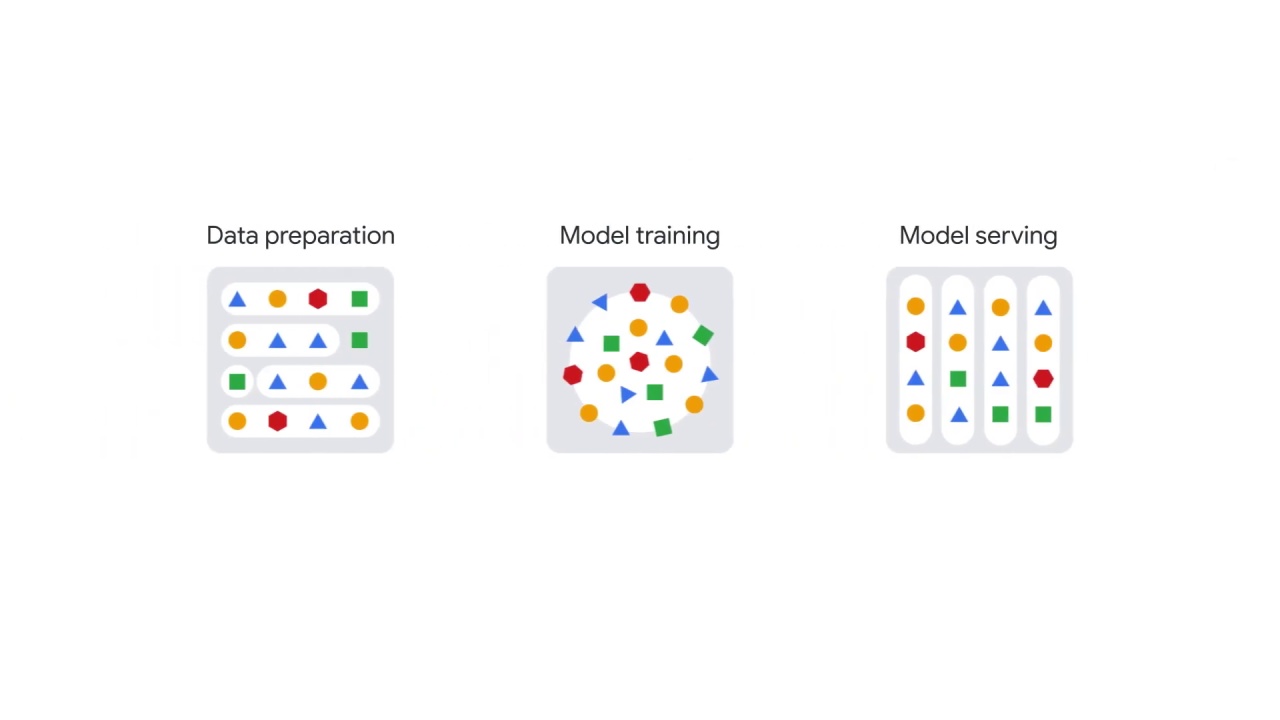
NLP end-to-end workflow
Vertex AI, Google’s AI Platform, provides developers and data scientists with one unified environment to build custom ML models.
How so?
Let’s look at how Vertex AI, specifically AutoML, experiments and builds an NLP model step by step.
There are three main stages:

