Right and wrong decisions


Some decisions about data are a matter of weighing

cost vs. benefit, like short-term performance goals against long-term maintainability.
Others, though, are about

right and wrong.
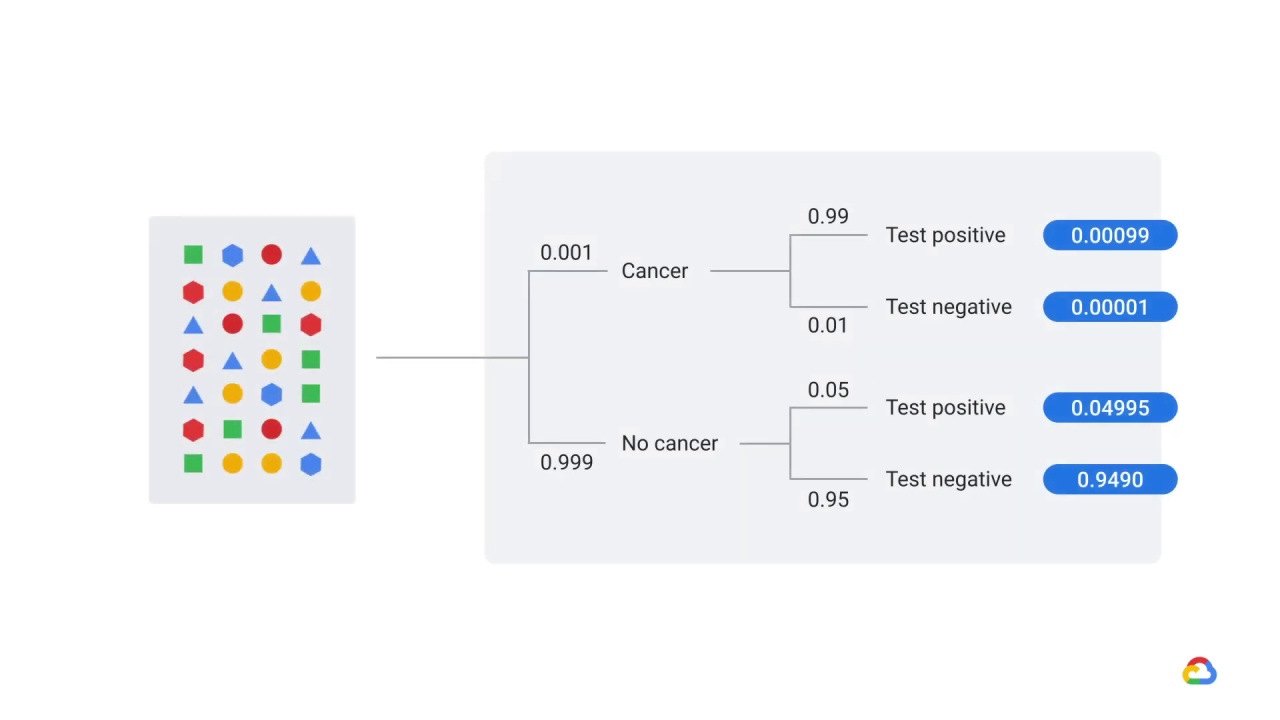
For example, let’s say that you’ve trained a model to predict “probability a patient has cancer” from medical records and
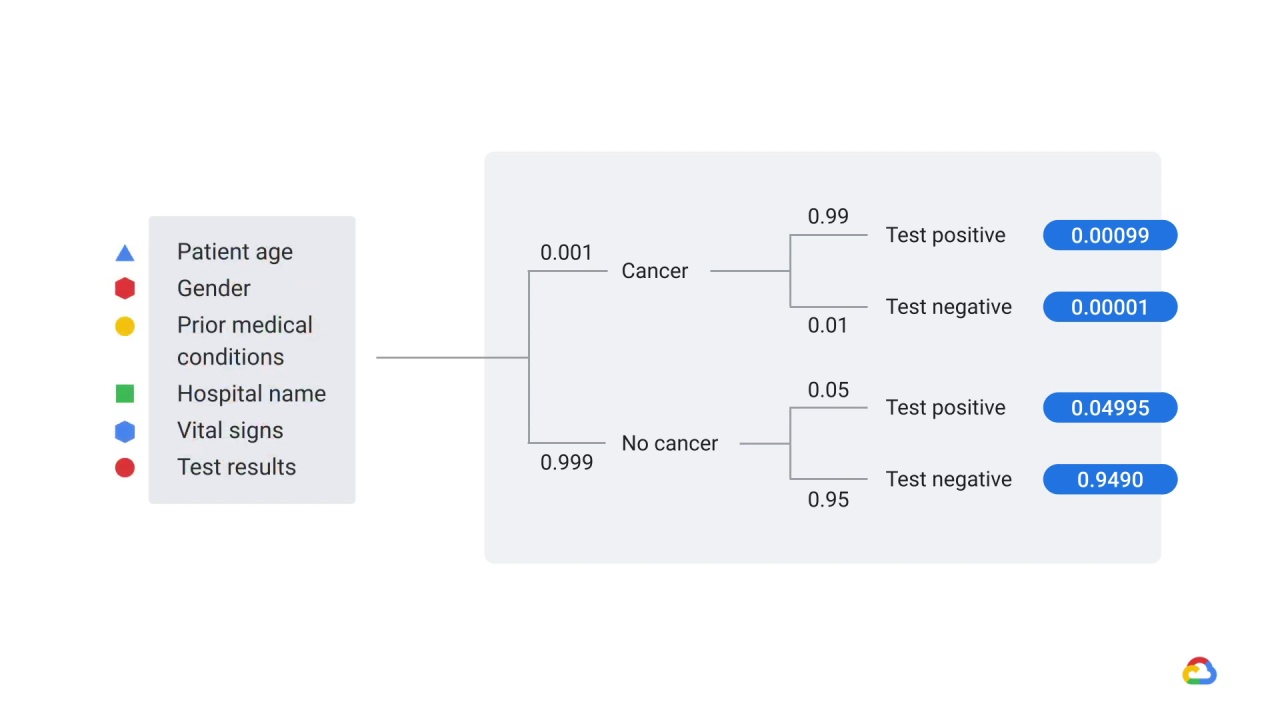
that you’ve selected patient age, gender, prior medical conditions, hospital name, vital signs, and test results as features.
Your model had excellent performance on held-out test data but performed terribly on new patients.

