Word2vec
Now you might agree that representing text with vectors is a good idea.

But how exactly does it work?

Let’s look at word2vec and walk you through the neural network training process.

Word2vec was created by a team of Google researchers led by Tomas Mikolov in 2013.

Let’s start with intuition.
Think about how you learn new vocabulary while reading back in elementary schools.

You read,

guess,

and you remember.

How do you guess the meaning of a new word?
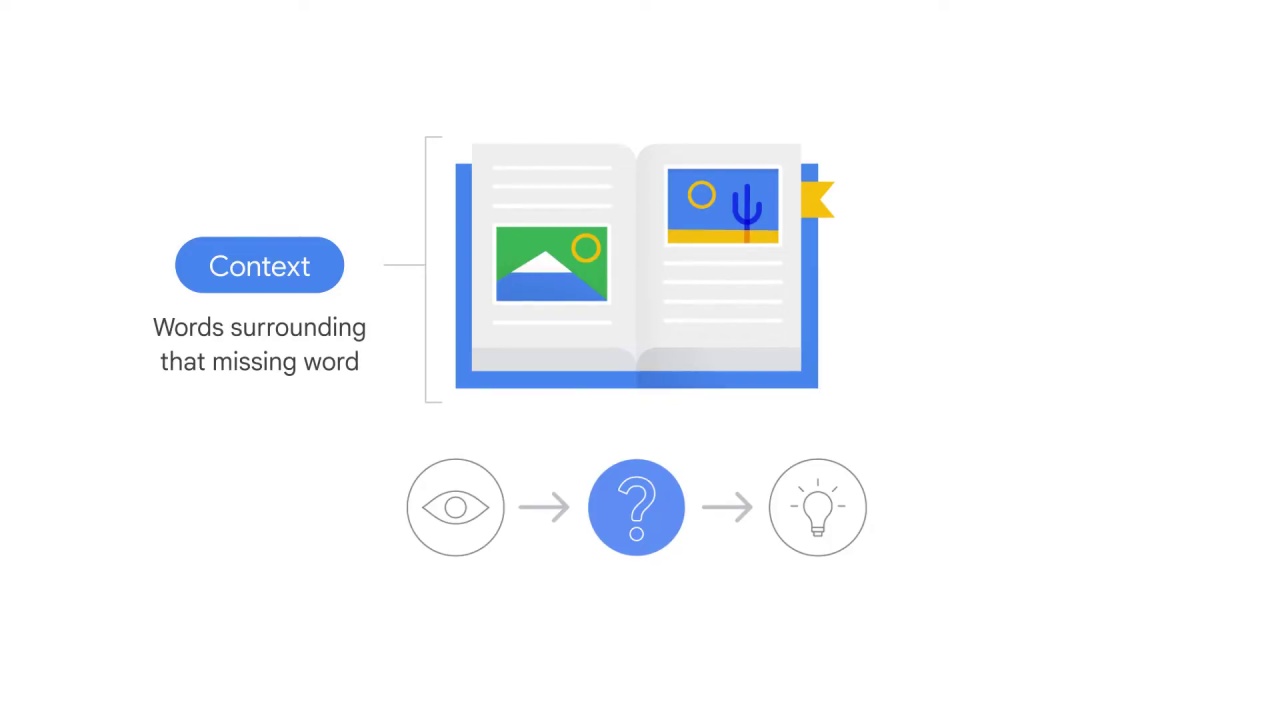
normally through the context, meaning the words surrounding that missing word.

For example, look at this sentence. ___

As an eight-year-old, you don’t recognize the word acumen, but you might guess through the context that this word probably means intelligence and sharp judgment.

The idea of using context to predict words applies to word2vec.


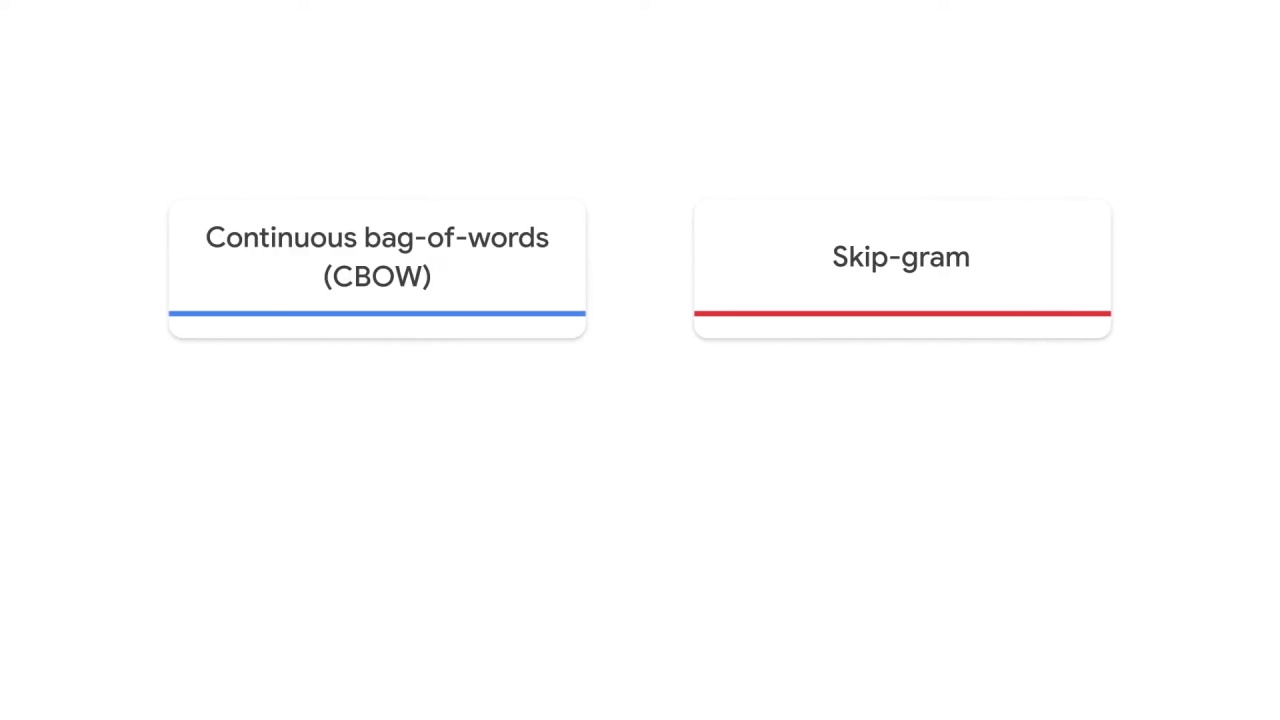
You’ll explore two major variants of word2vec: continuous bag-of-words (CBOW) and skip-gram.
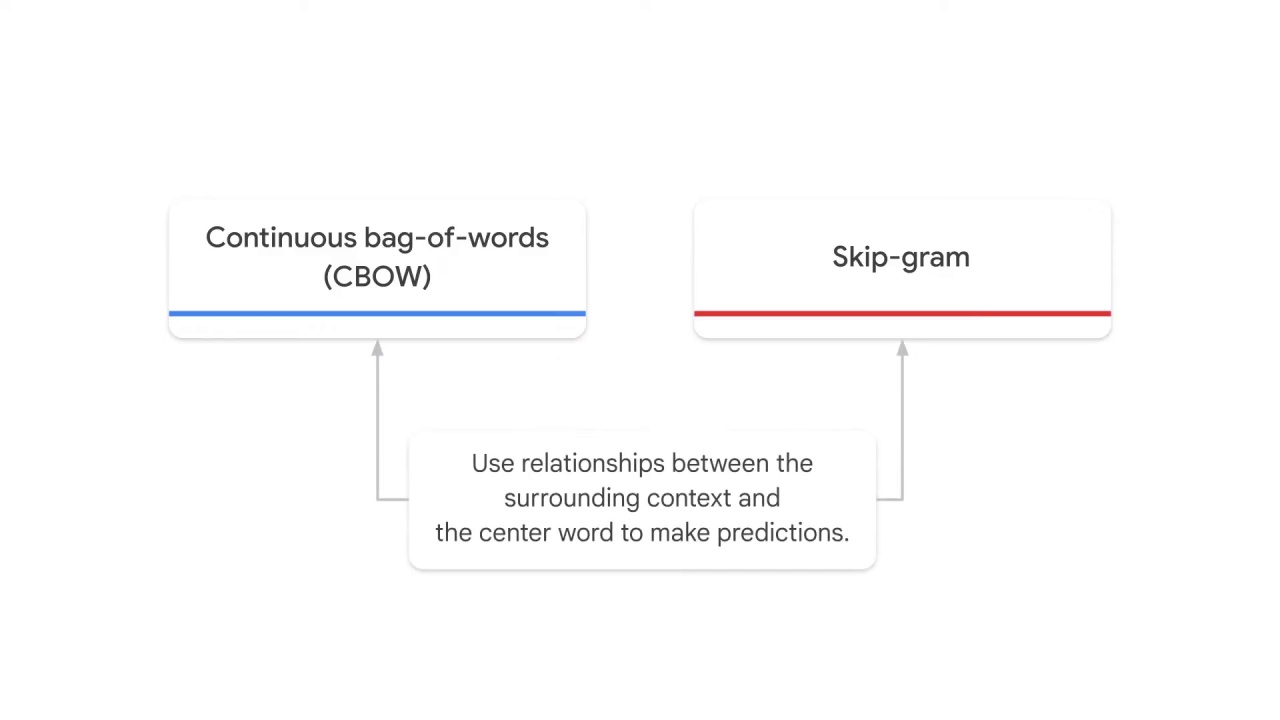
Both algorithms rely on the same idea of using relationships between the surrounding context and the center word to make predictions,
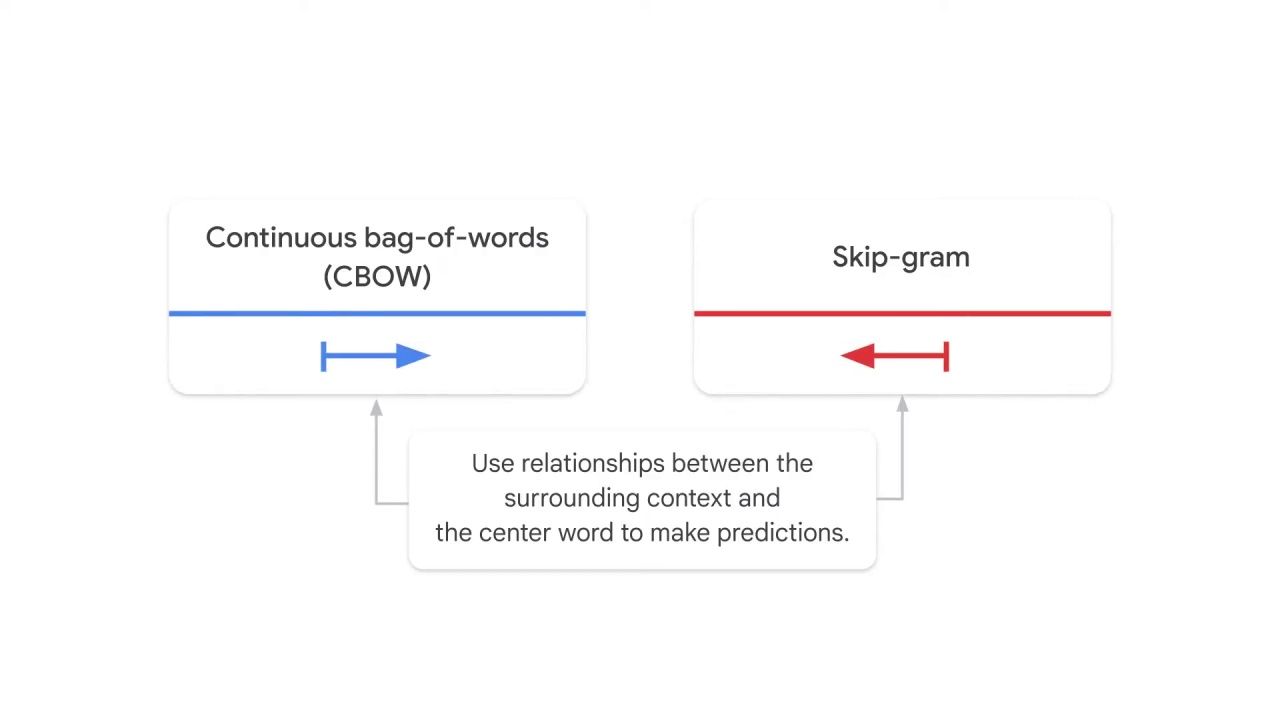
but in opposite directions.

Continuous bag-of-words predicts the center word given the context words,

and skip-gram predicts the context words given the center word.


Assume you miss the center word chasing
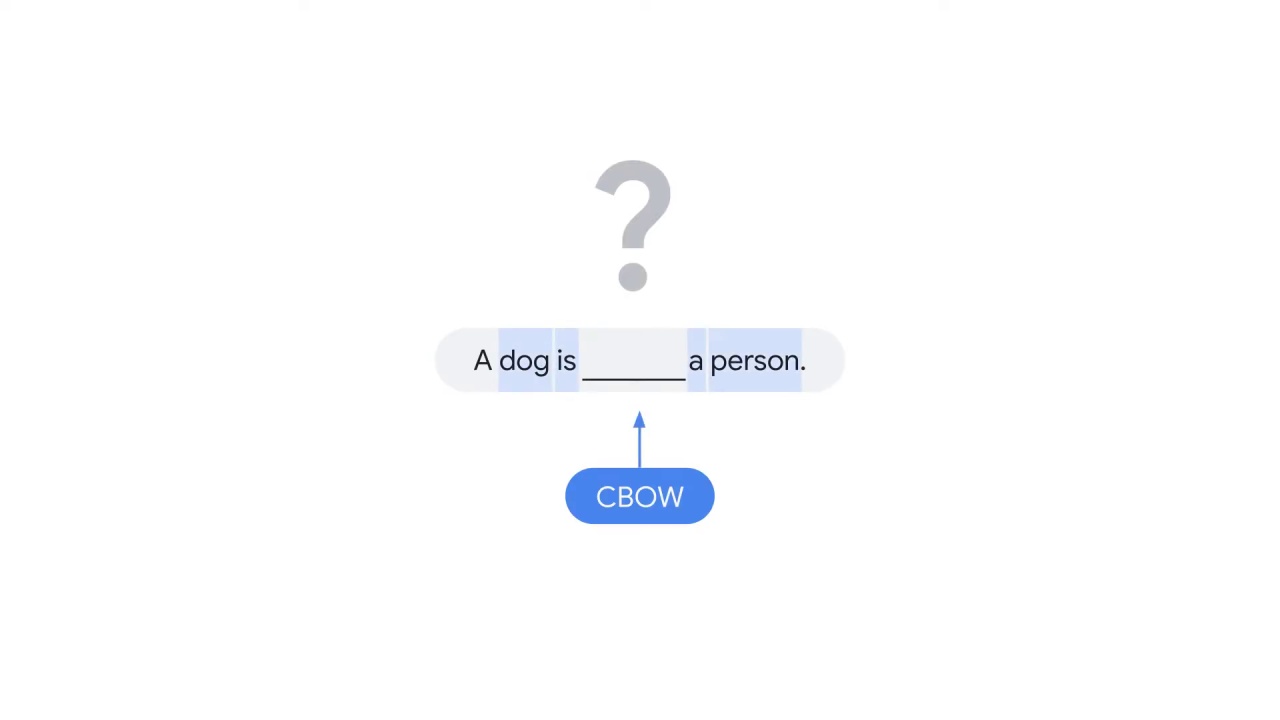
and CBOW tries to use the context words, dog, is, a, and person to predict the missing word.
How does it work technically?

