Training on large datasets with tf.data API

It’s time to look at some specifics.
The tf.data API introduces a tf.data.Dataset abstraction that represents a sequence of elements, in which each element consists of one or more components.
For example, in an image pipeline, an element might be a single training example, with a pair of tensor components representing the image and its label.
There are two distinct ways to create a dataset:
A data source constructs a Dataset from data stored in memory or in one or more files.
A data transformation constructs a dataset from one or more
tf.data.Datasetobjects.

Large datasets tend to be sharded or broken apart into multiple files which can be loaded progressively.
Remember that you train on mini-batches of data.
You do not need to have the entire dataset in memory.
One mini-batch is all you need for one training step.

The Dataset API will help you create input functions for your model that will load data progressively.
There are specialized Dataset classes that can read data from text files like CSVs, Tensorflow records or fixed length record files.
Datasets can be created from different file formats:
Use
TextLineDatasetto instantiate a Dataset object which is comprised of lines from one or more text files.TFRecordDatasetcomprises records from one or moreTFRecordfiles.And
FixedLengthRecordDatasetis a dataset object from fixed-length records from one or more binary files. For anything else, you can use the generic Dataset class and add your own decoding code.

Let’s walk through an example of TFRecordDataset.
At the beginning, the TFRecord op is created and executed, producing a variant tensor representing a dataset which is stored in the corresponding Python object.

Next, the Shuffle op is executed, using the output of the TFRecord op as its input, connecting the two stages of the input pipeline.

Next, the user-defined function is traced and passed as attribute to the Map operation, along with the Shuffle dataset variant input.

Finally, the Batch op is created and executed, creating the final stage of the input pipeline.
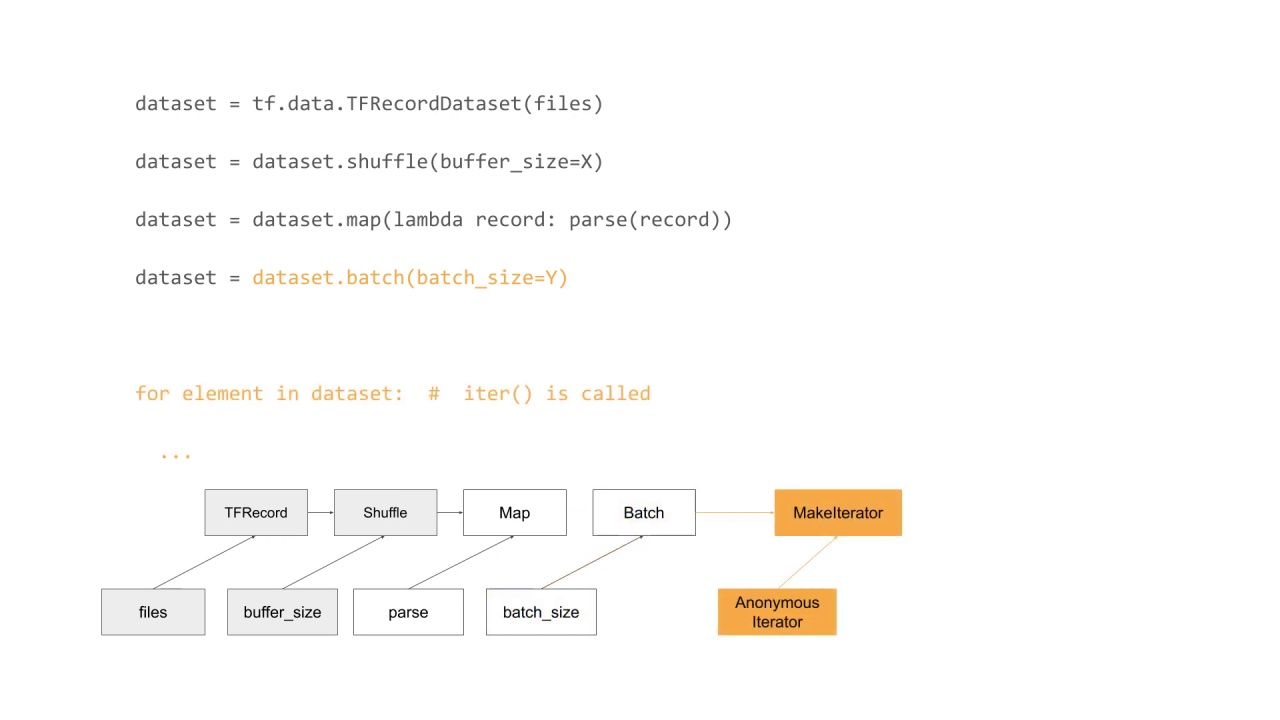
When the for loop mechanism is used for enumerating the elements of dataset, the iter method is invoked on the dataset, which triggers creation and execution of two ops.
First an anonymous iterator op is created and executed, which results in creation of an iterator resource.
Subsequently, this resource along with the Batch dataset variant is passed into the MakeIterator op, initializing the state of the iterator resource with the dataset.