data preparation,
model training and
model serving.
The first stage is data preparation.
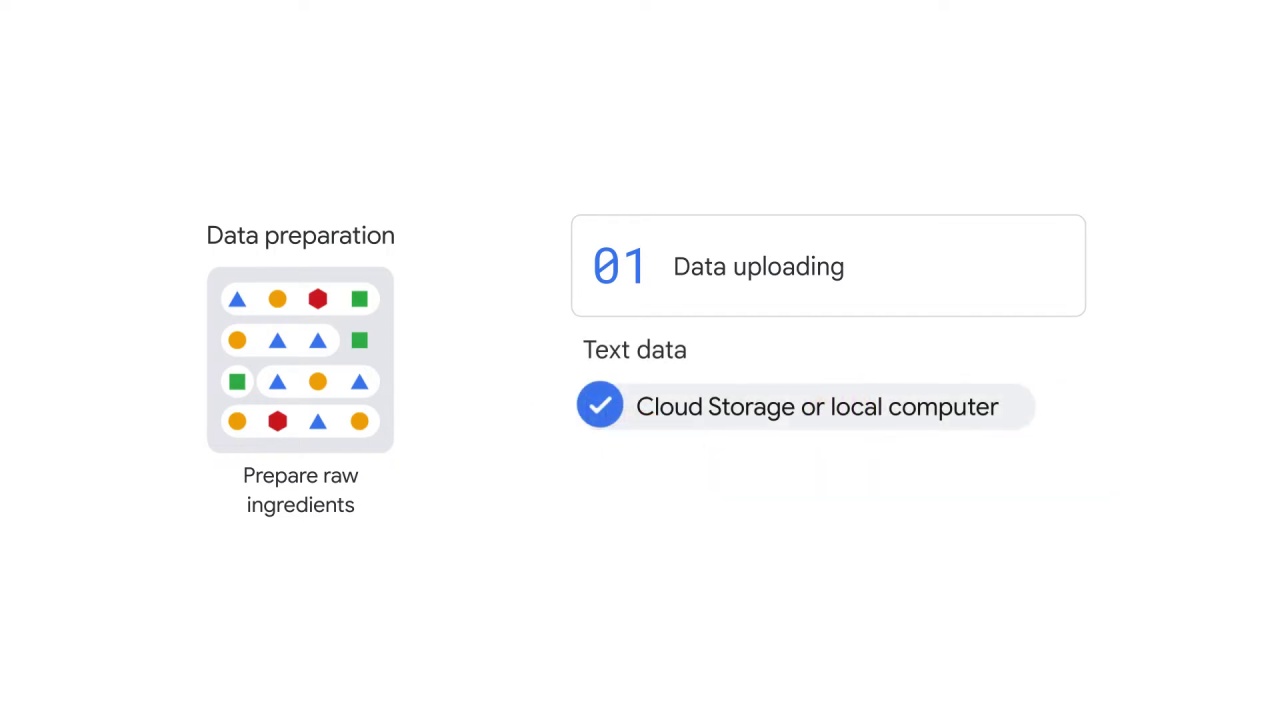
During this stage, you must first upload data.
The data used in NLP models is text data, which can come from either Cloud Storage or your local machine.

The data can also be either labeled or unlabeled depending on the goal of the NLP project.