Let’s walk through the two primary steps:
preparing the dataset and
training the neural network.
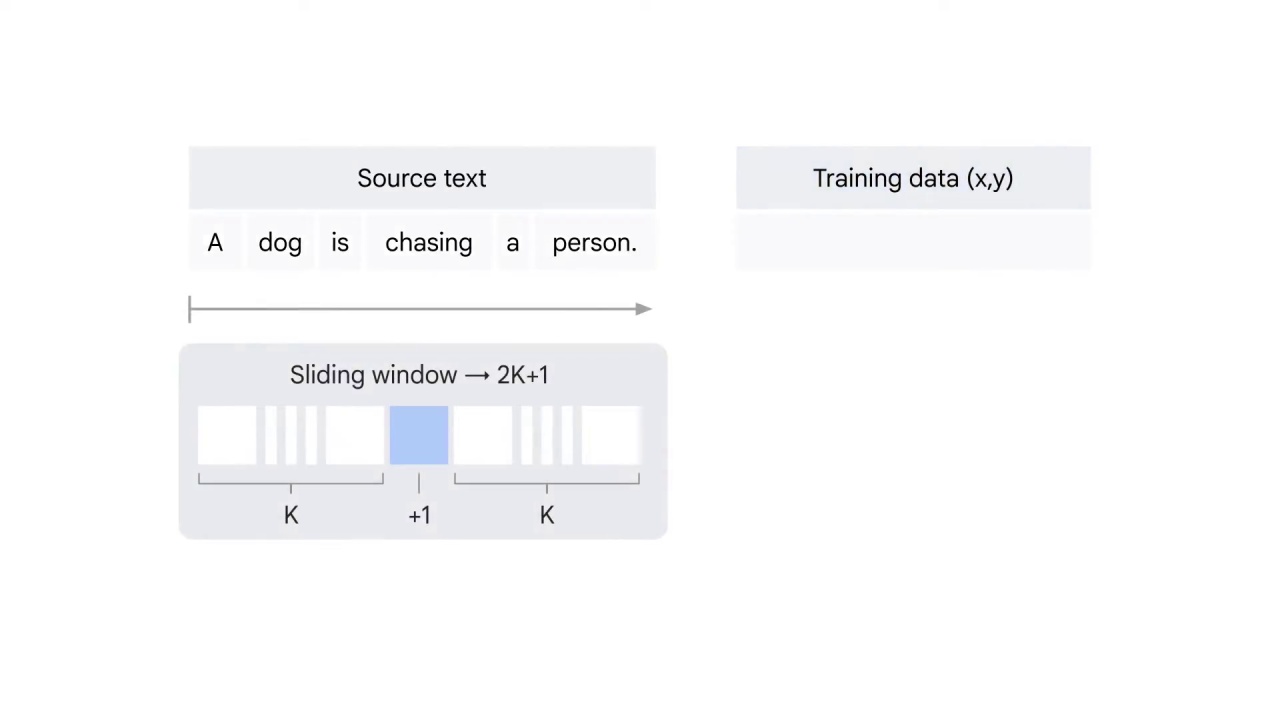
Prepare the training data.
You run a sliding window of size 2K+1
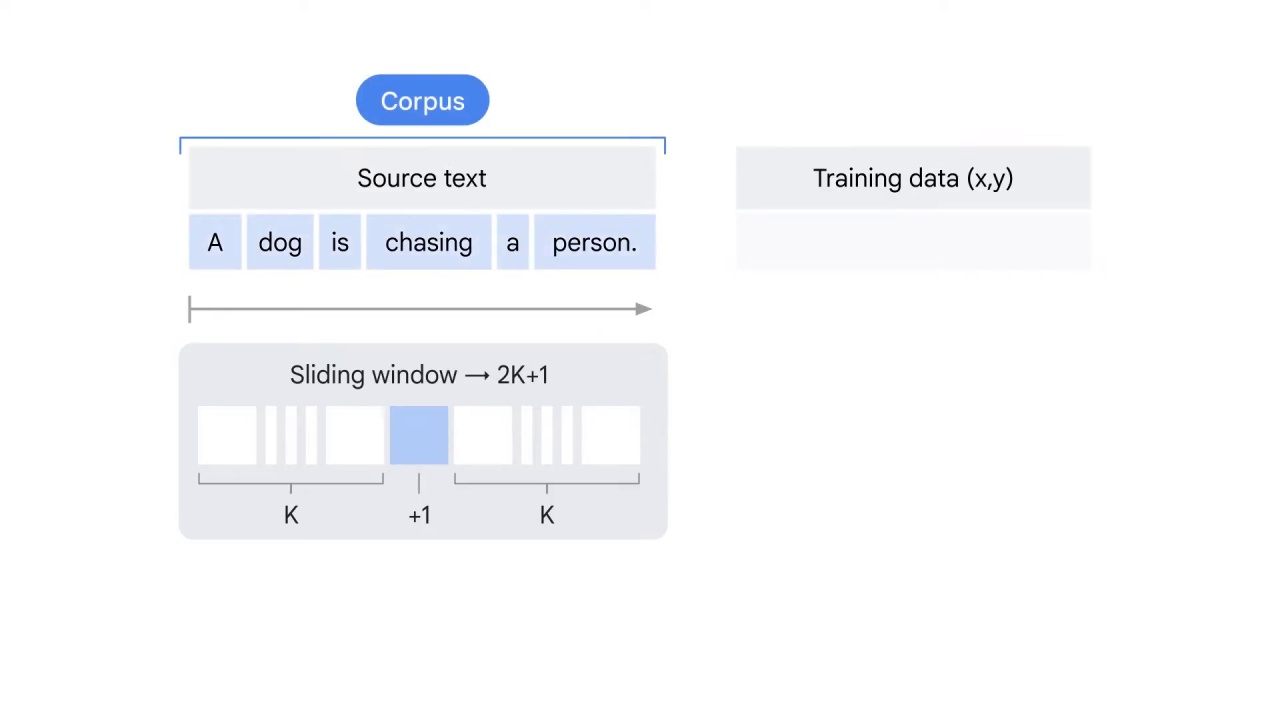
over the entire text corpus.
You might hear the word corpus often in NLP. It basically means a collection of words or a body of words.
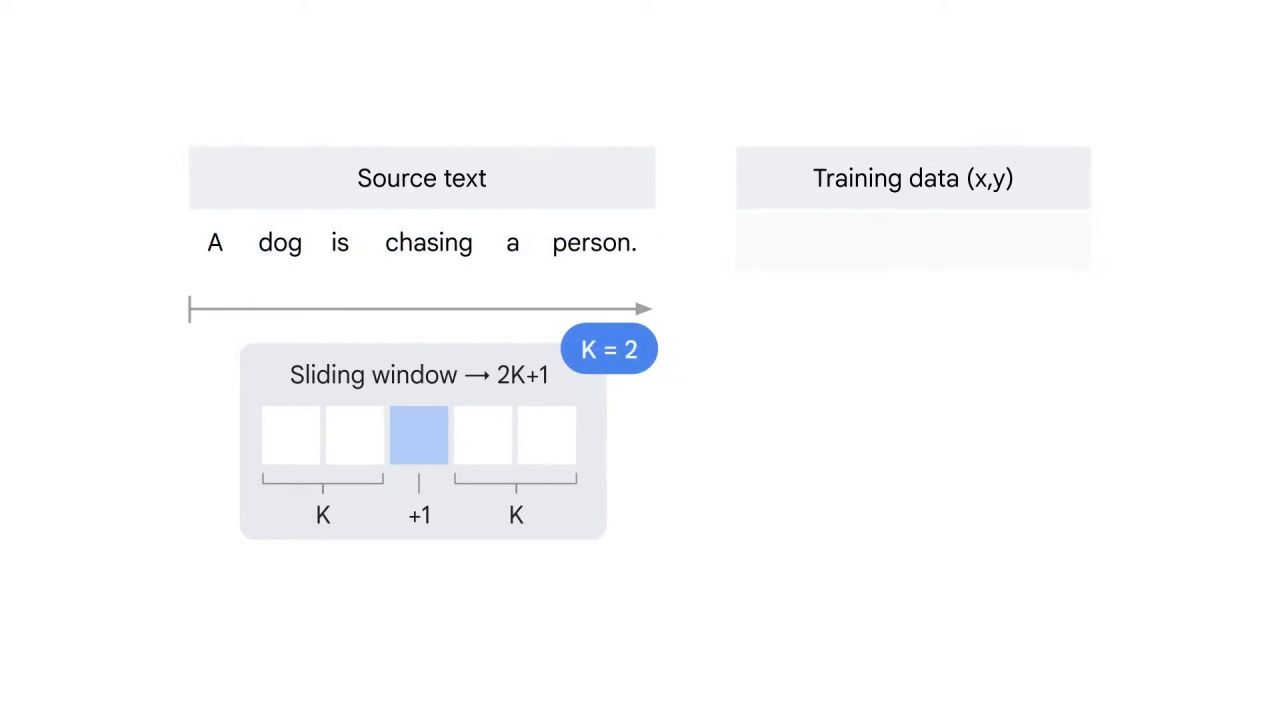
To put simply, let’s say K equals to 2.
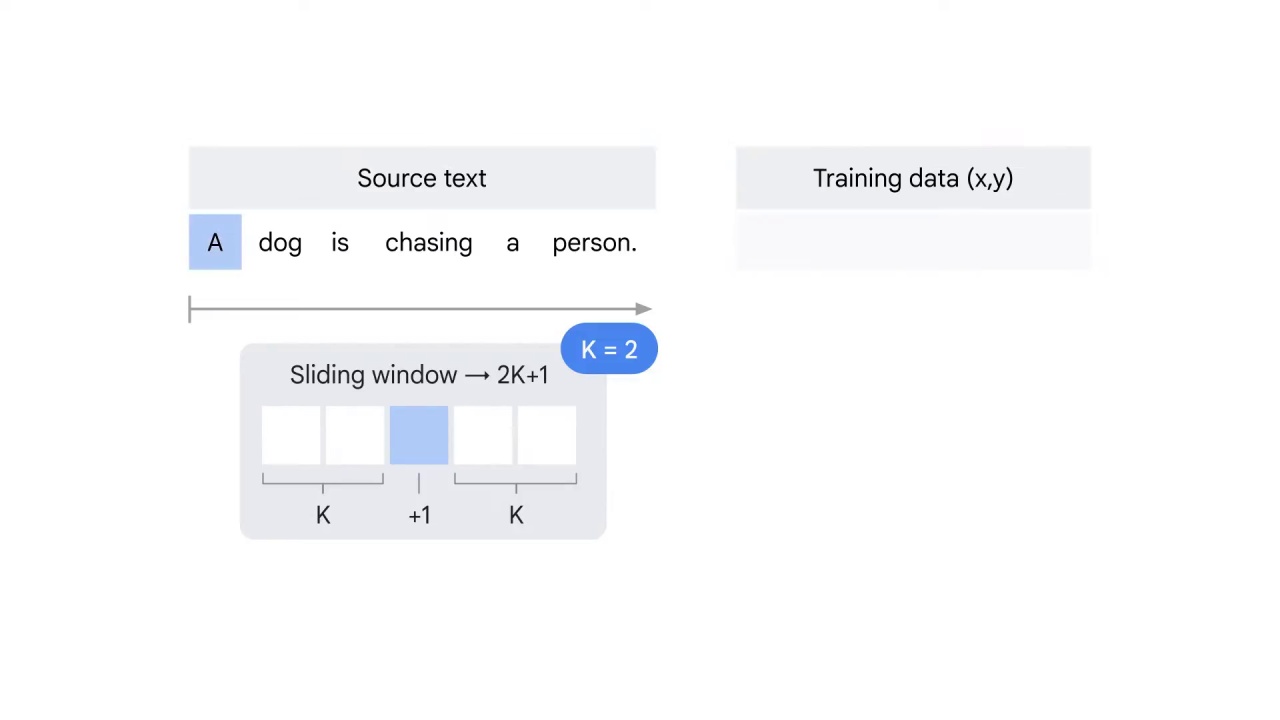
You start with the first word A.
To run a 2K+1 window and K equals to 2,
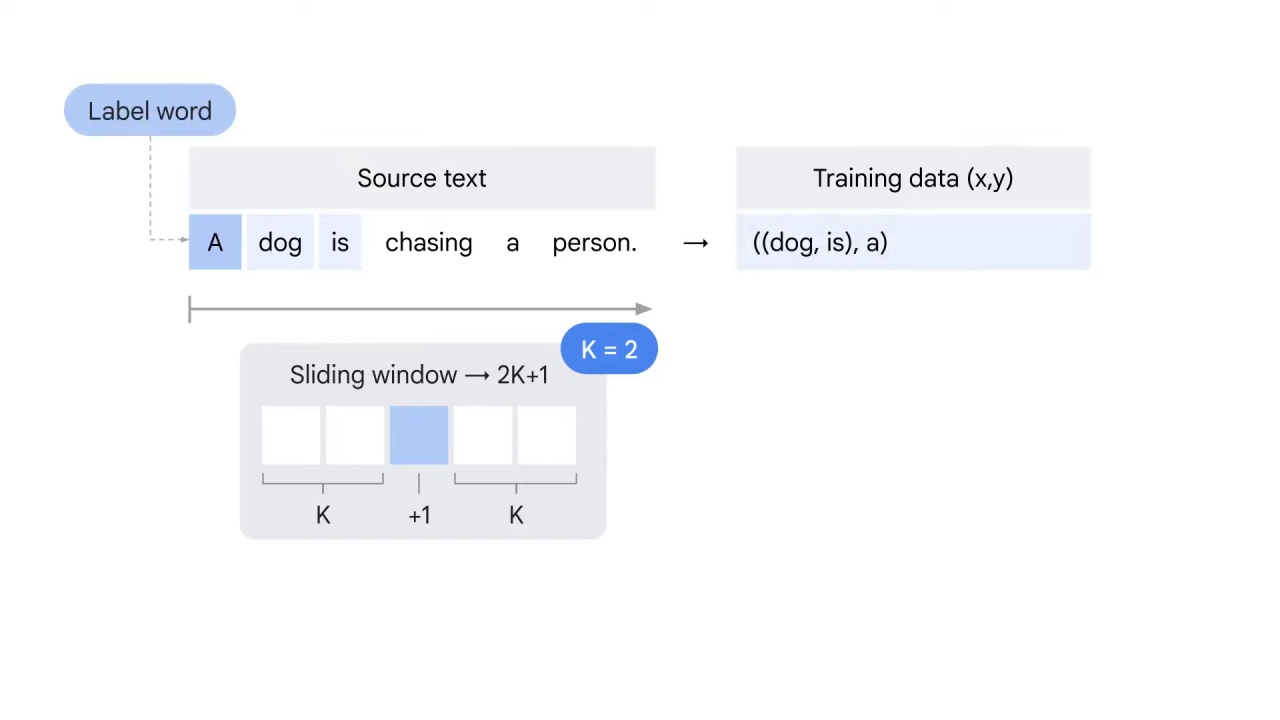
You have two words before and after the center word A.
No words before A but two words after A.
Therefore, the two words after A, dog and is, will be used to predict A, which is sometimes called the label word.
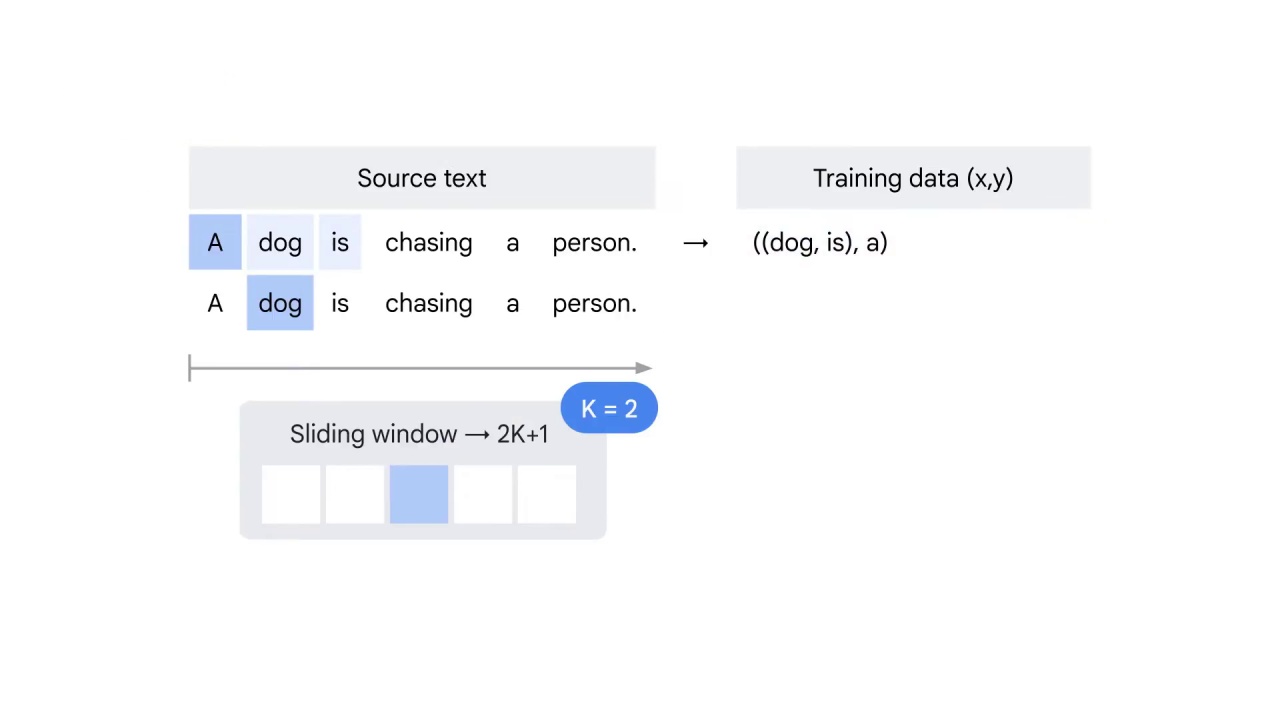