Any guesses as to why?
It turns out the model was trained using a feature
that wasn’t legitimately available at decision time, and so, when the model was deployed into production, the distribution of this feature changed and it was no longer a reliable predictor.
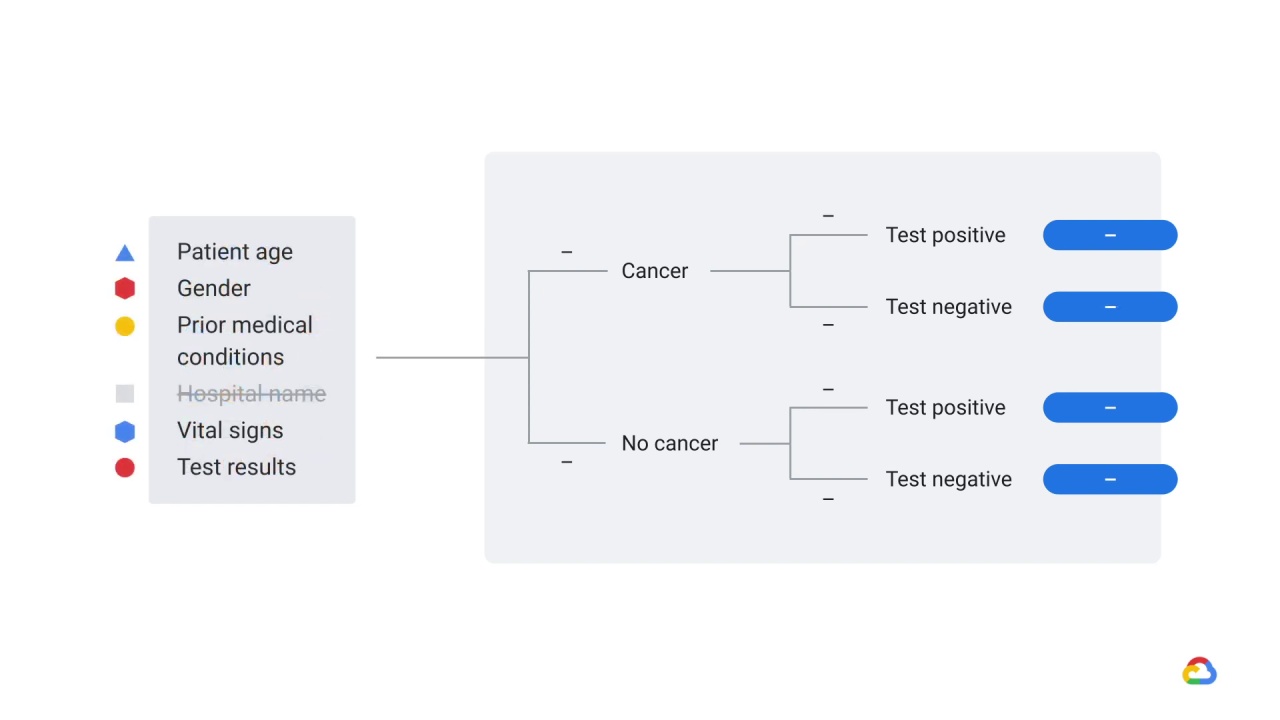
In this case, that feature was ‘hospital name’.
You might think, ‘hospital name’…
How could that be predictive?
Well, remember that there are some hospitals that focus on diseases like cancer.
So, the model learned that ‘hospital name’ was very important.

