Training
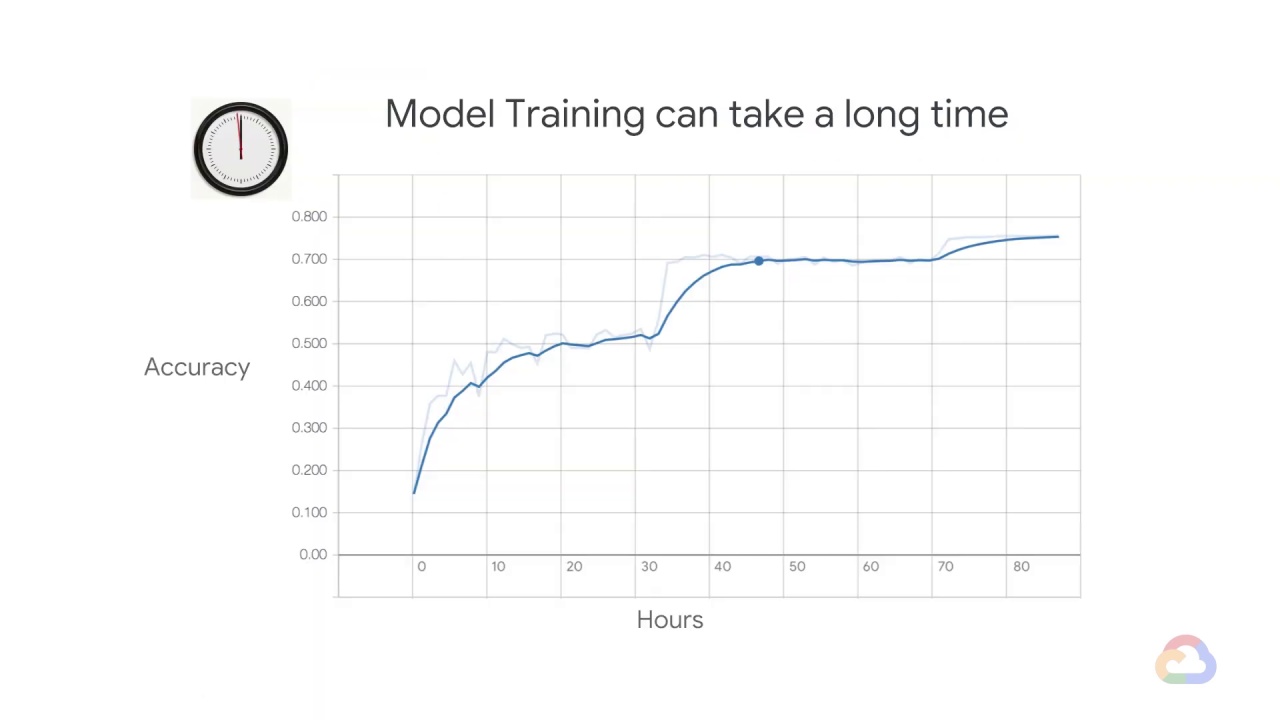
How long are you willing to spend on the model training?
This might be driven by the business use case.
If you are training a model everyday so as to recommend products to users the next day