Then the window shifts to the second word dog as the center word.
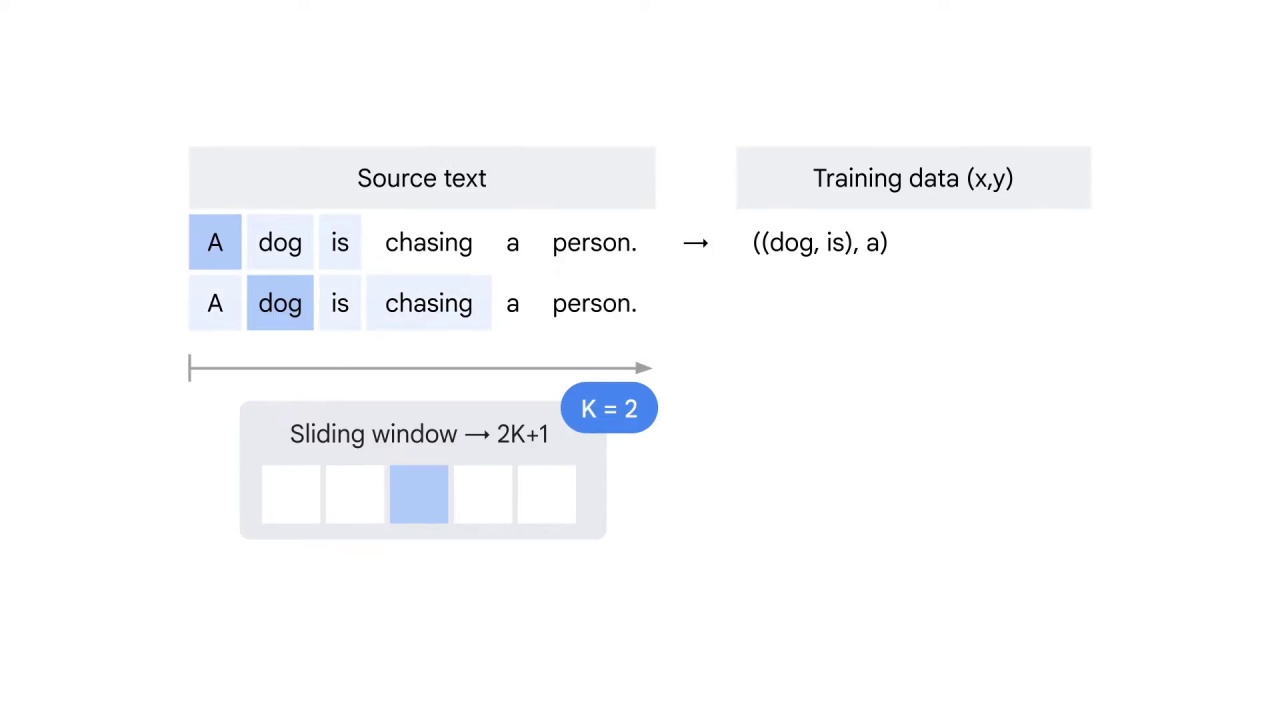
Dog will be predicted by the word A before it and the words is and chasing after it.
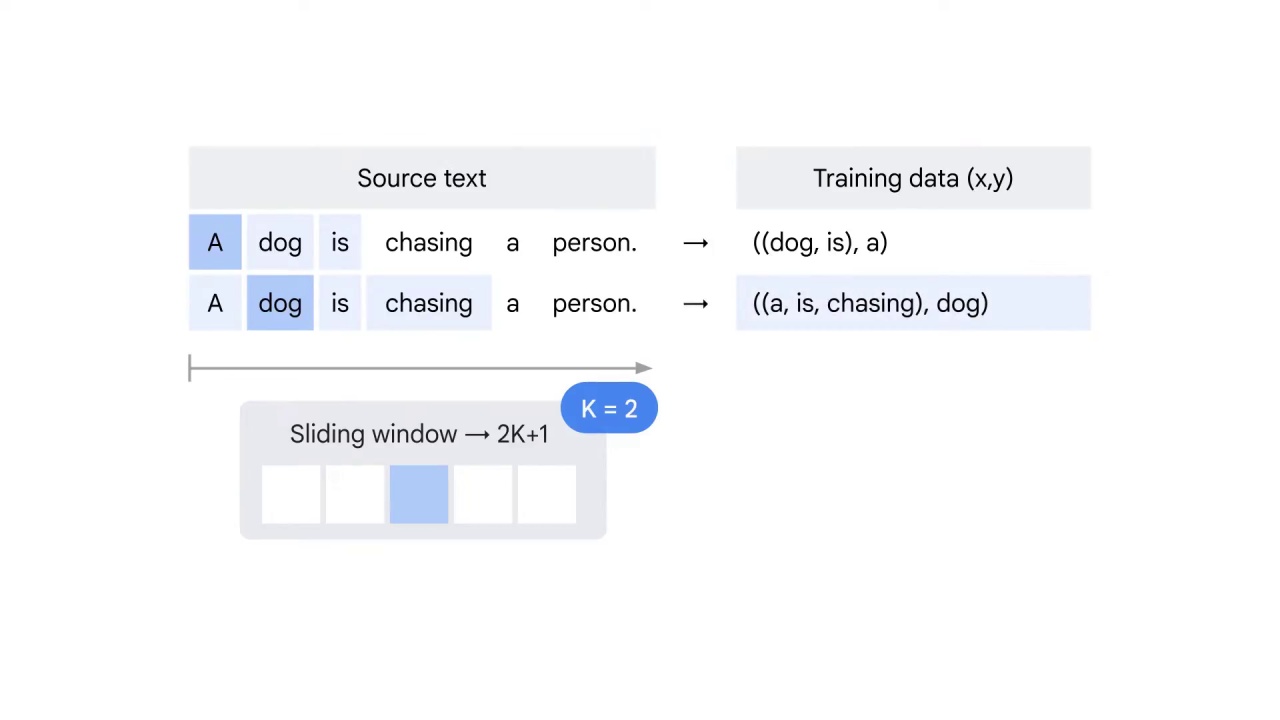
Therefore, three words: a, is, and chasing will be used to predict the label word “dog.”
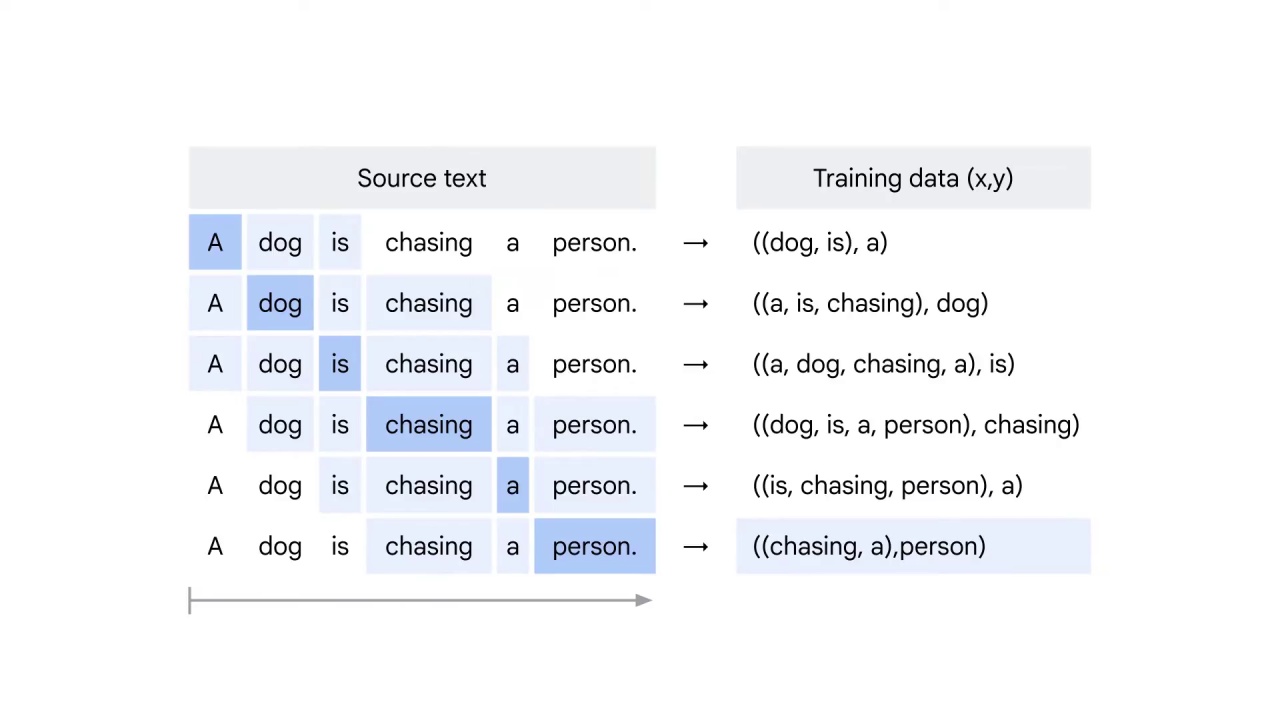
The same process continues till the last word person is the center word.
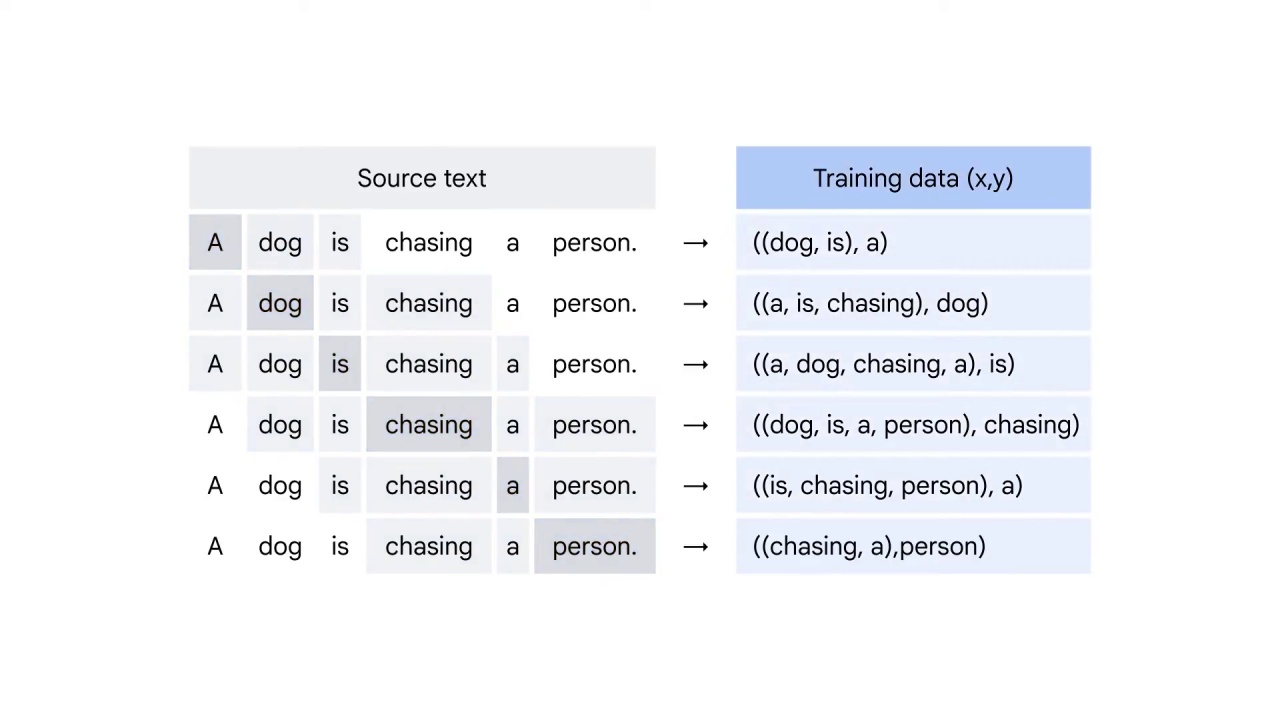
Now you get the training data ready.
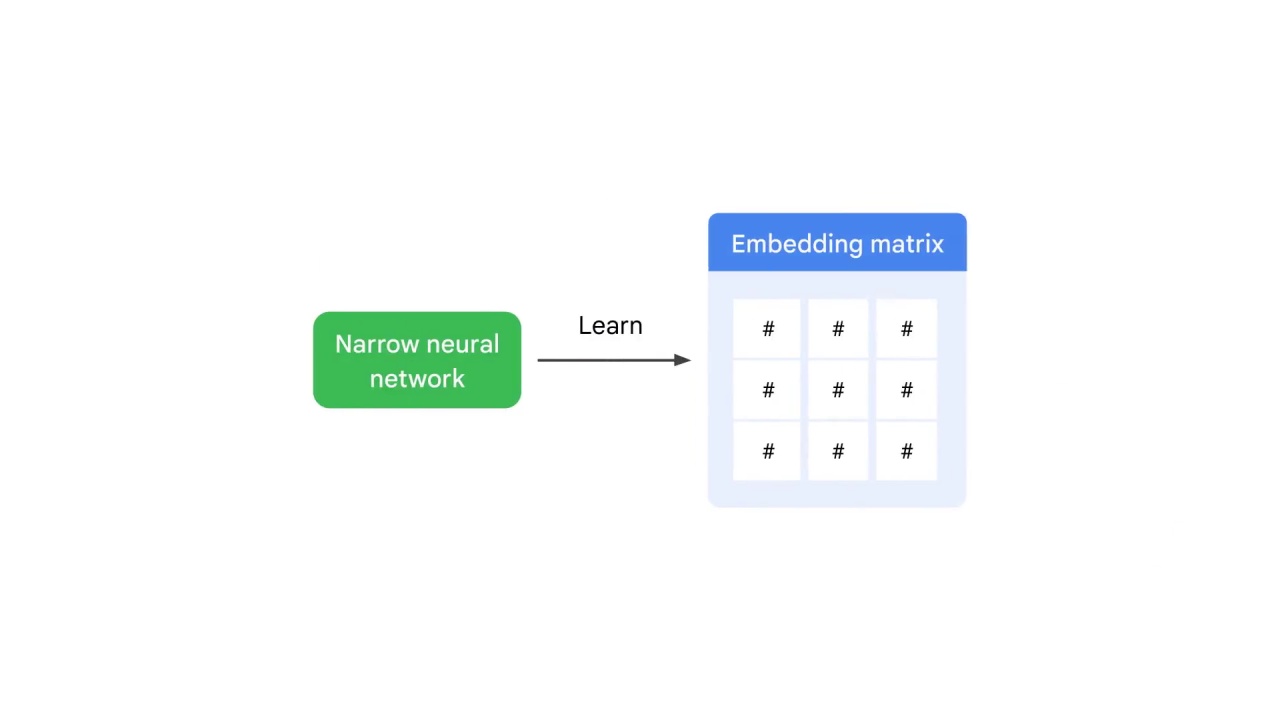
train the neural network
specifically a narrow neural network to learn the embedding matrix.
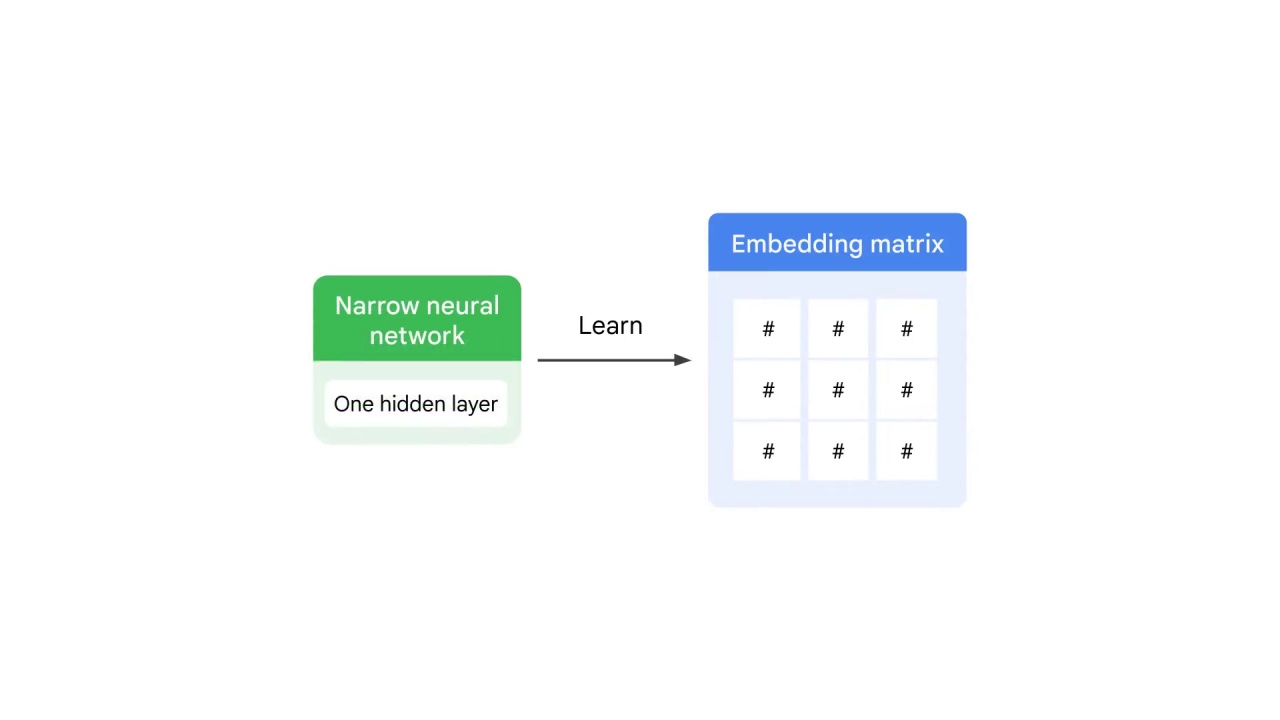
Narrow means there’s only one hidden layer in this model
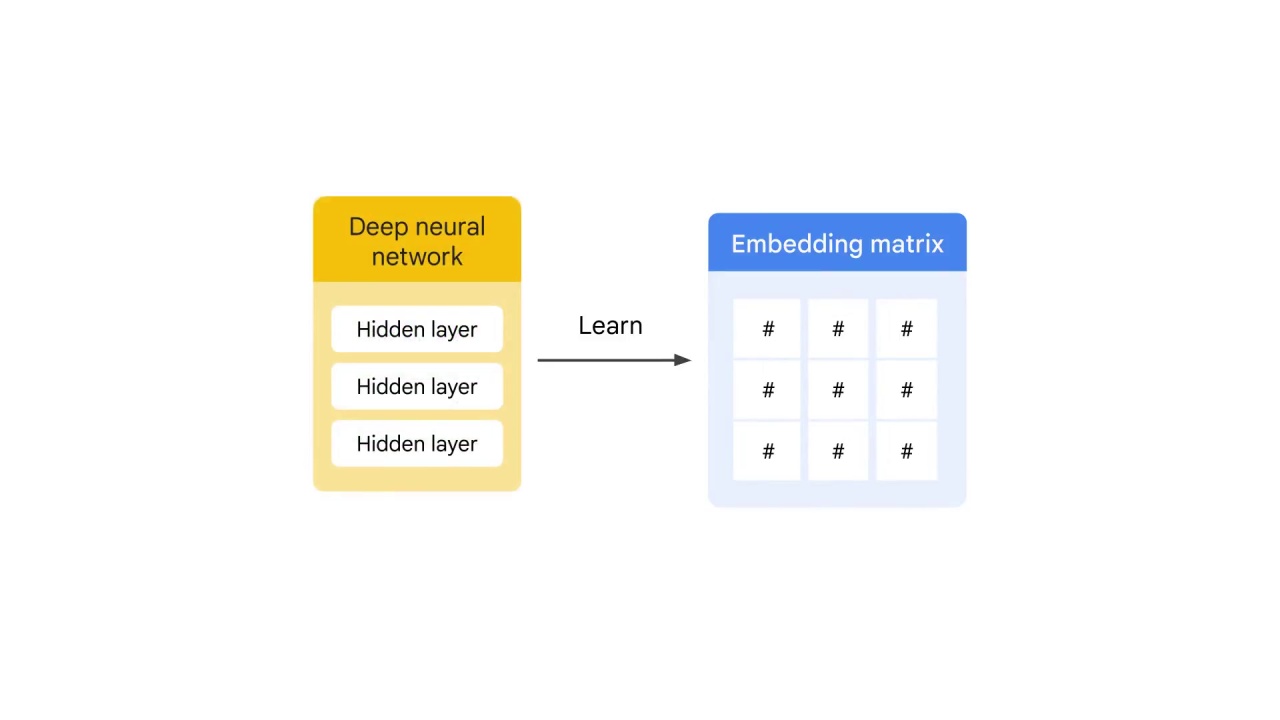
instead of multiple hidden layers, as in a deep neural network.