However, at decision time, this feature wasn’t available to the model, because patients hadn’t yet been assigned to a hospital, but rather than throwing an error, the model simply interpreted the hospital name as an empty string, which it was still capable of handling thanks to out-of-vocabulary buckets in its representations of words.

We refer to this idea where the label is somehow leaking into the training data as data leakage.

Data leakage is related to a broader class of problems.

where we talked about models learning unacceptable strategies.

Previously, we learned that when there’s class imbalances, a model might learn to predict the majority class.
In this case, the model has learned to use a feature that wouldn’t actually be known and which cannot be plausibly causally related to the label.

Here’s a similar case.
A professor of 18th century literature believed that there was a relationship between

how an author thought about the mind
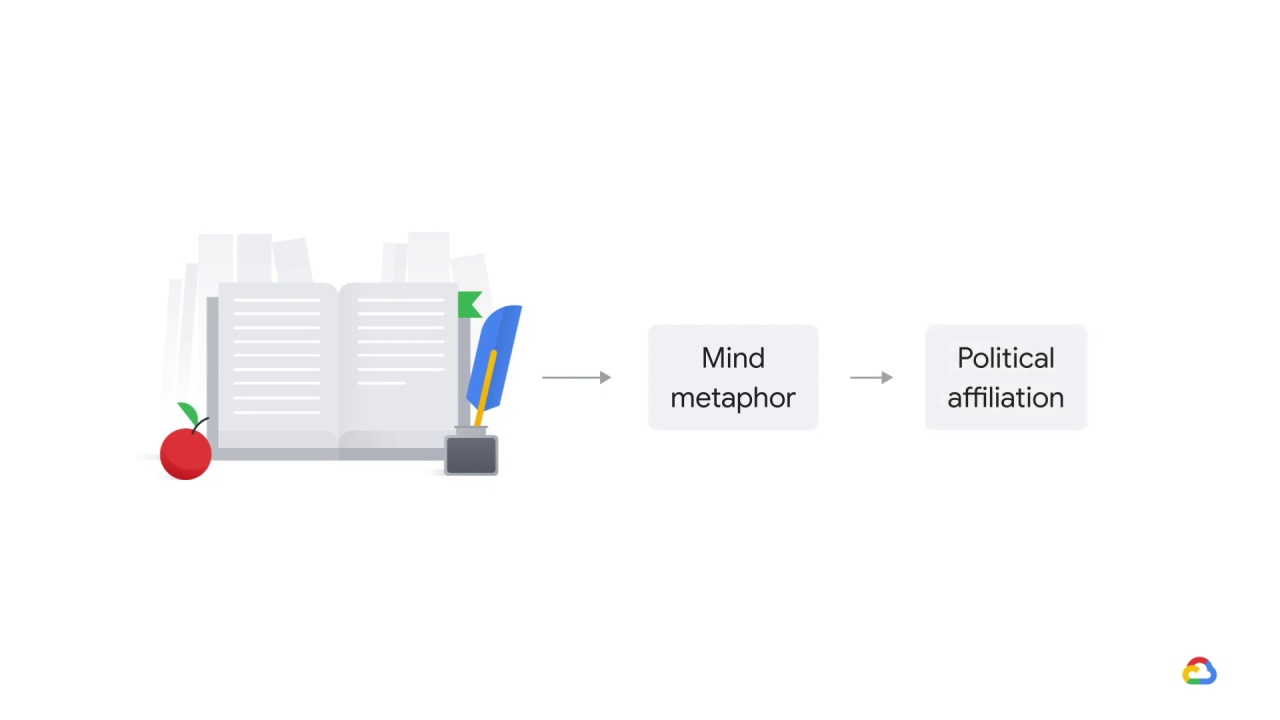
and their political affiliation.