When the next method is called, it triggers creation and execution of the IteratorGetNext op, passing in the iterator resource as the input.
Note that the iterator op is created only once but executed as many times as there are elements in the input pipeline.
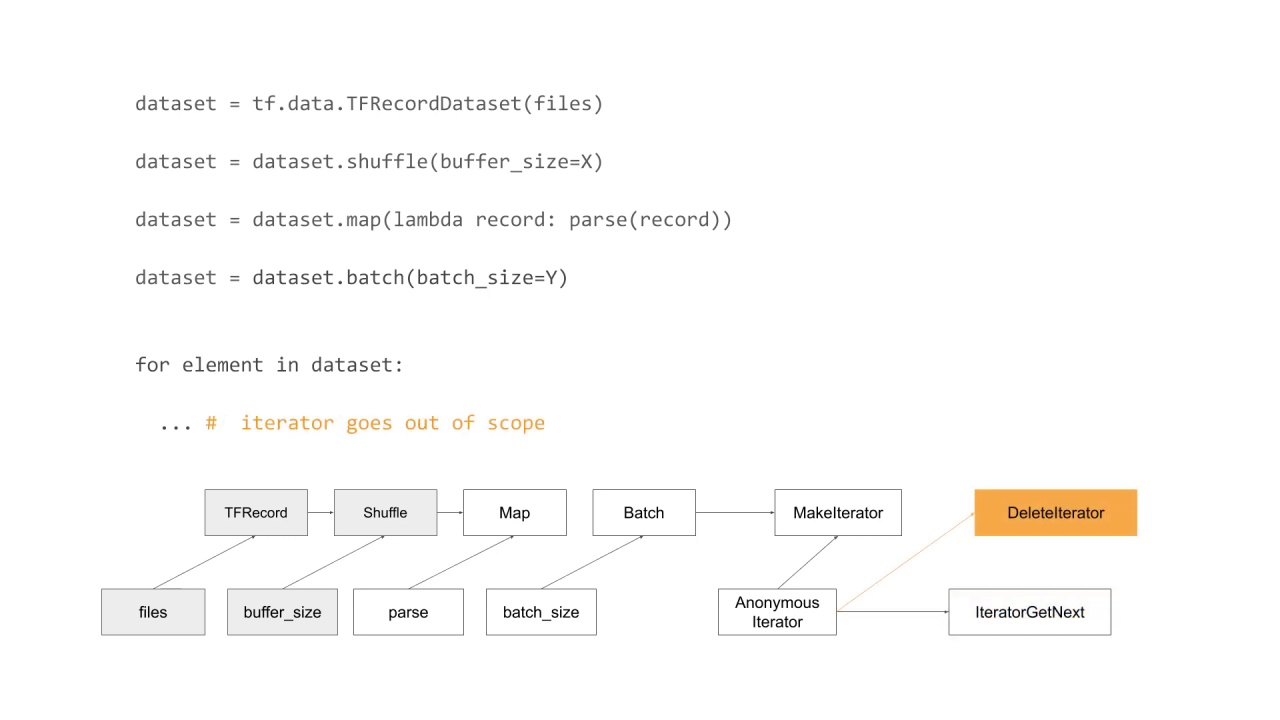
Finally, when the Python iterator object goes out of scope, the DeleteIterator op is executed to make sure the iterator resource is properly disposed of.
To state the obvious, properly disposing of the iterator resource is essential as it is not uncommon for the iterator resource to allocate 100MBs to GBs of memory because of internal buffering.