___ (for example, from TensorFlow) without needing to know the details.
In case you’re curious and want to train your own word2vec model instead of using a pre-trained one, here is what happens in the backend.
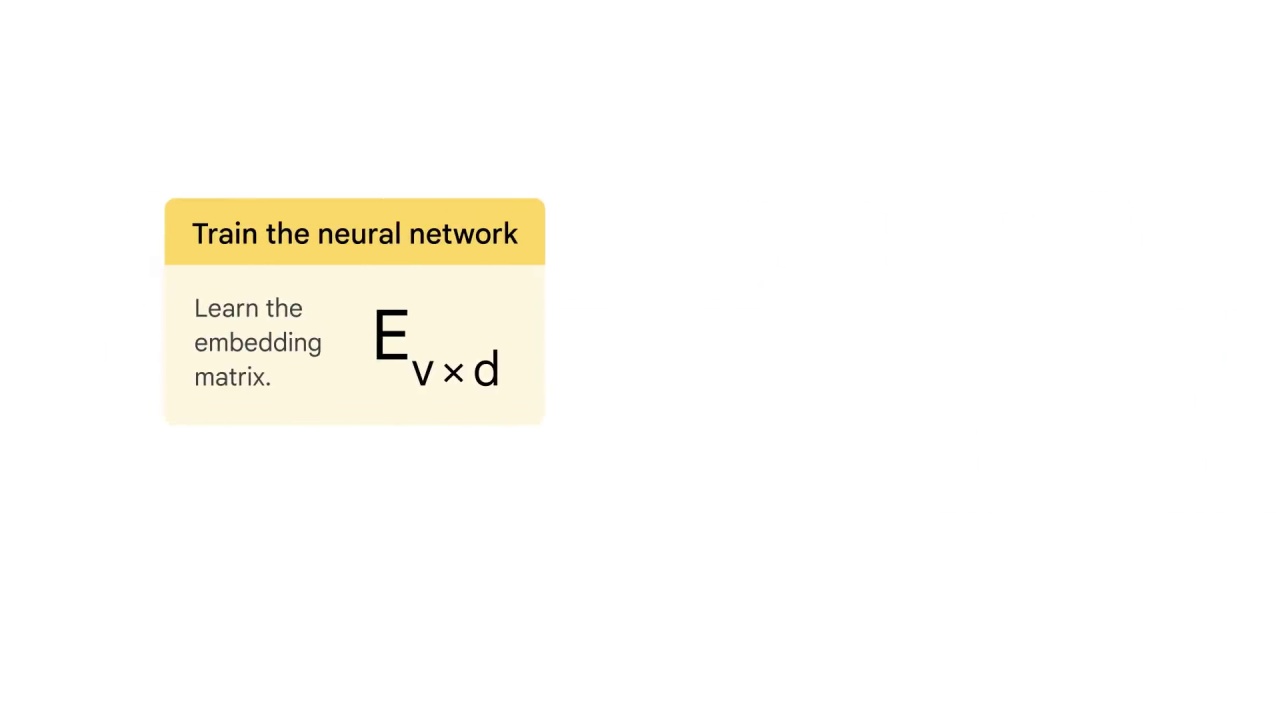
The goal is to learn the embedding matrix E_v*d,
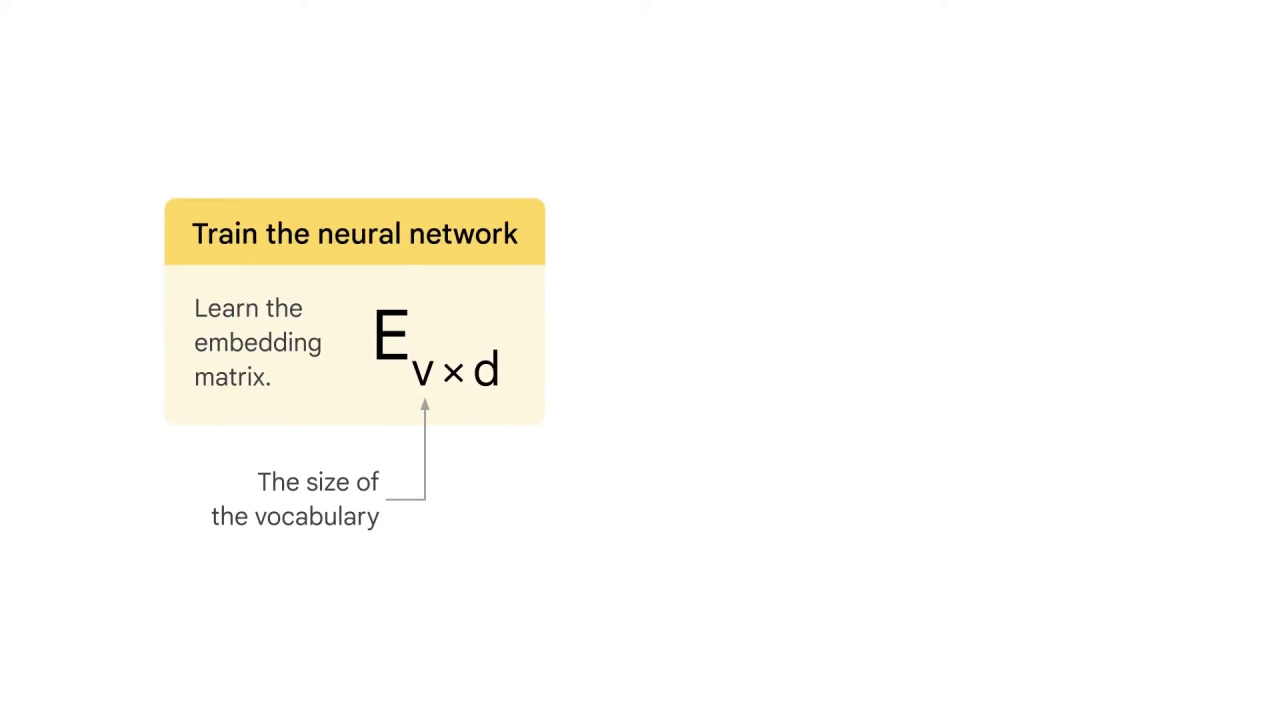
where v is the size of the vocabulary
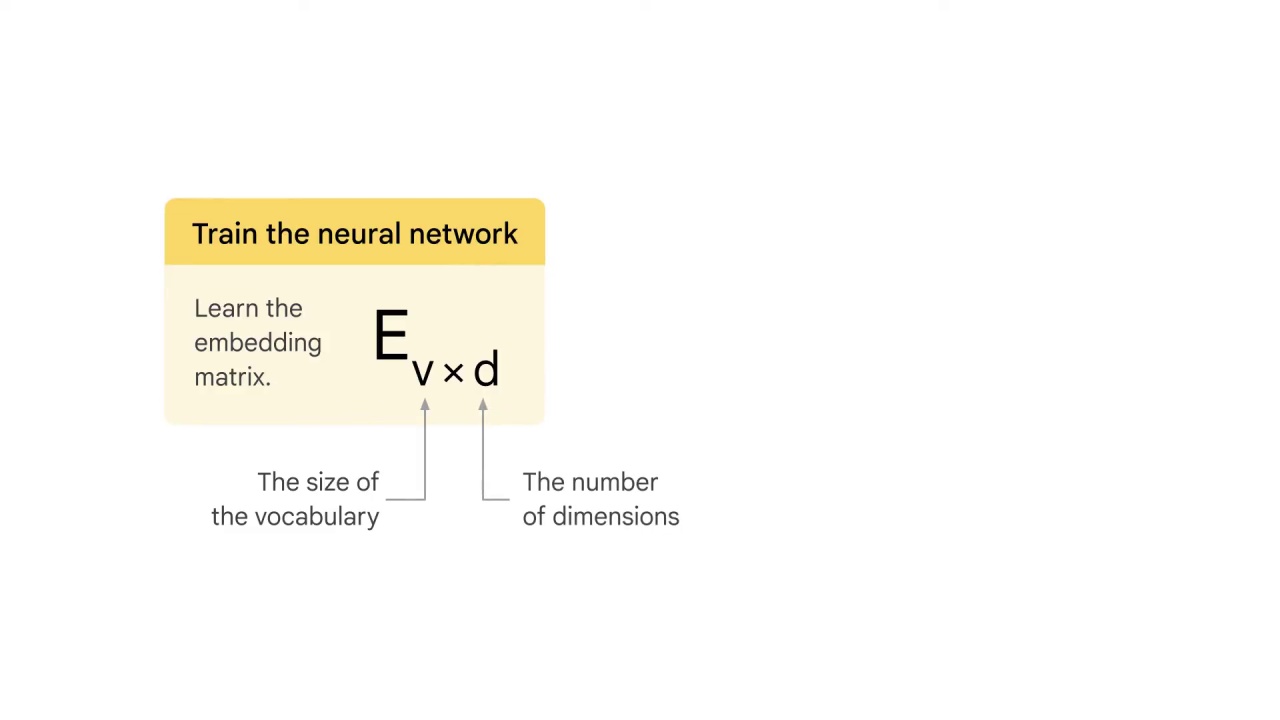
and d is the number of dimensions.
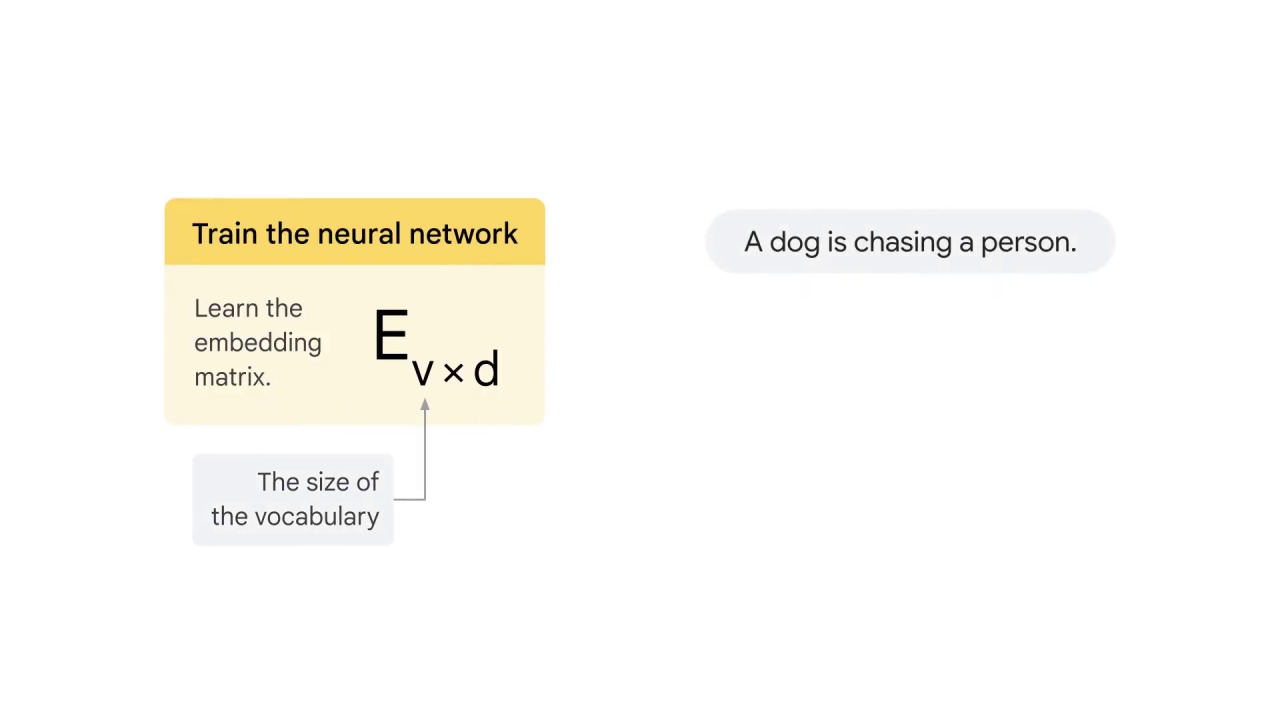
For example in the sentence “A dog is chasing a person,” you have five different words:
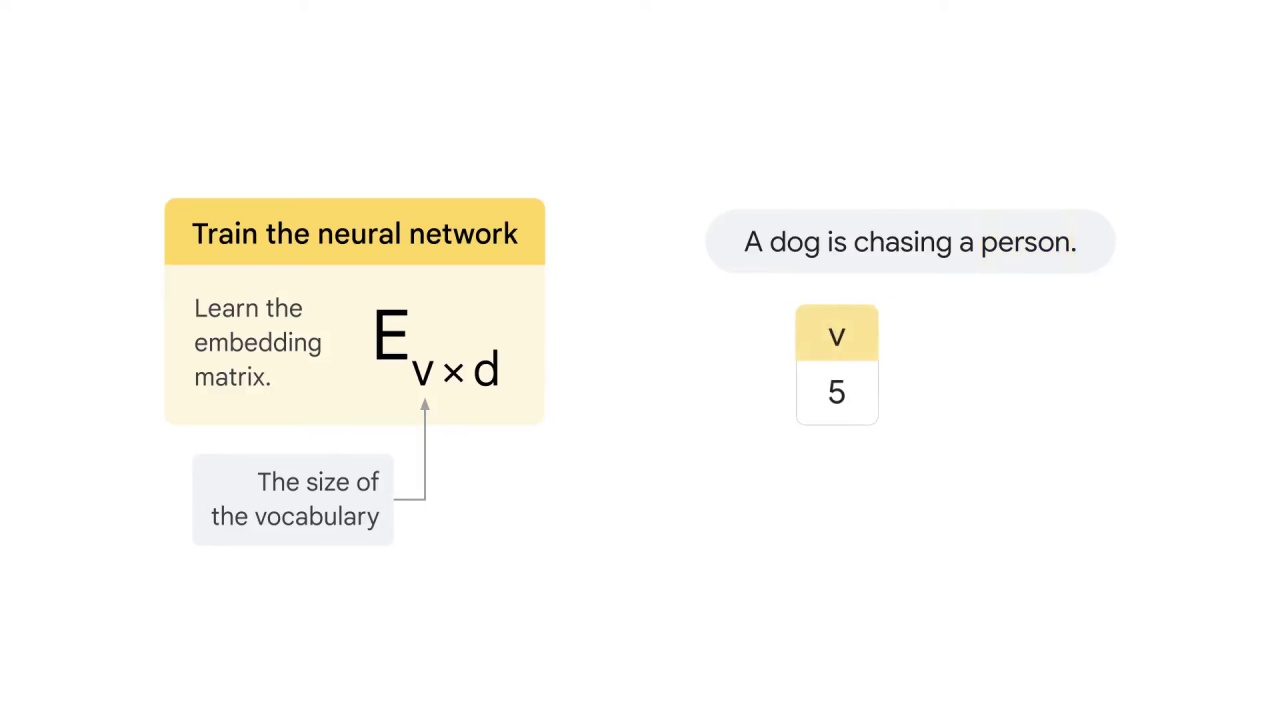
Therefore, v equals to 5.
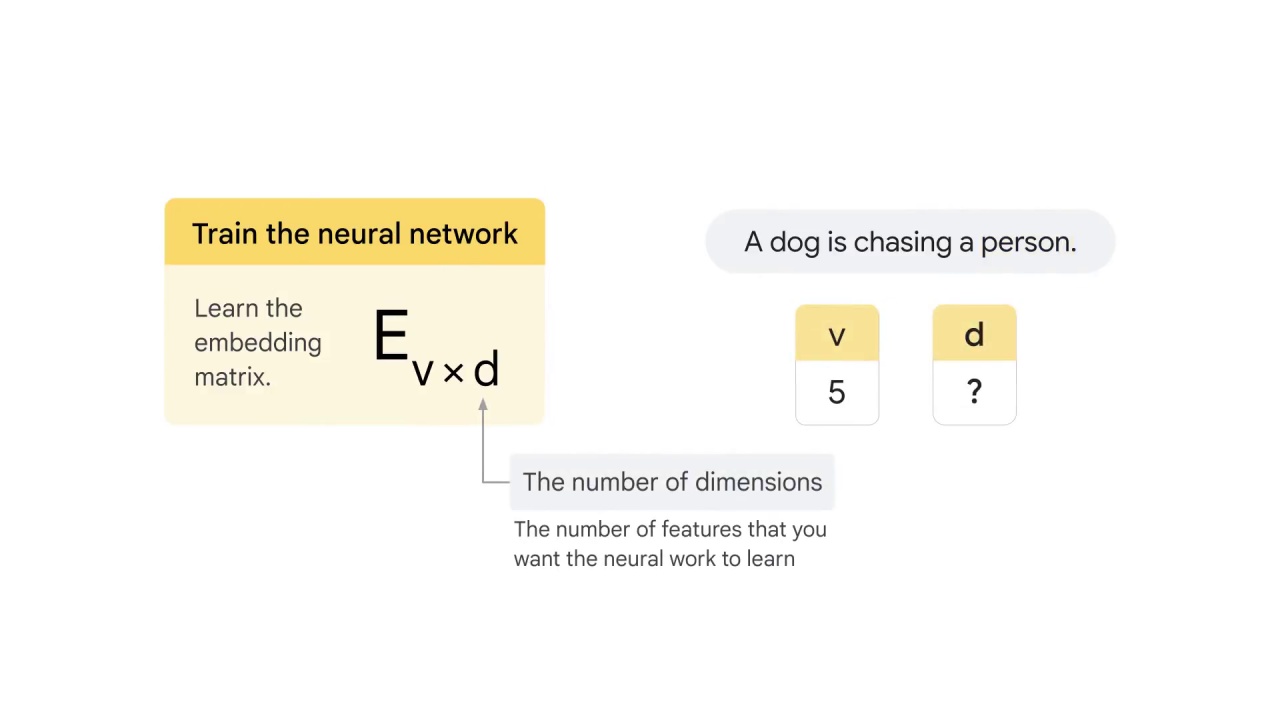
The value of d depends on the number of features that you want the neural work to learn to represent each word.
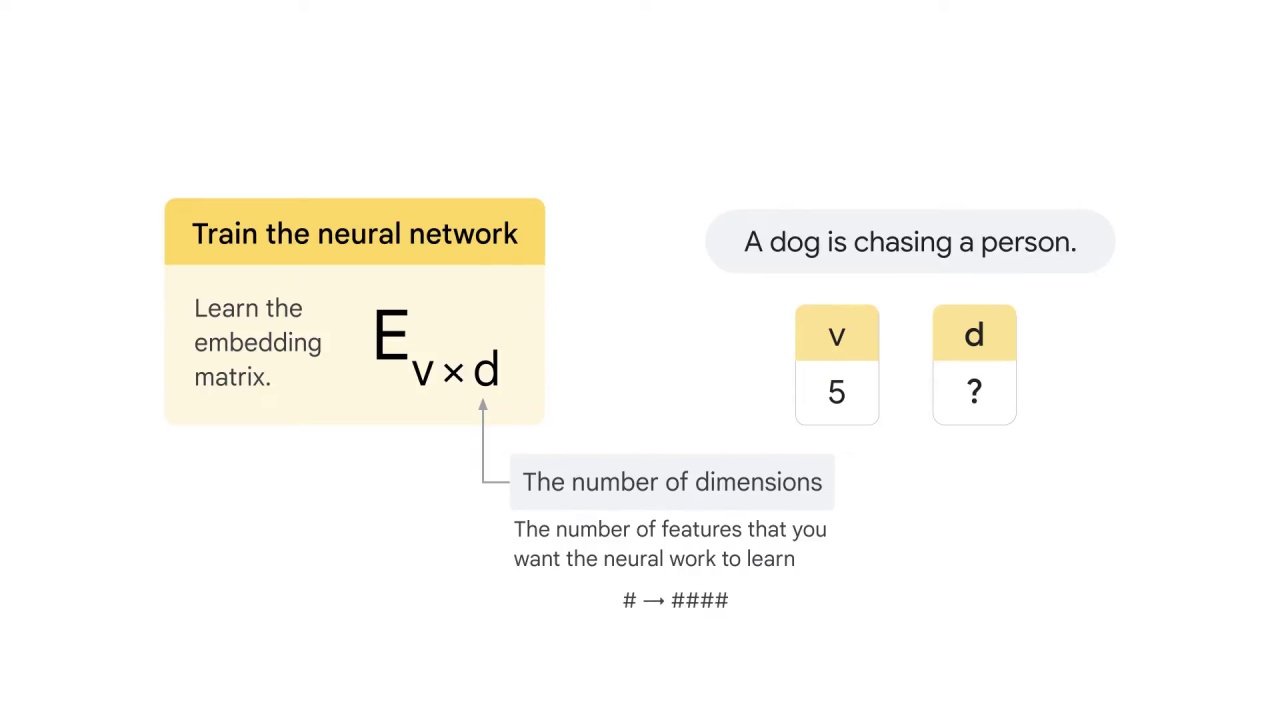
It can be anywhere between one to four digits.
Normally, when the number is larger, the model will be more refined; although it costs more computational resources.
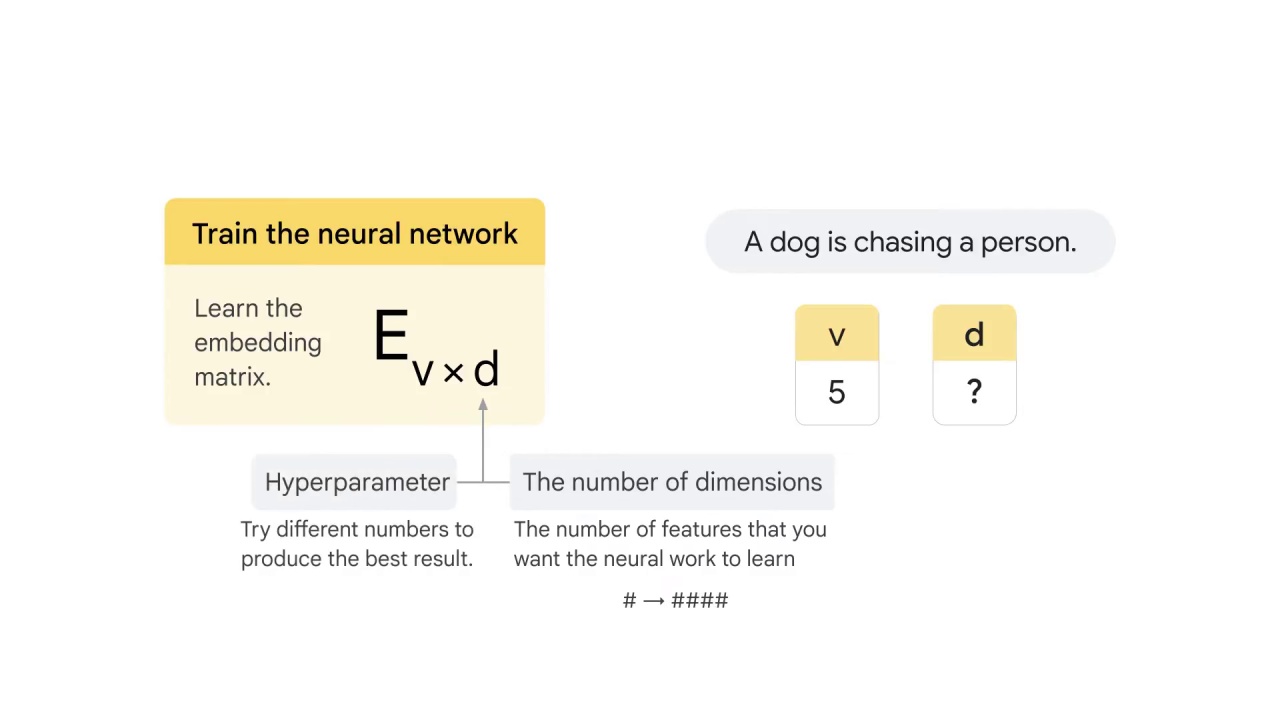
d is also a hyperparameter that you can tune when using Google’s pre-trained word2vec embedding, which means that you can try different numbers to see which one produces the best result.