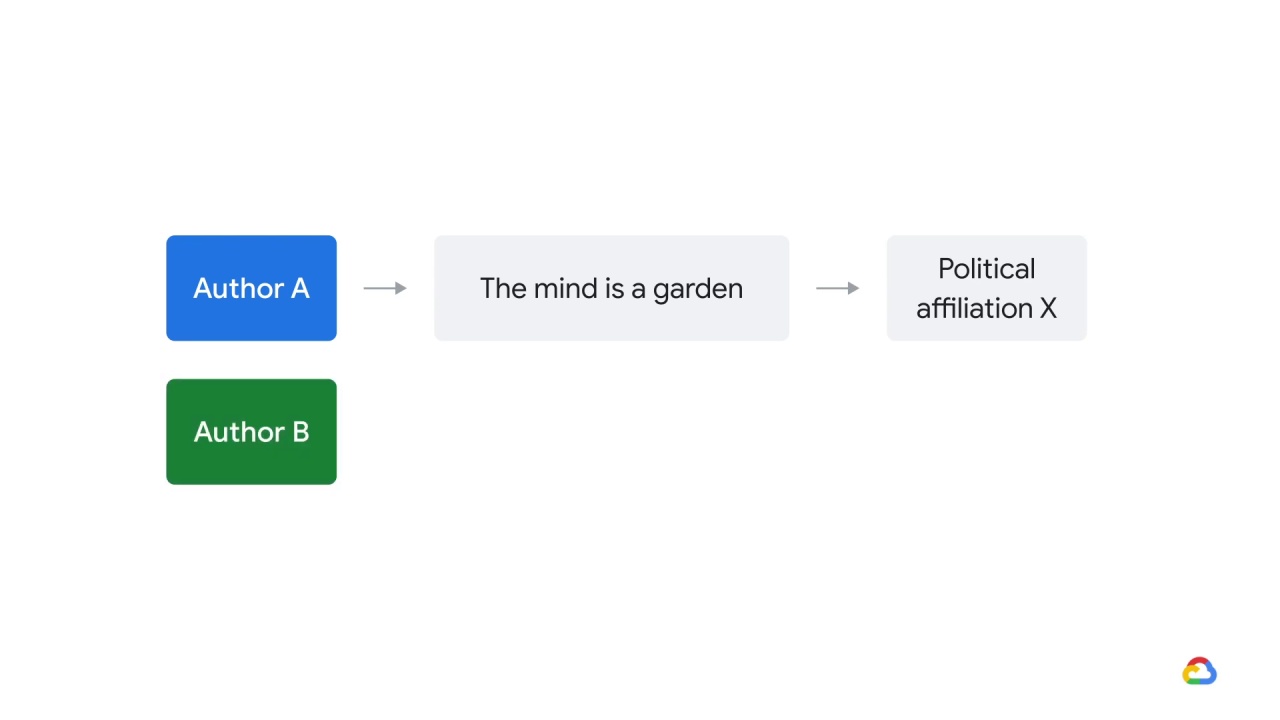
So, for example, perhaps authors who used language like