A label is a training target.
So, if you want an NLP model to identify the sentiment of a sentence,
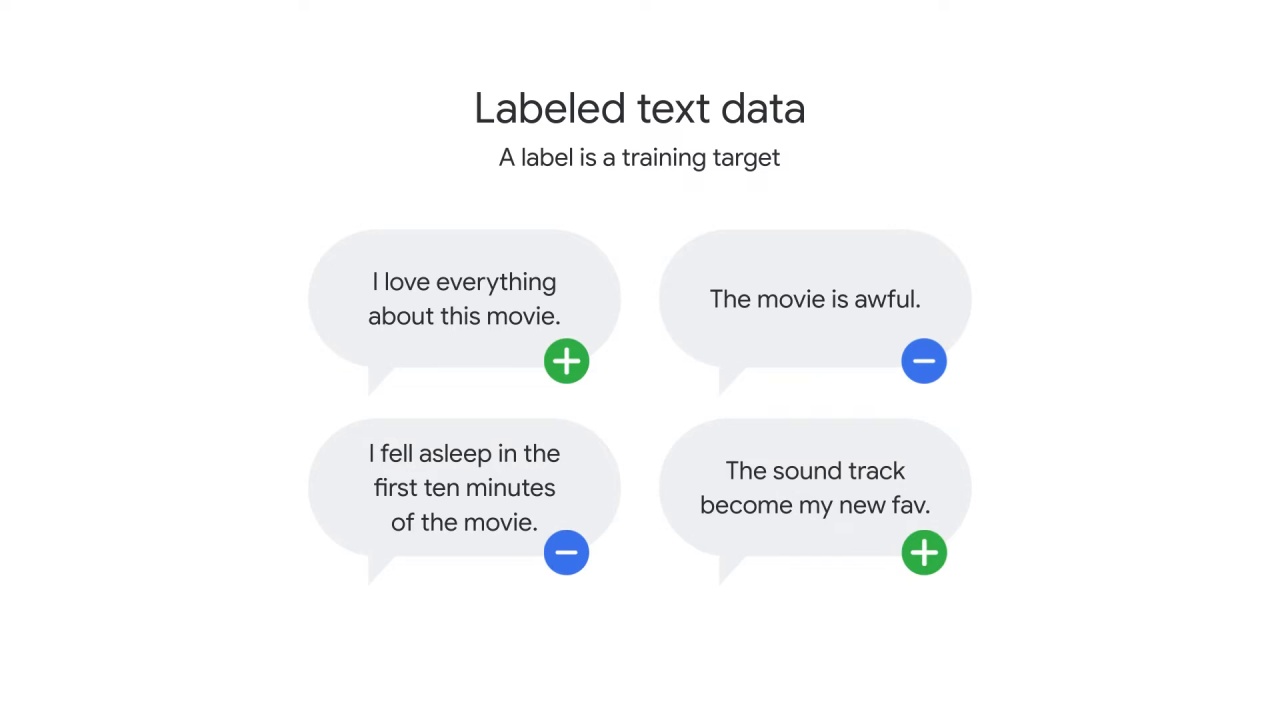
you must first provide sample sentences that are tagged or labeled as either positive or negative.

A label can be manually added, or

it can be added by using the paid label service of Google through the Vertex console.
These human labelers will manually generate accurate labels for you.

The text data can also be unlabeled.
For example, If you want to identify the underlying pattern of texts and group similar documents into sets, you can use cluster analysis.