To make the visual simple,
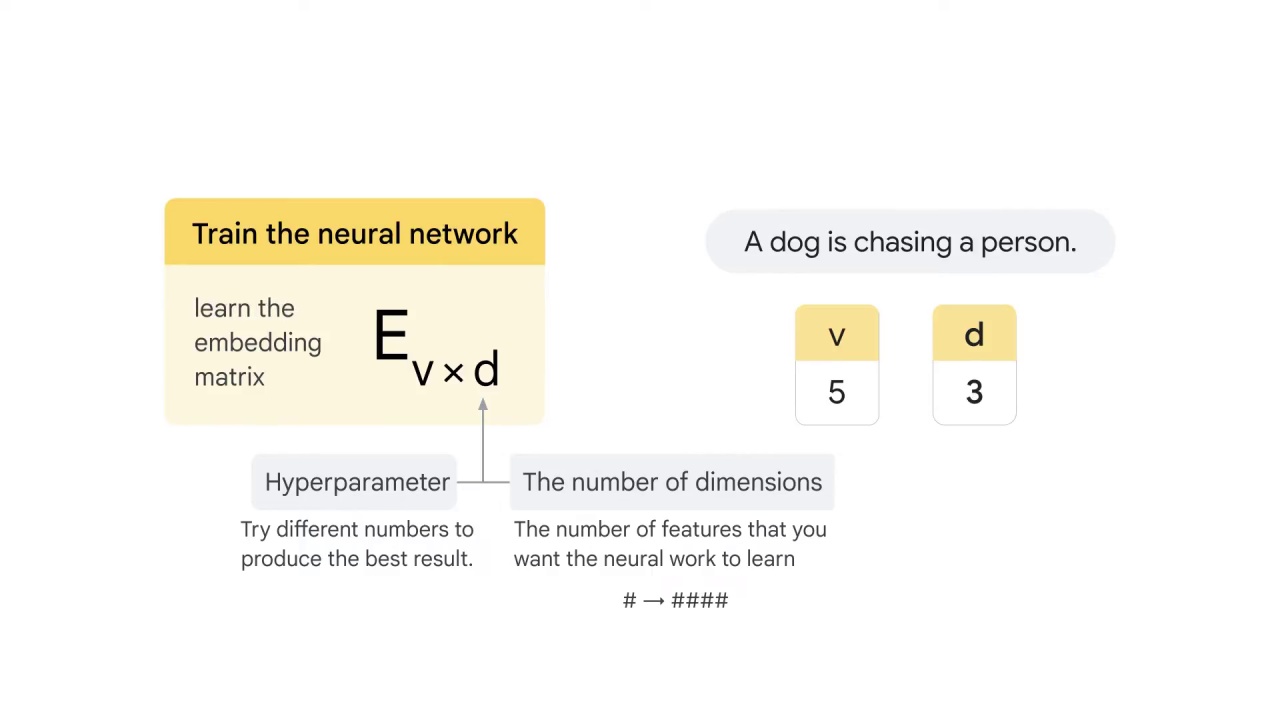
let’s say d equals to 3 here.
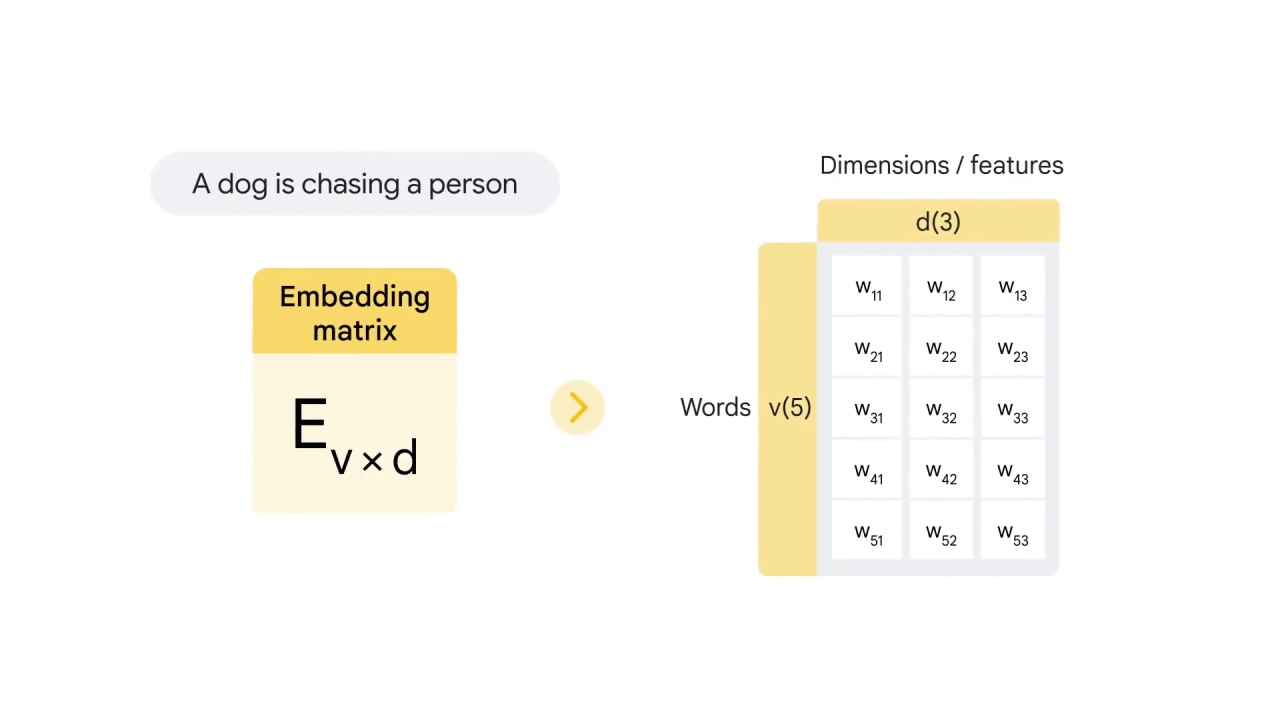
Therefore, the matrix in this example is 5 by 3 and it looks like this.
Each w represents a weight that you want to train the neural network to learn.
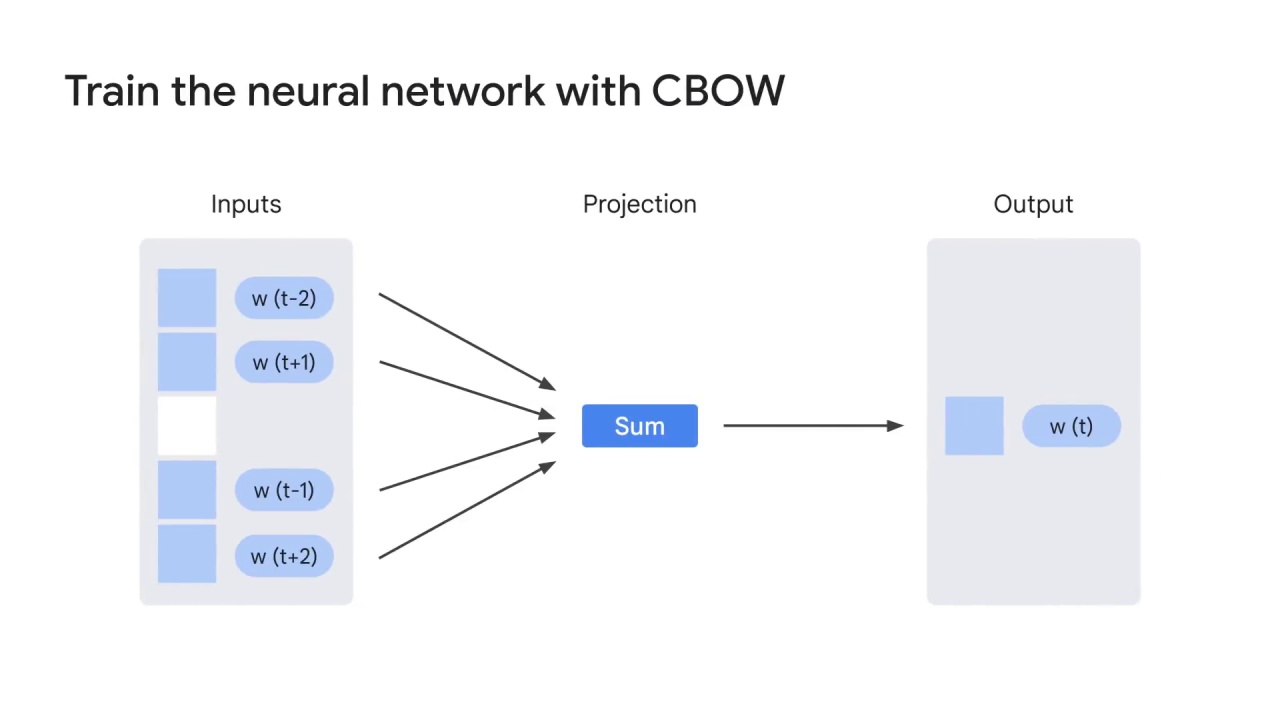
A simplified version to explain the process is to take the vectors of the surrounding 2000 words as input, sum them up, and output a vector to represent the center word.
This version is not very informative.
Let’s discuss this in more detail.
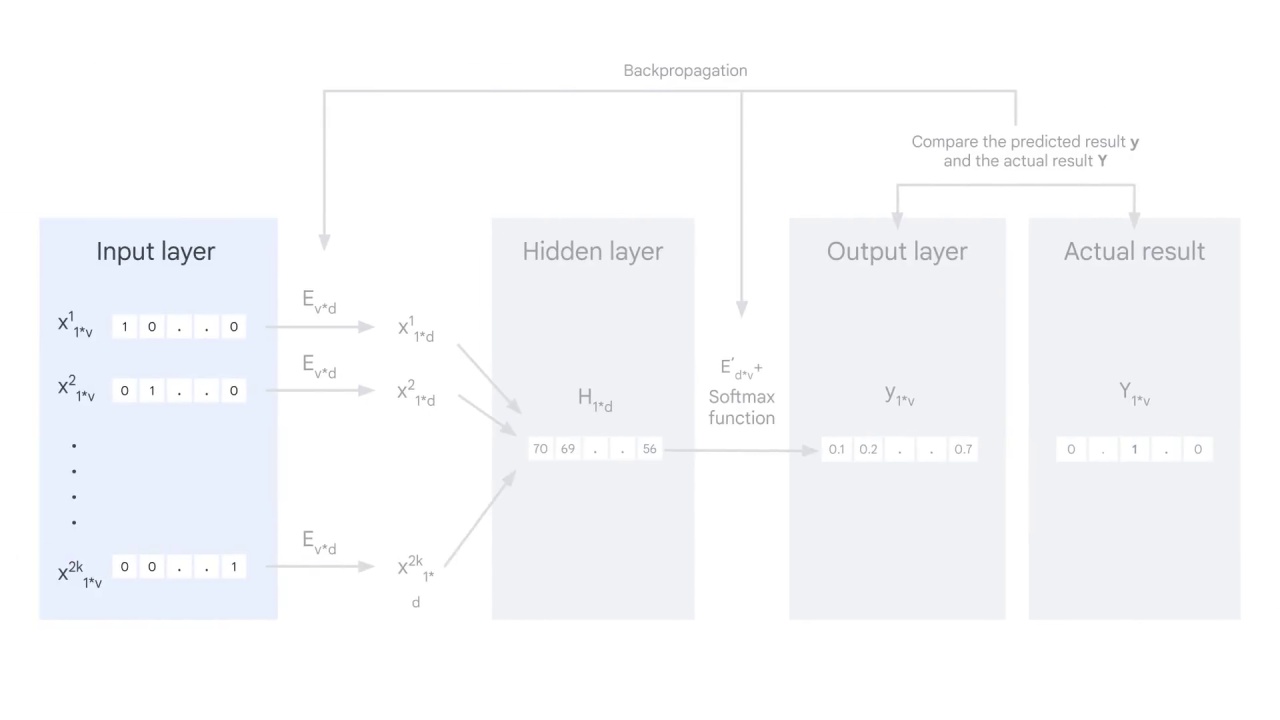
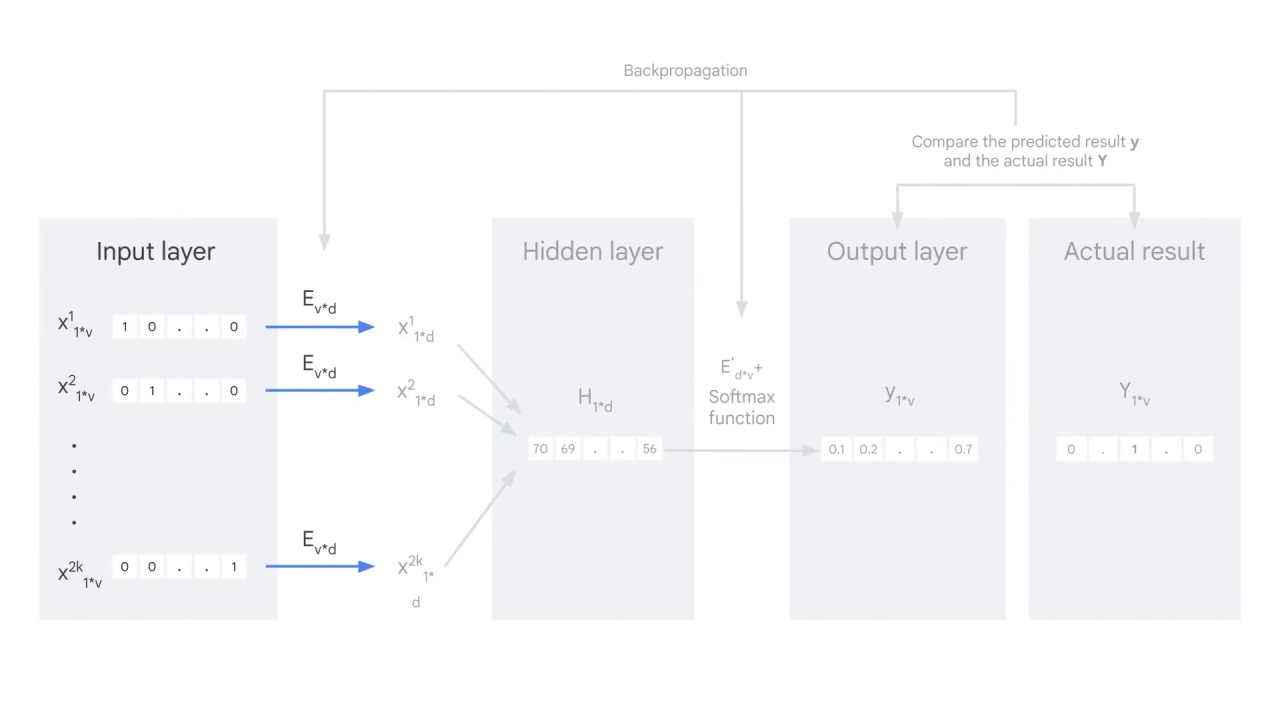
First is the input layer.
The Input layer consists of 2000 words, each is represented by a one-hot encoder vector.
If you recall from the previous lesson, a one-hot encoder is a one by v vector and v is the size of the vocabulary.
You’ll place a 1 in the position corresponding to the word and zeros in the rest positions.
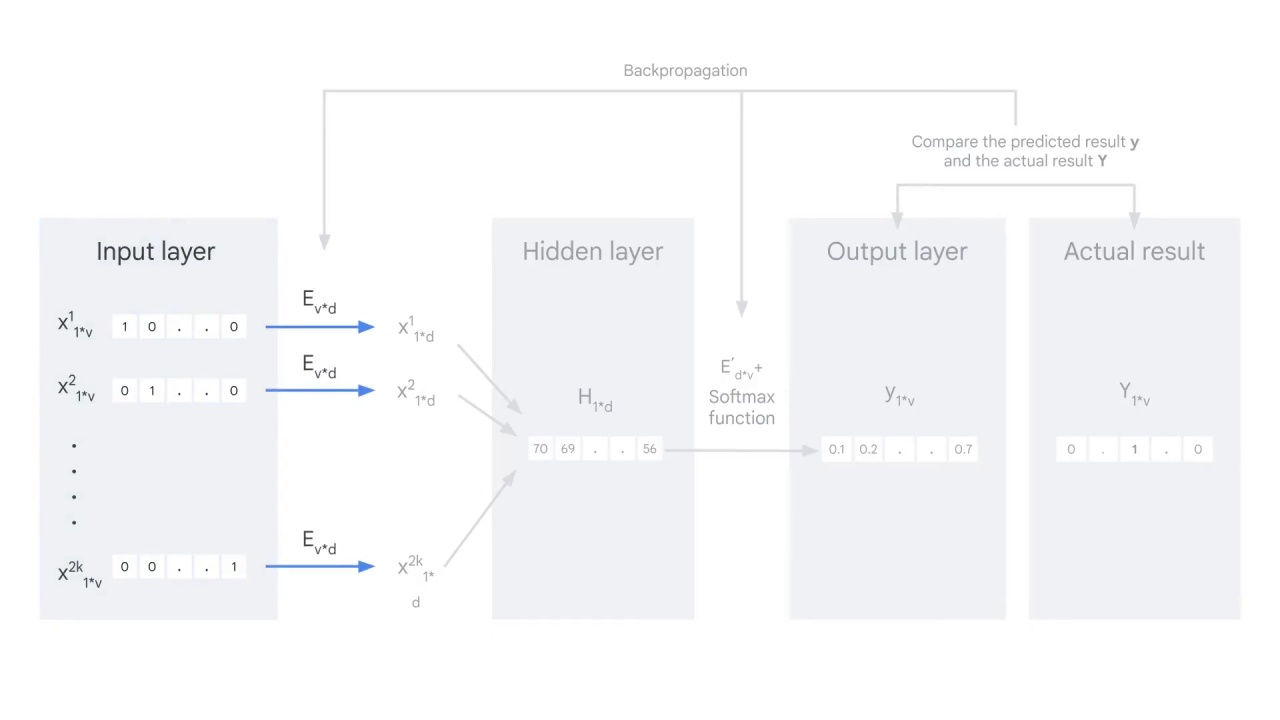