“the mind is a garden”
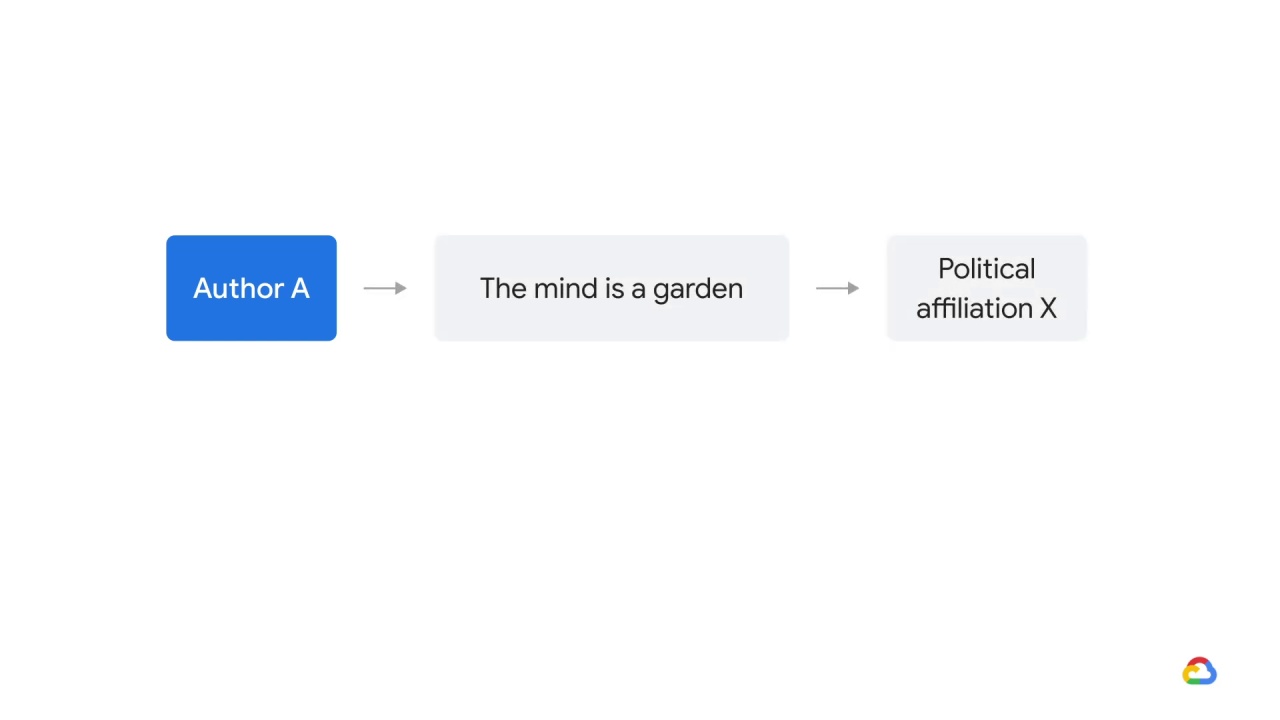
had one political affiliation
and authors who used language like