And if you want to recognize the co-occurrence of pairs of words or phrases you can use Latent Semantic Indexing (LSI).
After uploading data, you’ll then prepare it for model training with feature engineering.
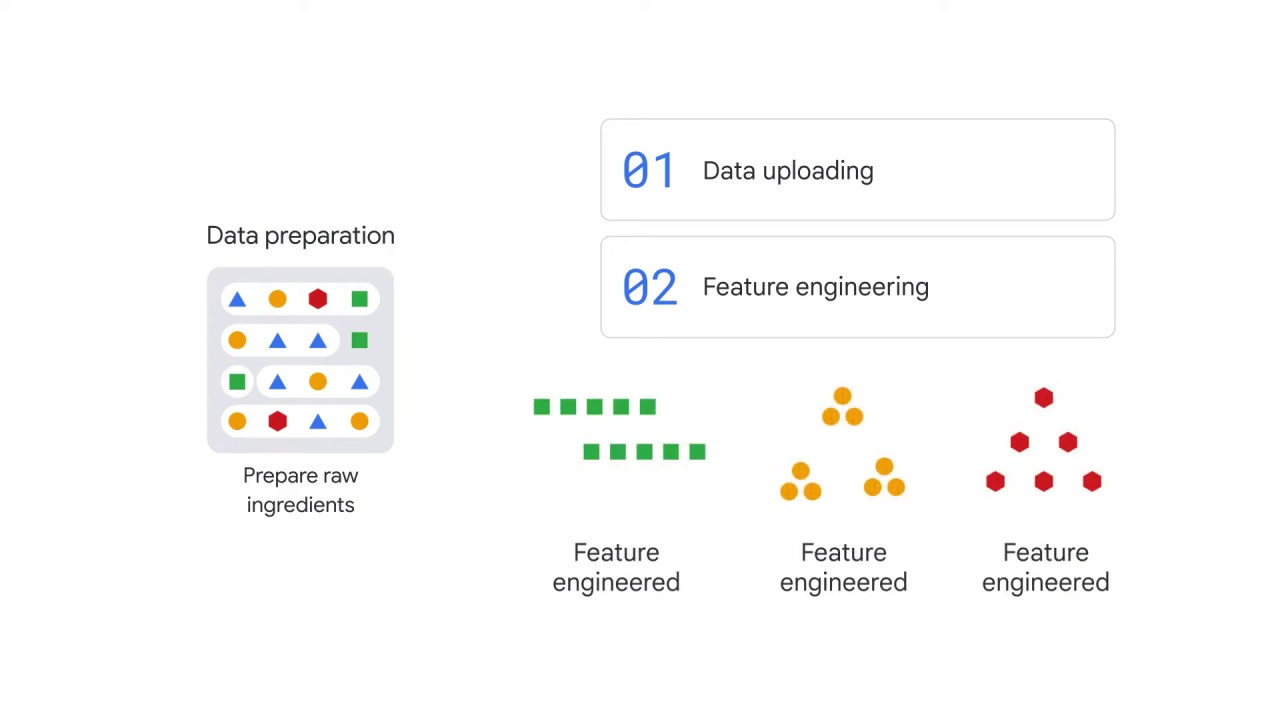
The data normally needs to be processed before the model starts being trained.
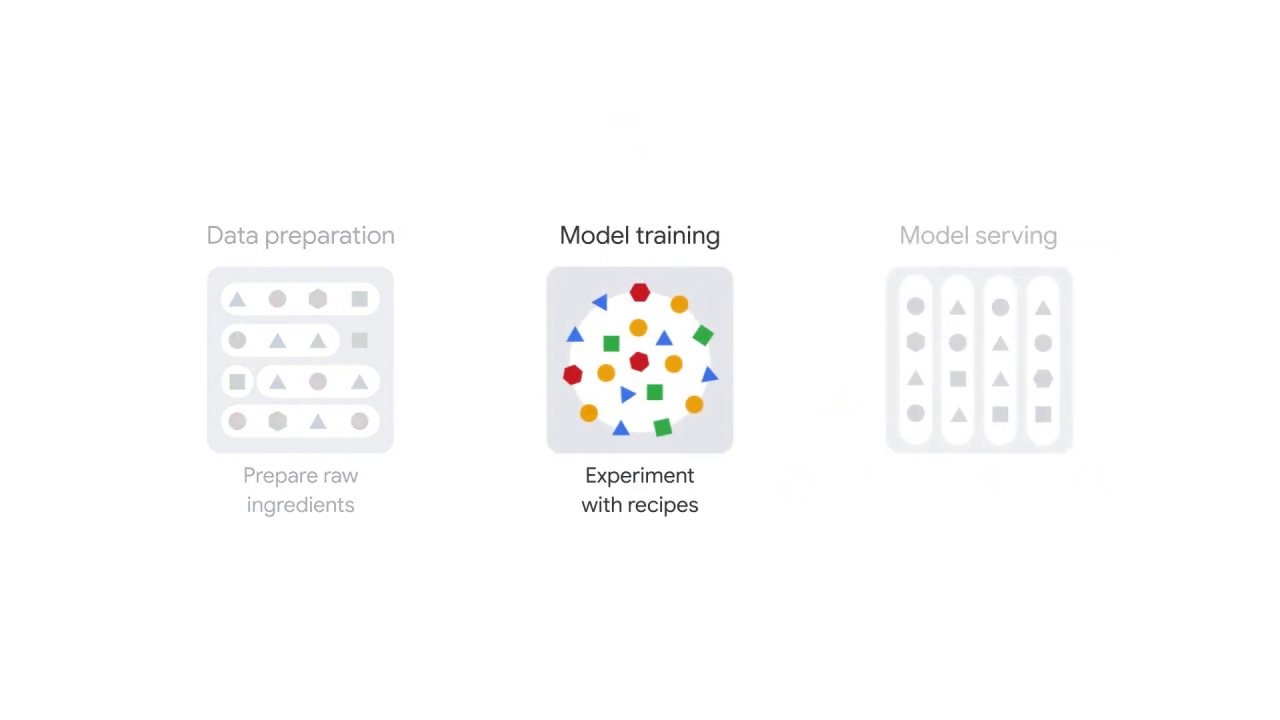
The second stage of the NLP workflow is model training.