Then you embed these vectors with the embedding matrix Ev*d, which means you multiply each vector by the embedding matrix E.
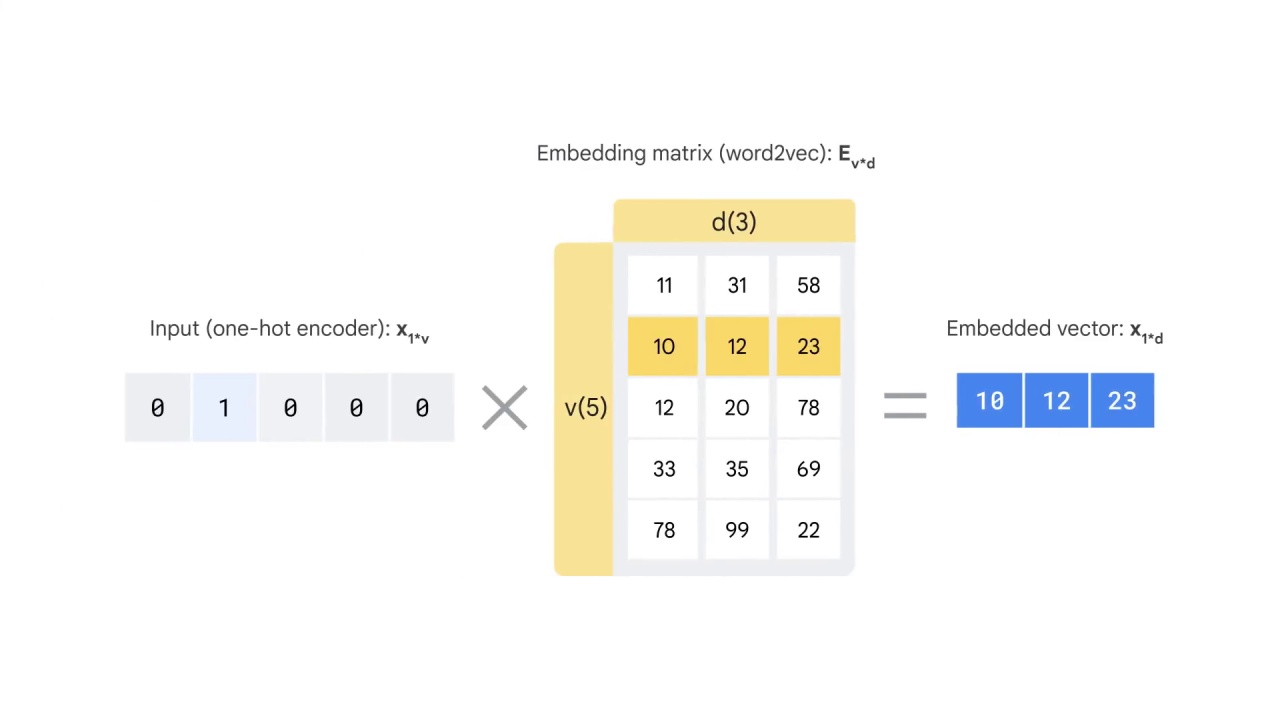
To illustrate this, let’s assume you have an input vector of a one-hot encoder as [0,1,0,0,0].
You multiply it with the embedding matrix, which in the case is the word2vec, by using the CBOW technique. And then you get the embedded 1*d vector as [10,12,23].
You can imagine the embedding matrix as a lookup table to turn the original word into a vector that has semantic meaning.
To begin this process, all the values (weights) in the embedding matrix E are randomly assigned.
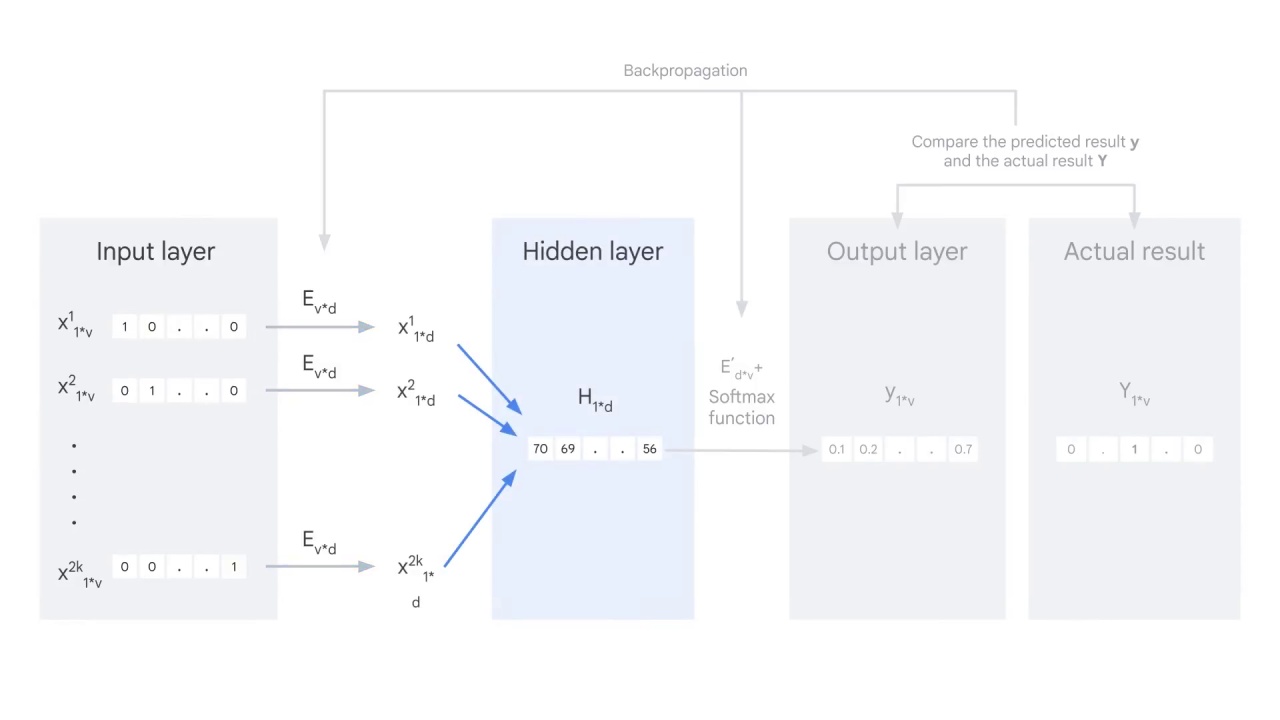
Once you get the embedded vector for each context word, sum all the vectors and get a hidden layer H, a one by d vector.
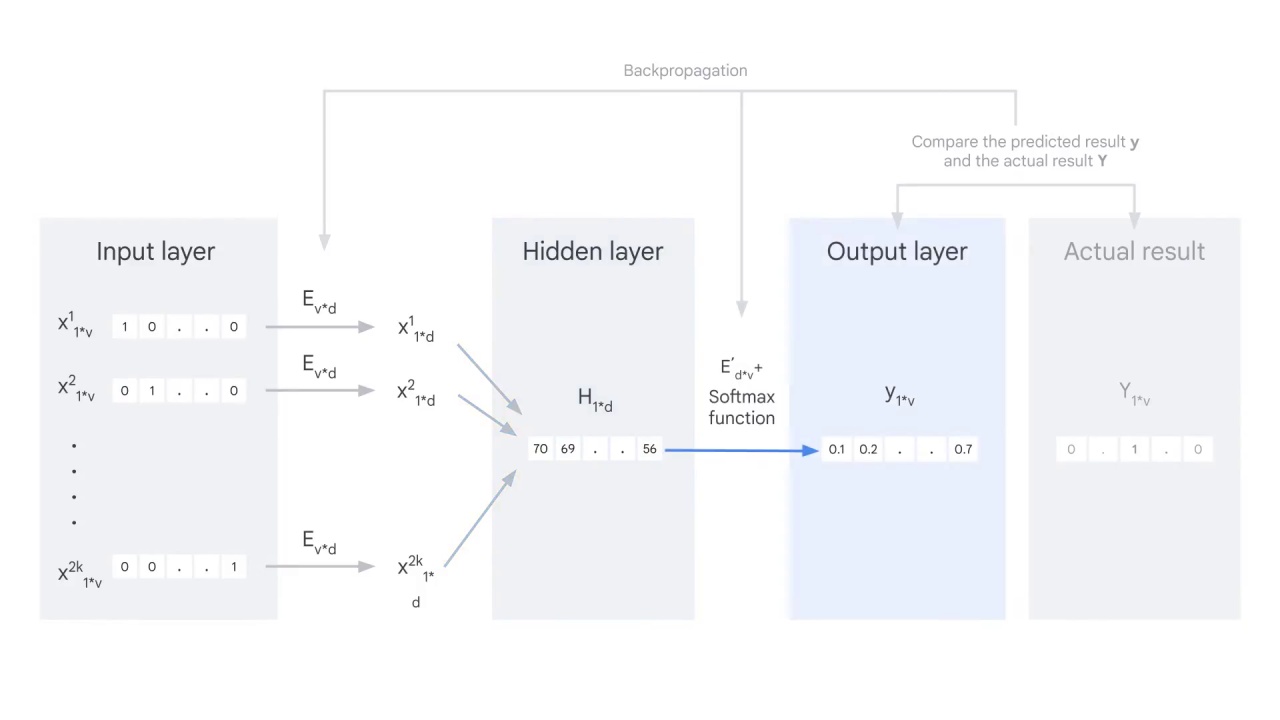
You multiply H with another matrix E’ and feed the result to a softmax function to get the probability y.
y is a one-by-v vector and each value shows the probability of the word in that position being the center word.
This is the output layer and the predicted result.
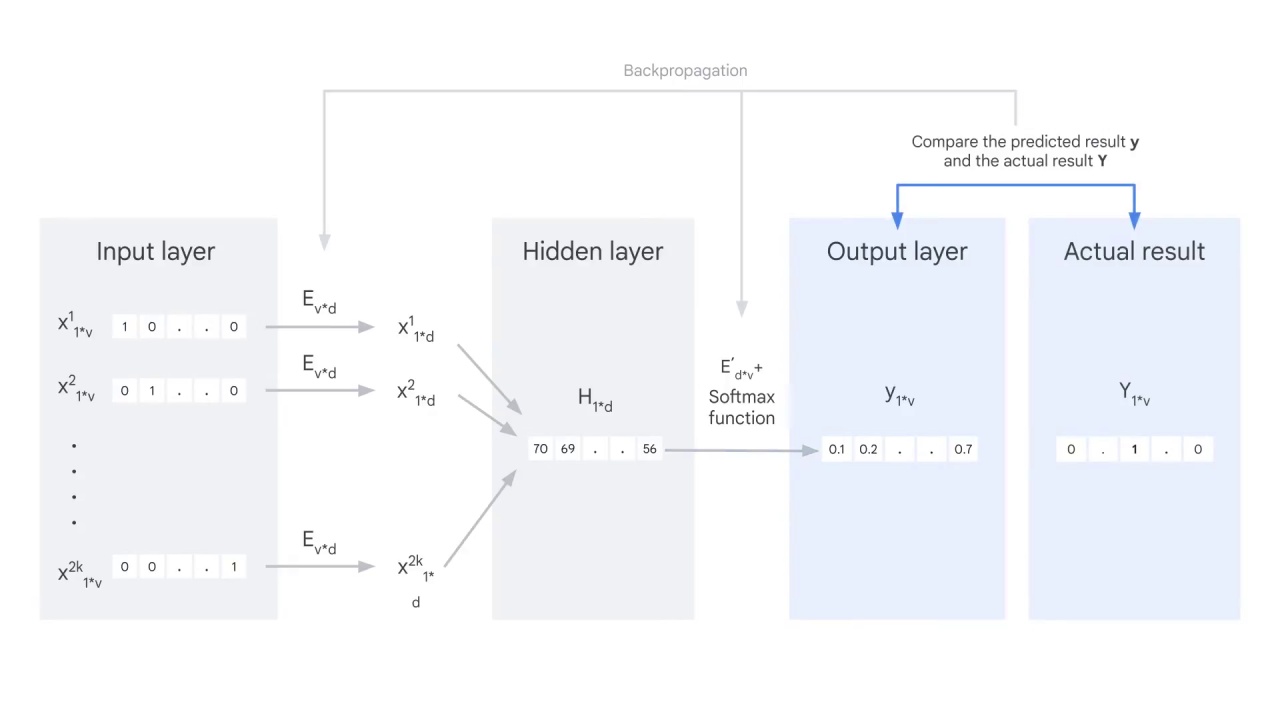
However, this is actually the beginning of the iteration.