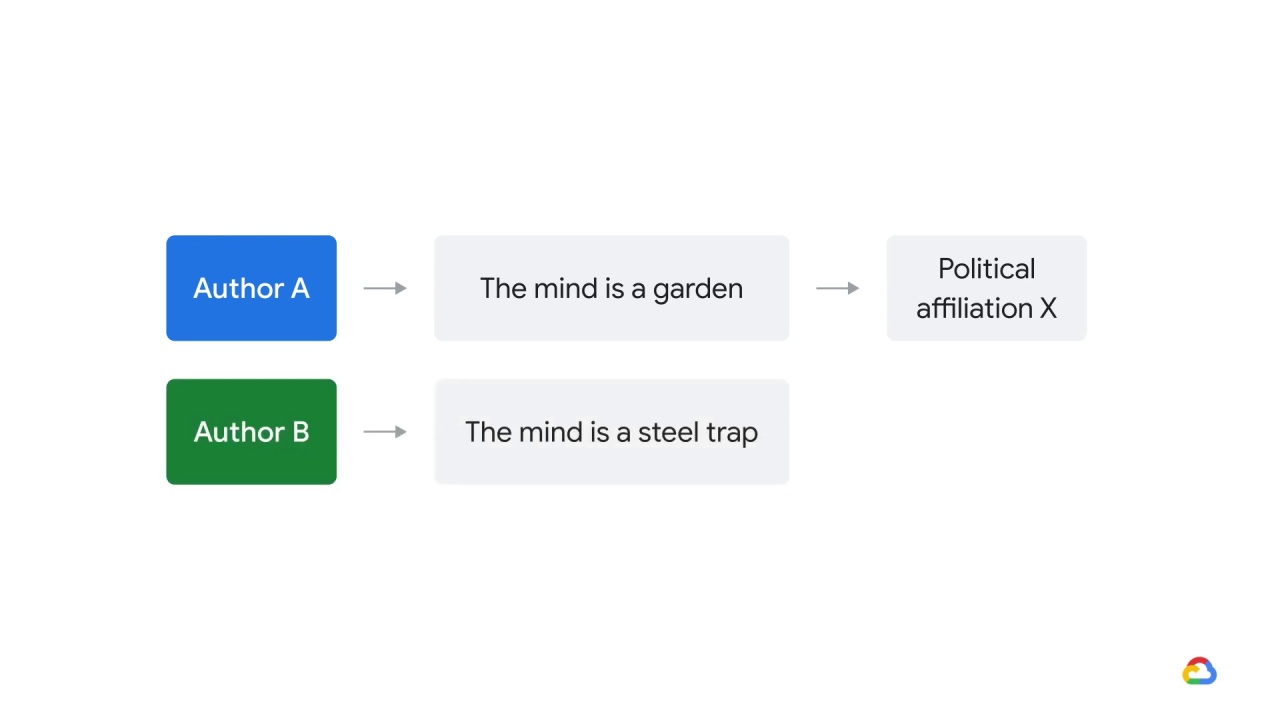
“the mind is a steel trap”
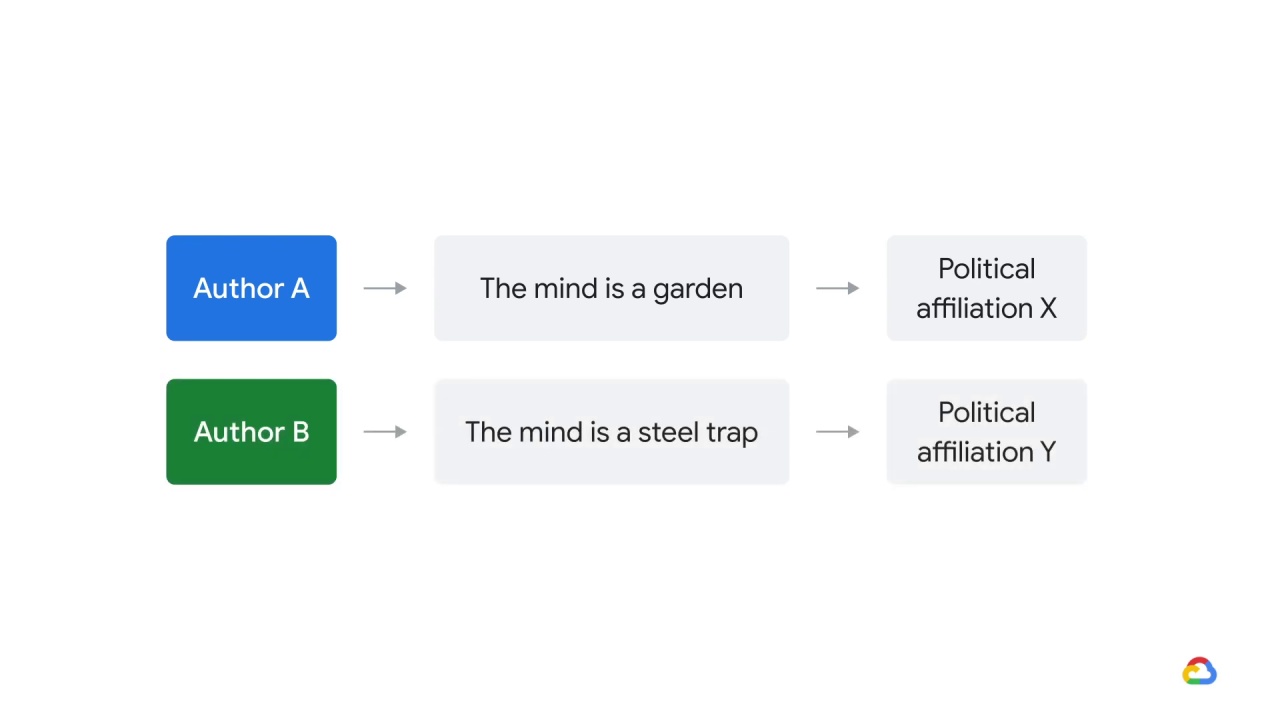
another. Here’s what they did.