then your training has to finish within 24 hours.
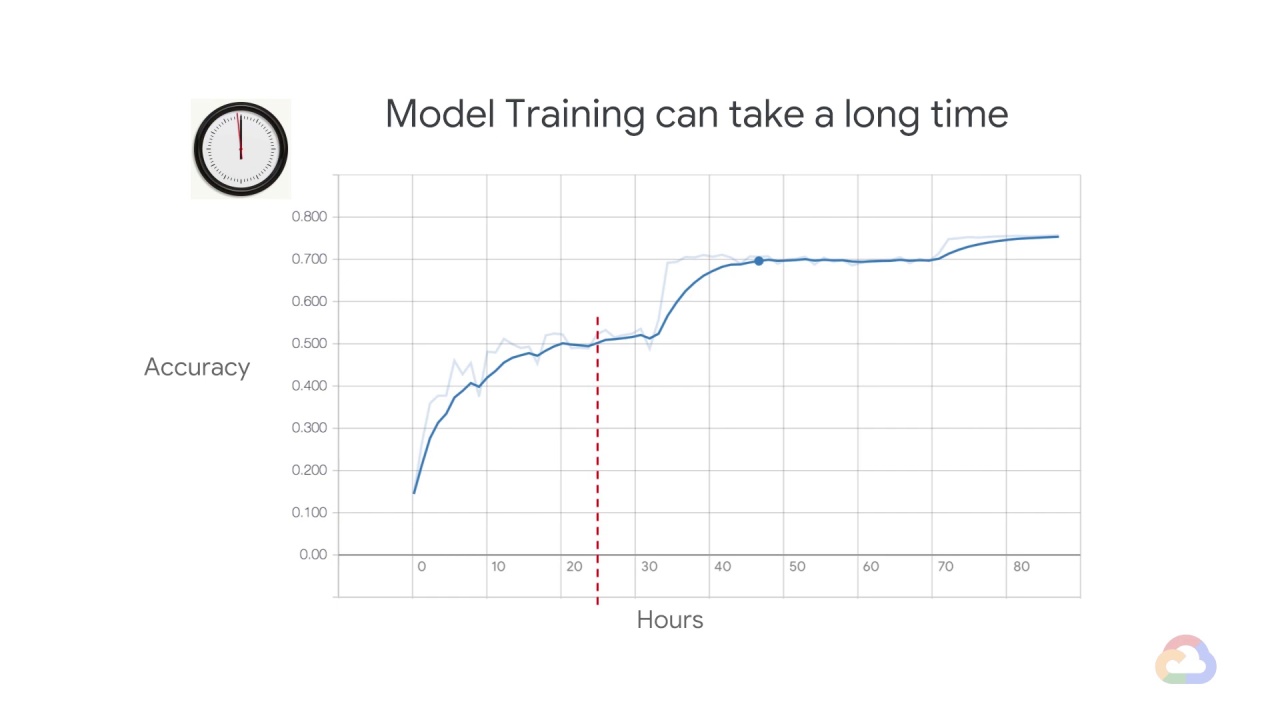
Realistically, you will need to time to deploy, to A/B test, etc.
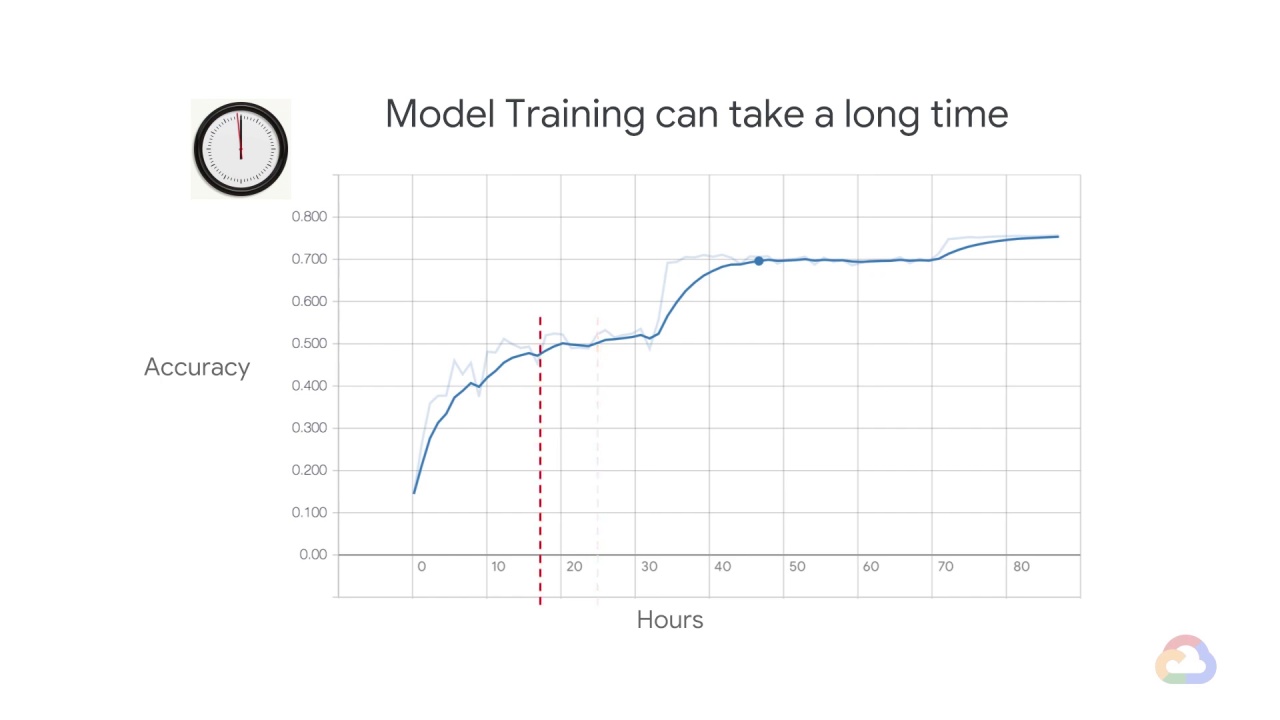
So, your actual budget might be only 18 hours.