You must compare the output vector with the actual result,
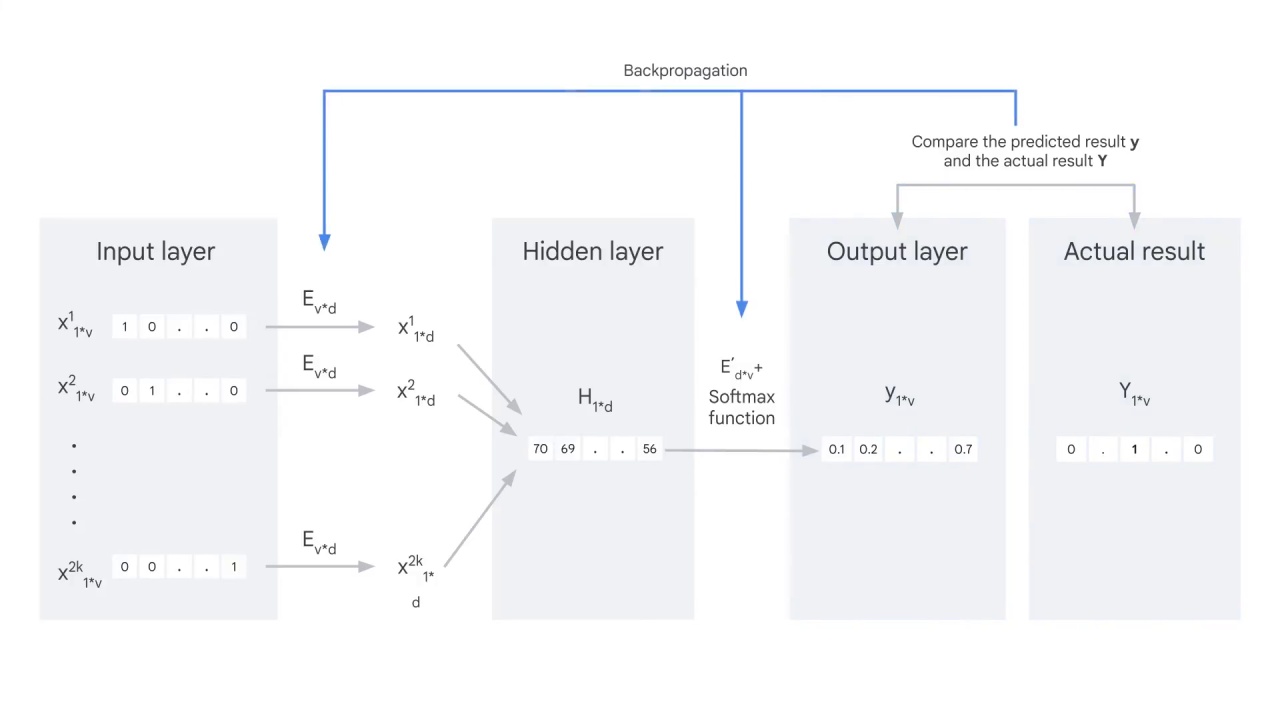
And use backpropagation to adjust the weights in the embedding matrices E and E’.
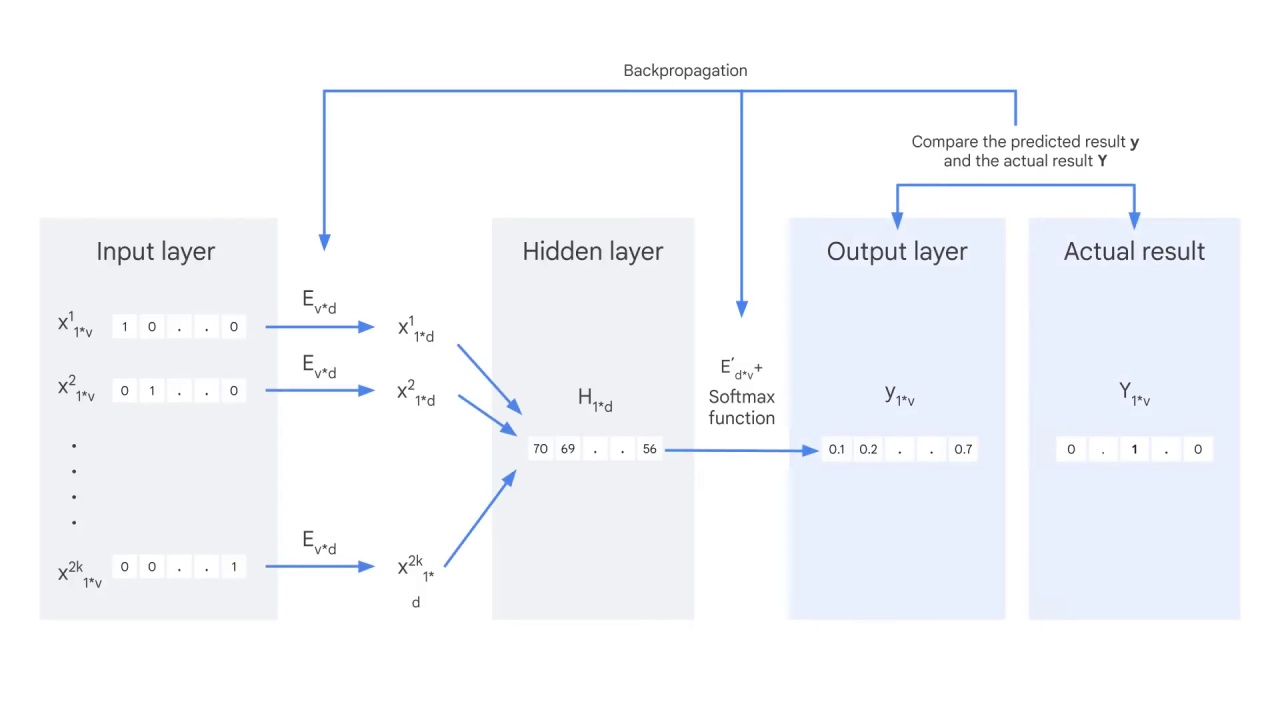
Iterate this process until the difference between the predicted result and the actual result is minimum.
Now you get the E, the word2vec embedding matrix that you aimed to learn at the beginning.
The training process depicts how a neural network learns.
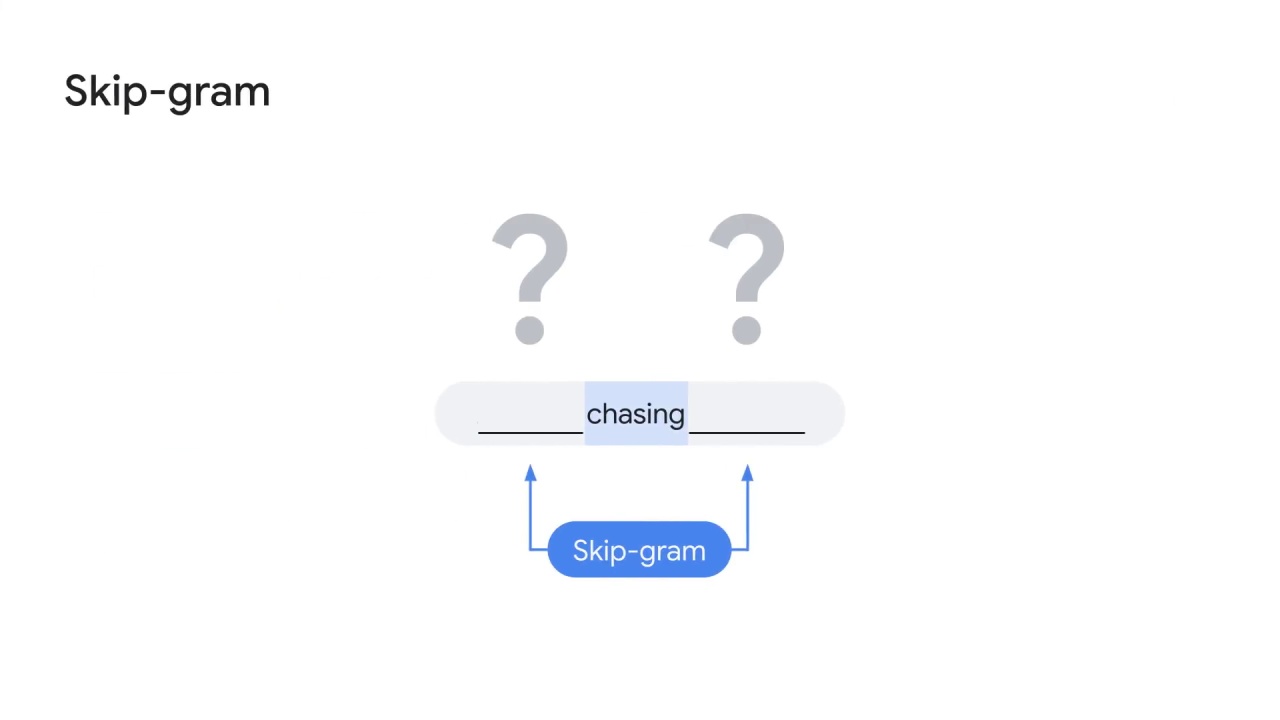
Opposite to continuous bag-of-words (CBOW), skip-gram uses the center word to predict context words.
For example, given chasing, what are the probabilities of other words such as a, dog, and person occur in the surrounding context?
The process is similar to CBOW, though.
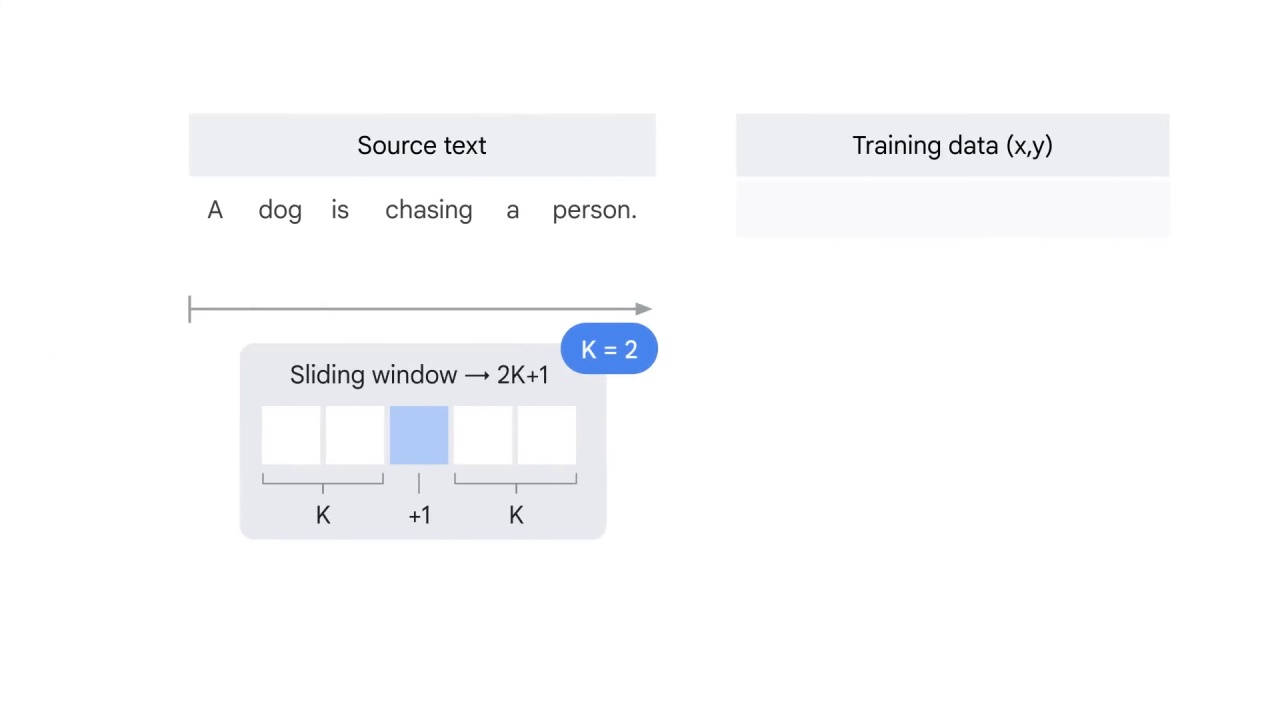
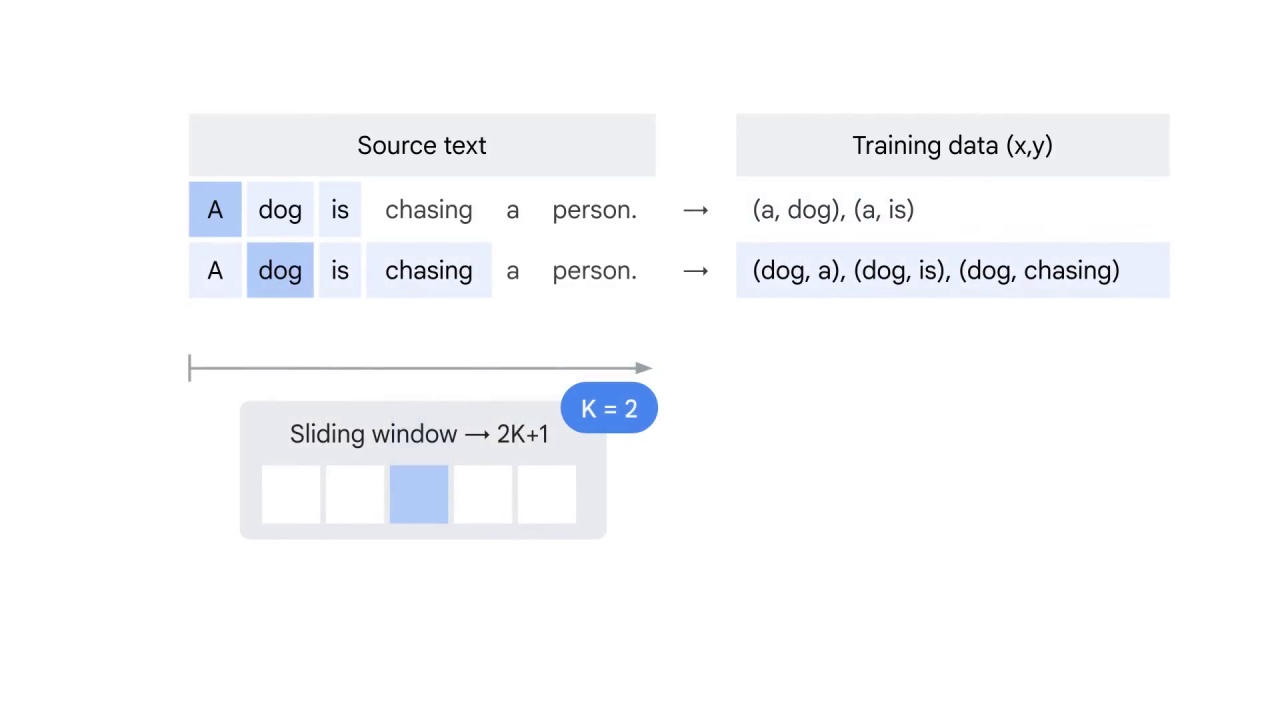
First, you prepare the training data by running a sliding window of size 2K+1.
For example, let k equals to 2.
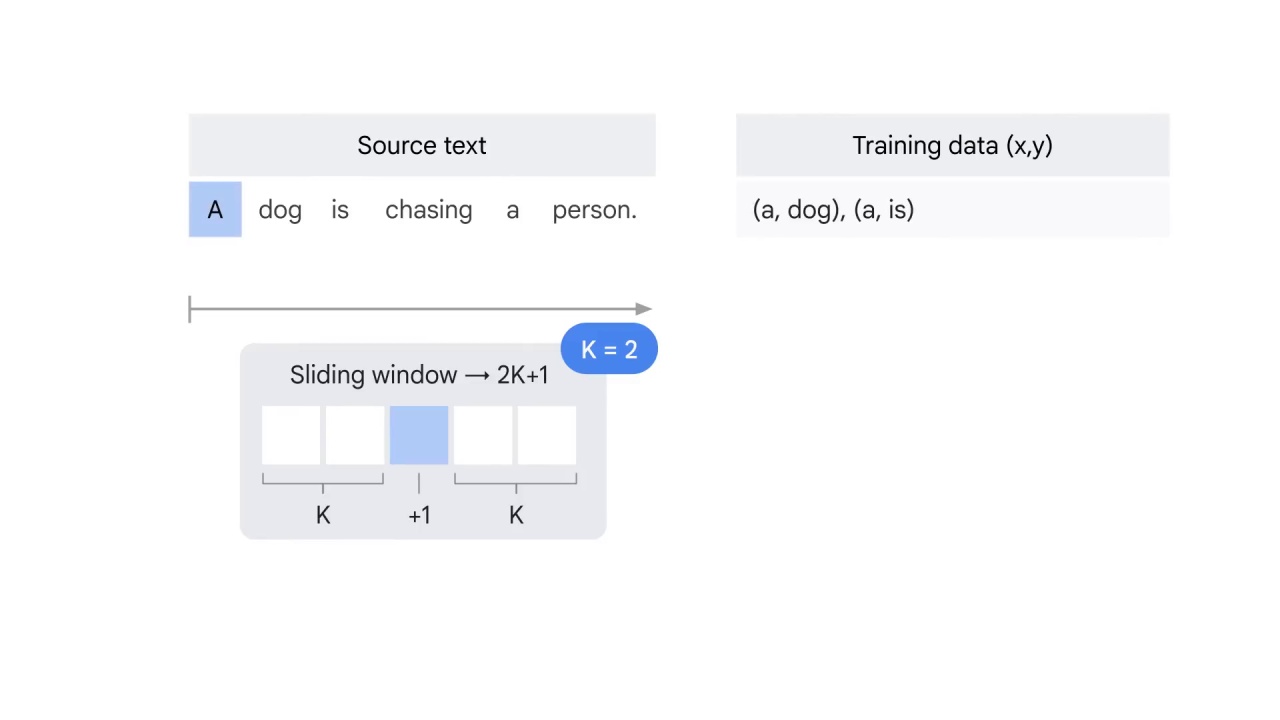
You start with the first word A.
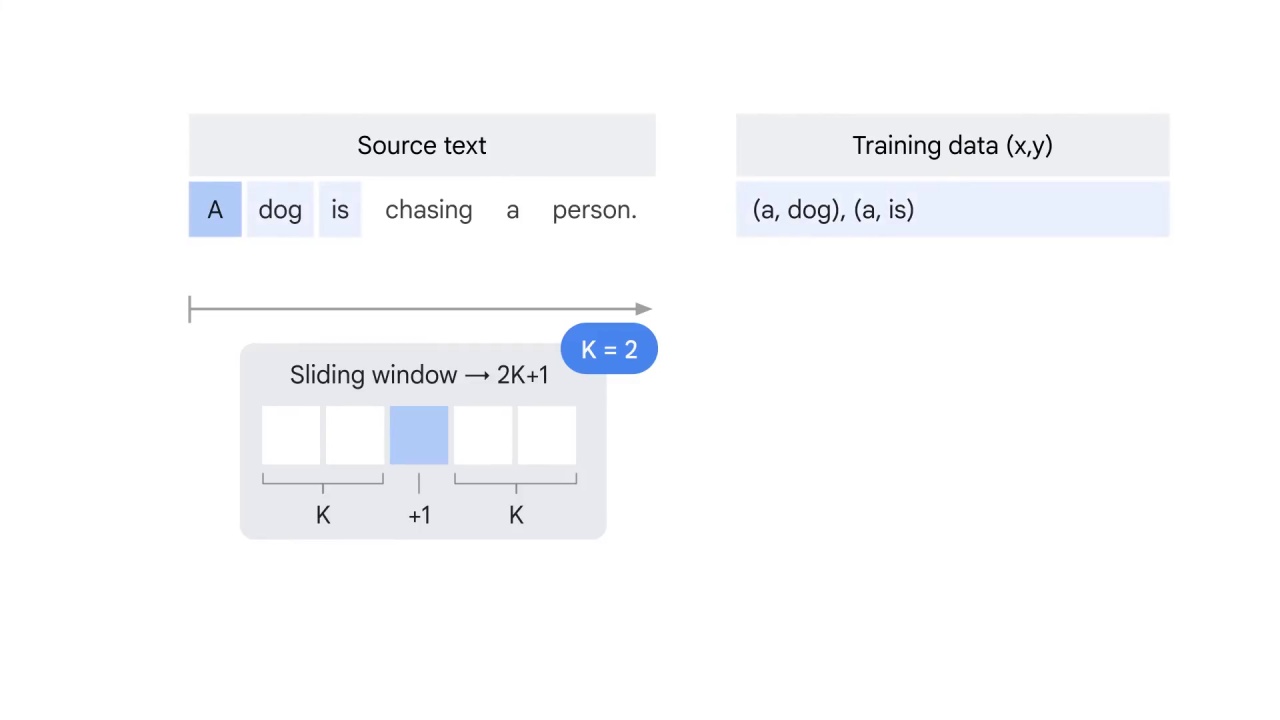
You have no word before A but two words after it.
