE).squeeze()
# Slice the forecast to get only the predictions for the validation set
rnn_forecast = rnn_forecast[G.SPLIT_TIME - G.WINDOW_SIZE:-1]
plt.figure(figsize=(10, 6))
plot_series(time_valid, series_valid)
plot_series(time_valid, rnn_forecast)
113/113 [==============================] - 2s 9ms/step
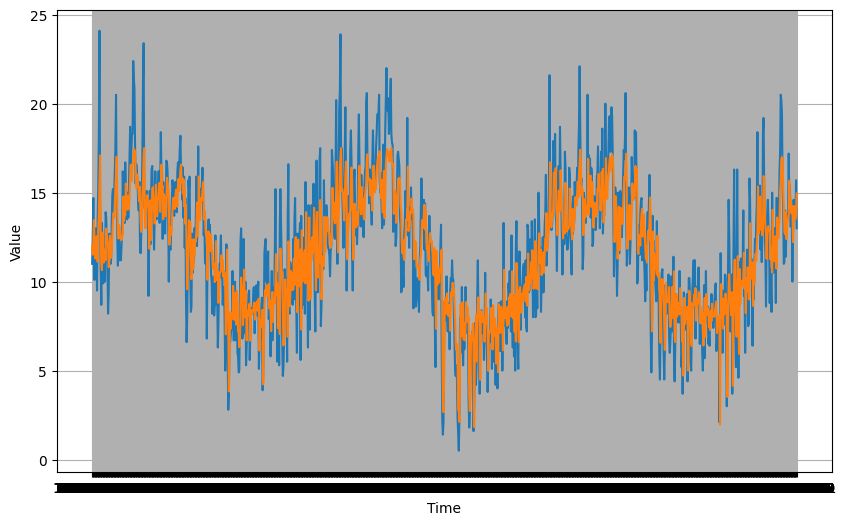
mse, mae = compute_metrics(series_valid, rnn_forecast)
print(f"mse: {mse:.2f}, mae: {mae:.2f} for forecast")
mse: 5.16, mae: 1.78 for forecast