In addition, there are ways to tune performance to reduce the time, reduce the cost, or increase the scale.
In order to understand what these are, it helps to understand that model training performance will be bound by one of three things:

input/output – how fast can you get data into the model in each training step.

CPU – how fast can you compute the gradient in each training step.

Memory – how many weights can you hold in memory, so that you can do the matrix multiplications in-memory on the
GPUorTPU.

Your ML training will be I/O bound if the number of inputs is large, heterogeneous (requires parsing), or if the model is so small that the compute requirements are trivial.
This also tends to be the case if the input data is on a storage system with low throughput.

Your ML training will be CPU bound if the I/O is simple, but the model involves lots of expensive computations.
You will also encounter this situation if you are running a model on underpowered hardware.

Your ML training might be memory-bound if the number of inputs is large or if the model is complex and has lots of free parameters.
You will also face memory limitations if your accelerator doesn’t have enough memory.
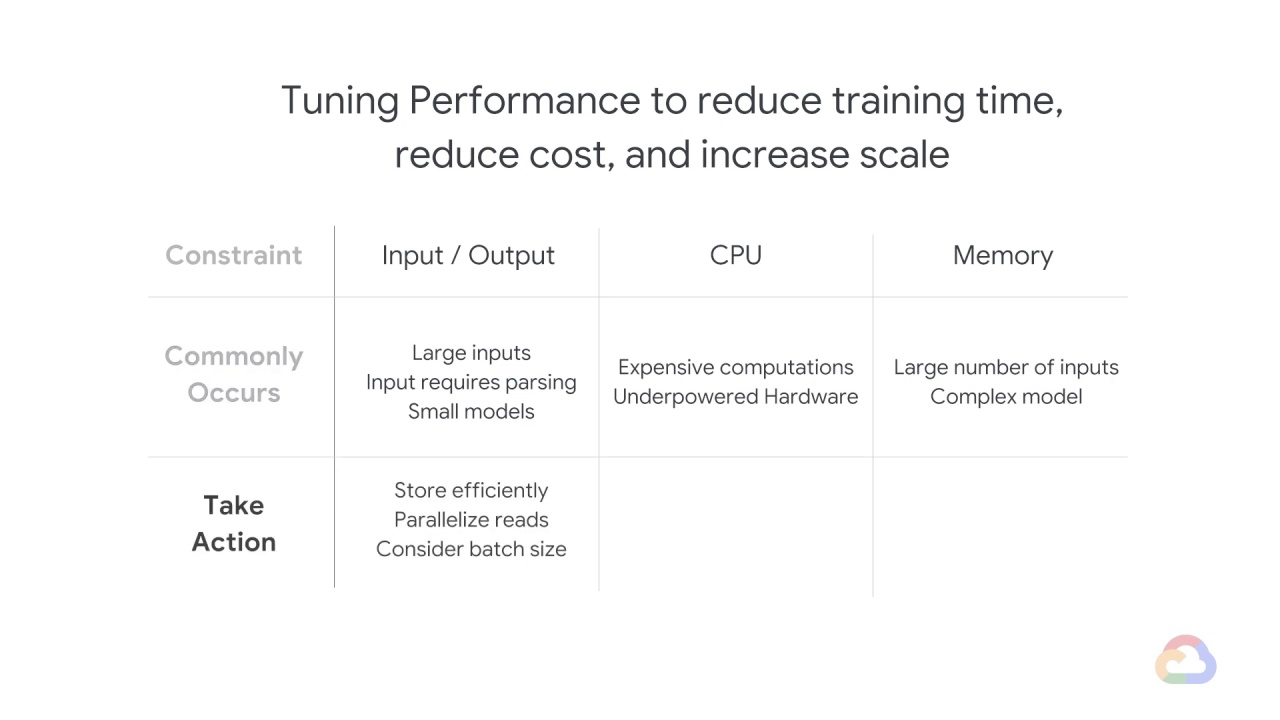
So, knowing what you are bound by, you can look at how to improve performance.
If you are I/O bound, look at storing the data more efficiently, on a storage system with higher throughput, or parallelizing the reads.
Although it is not ideal, you might consider reducing the batch size so that you are reading less data in each step.

If you are CPU-bound, see if you can run the training on a faster accelerator.
GPUs keep getting faster, so move to a newer generation processor.
And on Google Cloud, you also have the option of running on TPUs.
Even if it is not ideal, you might consider using a simpler model, a less computationally expensive activation function or simply just train for fewer steps.

If you are memory-bound, see if you can add more memory to the individual workers.
Again, not ideal, but you might consider using fewer layers in your model.
Reducing the batch size can also help with memory-bound ML systems.