Therefore, you use A to predict dog and is respectively.
And then the window shifts to the second word dog as the center word.
You use dog to predict the word a before it and the words is and chasing after it.
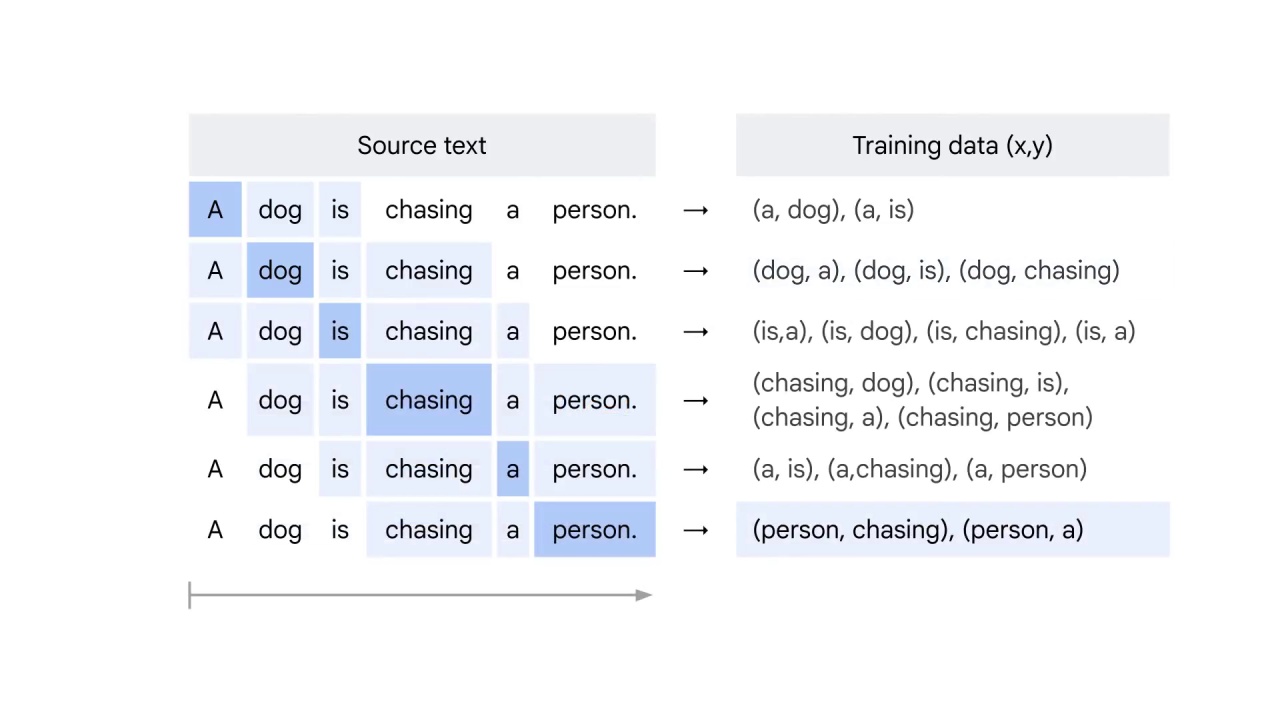
The same process continues till the last word person is the center word.
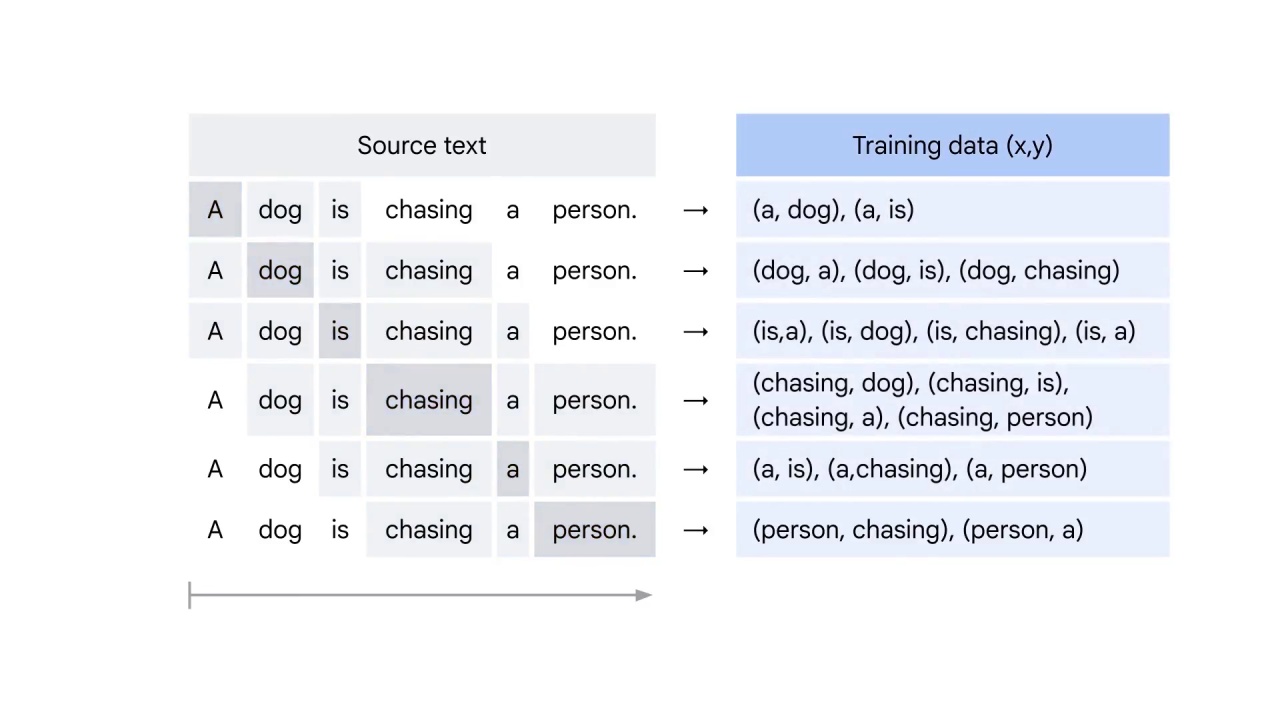
Now your training data is ready.
Next, you train the neural network to learn the embedding matrix E.
Compared to CBOW, E here is based on the skip-gram technique.
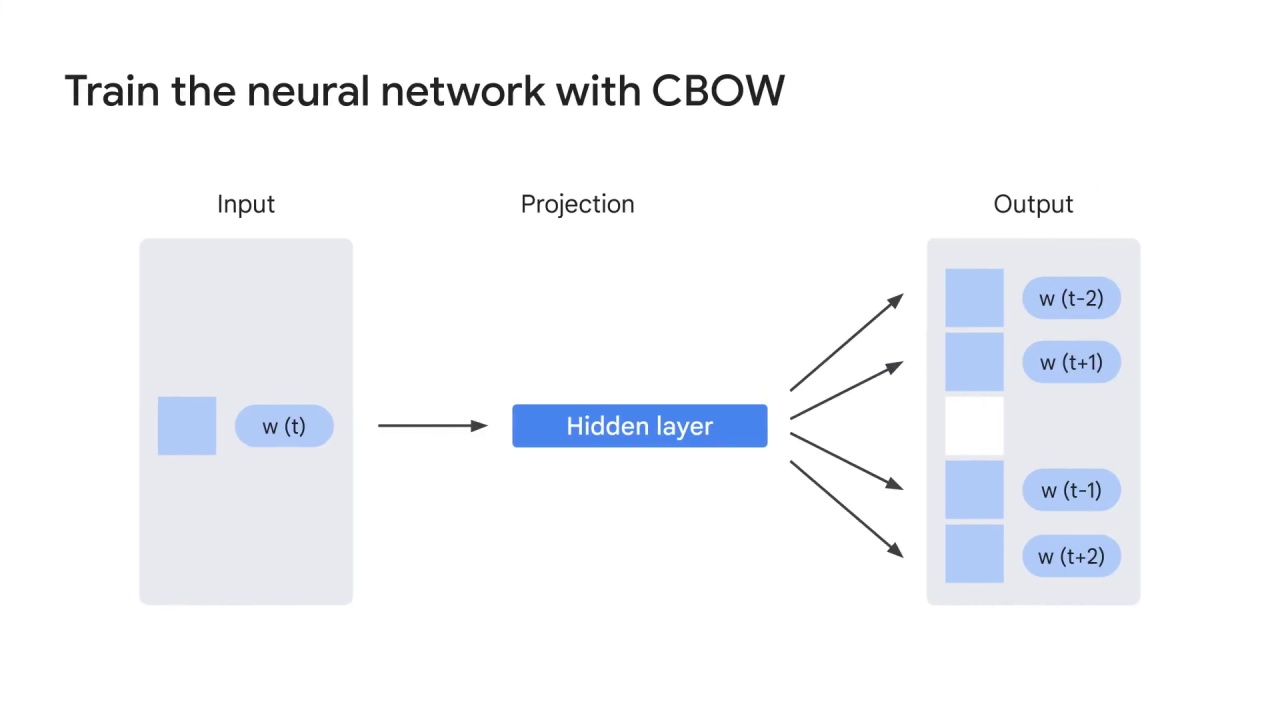
You start with the input layer which consists of the one-hot encoder vector of the center word.
Embed this vector with embedding matrix E, and feed the embedded vectors to one hidden layer.
After another E’ and the softmax function, you finally generate the output layer which consists of vectors to predict 2000 surrounding context words.

Now that you understand how wrod2vec works, let’s look at the coding.
Fortunately, you don’t have to train wrod2vec yourself.
Keras in TensorFlow packages all the details and you only need to call the pre-trained models and tune the hyperparameters.