What if we were to naively test this hypothesis with machine learning?
Some people tried that and they got some unexpected results.
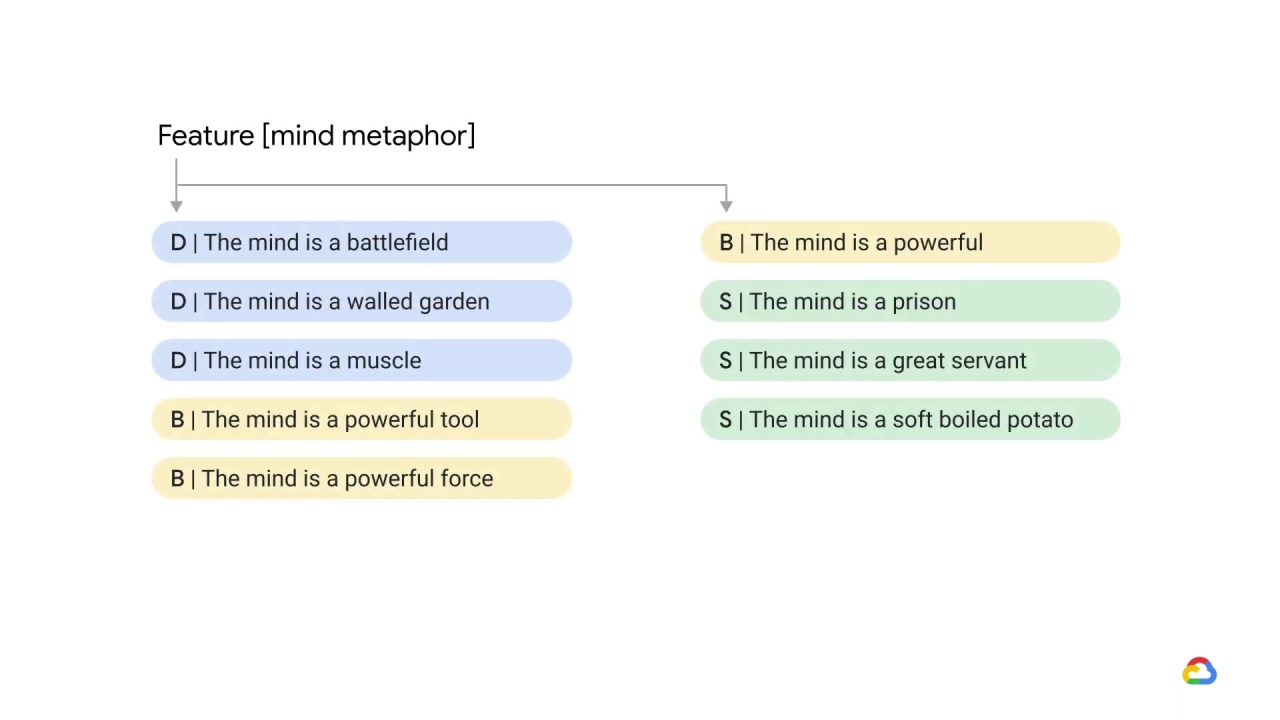
They took all of the sentences in all of the works by a number of 18th century authors, extracted just the mind metaphors and set those as their features
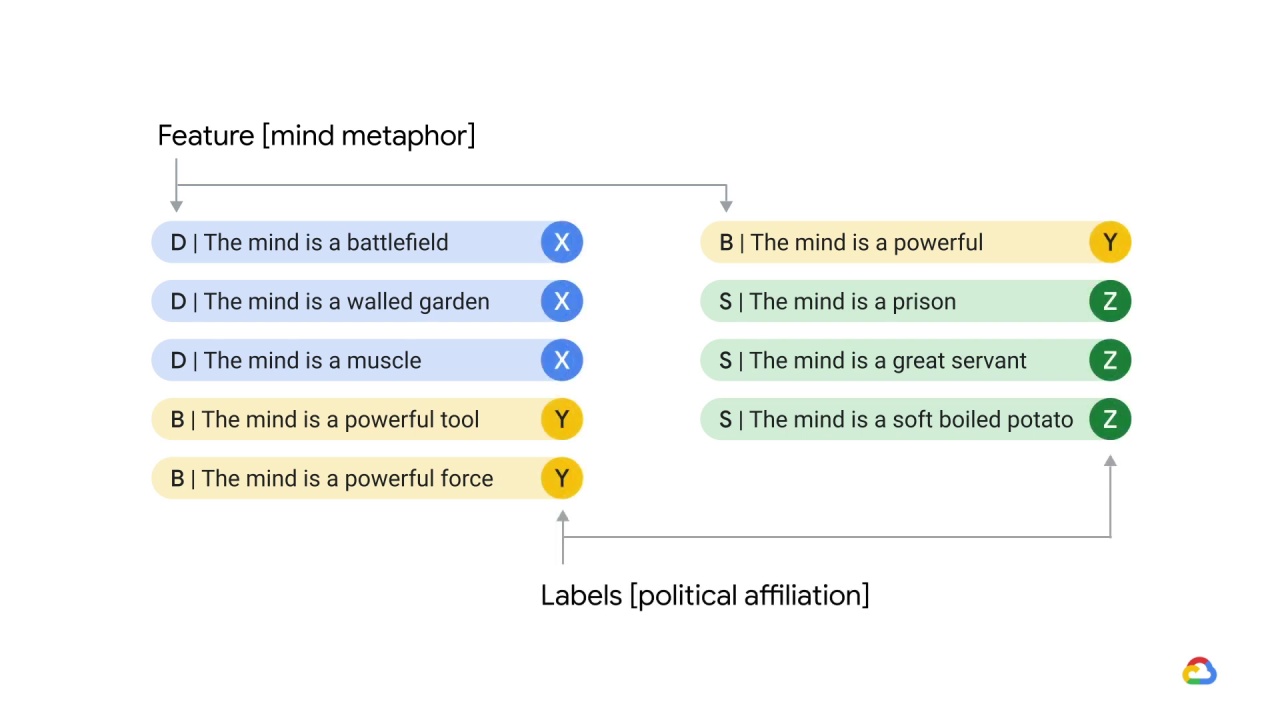
and set those as their features and then used the political affiliations of the authors who wrote them as labels.

Then, they randomly assigned sentences to each of the training, validation, and test sets.
And because they divided the data in this way, some sentences from each author were distributed to each of those three sets.
And the resulting model was amazing! … But suspiciously amazing.

What might have gone wrong?

One way to think about it is that political affiliation is linked to that person.
And if we wouldn’t include ‘person name’ in the feature set, we should not include it implicitly either

When the researchers changed the way they partition the data and instead partitioned it by author instead of by sentence, the model’s accuracy dropped to something more reasonable.