Model training includes two steps: model training and model evaluation,

An NLP model, just like the other ML models, needs a tremendous amount of iterative training.
This is when training and evaluation form a cycle where the NLP model is trained, then evaluated, and trained again.
The third and final stage is model serving.

Model serving also includes two steps: model deployment and model monitoring.
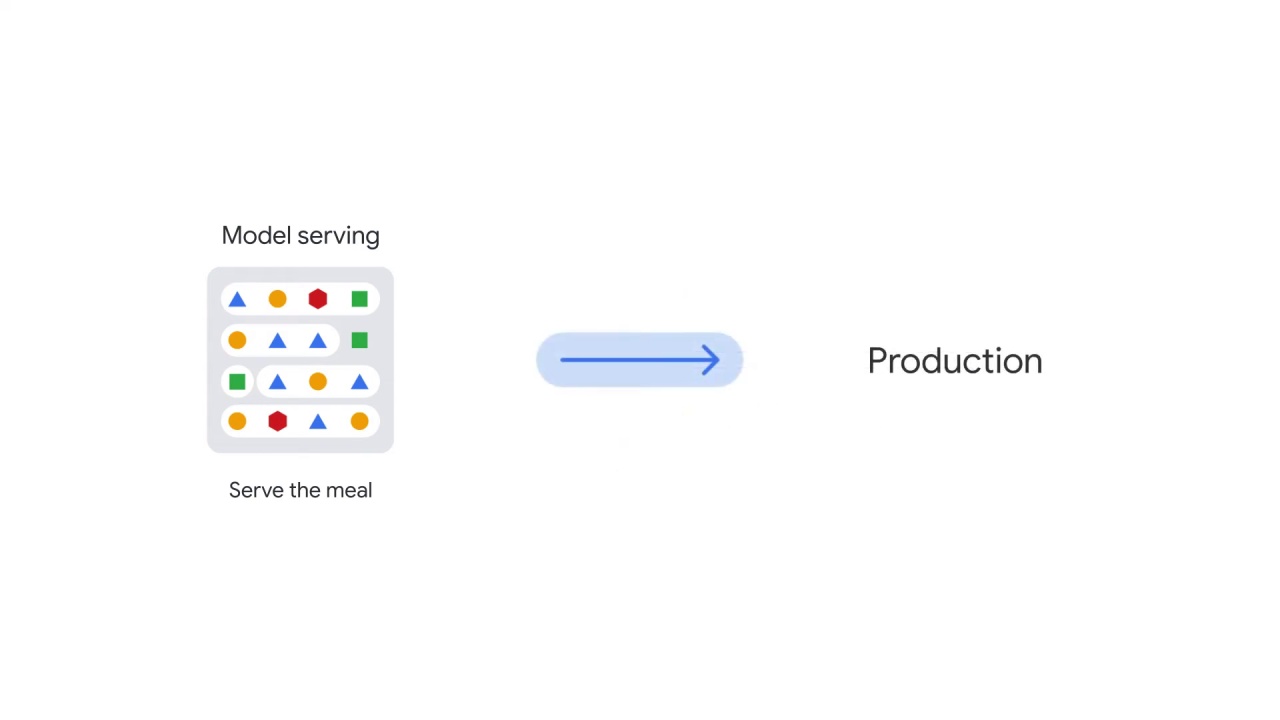
An NLP model needs to be moved into production, otherwise it has no use and remains only a theoretical model.

There are three options to deploy an NLP model.

The first option is to deploy to an endpoint.
This option is best when immediate results with low latency are needed, such as real-time translation.
A model must be deployed to an endpoint before that model can be used to serve real-time predictions.

The second option is to deploy using batch prediction.
This is the best option when no immediate response is required, and accumulated data should be processed with a single request.
For example, sending new ads every other week based on the user’s recent purchasing behavior and what’s currently popular on the market.

And the final option is to deploy using offline prediction.
This is the best option when the model should be deployed in a specific environment outside the cloud.
Now it’s important to note that an NLP workflow isn’t linear, it’s iterative.
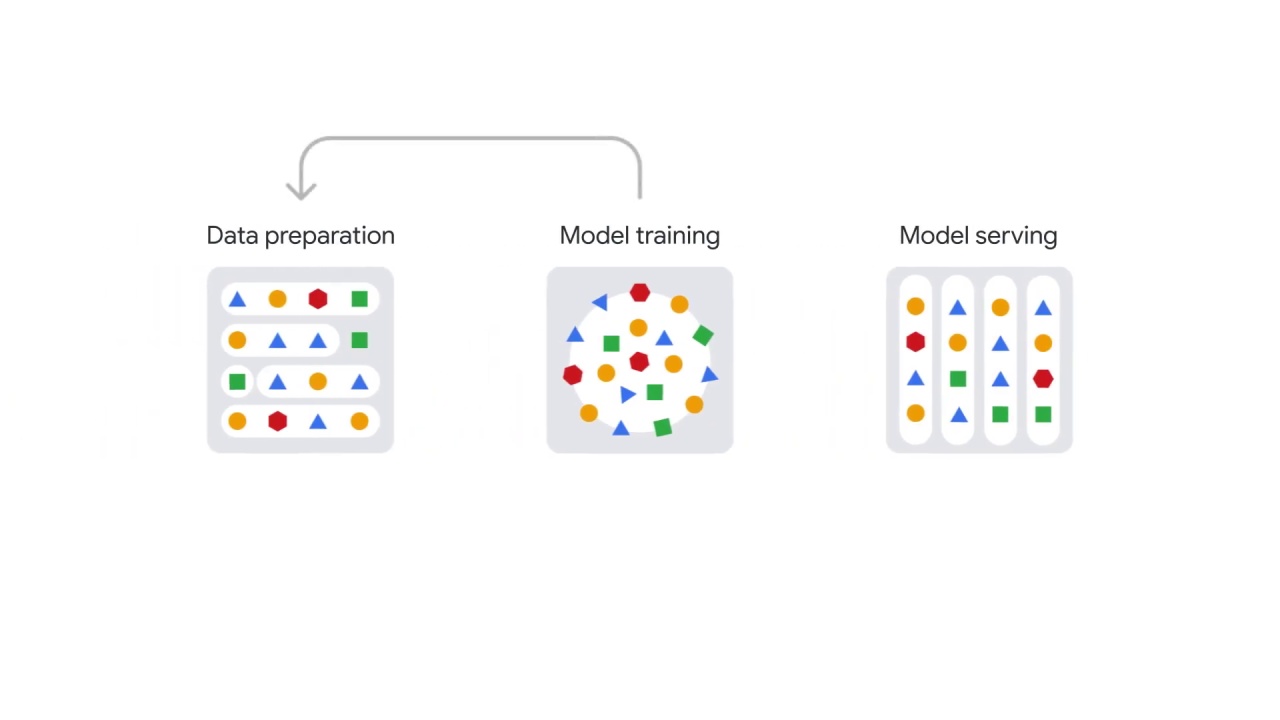
For example, during model training, you might need to return to investigate the raw data and generate more useful features to feed the model.

When monitoring the model during model serving, you might find data drifting, meaning the accuracy of your predictions might suddenly drop.
You might need to check the data sources and adjust the model parameters.
Fortunately, these steps can be automated with machine learning operations, or MLOps.